概述
论文地址:https://arxiv.org/abs/2405.00958
研究介绍了生成式制造系统(GMS),并表明这些系统能有效管理和协调自主制造资产,提高它们对不同生产目标和人类偏好的响应能力和灵活性。
与传统的显式建模不同,GMS 使用生成式人工智能(包括扩散模型和 ChatGPT)来隐式学习未来愿景,通过训练和采样从模型优化转向决策。生成式人工智能的集成使 GMS 能够通过人机交互做出复杂的决策,让制造资产能够生成多个高质量的全局决策,并根据人的反馈进行迭代改进。
实证结果表明,全球监测系统大大提高了系统的弹性和对不确定性的反应能力,将决策时间从几秒缩短到几毫秒。研究强调了所生成解决方案的创造性和多样性,并揭示了以人为本的决策可通过顺畅、持续的人机交互得到促进。
介绍
制造系统面临着多种形式、紧迫性和影响的持续不确定性。首先,大规模个性化的出现以及法规和标准的变化增加了生产要求的复杂性,要求系统巧妙地驾驭不断变化的需求和义务。其次,自然灾害、流行病、金融危机和地缘政治冲突导致的生产中断会造成资源短缺和消费行为的改变。在重大生产中断之后,20%-30% 的企业和业务被迫关闭。最后,在可持续发展、社会和环境目标的推动下,新的生产计划要求重新评估生产目标和重新思考现有系统。
未来的制造系统需要具有灵活性,能够快速适应不确定因素,并在新举措和新限制之间取得平衡。 20 世纪 60 年代,随着柔性制造系统的诞生,柔性首次被引入制造系统。尽管人们努力提高硬件和软件的灵活性,但随着资产和规划范围的不断扩大,集中控制带来的 NP 困难阻碍了系统的响应能力。
机器人、车辆和移动机械手等制造资产自主性的提高为应对这一挑战提供了机会,并有可能通过将决策权下放给每个资产来提高响应速度。奥迪等制造商正在从固定线生产转向使用自主资产的分体式工作站,而适合特定制造任务的资产(如小帮手、欧姆龙 MoMa、KMR IIWA)已在汽车和航空航天业显示出成效。这些资产通过战略任务分配和路线安排,实现了可调整的布局和时间表,预计可提高劳动利用率和产量达 30%。 新的制造系统,如基于代理的制造系统、矩阵生产系统和无政府制造系统,通过分散或分布式控制实现资产自主化。
然而,随着开放式接口和通用标准使更多资产变得更加复杂和灵活,这些控制方法也面临着挑战。单个资产往往缺乏对整个系统及其限制因素的全面认识,因此难以协调单个计划,阻碍了最佳解决方案的实现。
更重要的是,最佳解决方案有赖于有效平衡不同的目标和利益相关者的偏好,而这些目标和偏好可能无法完全明确地模拟出来。为了最大限度地发挥资产自主性的优势,需要一种革命性的方法来确保以人为本的决策,同时有效地管理各种资产,兼顾不同的生产目标和处理不确定性。
生成模型通过独特的生成能力、概率建模和互动决策,为应对这些挑战提供了变革性的机会。在本研究中,我们提出了一种 GMS,它代表了从当前显性模型到未来隐性知识的根本性转变。受梦工厂愿景的启发,我们的方法探索了各种决策和不确定性的组合,并从未来经验中生成了许多潜在的未来。通过利用生成模型(包括扩散模型和 ChatGPT),GMS 巧妙地捕捉到了决策背后的模式和分布,即使在超出最初探索范围的情况下,也能促进创造性决策。
生成式制造系统(GMS)
作者建议在未来的制造系统中,将固定机器、自主资产和多样化的人力协同整合在一起。考虑到资产的自主性和流动性越来越强,作者建议自主资产和人类可以在不同的工作站之间动态移动并进行自我组织,从而改善制造操作并简化货物流 GMS 的设计目的是在人类的监督下,根据不确定性和生产目标娴熟地调整其配置和计划。在人的监督下,GMS 可以根据不确定性和生产目标巧妙地调整配置和计划。
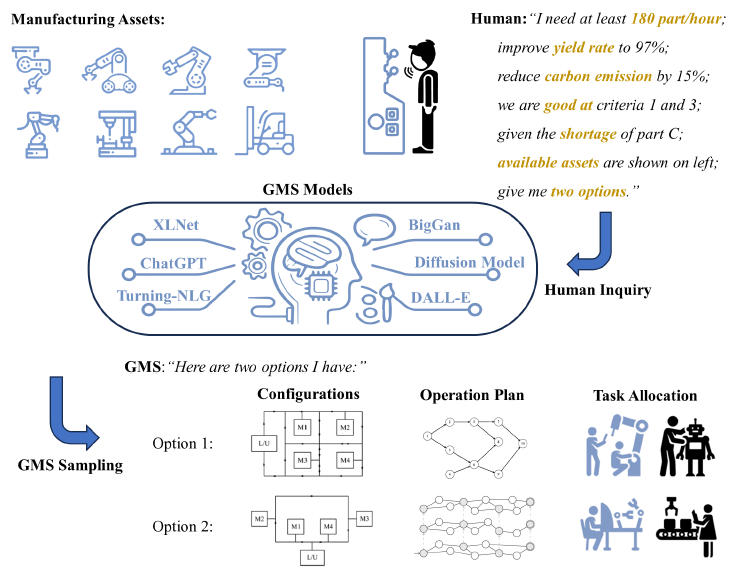
图 1:全球监测系统示意图
图 1 显示了 GMS 的示意图,描述了资产接收人类查询的过程(左图)、训练有素的 GMS 模型从未来探索中抽取新决策的过程(中图),以及 GMS 根据人类查询提供各种配置和调度选项的过程(右图)。图 2. GMS 利用大型语言模型(如 ChatGPT、XLNet 和 Turning-NLP)将人类查询转化为机器语言。
然后,利用图像生成模型(如扩散模型、BigGAN 和 DALL-E)来生成系统配置(每个工作站的人员和资产位置),以响应人类的询问。此外,还要确定详细的操作时间表和任务分配,在各工作站之间以及人与机器人之间分配任务,并考虑到材料和流程限制。 与依赖现有显式模型寻找最优决策(模型优化)的方法不同,GMS 采用的是训练和抽样方法。
通过对未来场景的广泛探索,GMS 可以隐式学习良好决策的概率分布,并根据人的愿望和生产目标组合这些分布,然后对决策进行采样。从模型优化到训练和采样方法的转变,不仅解决了现有制造系统在计算方面的难题,还带来了以下优势
创造性:在采样时加入噪音,可增加潜在决策的范围。生成模型还可以通过组合所学分布来创建新的决策,这是应对新的人类查询和意外情况的一个重要因素。
复原力:训练和采样使系统在面对不确定性时反应更灵敏,采样决策比优化收敛更有效率,并能为不同场景提供多种解决方案。
以人为本:全球监测系统中的隐性知识与人类的探究、知识和专长无缝整合,使人类能够从生成模型中获得微妙的见解。这种协同作用使人类与自主资产之间的合作更加一体化和有效,使人类能够利用全球监测系统的能力来加强决策,并获得主人翁感和工作满足感。
生成模型
本节将介绍两个用于 GMS 中动态资产管理的生成模型:1)使用 ChatGPT 从人类查询中提取系统需求;2)使用扩散模型为这些需求生成配置。
ChatGPT
通过使用 Python 中的 OpenAI ChatGPT API 和 gpt-3.5-turbo 模型,我们创建了一个命名实体识别任务,以便从人类查询中生成关键需求。例如,如果查询的内容是 "我需要一条每小时至少生产 240 个零件且使用不超过 9 台机器的生产线",响应将返回类 c = '(240, None, 9)'。无 "作为一个占位符,表示没有明确说明的人类技能。
扩散模型
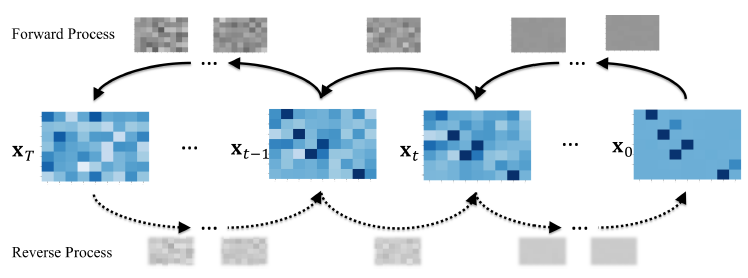
扩散模型通过从训练数据中学习配置的基本模式、特征和分布来生成新样本。扩散模型与其他机器学习模型的不同之处在于,它们是通过逐步完善噪声注入数据来生成新样本的。这一过程包括两个过程,如图 2 所示。
前向过程:添加噪声𝜖 𝑡,直到每一步都销毁数据 𝑥 0。
后向过程:逐步去除估计噪声,并对新的𝑥0 进行采样。
|-------------------------------------------------------------------------------------------------------------------------------------------|
| 图 2:扩散模型的前向和后向过程 在前向过程中,高斯噪声 𝜖 ∼ 𝑁 ( 0 , 𝐼 ) 在每一步 𝑡∈ 𝑇 被引入输入数据 𝑥0,权重由前向过程的方差 𝜖𝑡 决定。后向过程使用学习模型𝜃来估计噪声𝜖𝑡,作为𝑧𝑡、当前步骤𝑡和类别标签𝑐的函数。 |
学习模型
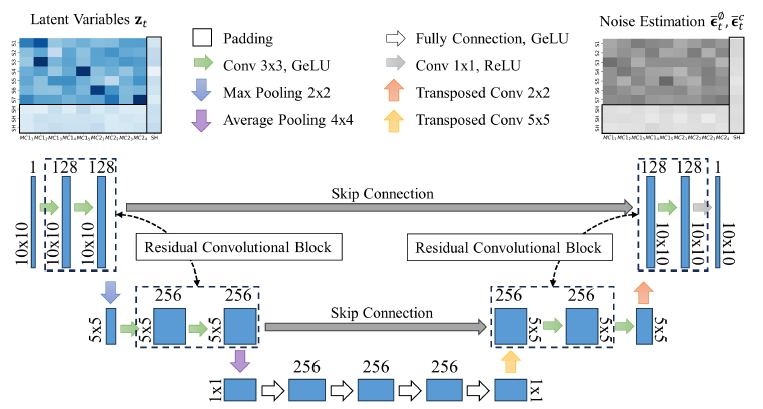
学习模型𝜃采用 U-Net 结构,以实现高效的噪声估计;U-Net 用于促进池化和反卷积路径之间的信息流。对残差卷积块进行了调整,以加强矩阵形式数据的分层特征提取和模式识别。跳转连接的引入无缝整合了 U-Net 不同层次的学习特征和上下文信息,保留了整个网络的空间特征。
|-----------------------------------------------------------------------------------------|
| 图 3:使用残差卷积块进行噪声估计的 U-Net 架构。 每个区块有两个连续的卷积层,采用批量归一化、GELU 激活和残差连接,将输入添加到输出张量中,确保网络学习残差映射。 |
做梦过程
这项研究引入了一个 "做梦过程",利用元启发式方法来探索潜在的决策。该过程随机生成未来的需求、人力和资产能力情景,并做出相应的配置和调度决策。它集成了遗传算法启发的选择、交叉和变异操作,以加快数据积累,促进生成多样化的适当配置。造梦过程在预定的迭代次数后终止,而不是模型收敛,从而确保了数据集的平衡。
结果
介绍了 GMS 的实施和模拟结果。本研究在一个工业部件加工使用案例中实施并模拟了 GMS。系统假设了九种资产类型和操作/运行设置,分布在七个工位,以促进灵活合作。人类技能水平随机设定为高/中/低(120/60/0 个零件/小时)。
|---------------------|
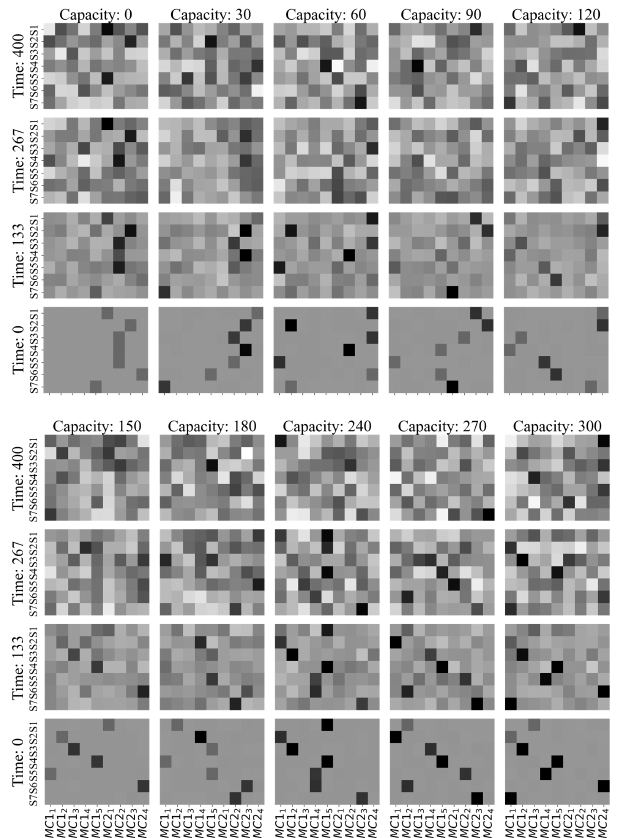
| 图 4:根据目标容量进行配置的抽样过程 |
造梦过程将操作员的技能随机分为 25 代,每代包括 40 种潜在配置;使用 Cplex 获得配置和最佳时间表的映射。模拟运行了 120 个运行单元,并在 15 个小时内生成了 120,000 个数据用于训练。扩散过程和训练模型使用 Python 和 PyTorch 实现。根据优化调整结果,将过程方差设为 φ0=10-4和 φ𝑇=0.02,总步数设为 T = 400,引导强度设为 w = 2。
通过采样过程对扩散模型进行训练,以生成符合指定目标容量的合理配置。随着步骤数量的减少,抽样配置变得更加合理,并产生清晰的布局。合理的生成依赖于对关键特征和模式的隐性知识的娴熟积累。例如,容量为零的配置在矩阵的后半部分主要以浅色显示,这表明某类资产的使用率很低。随着产能的增加,资产类型(深色)也随之增加,从而提高了并行生产和运营效率。
|------------------|
| 表 1:决策时间与其他算法的比较 |
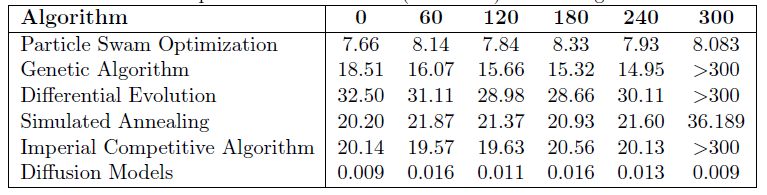
在整个指定容量范围内,扩散模型的决策时间在 9 毫秒到 16 毫秒之间。与其他算法相比,这种一致的效率代表了数量上的改进,其他算法在达到目标容量之前通常超过 10 秒,有时甚至超过 300 秒。扩散模型的一致效率表明,训练-抽样方法的算法效率有所提高,大大增强了全球监测系统对不确定性的响应能力和应变能力。
|-------------------|
| 表 2:有指导和无指导时的模型性能 |
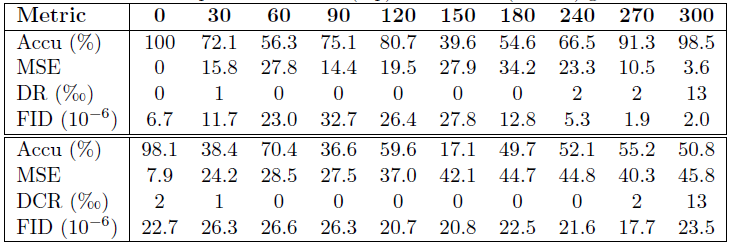
为全面评估生成样本的质量,随机抽取了 1000 个配置,并根据以下三个指标进行评估
精度:与所需容量一致的精度 (Accu) 和均方误差 (MSE)
多样性:训练数据中存在的生成配置的重叠率 (DR)
保真度:Frechet Inception Distance (FID),用于衡量生成样本与训练数据分布相比的可感知质量和保真度。
有指导和无指导的扩散模型性能如下所示。对于所需的要求,有指导的模型产生的决策具有更高的准确性、更低的 MSE 和更高的多样性;由于相应配置的高度相似性,FID 分数在极端容量时要低得多,而在中等容量时要高得多。总体而言,这些高精确度、高保真和高多样性的决策表明,GMS 在处理不确定性和多样化目标时具有很强的应变能力和创造力。
总结
本研究介绍了生成式制造系统(GMS),以利用制造资产的自主性来应对不确定性、人的愿望和新的生产目标。.来自工业应用案例的经验结果凸显了 GMS 的弹性和创造性,在决策时间、多样性和质量方面始终优于现有方法。
全球监测系统可以根据人类的询问和额外目标,巧妙地调整配置和调度,促进以人为本的决策,从而实现协作探索和持续改进。未来的研究可以探索诊断和质量管理等不同场景,以及碳排放和人类福祉等性能指标,并通过嵌入而非固定类别纳入更复杂的人类查询。