
在前面,我们已经学习了解了顺序表和链表这两种线性表,今天我们继续来学习了解新的两种线性表结构------栈和队列
目录
栈
概念
栈是⼀种特殊的线性表,其只允许 在固定的⼀端进⾏插⼊和删除元素 操作。进⾏数据插⼊和删除操作 的 ⼀端称为栈顶 , 另⼀端称为栈底 。
栈中的数据元素遵守 后进先出 (后面进去的元素先出栈)的原则。
同时 栈里面的数据不能遍历,也不能随机访问 。
我们来画图进行更好的理解
进栈:
出栈:
我们可以看到 数据的插入和删除操作都在固定的一端进行,我们把这固定的一端叫做 栈顶 ,另外的一端叫做栈底,这也就是栈这个线性表的特殊之处了。


实现
思路
那么栈只能在数据的一端进行处理,它的实现思路是什么呢?我们一起来分析分析。
我们知道栈的特点是只允许在栈的一端删除或者插入数据,同时不能遍历和随机访问。
如果我们使用链表来实现栈,如果是双向链表,里面会有两个指针,这样的话就更加吃内存。
如果使用单链表,每一次进行数据插入的时候,都需要进行一次空间的创建(malloc).
如果我们使用一个数组来实现栈,那么当空间不够的时候,我们就可以进行扩容(realloc),就不需要频繁地创建空间,相较于链表而言使用数组插入更好。
栈的实现可以使用数组或者链表实现,相对⽽⾔数组的结构实现更优⼀些。因为数组在尾上插入数据的代价比较小。
那么栈的具体结构是什么呢?
一般结构
首先,我们需要动态定义一块空间,同时需要知道栈顶的位置,从栈顶进行数据的插入和删除,同时也需要知道栈的容量(这里实现的栈底层结构是数组,也可以理解为数组的大小),如果容量不够就需要进行扩容。
cpp
struct Stack
{
int* arr;
int top;//栈顶
int capacity;//栈的容量
};优化:
cpp
//优化
typedef int STDataType;
typedef struct Stack
{
STDataType* arr;
int top;//栈顶
int capacity;//栈的容量
};剩下的在实现栈的时候就与我们的顺序表的实现有些类似了。
初始化
cpp
void STInit(ST* ps)
{
assert(ps);
ps->arr = NULL;
ps->capacity = ps->top = 0;
}入栈
栈也是有空间的,在空间足够的情况下,才可以进行数据入栈,如果空间不够的情况下就需要进行扩容。所以首先我们需要对栈顶容量进行判断,代码如下:
cpp
void stackPush(ST* ps, STDataType x)
{
assert(ps);
//判断空间是否足够
if (ps->capacity == ps->top)
//说明空间满了
{
int newcapacity = (ps->capacity == 0) ? 4 : (2 * ps->capacity);
//如果最开始容量为0就扩容到默认值4,如果不为0就扩大到原来的两倍
STDataType* tmp = (STDataType*)realloc(ps->arr, sizeof(STDataType) * newcapacity);
//创建一个临时变量,避免创建失败,影响最初的数据
if (tmp == NULL)
{
perror("realloc fail!");
exit(1);
}
else
{
ps->arr = tmp;
ps->capacity = newcapacity;
}
}
//空间足够
//ps->arr[ps->top++] = x;
//方法二
ps->arr[ps->top] = x;
ps->top++;
}取栈顶元素
取栈顶元素的时候,我们首先需要确定这个栈里面是不是有元素,是不是为空栈,前面的assert(ps)是用来判断地址是否有效。确定栈是否为空,我们需要新的方式来确定,代码如下:
cpp
bool stackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
//栈顶元素为0,说明就是初始化的结果,栈中没有元素,返回false
}
cpp
STDataType stackTop(ST* ps)
{
assert(ps);
//判断栈是否有元素
assert(!stackEmpty(ps));
return ps->arr[ps->top - 1];
//数组下标从0开始
}出栈
同样需要判断栈是否为空,代码如下:
cpp
//出栈
void stackPop(ST* ps)
{
assert(ps);
assert(!stackEmpty(ps));
--ps->top;//栈顶元素变化
}统计栈元素个数
栈中元素个数也就是top的值,直接返回就可以了。
cpp
int stackCount(ST* ps)
{
assert(ps);
return ps->top;
}销毁栈
cpp
void stackDestory(ST* ps)
{
assert(ps);
if (ps->arr)//如果数组不为空
free(ps->arr);
ps->arr = NULL;
ps->capacity = ps->top = 0;
}测试
我们使用一个test.c文件来简单的测试一下
cpp
void Test()
{
ST st;
STInit(&st);
//入栈
stackPush(&st, 1);
stackPush(&st, 2);
stackPush(&st, 3);
stackPush(&st, 4);
stackPush(&st, 5);
stackPush(&st, 6);
stackPush(&st, 7);
//后面进栈的先出栈
printf("begin count:%d\n", stackCount(&st));
while (!stackEmpty(&st))
{
STDataType data = stackTop(&st);
printf("%d ", data);
stackPop(&st);//出栈
}
printf("\nend count:%d\n", stackCount(&st));
//销毁栈
stackDestory(&st);
}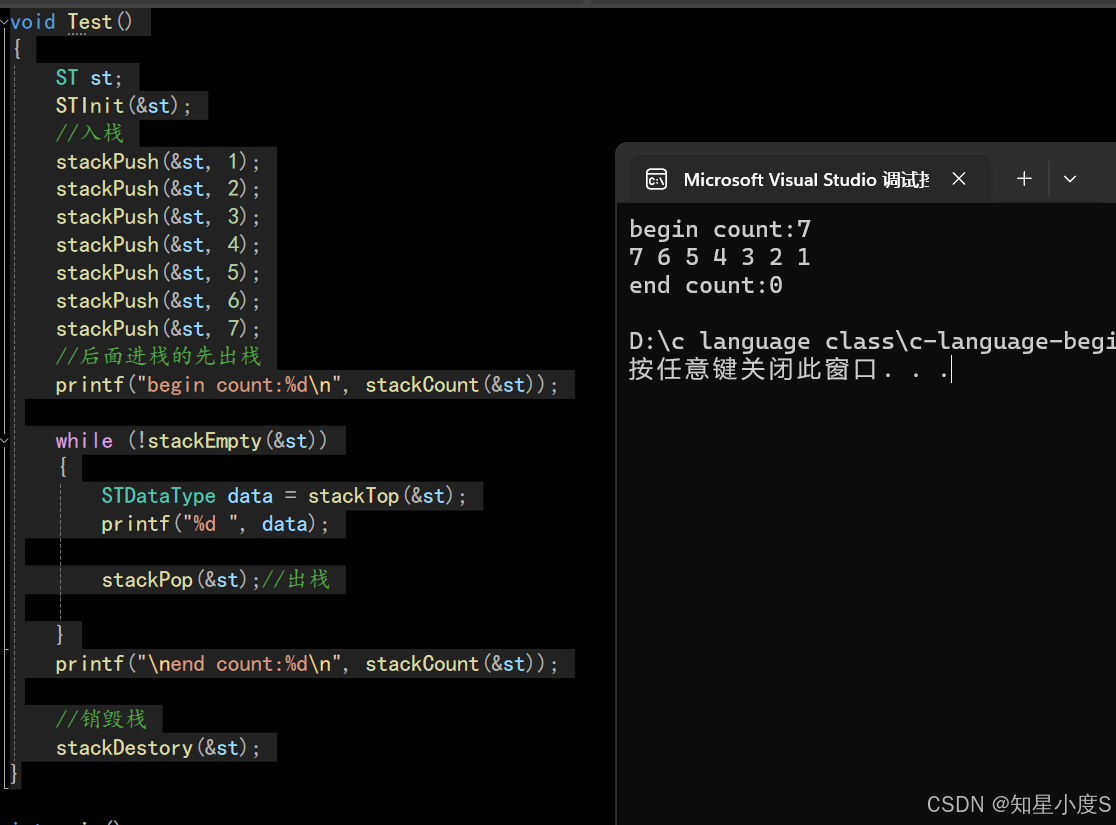
我们可以看到运行结果是没有问题的。
总代码
stack.h
cpp
//包含需要使用的头文件
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>
//struct Stack
//{
// int* arr;
// int top;//栈顶
// int capacity;//栈的容量
//};
//优化
typedef int STDataType;
typedef struct Stack
{
STDataType* arr;
int top;//栈顶
int capacity;//栈的容量
}ST;
void STInit(ST* ps);
void stackPush(ST* ps, STDataType x);
bool stackEmpty(ST* ps);
STDataType stackTop(ST* ps);
void stackPop(ST* ps);
int stackCount(ST* ps);
void stackDestory(ST* ps);stack.c
cpp
#include"stack.h"
void STInit(ST* ps)
{
assert(ps);
ps->arr = NULL;
ps->capacity = ps->top = 0;
}
void stackPush(ST* ps, STDataType x)
{
assert(ps);
//判断空间是否足够
if (ps->capacity == ps->top)
//说明空间满了
{
int newcapacity = (ps->capacity == 0) ? 4 : (2 * ps->capacity);
//如果最开始容量为0就扩容到默认值4,如果不为0就扩大到原来的两倍
STDataType* tmp = (STDataType*)realloc(ps->arr, sizeof(STDataType) * newcapacity);
//创建一个临时变量,避免创建失败,影响最初的数据
if (tmp == NULL)
{
perror("realloc fail!");
exit(1);
}
else
{
ps->arr = tmp;
ps->capacity = newcapacity;
}
}
//空间足够
//ps->arr[ps->top++] = x;
//方法二
ps->arr[ps->top] = x;
ps->top++;
}
bool stackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
//栈顶元素为0,说明就是初始化的结果,栈中没有元素,返回false
}
STDataType stackTop(ST* ps)
{
assert(ps);
//判断栈是否有元素
assert(!stackEmpty(ps));
return ps->arr[ps->top - 1];
//数组下标从0开始
}
//出栈
void stackPop(ST* ps)
{
assert(ps);
assert(!stackEmpty(ps));
--ps->top;//栈顶元素变化
}
int stackCount(ST* ps)
{
assert(ps);
return ps->top;
}
void stackDestory(ST* ps)
{
assert(ps);
if (ps->arr)//如果数组不为空
free(ps->arr);
ps->arr = NULL;
ps->capacity = ps->top = 0;
}test.c
cpp
#include"stack.h"
void Test()
{
ST st;
STInit(&st);
//入栈
stackPush(&st, 1);
stackPush(&st, 2);
stackPush(&st, 3);
stackPush(&st, 4);
stackPush(&st, 5);
stackPush(&st, 6);
stackPush(&st, 7);
//后面进栈的先出栈
printf("begin count:%d\n", stackCount(&st));
while (!stackEmpty(&st))
{
STDataType data = stackTop(&st);
printf("%d ", data);
stackPop(&st);//出栈
}
printf("\nend count:%d\n", stackCount(&st));
//销毁栈
stackDestory(&st);
}
int main()
{
Test();
return 0;
}队列
知道了栈这样一种特殊的线性表,接下来我们一起来看看另外一种特殊的线性表。
概念
只允许在 ⼀端进⾏插⼊数据操作 , 在 另⼀端进⾏删除数据操作 的特殊线性表
队列具有 先进先出 (先进队列的数据先出队列)的原则。
我们可以理解为队列的两端都是开口的,一端进行数据的插入,一端进行数据的删除。
⼊队列 :进⾏插⼊操作的⼀端称为 队尾
出队列 :进⾏删除操作的⼀端称为 队头

实现
思路
既然队列有一个队头和一个队尾,队头用来出数据,队尾用来插入数据
如果我们使用数据是不是就不太方便,如果把数组的第一个元素的位置当作队头,将最后一个元素的位置当作队尾,那么每一次出数据的时候,都需要遍历数组将后面的元素往前面进行移动,时间复杂度就为O(N)
如果我们使用单链表,那么我们就只需要保存链表的头结点和尾结点,在插入数据或者删除数据时,就只需要改变它们的指向就可以了,时间复杂度为O(1),这样的话是不是就更加的优化呢。
所以队列的实现可以使用数组或者链表实现,但是使用单链表的结构实现更优⼀些。
一般结构
既然我们知道队列用单链表实现更加方便,那我们这里实现队列底层就采用单链表的结构,首先,我们需要知道每一个节点的结构,然后再用两个指针来保存队列的队头和队尾。
代码如下:
cpp
//定义队列一个结点的结构
struct QueueNode
{
int data;
struct QueueNode* next;
};
//队列的结构,保存队头和队尾
struct Queue
{
struct QueueNode* phead;
struct QueueNode* ptail;
};简单优化:
cpp
typedef int QDataType;
//定义队列一个结点的结构
struct QueueNode
{
QDataType data;
struct QueueNode* next;
};
//队列的结构,保存队头和队尾
typedef struct Queue
{
struct QueueNode* phead;
struct QueueNode* ptail;
int size;
}Queue;这里除了将存储数据类型和队列结构进行了重命名,还添加了一个结构体成员size,这是为什么呢?
这是为了后面可以更好地知道队列中的有效元素个数,我们后面会进行更加详细的讲解。
初始化
这里涉及到结点的改变,所以我们需要传地址,用指针来接收。
cpp
#include"Queue.h"
void test01()
{
Queue QU;
QueueInit(&QU);
}
int main()
{
test01();
return 0;
}
cpp
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = pq->ptail = NULL;
pq->size = 0;
}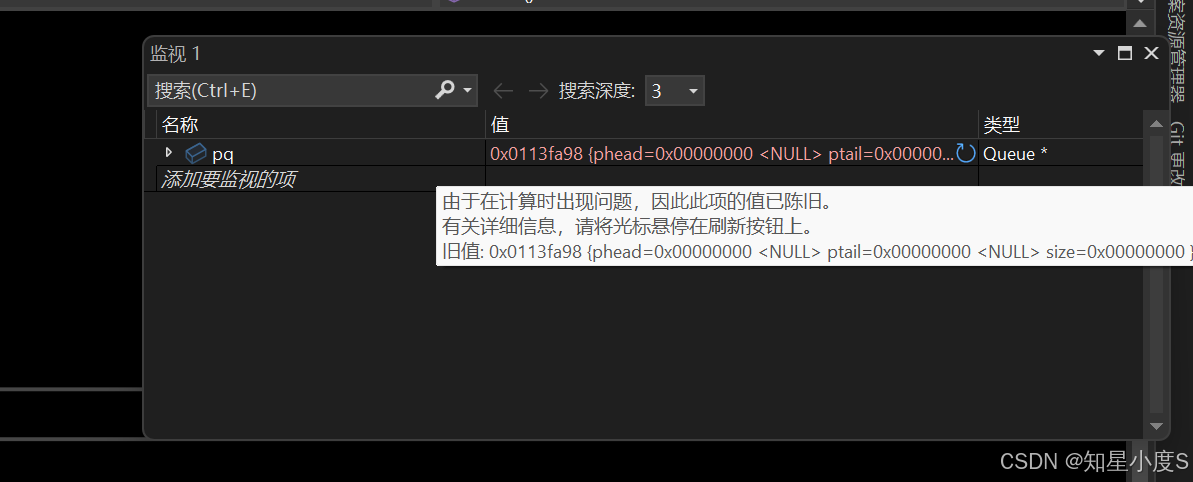
通过监视我们可以发现他成功地进行了初始化。
队列判空
我们对一个队列进行数据的删除和插入的时候,首先就需要判断,队列是不是为空,也就是队列里面是不是有数据,结合我们最开始的初始化,如果队列的头结点和尾结点都指向NULL,那么我们就可以判断队列为空。我们可以使用bool类型函数(头文件stdbool.h)来进行判断,代码如下:
cpp
//队列判空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return (pq->phead == NULL) && (pq->ptail == NULL);
//如果队头和队尾都为空说明是空队列,return true
}入队列
结合我们讲到的概念,入队列需要在队尾进行操作
入队列首先我们需要判断传过来的队列的地址是否存在,然后需要申请一个新结点进行插入,这里需要特别注意的是在进行新结点入队列的时候,需要判断队列是否为空,如果为空,那么队列的头结点和尾结点都是指向新结点的,不为空改变新结点及相邻结点的指向就可以了。同时最开始队列里面定义的size要++。
代码如下:
cpp
// 入队列,队尾
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
//创建一个新的结点
struct QueueNode* newnode = (struct QueueNode*)malloc(sizeof(struct QueueNode));
if (newnode == NULL)//没有创建成功
{
perror("malloc fail");
exit(1);
}
newnode->data = x;
newnode->next = NULL;
//如果原来为空队列,那么队头和队尾都是新结点
//if (pq->phead == NULL)
if(QueueEmpty(pq))
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;//原来队尾的下一个指向新结点
pq->ptail = newnode;//新结点成为新的队尾
}
pq->size++;
}出队列
入队列在队尾,出队列在队头。
跟入队列一样,首先我们需要判断传过来的队列的地址是否存在,再判断队列是否为空。如果不为空,就可以改变结点指向,释放掉最开始的头结点。但是如果队列只有一个结点的情况下,我们并没有对尾结点进行处理。所以我们还需要特别讨论一下这一种情况。如果只有一个结点我们要把头结点和尾结点都置为空,避免尾结点成为野指针。同时最开始队列里面定义的size要--。
代码如下:
cpp
// 出队列,队头
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
//如果只有一个结点
if (pq->phead == pq->ptail)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;//避免ptail野指针,因为后面代码没有对ptail进行释放
}
else
{
struct QueueNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
--pq->size;
}取队头队尾数据
队列我们本来就保存的是队列的头结点和尾结点,所以我们只需要返回相应的头结点和尾节点数据就可以了。(最开始需要判断传过来的队列的地址是否存在,再判断队列是否为空)
代码如下:
cpp
//取队头数据
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->phead->data;
}
//取队尾数据
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->ptail->data;
}队列有效元素个数
方法一:这里就与我们前面队列里面定义的size有很大关系了,最开始基本操作需要判断传过来的队列的地址是否存在,再判断队列是否为空,然后直接返回size的值就可以了。
方法二:如果最开始没有定义size的话,就需要对这个队列遍历来统计元素的有效个数,涉及到遍历那么时间复杂度就为O(N)
所以我们就可以用最开始定义一个size的方式来进行优化。
cpp
//队列有效元素个数
int QueueSize(Queue* pq)
{
assert(pq);
//方法一:遍历统计个数,时间复杂度为O(N)
/*struct QueueNode* pcur = pq->phead;
int size = 0;
while (pcur)
{
size++;
pcur = pcur->next;
}
return size;*/
//方法二:
return pq->size;
}队列销毁
最开始依然是基本操作判断传过来的队列的地址是否存在,再判断队列是否为空,然后对队列进行遍历销毁,最后记得把phead和ptail置为空,size置为0.
cpp
//销毁队列
void QueueDestroy(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
struct QueueNode* pcur = pq->phead;
while (pcur)
{
struct QueueNode* next = pcur->next;
//保存销毁位置的下一个结点
free(pcur);
pcur = next;
}
pq->phead = pq->ptail = NULL;
pq->size = 0;
}简单测试
总代码
Queue.h
cpp
//#include<stdio.h>
//#include<assert.h>
//
定义队列一个结点的结构
//struct QueueNode
//{
// int data;
// struct QueueNode* next;
//};
//
//
保存队头和队尾
//struct Queue
//{
// struct QueueNode* phead;
// struct QueueNode* ptail;
//};
#include<stdio.h>
#include<assert.h>
#include<stdbool.h>
#include<stdlib.h>
typedef int QDataType;
//定义队列一个结点的结构
struct QueueNode
{
QDataType data;
struct QueueNode* next;
};
//队列的结构,保存队头和队尾
typedef struct Queue
{
struct QueueNode* phead;
struct QueueNode* ptail;
int size;
}Queue;
//初始化
void QueueInit(Queue* pq);
// 入队列,队尾
void QueuePush(Queue* pq, QDataType x);
// 出队列,队头
void QueuePop(Queue* pq);
//队列判空
bool QueueEmpty(Queue* pq);
//取队头数据
QDataType QueueFront(Queue* pq);
//取队尾数据
QDataType QueueBack(Queue* pq);
//队列有效元素个数
int QueueSize(Queue* pq);
//销毁队列
void QueueDestroy(Queue* pq);Queue.c
cpp
#include"Queue.h"
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = pq->ptail = NULL;
pq->size = 0;
}
//队列判空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return (pq->phead == NULL) && (pq->ptail == NULL);
//如果队头和队尾都为空说明是空队列,return true
}
// 入队列,队尾
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
//创建一个新的结点
struct QueueNode* newnode = (struct QueueNode*)malloc(sizeof(struct QueueNode));
if (newnode == NULL)//没有创建成功
{
perror("malloc fail");
exit(1);
}
newnode->data = x;
newnode->next = NULL;
//如果原来为空队列,那么队头和队尾都是新结点
//if (pq->phead == NULL)
if(QueueEmpty(pq))
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;//原来队尾的下一个指向新结点
pq->ptail = newnode;//新结点成为新的队尾
}
pq->size++;
}
// 出队列,队头
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
//如果只有一个结点
if (pq->phead == pq->ptail)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;//避免ptail野指针,因为后面代码没有对ptail进行释放
}
else
{
struct QueueNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
--pq->size;
}
//取队头数据
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->phead->data;
}
//取队尾数据
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->ptail->data;
}
//队列有效元素个数
int QueueSize(Queue* pq)
{
assert(pq);
/*struct QueueNode* pcur = pq->phead;
int size = 0;
while (pcur)
{
size++;
pcur = pcur->next;
}
return size;*/
return pq->size;
}
//销毁队列
void QueueDestroy(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
struct QueueNode* pcur = pq->phead;
while (pcur)
{
struct QueueNode* next = pcur->next;
//保存销毁位置的下一个结点
free(pcur);
pcur = next;
}
pq->phead = pq->ptail = NULL;
pq->size = 0;
}test.c
cpp
#include"Queue.h"
void test01()
{
Queue QU;
QueueInit(&QU);
QueuePush(&QU, 1);
QueuePush(&QU, 2);
QueuePush(&QU, 3);
QueuePush(&QU, 4);
QueuePush(&QU, 5);
//1-》2-》3-》4-》5
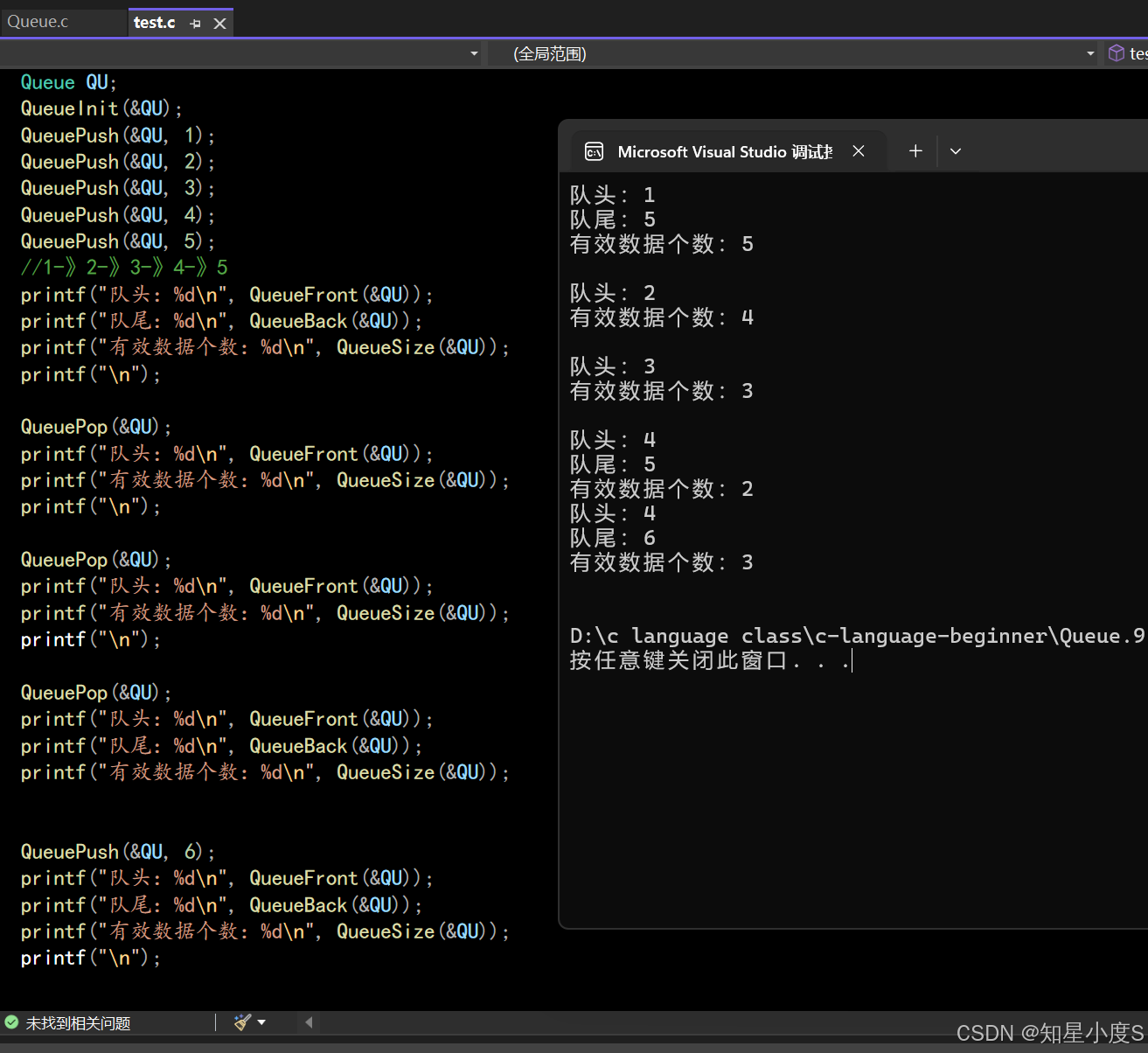
printf("队头:%d\n", QueueFront(&QU));
printf("队尾:%d\n", QueueBack(&QU));
printf("有效数据个数:%d\n", QueueSize(&QU));
printf("\n");
QueuePop(&QU);
printf("队头:%d\n", QueueFront(&QU));
printf("有效数据个数:%d\n", QueueSize(&QU));
printf("\n");
QueuePop(&QU);
printf("队头:%d\n", QueueFront(&QU));
printf("有效数据个数:%d\n", QueueSize(&QU));
printf("\n");
QueuePop(&QU);
printf("队头:%d\n", QueueFront(&QU));
printf("队尾:%d\n", QueueBack(&QU));
printf("有效数据个数:%d\n", QueueSize(&QU));
QueuePush(&QU, 6);
printf("队头:%d\n", QueueFront(&QU));
printf("队尾:%d\n", QueueBack(&QU));
printf("有效数据个数:%d\n", QueueSize(&QU));
printf("\n");
QueueDestroy(&QU);
}
int main()
{
test01();
return 0;
}总结
我们又了解了两种新的特殊的线性表结构,它们特殊之处主要在哪里呢?这里简单总结一下:
栈和队列是插入和删除位置受限制的线性表,
栈只可以在一端(栈顶)进行数据的插入和删除操作,遵循先进后出的原则;
队列在一端(队尾)进行数据插入,另外一端(队头)进行数据删除,遵循先进先出的原则。
2.栈的底层结构使用数组更好,队列底层结构使用单链表更好。
3.栈和队列都不可以进行遍历和随机访问元素,在实现的时候,我们没有这样进行实现。