**导读:**本期是《深入浅出Apache Spark》系列分享的第四期分享,第一期分享了Spark core的概念、原理和架构,第二期分享了Spark SQL的概念和原理,第三期则为Spark SQL解析层的原理和优化案例。本次分享内容主要是Spark SQL分析层的原理和优化的案例,且此优化案例是对于理解分析层原理很重要的。
本期介绍会围绕下面五点展开:
-
前情提要
-
Spark SQL 分析层原理
-
优化案例
-
总结
-
Q&A
►►►
前情提要
首先介绍数新智能与Spark有深度关系的两个产品。

赛博数智引擎,即CyberEngine,它可以帮助用户管理、部署、运维各种组件。该引擎旨在打造一款云原生的数据服务底座,同时支持各种任务的调度,包括存储等各方面的管理和运维工作。

赛博数据平台,包括数据治理、数据开发、数据探索、数据查询等各种能力,其中Spark是它支持的重要数据引擎之一。

上一讲主要介绍了Spark SQL解析层的优化。Spark SQL 解析层实际上是一条SQL执行生命周期中的第一个阶段,首先它需要被解析成一棵抽象语法树。解析后的抽象语法树由于缺少与元数据的绑定,所以我们无法知道UnresolvedAttribute是一个数据库表的列,还是Parquet文件中的一个元数据字段;我们也无法知道或者是一UnresolvedRelation是一张数据库表,还是HDFS上的文件目录。这些分析依赖于Spark SQL的分析层,也就是本次要分享的内容。
►►►
Spark SQL 分析层原理
1. Spark SQL分析层原理

刚才回顾了解析层,或者说是Spark里面的Parser,它能够把输入的SQL 文本转换成一棵解析后的抽象语法树,那么下一步就需要分析层Analyzer,即分析器对抽象语法树进行分析,把抽象语法树跟元数据信息进行绑定,知道数据的位置信息、元数据信息等等,之后才能有机会真正地查询、执行或者修改它。
分析器分析的过程依赖于一些元数据的组件,如SessionCatalog ,在SQL组件中属于元老级的组件。在Spark 2.5版本中引入的Data Source V2中一个很重要的组件叫CatalogManager,其具有用户注册机制,可以让用户注册自己的Catalog。可以理解为用户通过使用Spark内置的SessionCatalog,就可以拥有自己的Catalog。在多个Catalog注册的情况下,可以实现多个数据源之间的联邦,拥有更丰富的业务场景,更加灵活。
有些人觉得Spark内置的SessionCatalog对于Hive的支持会有一些局限,那么就可以用CatalogManager的方式去实现。 不管是老的SessionCatalog,还是新的CatalogManager,实际上最重要的是对Catalog、数据库、表、字段等元数据信息的管理。当然这里提到的表只是从Catalog的角度抽象的一个概念,实际上它未必是一个真的表,例如一个以Kafka作为数据源的Catalog,你可以把Kafka里面的一个Topic抽象成一个表,或者也可以根据这个逻辑把Topic看作是一个数据库。总之,这是一个很灵活、很便利的新扩展,是一个为了帮助分析器获取元数据信息的组件。
在分析层中除了解决元数据信息的绑定之外,还需要去解决一些其他的问题,如内置函数的绑定。比如在SQL里面包含一些函数,这些函数有些是无参数的,有些是带有多个参数的。那么这些函数是不是都是Spark本身就支持的呢?如果输入的是一个ClickHouse的函数呢?因为有些函数肯定是Spark不支持或不认识的,这是Spark在分析过程中首先要去分析的内容,它不能跳过分析直接去执行这个函数。
对函数的分析过程,Spark依赖于FunctionRegistry这个函数注册表组件,函数注册表里面绑定了一些Spark支持的内置函数。如果用户想要实现一些Spark没有但想要扩展的功能的时候,Spark也提供了用户自定义函数的支持,有新旧两套接口去实现UDF。当用户自己去实现UDF的时候,实际上是注册到整个Spark的元数据体系里面,或者说是函数的体系里面,分析器首先会从函数注册表里去查找相关函数,来确保SQL执行的合法性和安全性。这里介绍了分析层在SQL整个执行流程中的作用,接下里会从更深入的角度去介绍分析层的一些内容。

刚刚提到解析后的查询树或者说逻辑执行树、抽象语法树需要跟元数据绑定,分析器就是负责这些处理的角色。
之前在第一、二讲中,整体介绍Spark SQL的执行流程时,介绍过两个很核心的抽象概念------规则(即Rule)和规则执行器(即RuleExecutor)。本次分享分析器,以及下一讲将要分享的优化器,实际上就是规则执行器的具体应用。分析器里面的每一个分析规则、优化规则都是规则的实现。规则执行器能够帮助逻辑计划去应用这些规则,这就是规则执行器的简单原理。
当然规则还需要一定的匹配过程,比如有一些规则要解析表或者数据源的位置,有一些可能是为了识别某些属性是一个别名还是表的名字、表的字段,每个规则都有具体的针对性工作。
最后需要提一提------规则的执行是有细节的。在第二讲中分享规则的时候,提到除了规则信息的抽象之外,就是规则的执行。例如处理抽象语法树,对整棵树应用一个规则的时候,它需要一定的封装逻辑。
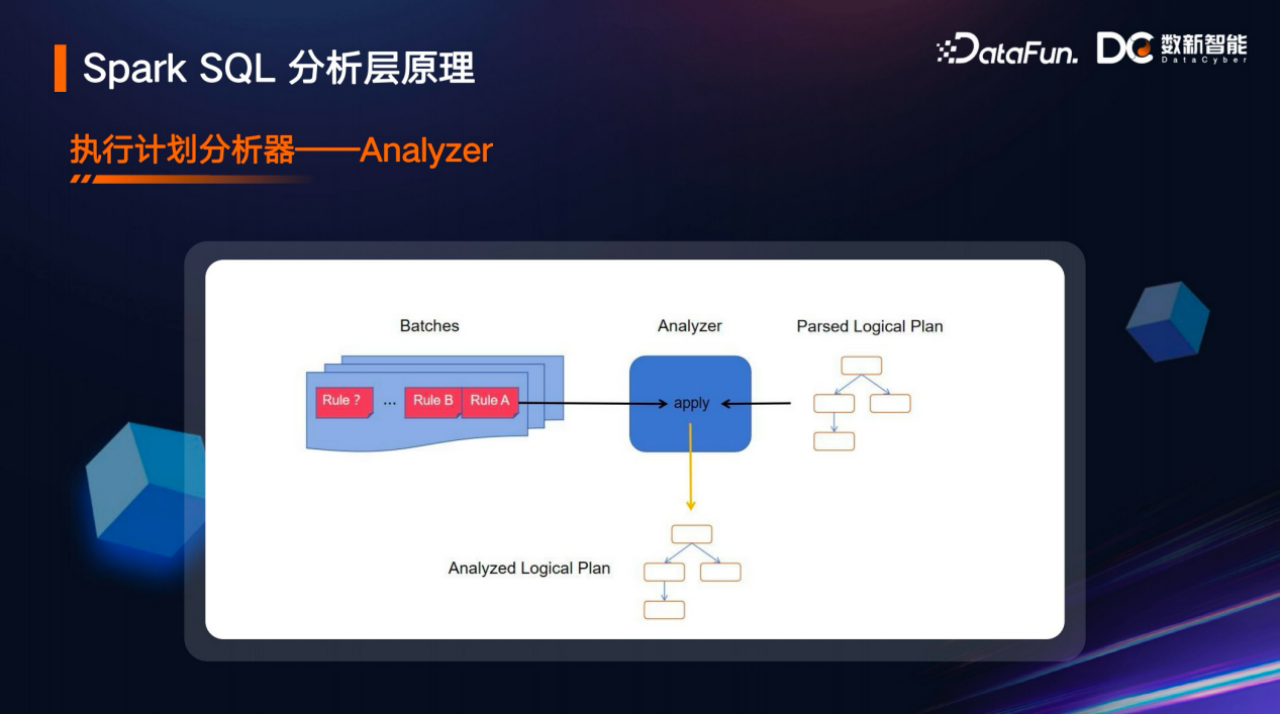
在Spark SQL的执行流程中,分析器本身就是规则执行器的具体实现,它里面会应用很多规则,这些规则可能是分批的,每一批里面又有很多规则,这些规则有些可能只执行一次,有些可能执行多次。而后分析器会对解析后的语法树进行处理,也可以理解是应用了一系列分析规则之后,它就会变成分析后的逻辑语法树。
2. 分析规则介绍

本节介绍一个简单的例子,这个例子可以帮助大家快速了解如何去写一个规则,为将来工作中使用Spark SQL对一些业务场景进行增强分析提供参考。
例如ResolveRelations分析规则,如select xxx from Tab1,解析层会把这个SQL解析成抽象语法树,这里Tab1是一张真的表,但是解析器是不知道的,它只会把它简单地封装成一个UnresolvedRelation,即未分析的Relation,那么这个Relation究竟是一个表还是其他什么东西,是需要分析器来处理。分析器主要就是依靠ResolveRelations这个分析规则进行处理,上图展示了分析规则的代码片段,实际这个规则的代码远比展示的要多,但因为其他代码对本次介绍的内容来说是一些干扰,所以就忽略了。从代码片段可以看到它调用了plan.resolveOperatorsUpWithPruning的遍历算法,resolveOperatorsUp是一个自底向上的过程,如果跟树的遍历算法类比的话,可以理解为它是深度遍历的一种方式。
首先它会帮你找到这棵树的第一个叶子节点,但它不会立刻去执行计算,它还会往树的更深处去找,直到找到最后的叶子节点,等这个叶子节点处理完了之后才会往上卷,这个就是对应的深度遍历算法。但是既然Up了,为什么后面还有一个WithPruning,Pruning的中文意思是裁剪,这里为什么要这么用,后面再详细介绍。
抛开这个遍历的过程,深度遍历的方式会找到每一个UnresolvedRelation,每找到一个还不知道具体是干什么的relation之后,就会首先去调用 ResolveRelation的方法,去分析Tab1是一个文件目录还是一个表,或者是其他什么,如果调用完之后发现都不是,可能会返回一个none,代表它不是一个表,也不是Hadoop里面的一个目录。之后就会交给一个叫ResolveViews的方法,因为它可能是一个视图,所以调用ResolveViews 的方法去获取views的元信息。ResolveViews方法的代码在这里没有展示,因为对本次的主题来说不是很重要,本次主要是想展示ResolveRelations这个分析规则模板实现的套路。
►►►
优化案例
1. 优化前 - 3.2.0以前的Rule的全面遍历

针对树的遍历,Spark 3.2.0版本引入了一个比较大的优化,这个优化对于分析层来说也是相当重要。
刚刚在介绍ResolveRelations时,采用了Spark 3.2.0之后的代码,其中使用的是带有 Withpruning后缀的operatorsUpWithpruning方法,表示有裁剪的意思,那么它究竟是怎么裁剪的呢?
回到Spark 3.2.0以前这块代码的实现。 Spark在分析层最主要依赖于以下几个方法,在3.2.0版本之前resolveOperators方法默认调用resolveOperatorsDown方法,resolveOperatorsDown是一个广度优先的遍历方法,此外,还有采用深度遍历的resolveOperatorsUp方法,这是Spark 3.2.0以前分析层遍历树的基本原理。在应用规则实现遍历树的时候,不管是遍历整棵树,还是随着遍历的层次不同,遍历整个树的一部分或者是一个叶子节点,都会完完整整地去遍历。可以理解为这棵树不管有多深,每一层有多少个节点,在遍历这棵树的时候,它会把规则应用到整棵树的每一个节点。
Spark SQL中有很多分析规则,有些分析规则可能只针对特殊的模式或者特殊的场景,如果用户写的SQL跟这个规则完全没有关系,并且SQL本身很复杂,对应的树的深度很高、体量庞大,如果不断地应用这个规则去执行,就会浪费大量的CPU时钟。

resolveOperators等三个方法,主要是针对整个逻辑计划层面,而逻辑计划是一个树的结构,除了逻辑计划之外,Spark里面的表达式本身也是树的结构。举个最简单的例子,例如在where条件里输入a>10 and b<0,这就是由两个表达式用and组成的一棵树,除了and组成树之外,a > 10本身也是颗树,大于号是一个父节点,大于号下面的a字段和10属性值是两个叶子。
在Spark 3.2.0之前,表达式的转换通过上图左边展示的transformExpressions、transformExpressionsUp和transformExpressionsDown。 而对逻辑计划的处理则依赖上图右边展示的resolveOperators、resolveOperatorsUp和resolveOperatorsDown。
2.优化后 - Support travelsal pruning in transform/resolve

Spark 3.2.0 之后的这个优化,我个人认为是分析层自Spark SQL诞生以来做的最重要的优化之一。大家有兴趣可以去看Spark社区任务里面一些具体的讨论,包括推进的过程和commit的一些代码。
这个优化主要包括以下三部分:首先是TreePattern,它是一个枚举值,不管是表达式、还是逻辑计划,它都会匹配对应的模式去实现;第二是TreePatternBits,是一个可以便于TreePattern快速查找的数据结构;第三是带有裁剪功能的Transform函数。
3.TreePattern

TreePattern是一个用Scala实现的枚举类模板,实际的枚举类会非常多,但本次为了介绍方便,只列举了几个枚举值。例如AGGREGATE_EXPRESSION,它跟在Spark表达式里面很重要的聚合表达式相关。如果表达式里面包含别名,那就会用到ALIAS。再比如上文列举的and逻辑运算表达式,这里也会有AND和and表达式相对应。
本次分享的最后会具体介绍EXPRESSION_WITH_RANDOM_SEED枚举值。
4.TreePatternBits

这个接口的出现是为了能够快速地帮助一个树形结构(不管是逻辑计划的树,还是一个表达式的树)与具体的Treepattern进行匹配校验。从这个trait的代码可以看到它里面用了 BitSet 这个通过位运算来进行快速判别的数据结构。实际上每个TreePattern本身都有一个ID属性,可以通过ID来进行判定。比如这里有三个方法,第一个方法叫containsPattern,这个方法的作用就判定当前这棵树有没有某个pattern,如果有这个pattern 才会处理。比如刚介绍的ResolveRelations,它肯定会有与relation相关的pattern,只有找到逻辑树里面与relation对应的pattern之后,才会进一步去执行规则。
当然,有些条件可能比较苛刻,比如像优化器层做优化,有Limit算子(字面上可以理解为SQL里的limit)、Sort算子(字面上可以理解为SQL里的order by)。 当order by 加 limit 同时出现时,就能应用很多优化规则。如果只有limit出现,或者只有order by 出现,那它就不需要应用这个规则。所以第二个方法叫containsAllPatterns,当同时满足多个pattern时,或者可以理解为通过它快速判断语法树同时有多个节点时,才会去应用某个规则。
第三种方法是containsAnyPattern,当出现任何一种情况时,就可以应用某个规则。
据我理解,上面提到的Limit算子、Sort算子、Aggregation算子以及各种各样的表达式在Spark 3.2.0之后,绝大部分或者说全部都已经实现了这个特质。
5.带有裁剪功能的Transform函数

上文讲resolveOperators方法的时候,它里面默认是调用resolveOperatorsDown,这是Spark 3.2.0之前的方法,而现在已经换成了resolveOperatorsWithPruning,虽然还没有体现遍历树的方式,也没有说是深度还是广度,但已经开始去调用这个带有裁剪功能的解析操作了。可以看到resolveOperatorsWithPruning里面默认调用了resolveOperatorsDownWithPruning,从深度遍历和广度遍历的角度来说,这个逻辑还是不变的,只不过它替换成了带有裁剪功能的一个新的实现或者调用而已。同样resolveOperatorsUp也替换成了resolveOperatorsUpWithPruning。 这样也是为了兼容Spark之前的老版本,以确保用户升级到SPARK 3.2.0后原来生产的代码也可以正常执行,保证用户的可迁移性。
6.resolveOperatorsDownWithPruning

以resolveOperatorsDownWithPruning为例来深入的剖析裁剪具体是怎么做到的,为什么要裁剪?之前有提到在Spark 3.2.0之前,不管语法树跟某个规则有没有关系,规则都会应用一遍,因此浪费了大量CPU时钟。
而从resolveOperatorsDownWithPruning的代码来看,这个方法的签名带有一个condition,这个condition就是以TreePatternBits特质为入参,也可以认为这里传递进来的是一个逻辑节点或一个逻辑计划树,然后返回一个布尔值。 就是说condition会判定一棵树符不符合这个规则,是否需要把这个规则应用到这棵树上,代码中cond.apply(self) 意思是应用到它自己,把规则本身作为参数传递给一个匿名函数,传递完之后,TreePatternBits来判断到底有没有符合这个树的TreePattern。只有在符合了这个条件之后,才会进到最外层if 的框里,接下来后面还有一个isRuleIneffective,进入这个方法体之后,它会对里面的叶子节点进行处理,即调用resolveOperatorsDownWithPruning,处理完之后,再一层一层地往里调用。可以理解为把整个树的子树一层一层的传递给resolveOperatorsDownWithPruning。
所以基于现在这个逻辑,所有的树和子树都会被传递,但不一定会应用某个规则,而之前就是什么都不管就直接开始执行分析规则,这就是它们优化前后的区别。
7.resolveOperatorsUpWithPruning

resolveOperatorsUpWithPruning方法和resolveOperatorsDownWithPruning其实大同小异,都是通过condition或者说实现了treepatternbits特质的逻辑计划节点来作为入参,然后来判断每个pattern是否满足规则。
以上两个方法的介绍中,没有对代码中的 isRuleIneffective(ruleId) 和markRuleAsIneffective(ruleId) 进行介绍,其实它们跟模式匹配这种裁剪的方式在思想上是类似的,它们能够进一步帮助处理裁剪的规则,只不过方法实现上有所区别。这两个就留给感兴趣的读者自己去看看它们的实现。
8.优化后表达式树的转换

上面着重讲了resolve裁剪的实现,其对应的表达式也有相应的变化,比如左侧这三个新的函数或者接口都带有WithPruning。表达式的优化也是类似的,根据之前对逻辑计划的裁剪优化的分析,相信看懂它不会有什么问题,感兴趣的读者可以去看看它的实现过程。
9.RevolveRandomSeed
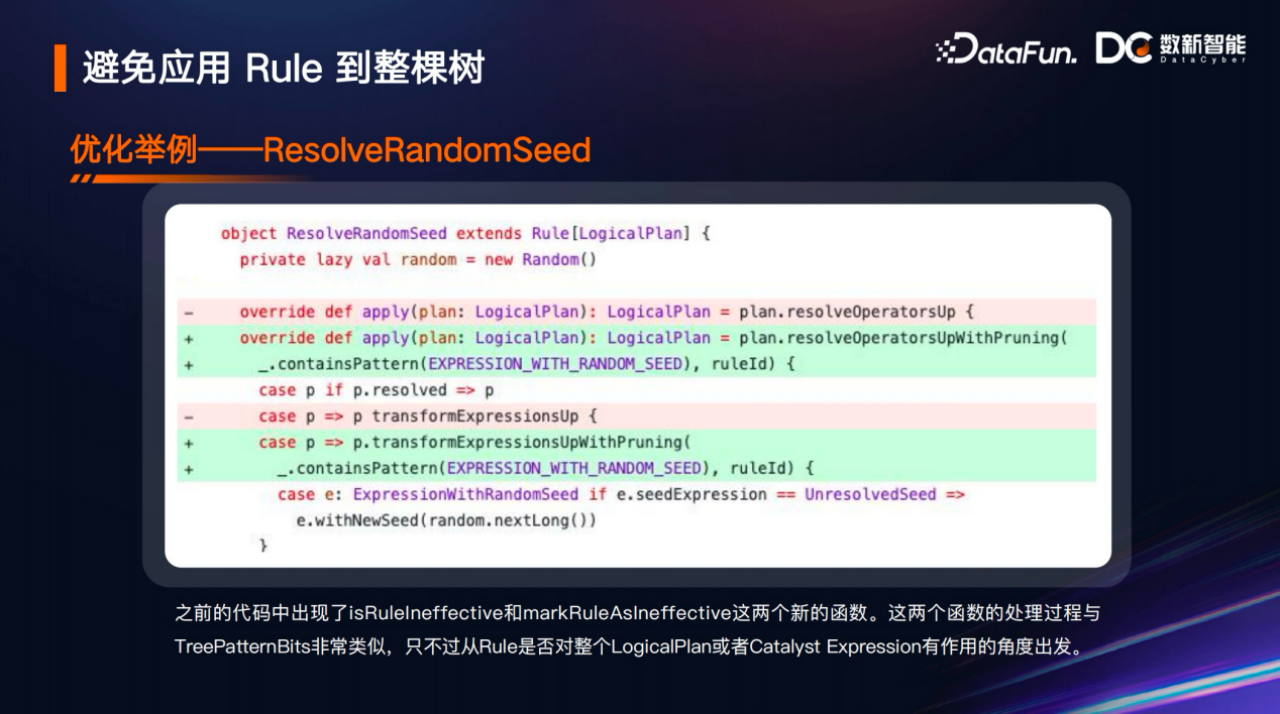
上面给大家分享了本次优化带来的三个新的组件,一是TreePattern枚举类,二是TreePatternBits特质,可以快速判别一个逻辑计划节点跟某一个规则是否匹配的一个接口,三是增加了一批便利的带有裁剪功能的转换实现。那么这三者最后是怎么应用到一起呢?我从Spark的源码中挑了一个逻辑较为简单的RevolveRandomSeed规则来讲解。
从这个规则的名字可以看到它是一个解决随机种子表达式的特殊分析处理规则。从这个分析规则的代码中可以看到,它把之前的resolveOperatorsUp方法替换成为了带有裁剪功能的resolveOperatorsUpWithPruning,同时传递参数的时候,调用了containsPattern,这个contentsPattern就是上面提的那个数据结构特质里面用于快速判别一个逻辑计划跟一个模式是否匹配的数据结构,通过它来快速判断这个逻辑计划里面包不包含EXPRESSION_WITH_RANDOM_SEED模式。如果包含了,才会走里边的逻辑,如果不包含,那么就直接返回,不会有过多的消耗。
再往下看就是针对逻辑计划的介绍,可以看到进入这个分析规则的内部,以前的transformExpressionsUp现在也替换成了带有裁剪功能的transformExpressionsUpWithPruning,并调用了containsPattern的方法来进行判断。
以上这个例子我相信已经足够简单的让大家去理解Spark 3.2.0版本带来的分析层、优化层的重大优化。
►►►
总结

以上就是本次分析层的介绍。最后这个标题叫Stop earlier without traversing the entire tree,感兴趣的读者可以去Spark官网查看其详细内容,在此不做展开介绍。
►►►
Q&A
**Q1:**在实际应用中应该如何监控和调试 Spark SQL 查询计划,以确保 ResolveRelations规则的正确执行?
**A:**ResultRelations是Spark分析器里很重要的一个分析规则,它能分析relation对应的这个文件包括哪些信息,这些都是Spark社区经过了大量增强的一个很健壮的东西。 怎么监控它能正确执行?假如它不能够正确执行,那可能就是Spark的bug 了,可以反馈给Spark社区,让Spark社区去解决。
**Q2:**逻辑计划算子树规则应用的优化效果,在批处理的背景下,用户应该是无感知的吗?
**A:**针对用户的SQL场景,大多数情况下用户肯定是无感知的,因为这块优化毕竟只是针对逻辑计划进行的优化,逻辑计划优化带来的性能提升可能没有针对物理算子进行的优化带来的提升那么明显,但是也不全然如此。比如说用到一些服务化的Spark的时候,如HiveThriftServer2,Kyuubi等长运行周期的服务,如果它要处理的SQL并发很高,且用户的SQL本身又很复杂,那么这种优化用户应该还是有感知的。
**Q3:**同样的数据量和运算量,用Spark做离线批量计算,用Flink做实时流计算,能节省多少资源,资源主要是节省在哪些地方?
**A:**我觉得节约最主要还是离线批量计算本身带来的优势。例如网络传输消息,从时效性来说,如果只传输一条信息,它会立即去传输,时效比较快,而从整个批量的角度来说,每传一个消息,就有一个数据包,这些消息加起来的数据量实际上比成批去传输的数据量要更大,如果网络的连接不是长连接而是短连接,还要大量的在连接建立方面的开销。所以Spark或者Hive批处理场景的诞生就是为了提高数据执行的处理效率,包括节省计算资源、提高数据的吞吐量等。从这个角度来说,按Filnk现在的发展也可以按批去处理一些数据,并不是来一条消息就立马下发的模式,实际上它现在也有消息的缓存,不管它是发送端还是接收端,都有缓存队列这种类似批的概念。当然具体的资源节省可能还是需要用实际的数据进行测试,以上只是偏理论的分析。
**Q4:**逻辑计划优化,除了常见的谓词下推、列剪裁、常量累加,还有哪些优化?
**A:**其实优化是非常多的,比如你刚刚说的谓词下推,还有Project 下推、聚合下推。而常量,除了你说的那种常量之外,还有对random表达式进行比较运算的优化,Limit下推、Limit和Sort这种top n场景的优化,对规则的重写优化等等。
▌公司简介
浙江数新网络有限公司是一家专注于多云数据智能平台和数据价值流通的服务商。公司总部位于杭州,在上海、北京、深圳等各地设有分支机构,服务网络覆盖全国各区域,客户遍布全球 50+ 城市。数新智能自成立以来就在人工智能领域进行了深入的探索,已有成熟的产品、基于场景的解决方案及不同行业的成功案例。帮助金融、能源电力等行业相关企业实现数字化、智能化转型,提升企业新质生产力。
数新智能自主研发的一站式多云数据智能平台,主要包括赛博数智引擎 CyberEngine、赛博数据平台 CyberData、赛博智能平台 CyberAI,可提供基于大数据的大模型调优、深度学习、价值流通等多种服务。数新智能自主研发的赛博数智引擎 CyberEngine 基于开源开放的设计理念,兼容开源引擎并进行深度优化,开放式架构支持主流引擎生态,支持多元异构引擎灵活插拔,支持流批一体、湖仓一体、数智一体等场景化能力。在此基础上,CyberEngine 以 Spark、Flink 作为主计算引擎,以 Spark 为例,基于 Spark 实现数新智能的流批引擎、统一查询引擎,在性能、稳定性、云原生化等方面全面优于社区开源版本。
▌数新网络高级架构专家 Spark Committer
耿嘉安
2014 阿里巴巴御膳房主力开发
2016 软件开发&大数据开发,出版畅销书籍《深入理解 Spark 》
2016 艺龙网大数据架构师,主导开发大数据平台
2017 360大数据专家,出版畅销书籍《 Spark 内核设计的艺术》
2018 360高级大数据专家,主导开发XSQL查询平台
2020 麒麟高级性能专家,主导 Kylin 执行引擎加速
2024 数新网络高级架构专家