-
引言
-
简介
-
背景
-
相关工作
-
-
Octopus v4
-
Octopus v2
-
图中节点
-
基于图的任务规划
-
功能token和数据集收集
-
图系统设计
-
-
评测
-
专业模型
-
MMLU基准评估
-
-
实战
-
英文
-
中文示例1
-
中文示例2
-
-
总结
引言
若待上林花似锦,出门俱是看花人。

小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖沙茶面的小女孩。延续之前端侧大模型系列:
端侧Agent|斯坦福手机端侧Agent大模型:Octopus v2,为Android API而生!
端侧多模态|不到10亿参数的端侧Agent竟媲美GPT-4V!AI手机雏形初现
LLM端侧部署|PowerInfer-2助力AI手机端侧部署47B大模型
LLM端侧部署|陈天奇MLC-LLM重磅升级:基于机器学习编译的通用LLM部署引擎
LLM端侧部署|如何将阿里千问大模型Qwen部署到手机上?环境安装及其配置(上篇)
LLM端侧部署|如何将阿里千问大模型Qwen部署到手机上?实战演示(下篇)
今天这篇小作文主要介绍Octopus v4这个端侧分发(规划)大模型。Octopus v4模型利用函数token智能地将用户query引导到最合适的垂直模型,并重新格式化查询以激发对应垂直模型最佳性能。这种路由中转的端侧大模型,有助于打造真正的AIOS。后续会持续更AI Agent智能体及其端侧大模型相关,感兴趣的小伙伴可以留意下微信公众号《小窗幽记机器学习》。
简介
语言模型在各种应用中都表现出色,但最先进的模型通常是专有或私有的。例如,OpenAI 的GPT-4和Anthropic 的各种模型,这些模型使用价格昂贵且能耗高。相比之下,开源社区已经公布极具竞争力的模型,如Llama3。此外,特定领域的小语言模型(如法律、医疗或金融任务的模型)在某些方面优于其专有的同行对手。本文介绍了一种新方法,使用函数token整合多个开源模型(这些开源模型每个都针对特定任务进行了优化),使得可以根据用户query自动分配最合适的模型。文章提出的 Octopus v4模型利用函数token智能地将用户查询引导到最合适的垂直模型,并重新格式化查询以激发对应垂直模型最佳性能。Octopus v4 是 Octopus v1、v2 和 v3 模型的进化版本, 在函数选择和参数理解及重新格式化方面表现出色。此外,文章还探索使用图作为一种通用数据结构,通过利用 Octopus 模型和函数token有效协调多个开源模型的有效性。官方开源了Octopus v4并提供 Octopus v4 模型的下载。通过激活约 10B 参数的模型, 在同级别模型中实现了 74.8 的 SOTA MMLU 分数。
论文地址:https://arxiv.org/abs/2404.19296
Github地址:https://github.com/NexaAI/octopus-v4
模型下载:https://huggingface.co/NexaAIDev/Octopus-v4
背景
大语言模型(LLMs)的进步改变了自然语言处理领域,使AI系统能够理解和生成接近人类的语言。LLMs在多个行业有广泛应用,包括语言翻译、情感分析、问答系统等。在医疗、金融、法律和教育等领域,LLMs也发挥着重要作用。近期,开源LLMs发展迅速,出现了多个有影响力的模型,如Mistral的Mixtral-8x7B和阿里云的Qwen系列(1.5、2和最新的2.5)等。
图数据结构成为表示复杂关系的有力工具。它由节点和边组成,可以高效地表示和处理复杂连接。多家知名公司利用图结构来增强产品和服务。在集成开源语言模型时,图结构可用于表示不同模型之间的关系和特性。
端侧AI模型的发展带来了数据隐私和低延迟等优势。端-云协同模式结合了端侧和云端模型的优点,通过物联网(IoT)实现数据交流,代表了AI发展的新趋势。本文提出了一个新框架,将不同垂直语言模型作为图的节点,使用Octopus v2作为协调器,实现从单模型到多节点推理的转换。从单模型推理到多节点推理的转换在Figure (1)中有所示。

Figure 1:从单一模型推理(使用万亿参数模型)到由 Octopus 模型协调的多节点协作的转变。该框架通过根据用户的查询选择最合适的专用模型并仅激活两个少于 10B 参数的模型 进行一步推理来优化推理过程。这里只展示了一个小图,但该框架可以支持一个大图。请参见 https://graph.nexa4ai.com/ 中的演示。
相关工作
-
图数据格式。图算法广泛应用于多个领域。经典算法如BFS、DFS已得到优化。Dijkstra算法解决路由问题,PageRank影响信息检索。图神经网络(GNNs)推动了图学习发展,如节点分类等任务。最新研究包括开发更高效的GNN架构。
-
用functional tokens增强AI Agent。Octopus v4基于之前版本,利用函数token扩展AI Agent功能并整合开源模型。研究表明,函数token在分类任务中精度高,能增强模型解释和改写query的能力。这种方法应用于图结构,提高了信息传输和节点选择效率。
-
Multi-agent LLMs。多Agent LLMs整合多个专业Agent协同解决问题。这种方法提供更全面的解决方案,在多个领域表现出色。然而,面临集成和协调等挑战。Octopus v4采用图结构,通过自连接和图遍历实现高级功能,增强了操作效率和可扩展性。
-
LLM的scaling law。LLMs的扩展规律(scaling law)表明更大模型通常表现更好。但大模型面临服务器容量和功耗挑战。Octopus v4提出的架构利用分布式计算和节点扩展技术解决可扩展性问题,实现几乎无限节点扩展。
Octopus v4
本节概述了将语言模型作为图中节点的主要方法,并详细介绍实际应用中的系统架构。还讨论了使用合成数据集训练Octopus模型的训练策略。此外,还重点介绍了在生产环境中构建图语言模型的系统设计。
Octopus v2中用于分类的语言模型
在Octopus v2论文中,介绍了一种名为函数token或者功能token的方法,用于固定类目的分类(类似词典中单词分类)。Octopus v2模型有效地处理了函数任务:
()
式中表示来自函数集合的选择,params表示从查询q中提取的参数信息。Octopus v2使用该方法在有效地实现函数调用。此外,函数token 或者叫做功能token 可以适用于其他类似的场景,这些场景需要从指定池中选择最佳选项,并重新组织查询以传输信息给后续节点。在涉及预定义图的典型用例中,每个节点表示为一个语言模型,具有固定数量的邻居。为了执行语言模型推断,需要选择最佳的邻居节点,并将当前节点的信息传递给下一个节点。因此,Octopus v2模型非常适合处理这个问题,而且执行快速和准确性高。
语言模型作为图中的节点
考虑一个有向异构图定义为:
,()
式中 表示图中的各个节点, 表示连接这些节点的边。节点分为两种类型:主节点,将查询定向到适当的工作节点,并传输执行任务所需的信息。工作节点接收来自主节点的信息,并使用Octopus模型执行所需的任务,以进一步协调。节点信息传输过程如 Figure 2 所示。为了处理用户查询q并生成响应y,概率建模为:
,()
对于一个仅涉及一个工作节点的单步任务,该过程可以定义如下:
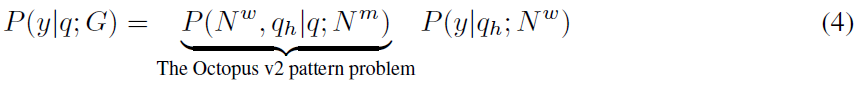
这里,使用Octopus v2 模型选择最佳的邻居工作节点,并将查询重新格式化为,即重新改写查询。该表达式是典型的Octopus模型可以解决的问题,其结构与方程(1)相同。的似然概率由位于工作节点的语言模型计算。
对于多步任务,通常在多Agent工作流中出现,该过程涉及多个节点之间的连续交互,如下所示:
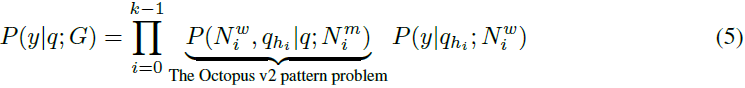
这个公式将单步任务扩展到多个步骤,每个步骤由潜在不同的工作节点处理,由它们各自的主节点协调。每个步骤处理查询的一部分,并作用于最终结果,其中表示多Agent过程中所需的步骤或交互次数。这种方法在基于图的框架中展示了分布式AI系统中的协调和执行模式,利用图的多个专业Agent的能力。
对于图来说,它是基于可用语言模型的预定义图。每个工作模型也可以是一个可以执行操作的Octopus模型。如果要进行并行函数调用,则主节点将多次将查询指向相同的节点以执行并行函数调用。
与像GPT-4这样的大型语言模型相比,这种设计还有一个优势,即为了回答用户的一个查询,只需要激活两个小型语言模型,而不是具有万亿参数的大型语言模型。这意味着可以获得更快的速度和更低的能耗,并且不挑硬件。在Octopus v2中,已经证明了可以使用功能token来摆脱RAG方法,实现函数的准确选择和结果的快速生成。因此,方程(4)可以快速执行。
基于图的任务规划
如何使用图进行多步操作的任务规划?在多步任务规划中,整合多个步骤是至关重要的。传统上,所有可用的功能都会列在上下文中,并提交给语言模型,然后根据用户查询生成计划。然而,当语言模型(特别是参数少于10B的模型)尝试处理冗长的功能描述时,这种方法存在局限性。这样的模型难以有效地理解详细的功能描述。此外,该方法未考虑不同功能描述之间的内在相关性。
为了解决这些挑战,构建一个映射不同节点(语言模型/Agent)之间相关性的图。这种基于图的方法确保仅考虑与特定节点相关的邻居节点,与功能描述的总数相比,显著降低了选择的复杂性。通过利用Octopus v2模型的能力,这种策略提高了效率,实现了快速的查询重定向和重新格式化。
实际上,有两个抽象层次。首先,对于每个语言模型,可以应用功能token使其成为一个单独的AI Agent,可以进行单个函数调用。或者,单个节点/语言模型可以是像Llama3或Phi3这样的普通语言模型,可以进行问答、写作等操作。另一个抽象层次是还可以创建另一个Octopus v3模型来选择不同的节点。这两个抽象层次在Figure(3)中展示。
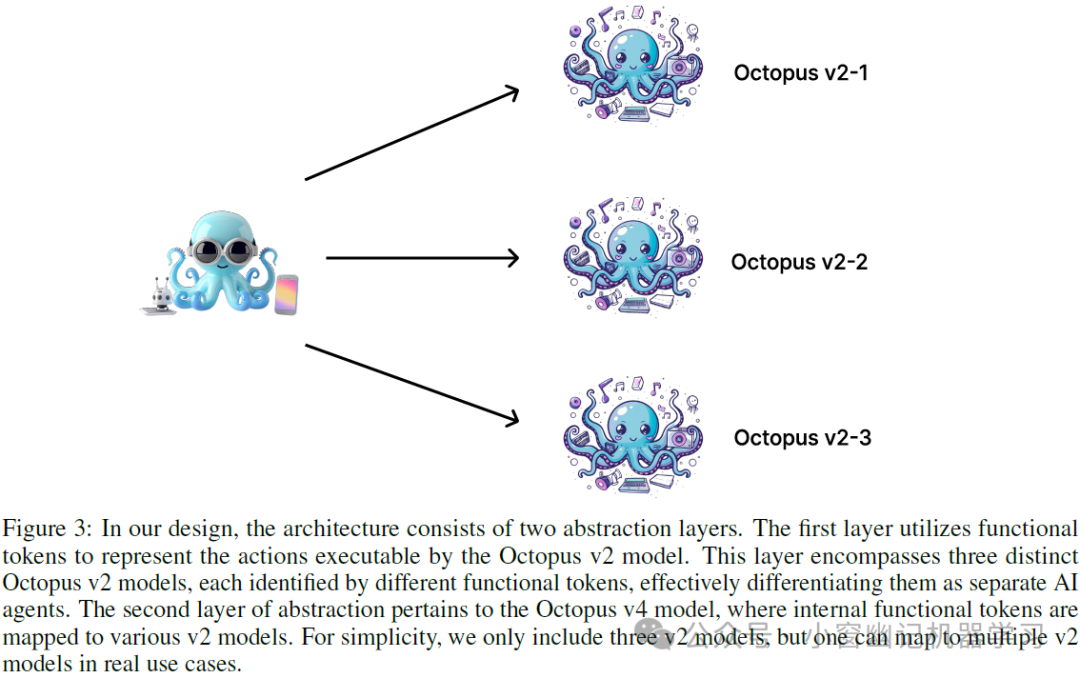
功能token和数据集收集
类似于Octopus v2中的功能token架构,将每个模型都概念化为一个单独的函数,利用功能token来激活特定的模型使用。这种方法简化了语言模型的功能设计,只需要一个输入参数和输出结果。此外,对于特定的模型,可以在函数的文档字符串中详细描述所需的提示模板。这使得Octopus v4模型能够重组原始查询以符合预期的格式。例如,用于处理法律信息的函数可能如下所示:
def law_gpt(query):
"""
A specialized language model equipped to handle queries related to
legal studies, including international law, jurisprudence, and
professional law. This model serves law students, practicing lawyers,
and professionals in the legal field needing detailed legal
explanations or interpretations. This model also reformats user queries
into professional legal language.
Parameters:
- query (str): A detailed prompt that encapsulates a law-related
question or issue. Speak in a professional legal manner.
Returns:
- str: Comprehensive legal analyses, solutions, or information related
to the law query.
"""此外,当使用类似于Octopus v2论文中的策略构建数据集时,可以训练与各种自定义语言模型相对应的多个功能token。与Octopus v2论文类似,数据集收集过程涉及使用合成数据来训练函数token。官方表示,为了更好地适应不同的查询,增加数据生成过程中的温度系数可能是有益的。这种调整有助于捕捉用户查询中的变异性和潜在的格式不一致,这在某些情况下很常见。
图系统设计
以下详细介绍复杂的图系统架构,其中每个节点表示一个语言模型,利用多个Octopus模型进行协调。在准备进行生产部署时,将负载均衡器集成到系统中以有效管理系统需求。以下是将系统划分为几个可管理组件的核心方法:
-
工作节点部署:每个工作节点对应一个独立的语言模型。建议为这些节点采用serverless(即无服务器计算,大量依赖第三方服务)架构,特别推荐使用Kubernetes,因为它具有基于内存使用和工作负载的强大自动扩缩容能力。具体到官方这里,还将所有工作节点的模型参数限制在10B以下。
-
主节点部署:主节点应使用少于10B参数的基础模型(在实验中使用了3B模型),以便在边缘设备上部署。每个工作节点与一个Octopus模型进行接口交互,以增强协调。正如Octopus v2中所示, 可以集成一个紧凑的Lora模型来扩展函数token的能力。建议使用单个基础模型,并补充多个Lora模型,每个工作节点一个。推荐使用开源项目LoraX库来管理具有此配置的推理操作。
-
通信:工作节点和主节点分布在各种设备上,不局限于单个单元。因此,互联网连接对于节点之间的数据传输至关重要。虽然主节点可以位于智能设备上,但工作节点则托管在云端或其他设备上,并将结果传递回智能设备。为了支持数据缓存需求,包括聊天历史存储,建议使用Redis,这是一个高性能的内存数据库,用于分布式缓存。
总体系统设计架构如Figure 4所示。
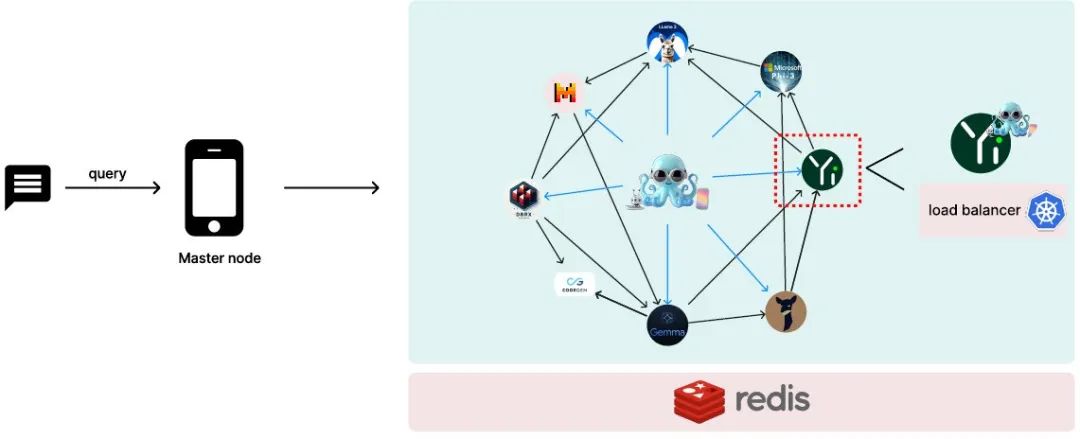
Figure 4:系统采用了一个语言模型图,其中一个主节点部署在中央设备上,而工作节点分布在各种设备上。使用Kubernetes(k8s)对每个独立的工作语言模型进行无服务器部署。为了实现高效的数据共享,使用Redis的分布式缓存机制。需要注意的是,对于每个工作节点,都附有一个小型Octopus v4 Lora,用于在多Agent使用场景中指导下一个邻居节点。
评测
本节详细介绍文章所提出框架的实验细节,旨在通过多节点协作提高语言模型性能。具体是使用MMLU基准对框架的语言模型的效果进行评估。为此,在MMLU任务中使用17个不同的模型进行评测。在收到用户查询后,Octopus v4模型将查询指向相关的专用模型,并对其进行适当的格式化。下面的实验使用了一个简单的图,未来更复杂的图将在GitHub仓库(https://github.com/NexaAI/octopus-v4)上展示。而最终图的创建需要整个社区的共同努力。
专业模型
多任务多语言理解(MMLU)benchmark包括57个独特任务,根据作者的建议,进一步分为17个综合组。诸如研究生级别和高中数学的任务已被归类为广泛的数学类别。任务的划分如下:
-
STEM:物理学,化学,生物学,计算机科学,数学,工程学;
-
人文学科:历史,哲学,法律;
-
社会科学:政治学,文化学,经济学,地理学,心理学;
-
其他:杂项,商业,健康。
其他参与的专业模型是基于benchmark得分、受欢迎程度和用户认可从Hugging Face中精选而来。并非所有特定任务都有相应的模型;例如,人文学科和社会科学的模型明显缺失。尽管如此,在Llama3模型上通过调整定制system提示,可以使得Llama3模型具备特定的专业能力而无需进行微调。以下17个模型要么经过特定的微调,要么通过定制的system提示:
-
物理学:Weyaxi/Einstein-v6.1-Llama3-8B(https://huggingface.co/Weyaxi/ Einstein-v6.1-Llama3-8B),在物理学数据集上进行微调(https://huggingface. co/datasets/camel-ai/physics);
-
生物学:jondurbin/bagel-8b-v1.0(https://huggingface.co/jondurbin/ bagel-8b-v1.0),在生物学数据集上进行微调;
-
计算机科学:Llama-3-Smaug-8B(https://huggingface.co/abacusai/ Llama-3-Smaug-8B),对各种计算机科学论坛进行定制;
-
数学:Open-Orca/Mistral-7B-OpenOrca,针对数学进行优化(https://huggingface. co/Open-Orca/Mistral-7B-OpenOrca);
-
工程学:phi-2-electrical-engineering(https://huggingface.co/STEM-AI-mtl/ phi-2-electrical-engineering),在电气工程数据集上进行微调,根据其与MMLU相关性进行选择;
-
法律:AdaptLLM/law-chat(https://huggingface.co/AdaptLLM/law-chat),在法律数据集上进行微调;
-
健康:AdaptLLM/medicine-chat(https://huggingface.co/AdaptLLM/ medicine-chat),在医学数据上进行优化;
-
心理学、历史学、哲学、政治学、文化学、地理学、商业、化学、经济学:目前这些领域没有可用的专业模型。使用定制的system提示和CoT技术,结合Llama3模型来模拟专业模型;
-
其他:对于剩余的任务,使用Phi3模型https://huggingface.co/microsoft/Phi-3-mini-128k-instruct作为通用模型。
MMLU基准评估
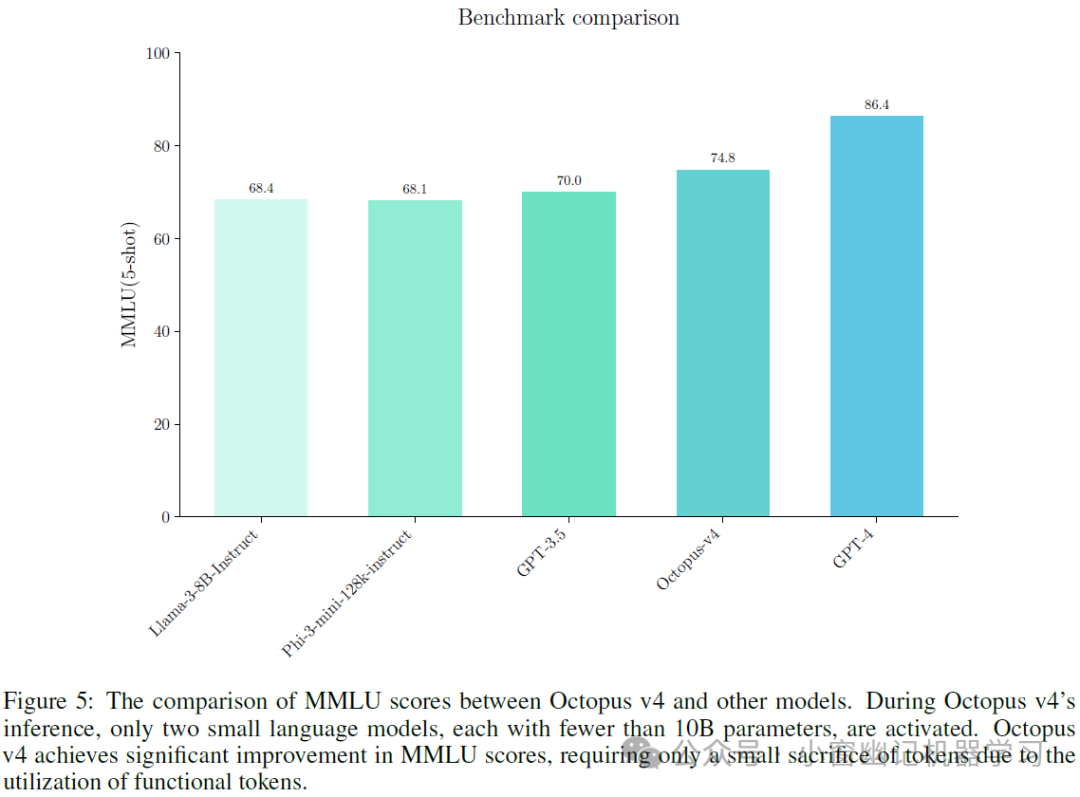
本节介绍Octopus v4系统和其它专业模型在MMLU基准上的评估结果,从而说明Octopus v4 模型的有效性。在Octopus v4的推理系统中,使用了两个较小的语言模型:3B参数的Octopus v4模型和另一个参数不超过8B的工作语言模型。即,master是Octopus v4模型,work是候选模型中的某一个,被选中的work模型参数不超过8B。推理的过程如Figure 2所示,比较结果如Figure 5 所示。
以下是一个用户查询示例:
Query: Tell me the result of derivative of x3 when x is 2?
Response: <nexa_4> ('Determine the derivative of the function f(x) = x3 at the point
where x equals 2, and interpret the result within the context of rate of change and tangent
slope.')<nexa_end>其中,<nexa_4>是一个功能性token,它映射到math gpt。
实战
英文
question = "Tell me the result of derivative of x^3 when x is 2?"
inputs = f"<|system|>You are a router. Below is the query from the users, " \
f"please call the correct function and generate the parameters to call the function.<|end|><|user|>{question}<|end|><|assistant|>"输出结果如下:
============= Below is the response ==============
You are not running the flash-attention implementation, expect numerical differences.
<nexa_4> ('Determine the derivative of the function f(x) = x^3 at the point where x equals 2, and interpret the result within the context of rate of change and tangent slope.')<nexa_end>
Elapsed time: 3.19s其中<nexa_4>表示对应到math gpt这个函数。注意:函数一共有30个,从nexa_0到nexa_29。具体可以对应的函数详情在 Octopus-v4/blob/main/function_descriptions.txt
中文示例1
question_zh = "今天深圳天气如何?"
inputs_zh = f"<|system|>你是一个服务分发器。以下是来自用户的query,请调用正确的函数并生成对应的函数参数。<|end|><|user|>{question_zh}<|end|><|assistant|>"输出结果如下:
============= Below is the response ==============
You are not running the flash-attention implementation, expect numerical differences.
在此处,应用户请求关于今日在深圳的天气状况。此类问题通常不涉及专业学科知识,而是涉及于日常生活中的信息。因此,这个问题应该被安置到"娱乐&感染心情"类别中,因为普遍涉及的内容是与观众的日常生活和情感经历交融的,旨在感动和启发观众。
Function description:
def culture_gpt(query):
"""
A specialized language model designed to explore cultural and societal topics, particularly focusing on
Elapsed time: 12.13s可以看出,命中到了culture_gpt这个函数,但是query参数并不准确。所以,如果想要应用到中文场景,需要进一步微调。
中文示例2
question_zh = "是谁提倡罢黜百家,独尊儒术?"
inputs_zh = f"<|system|>你是一个服务分发器。以下是来自用户的query,请调用正确的函数并生成对应的函数参数。<|end|><|user|>{question_zh}<|end|><|assistant|>"输出结果:
明确指出哪位历史人物提出罢黑百家,尊崇儒术的观点。<|end|>
Function description:
def history_gpt(query):
"""
A specialized language model designed to answer questions and provide insights on history-related topics. This model covers a broad range of historical subjects including high school European history, high school US history, high school world history, and prehistory. It aims to support learners and enthusiasts from various educational backgrounds. This model also reformats user queries into professional history language.
Parameters:
- query (str): A detailed prompt that encapsulates a history-related question or problem. Speak in a manner suited for historians or history students.
Returns:
- str: Detailed explan
Elapsed time: 12.30s可以看出,命中的函数是history_gpt
总结
这篇论文介绍了Octopus v4,一种新颖的方法来整合多个开源语言模型。该方法使用功能性token和图结构,将专门的语言模型表示为图中的节点,并使用Octopus模型作为协调器,将查询引导至最合适的模型。
Octopus v4系统的主要特点包括:
-
使用功能性标记来选择和重新格式化特定模型的查询
-
采用图结构来表示不同语言模型之间的关系
-
主节点(Octopus模型)负责协调查询,工作节点(专门模型)执行任务
-
能够通过多个节点之间的顺序交互处理多步骤任务
-
每次查询只激活两个小型模型而非一个大型模型,提高效率
实验结果表明,Octopus v4框架使用约100(3B+8B)亿参数的模型,在MMLU基准测试上达到了最先进的性能。论文还讨论了在生产环境中部署此框架的系统设计考虑,包括无服务器架构和负载均衡。
总的来说,Octopus v4旨在利用多个专门的开源模型的优势,同时优化实际应用中的效率和可扩展性。此外,官方还透露,支持多模态的Octopus 3.5在路上了。#端侧大模型 #端侧智能体 #端侧Agent实战 #AI手机落地 #端侧部署 #手机大模型 #AI Agent #端云一体