在深度学习训练过程中,学习率调度器扮演着至关重要的角色。这主要是因为在训练的不同阶段,模型的学习动态会发生显著变化。
在训练初期,损失函数通常呈现剧烈波动,梯度值较大且不稳定。此阶段的主要目标是在优化空间中快速接近某个局部最小值。然而,过高的学习率可能导致模型跳过潜在的优质局部最小值,从而限制了模型性能的充分发挥。
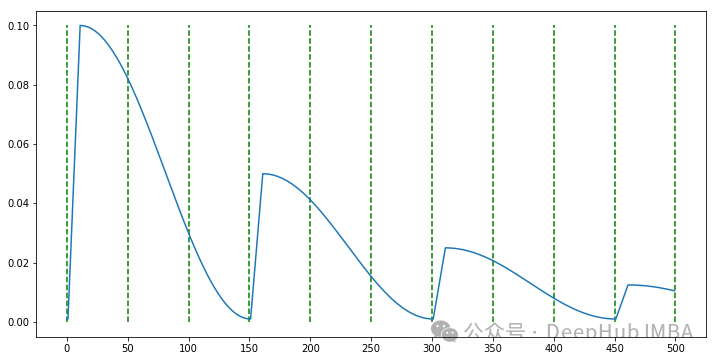
尽管PyTorch提供了多种预定义的学习率调度器,但在特定研究场景或需要更精细控制时,这些标准实现可能无法完全满足需求。在这种情况下,实现自定义学习率调度器成为了一个可行的解决方案。
本文将详细介绍如何通过扩展PyTorch的
LRScheduler类来实现一个具有预热阶段的余弦衰减调度器。我们将分五个关键步骤来完成这个过程。
1、继承LRScheduler类
在PyTorch中实现自定义学习率调度器时,首先需要继承
torch.optim.lr_scheduler.LRScheduler类。这个基类提供了管理学习率调度所需的核心功能。
通过继承
LRScheduler,我们可以利用以下关键特性:
self.optimizer:对优化器的引用,用于调整其学习率。self.base_lrs:存储优化器中所有参数组的初始学习率,可在自定义调度器中进行访问和修改。self.last_epoch:跟踪当前训练轮次,用于根据轮次数调整学习率。step()方法:在每个训练轮次后调用,用于自动更新学习率。- 参数组处理:
LRScheduler设计支持优化器中的多个参数组,允许对模型的不同部分应用不同的学习率调整策略。
以下是继承
LRScheduler的基本代码结构:
fromtorch.optim.lr_schedulerimportLRScheduler
classCosineWarmupScheduler(LRScheduler):
pass通过继承
LRScheduler,我们获得了上述所有功能,只需要通过实现
get_lr()方法来定义学习率的具体变化逻辑。
2、实现构造函数
在自定义学习率调度器中,构造函数(
__init__方法)用于初始化调度器的关键参数。这些参数定义了学习率调整的具体策略,包括预热期的长度、总训练轮次和最小学习率等。
以下是构造函数的实现示例:
classCosineWarmupScheduler(LRScheduler):
def__init__(self, optimizer, warmup_epochs, total_epochs, min_lr=0.0, last_epoch=-1):
self.warmup_epochs=warmup_epochs # 学习率线性增加的预热轮次
self.total_epochs=total_epochs # 总训练轮次
self.min_lr=min_lr # 学习率下限
super(CosineWarmupScheduler, self).__init__(optimizer, last_epoch)参数说明:
optimizer:PyTorch优化器实例,其学习率将被调整。warmup_epochs:预热阶段的轮次数,在此期间学习率线性增加。total_epochs:训练的总轮次,包括预热阶段和衰减阶段。min_lr:学习率的下限,衰减阶段的最终学习率不会低于此值。last_epoch:上一轮的索引,用于恢复训练。默认为-1,表示从头开始训练。
3、调用父类构造函数
在自定义调度器的构造函数中,通过
super()调用父类(
LRScheduler)的构造函数是非常重要的。这确保了基类被正确初始化,使我们能够访问诸如
self.optimizer、
self.base_lrs和
self.last_epoch等关键属性。
super(CosineWarmupScheduler, self).__init__(optimizer, last_epoch)这行代码不仅初始化了基类,还使得自定义调度器能够继承
LRScheduler的其他有用方法,如
step()和
get_last_lr()。
4、实现get_lr()方法
get_lr()方法是自定义调度器的核心,它定义了学习率如何随训练轮次变化的具体逻辑。在本例中,我们实现了一个包含预热阶段的余弦衰减调度策略:
预热阶段:在前
warmup_epochs轮中,学习率从0线性增加到初始学习率。
余弦衰减阶段:预热结束后,学习率按余弦函数从初始值衰减到最小值。
以下是
get_lr()方法的实现:
importmath
classCosineWarmupScheduler(LRScheduler):
def__init__(self, optimizer, warmup_epochs, total_epochs, min_lr=0.0, last_epoch=-1):
self.warmup_epochs=warmup_epochs
self.total_epochs=total_epochs
self.min_lr=min_lr
super(CosineWarmupScheduler, self).__init__(optimizer, last_epoch)
defget_lr(self):
epoch=self.last_epoch+1
ifepoch<=self.warmup_epochs:
# 预热阶段:线性增加学习率
return [base_lr*epoch/self.warmup_epochsforbase_lrinself.base_lrs]
else:
# 余弦衰减阶段
decay_epochs=self.total_epochs-self.warmup_epochs
cosine_decay=0.5* (1+math.cos(math.pi* (epoch-self.warmup_epochs) /decay_epochs))
return [self.min_lr+ (base_lr-self.min_lr) *cosine_decayforbase_lrinself.base_lrs]这个实现确保了学习率在预热阶段平滑增加,然后在剩余的训练过程中逐渐衰减,最终达到指定的最小值。
5、在训练流程中应用自定义调度器
实现自定义学习率调度器后,下一步是将其集成到训练流程中。以下示例展示了如何在PyTorch训练循环中初始化和使用自定义调度器:
importtorch
importtorch.optimasoptim
# 定义模型(此处使用简单的线性模型作为示例)
model=torch.nn.Linear(10, 1)
# 初始化优化器
optimizer=optim.SGD(model.parameters(), lr=0.1)
# 初始化自定义学习率调度器
scheduler=CosineWarmupScheduler(optimizer, warmup_epochs=5, total_epochs=50, min_lr=0.001)
# 训练循环
num_epochs=50
forepochinrange(num_epochs):
model.train()
fordata, targetindataloader:
optimizer.zero_grad()
output=model(data)
loss=criterion(output, target)
loss.backward()
optimizer.step()
# 在每个epoch结束时更新学习率
scheduler.step()
# 记录当前学习率(用于监控)
current_lr=scheduler.get_last_lr()[0]
print(f"Epoch {epoch+1}/{num_epochs}, Learning Rate: {current_lr:.6f}")在这个示例中,我们执行以下关键步骤:
- 定义模型和优化器。
- 使用之前实现的
CosineWarmupScheduler初始化学习率调度器。 - 在每个训练epoch中:- 执行标准的前向传播、损失计算和反向传播步骤。- 调用
optimizer.step()更新模型参数。- 在epoch结束时调用scheduler.step()更新学习率。 - 使用
scheduler.get_last_lr()获取并记录当前学习率,用于监控训练过程。
关键组件说明
scheduler.step():这个方法在每个epoch结束时调用,根据当前epoch更新学习率。它是动态调整学习率的核心机制。scheduler.get_last_lr():返回当前的学习率。在多参数组的情况下,它返回一个列表,每个元素对应一个参数组的学习率。
总结
通过继承PyTorch的
LRScheduler类并实现自定义的
get_lr()方法,我们可以创建灵活的学习率调度策略,以满足特定的训练需求。本指南展示的带预热的余弦衰减调度器只是众多可能实现的一个例子。
自定义学习率调度器的关键优势在于:
- 灵活性:可以实现任何所需的学习率调整策略。
- 精确控制:能够根据训练动态和模型特性精细调整学习过程。
- 适应性:可以轻松适应不同的模型架构和数据集特性。
在实际应用中,可能需要进行大量实验来确定最适合特定问题的学习率调度策略。通过掌握自定义调度器的实现技巧,研究人员和工程师可以更灵活地优化深度学习模型的训练过程,从而潜在地提高模型性能和训练效率。
https://avoid.overfit.cn/post/aa1e90e02eb24d9f982e2c933bdd97a7