0.概述
论文地址:https://arxiv.org/abs/2404.05976
在许多制造应用中,机器学习(ML)已被证明可以提高生产率。针对制造业应用提出了一些软件和工业物联网(IIoT)系统,以接收这些 ML 应用。最近,有人提出了一种利用交互因果关系的自标注方法(SLB),以发展自适应 ML 应用。这种方法可以自动调整和个性化 ML 模型,以适应部署后数据分布的变化。自标注方法的独特功能要求新的软件系统能够在不同层面进行动态调整。
本文提出的 AdaptIoT 系统包括端到端数据流管道、ML 服务集成和自动自标注服务。自标注服务包括一个因果知识库和一个自动化、全周期的自标注工作流,可同时调整多个 ML 模型。AdaptIoT 通过容器化微服务架构为中小型制造商提供可扩展、可移植的解决方案。在创客空间对自贴标签自适应 ML 应用程序进行了实地演示,并证明了其可靠的性能。
1.介绍
将实时机器学习(ML)技术集成到网络物理系统(CPS),特别是智能制造中,需要硬件和软件平台来协调传感器数据流、ML 应用部署和数据可视化。现代制造系统利用先进的网络技术,如物联网(IoT)系统、面向服务的架构、微服务、数据湖和数据仓库等。系统可以支持和启用。
例如,Yen 等人开发了一个软件即服务(SaaS)框架,利用物联网传感器集成来管理制造系统的健康状况,从而促进数据和知识共享。Mourtzis 等人提出了一种面向中小型制造商(SMMs)的 IIoT 系统,该系统结合了大数据软件工程技术,每月可处理 TB 级数据;Liu 等人提出了一种云制造范式中的高效数据管理和云制造范式中的传输服务。云制造范式中的高效数据管理和传输,并设计了一种面向服务的 IIoT 网关和数据模式,以实现这一目标。
作者研究的主要目标是在制造业中提供个性化智能,这需要在部署后根据环境调整 ML 模型。然而,在制造环境中开发和部署个性化 ML 系统有几个障碍。例如,人工收集和注释训练数据集的成本已经减缓了人工智能增强型智能制造系统的普及速度,尤其是对中小型制造商(SMM)而言。
最近,适应不同部署环境的自适应机器学习已成为一种有效的解决方案,可降低 ML 进入 SMM 的门槛。目前已提出了几种自适应 ML 方法,包括带有伪标签的半监督学习(SSL)、懒标签和利用领域知识学习。
为了在制造网络物理系统应用中实现自适应机器学习,我们提出了一种新颖的基于因果关系的交互式自标注方法。该方法利用从领域知识中提取的因果关系来自动执行部署后的自标注工作流程,并使 ML 模型适应本地环境。自标注方法可自动实时捕获和标注数据,有效利用有限的预分配或公共数据集。
为支持和实施这种方法,需要一个系统基础设施,特别是对标准监测机制而言,它应满足以下要求
- 从异构服务和设备实时传输带有时间戳的传感器、语音和视频数据。
- 因果知识库可管理模型之间的交互,并促进因果节点之间的自标签 ML。
- 核心自标注服务可连接 ML 服务、路由数据流、执行自标注工作流以及在边缘自主重新训练和重新部署 ML 模型。
- 可扩展架构,可轻松集成新的边缘、ML 和 SLB 服务。
为了满足交互式因果关系的独特需求,需要一个新的软件系统来实现各种 ML 模型的自我标签功能。该软件系统将利用实时物联网传感器数据、ML 和自标签服务,使模型能够随着环境的变化而调整。
2.相关研究
本文的相关研究如下。
- 物联网与智能制造:Lu 和 Cecil 提出了一个基于物联网的先进制造协作框架。这将在整个制造过程中实现合作和数据共享。
- 面向服务的智能制造:Tao 和 Qi 展示了一种新的信息技术驱动的面向服务的智能制造框架及其特点。该框架可实现灵活、适应性强的制造流程。
- 微服务与制造系统:Thramboulidis 等人为制造装配系统提出了一个基于网络物理微服务和物联网的框架(CPUS-IoT)。该系统可监控整个装配线。
- 数据湖和高压压铸:Rudack 等人的研究成果这将实现对大量制造数据的高效管理和分析。
- 制造系统的监控和诊断:Yen 等人利用物联网传感器集成开发了一个制造系统监控和诊断框架。该框架促进了数据和知识共享。
- 大数据和 IIoT:Mourtzis 等人提出了一种 IIoT 系统,用于处理拥有 100 台机器的制造现场每月 TB 级数据的生成和传输。
- 云制造和物联网网关:Liu 等人设计了面向服务的物联网网关和数据模式,以促进高效的数据管理和传输。
- 数控机床与边缘-云协调:Sheng 等人提出了一种基于多模态 ML 的数控机床质量检测系统。该系统执行从边缘(传感器数据采集)到云端(深度学习计算)的协调。
- 预测性调度和云制造:Morariu 等人设计了一种端到端的大数据软件架构,用于面向服务的云制造系统中的预测性调度。
- ML 生命周期中的挑战:Paleyes 等人总结了在不同阶段部署 ML 系统所面临的挑战。
- 智能制造的网络基础设施:Davis 等人讨论了智能制造民主化的网络基础设施。
- 自适应 ML 和半监督学习:Yan 等人提出了一种用于半监督学习的无源自适应 ML 的自标注增强方法;Zhou 等人提出了一种用于对比表示学习的理论驱动的自标注细化方法;Zhou 等人提出了一种用于对比表示学习的理论驱动的自标注细化方法。
- 延迟标记和性能评估:Grzenda 等人研究了延迟标记分类中进化预测的性能指标。
- 数据编程和物理定律:拉特纳等人提出了一种快速创建大型训练集的数据编程方法;斯图尔特和埃尔蒙利用物理定律和领域知识提出了一种无标签的神经网络超级视觉他们还提出
- 自标注的好处:Ren 等人提出了一种用于制造网络物理系统自适应机器学习的自标注方法。该方法可在部署后自动执行自标注工作流程,并使 ML 模型适应本地环境。
3. 互动因果关系和自我标记方法概述
3.1 利用因果关系的自我标记方法
交互式因果关系自标注(SLB)方法是为了实现 ML 系统的自适应学习而开发的。该方法可使已部署的 ML 模型适应本地数据分布的变化,并实时执行自标注。自标注始于从领域知识和本体中提取的动态因果知识图(KG)中选择因果相关的节点。
如图 1 所示,自标注始于在动态因果知识图(KG)中选择因果节点。由于因果关系可能随时间而波动,因此所选节点与效果状态的转换相关联;SLB 监控一个或多个数据流,并观察因果事件发生的时间。
自我标示需要三种不同的模式
- 效应状态检测器(ESD):监控效应数据并检测效应状态转换。
- 交互时间模型(ITM):以效应数据为输入,预测因果时间延迟。
- 任务模型:使用因果数据作为输入特征,以效应转换为标签训练任务模型。
图 1 展示了整个自我标注程序。
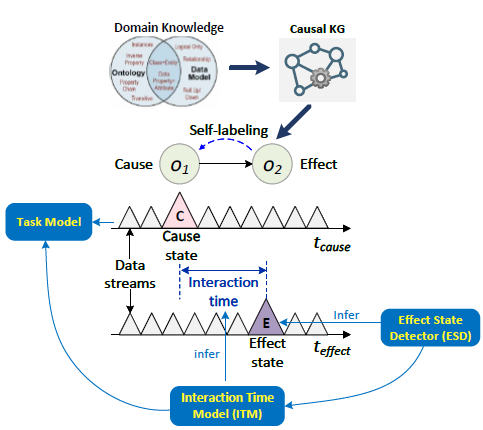
|--------------------|
| 图 1. 整个自我标注程序的示意图。 |
3.2 任务模型的持续学习
任务模型通过 SLB 不断学习。在输入和/或输出数据分布自初始训练以来发生波动的情况下,持续学习尤其有益。因果关系对数据漂移具有鲁棒性,这种鲁棒性延续到自标记方法中,并为持续学习提供了基础;SLB 将因果数据与效果状态转换联系起来,并以此训练任务模型,而无需人工干预。
3.3 系统基础设施要求
为支持和实施 SLB 方法,需要一个系统基础设施,特别是针对中小型制造商 (SMM) 的系统基础设施,该基础设施应满足以下要求
- 从异构服务和设备实时传输带有时间戳的数据。
- 因果知识库可管理模型之间的交互,并促进因果节点之间的自标签 ML。
- 核心自标注服务可在边缘路由数据流、执行自标注工作流以及自主重新训练和重新部署 ML 模型。
- 可扩展架构,可轻松集成新的边缘、ML 和 SLB 服务。
4.AdaptIoT 的软件架构
AdaptIoT 系统的软件架构采用模块化结构,旨在支持自标签应用。本节将介绍系统的主要功能模块及其各自的作用。
4.1 模块级架构
AdaptIoT 系统由边缘服务、数据流管理器(DSM)、存储数据库、机器学习(ML)服务集群、交互式因果引擎(ICE)和前端图形用户界面(GUI)组成。系统由处理程序组成。边缘服务包括传感器、边缘计算设备、外部应用程序和工厂机械。本地边缘服务通过 DSM 将数据流传输到数据库和应用程序,而 DSM 则充当后端,将高吞吐量流数据路由到适当的目的地
已经实现了多种类型的数据库,包括时间序列数据库、SQL 数据库和 NoSQL 数据库。这些数据库存储原始时间戳传感器数据、服务和设备元数据、处理后的 ML 结果、自标签结果等。此外,任务模型、效应状态检测器(ESD)和交互时间模型(ITM)等 ML 服务集群也在运行,在参与自我标签工作流的同时提供可操作的智能。
图 2 显示了用于自贴标签应用的物联网系统的高级框图。
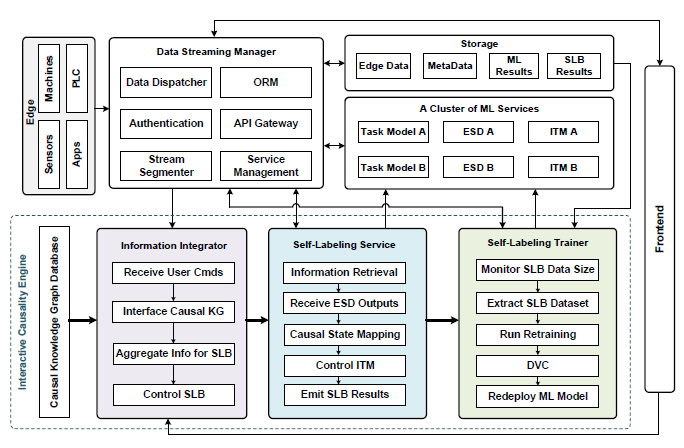
|--------------------------|
| 图 2:拟用于自标签应用的物联网系统的高级框图。 |
4.2 交互式因果引擎(ICE)
交互式因果引擎(ICE)是实现已部署的 ML 任务模型适应性的核心引擎。ICE 由因果知识图数据库、信息集成器、自标注服务和自标注训练器组成。这四个组件分别负责不同的任务,并自动执行自标注工作流程。
因果知识图谱数据库存储多个知识图谱(KG),代表节点之间的交互和因果关系。这些知识图谱是从现有的领域知识中提取和重建的。图 3(a) 显示了一个简化的 3D 打印机知识图谱示例。图中的链接表示相互作用,而节点之间的连接表示可能的因果关系。
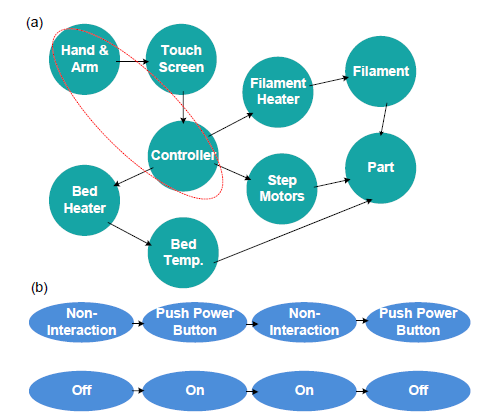
|-------------------------------------------------------------|
| 图 3 (a) 3D 打印机用例的简化知识图谱;(b) 因果关系 Hand&Arm 和控制器节点的相应状态转换关系。 |
信息集成器将因果关系 KG 数据库、自标签服务、传感器元数据、ML 服务和用户连接起来,集成必要的信息并控制自标签。通过信息集成器,用户可以启动或停止因果关联节点之间的自标签工作流。
自我标示服务接收信息集成器的输入,并启动自我标示工作流程。这包括收集原始数据流、与 ML 服务连接以及与自我标示培训师协调。
自标注训练器可持续监控自标注样本的数量,并根据用户指令重新训练和部署任务模型。为了实现可重用性和可扩展性,训练器的设计独立于自我标记服务。
4.3 单位服务模式
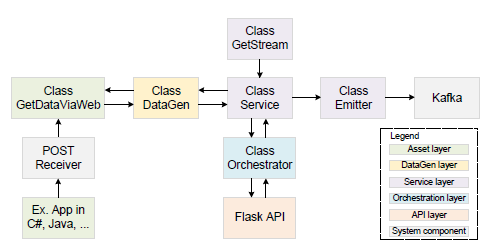
为确保 AdaptIoT 系统的可扩展性和同质性,我们设计了一个抽象的分层单元服务模型。该模型适用于系统中的所有服务,为生成数据并将数据发送到存储位置提供了标准化接口。单元服务模型由四层组成:资产层、数据生成层、服务层和应用程序接口层。
资产层:对传感器和机器等独立组件进行抽象。
数据生成层:负责数据生成和与资产层的接口。
服务层:与数据生成层集成,执行所需的服务功能。
应用程序接口层:定义应用程序接口端点并管理与其他服务的交互。
系统实施和分析
AdaptIoT 系统的实施包括硬件和软件基础设施,自我标签服务的实施就是一个具体例子。
4.4 网络创客空间的硬件基础设施
AdaptIoT 系统部署在 CyberMaker 空间实验室,包括以下制造设备
- 三维打印机
- 数控机床(铣床和车床)
- 合作机器人
- 氩弧焊机
每台机器都安装有多模态传感器,包括摄像头、功率计、振动传感器、声学传感器、距离传感器和环境传感器。传感器位于机床的关键部件和多个位置,用于收集数据。数控机床和机器人也由可编程逻辑控制器 (PLC) 控制,可直接获取机器运行状态的信息。
4.5 AdaptIoT 系统的软件实施
AdaptIoT 系统的实施包括以下软件组件
- 消息队列:分布式系统和计算机网络中的异步通信方法;Apache Kafka 用于提供横向可扩展性和高吞吐量。
- 数据库和存储:存储以下类型的数据
- 元数据:MySQL 数据库
- 高吞吐量传感器数据:时间序列数据库 InfluxDB。
- ML 服务成果:MongoDB 和 MySQL
- 因果知识图谱:Neo4j 图数据库。
- 视频和音频数据:文件系统
图 4 显示了 AdaptIoT 系统的硬件和软件基础设施。
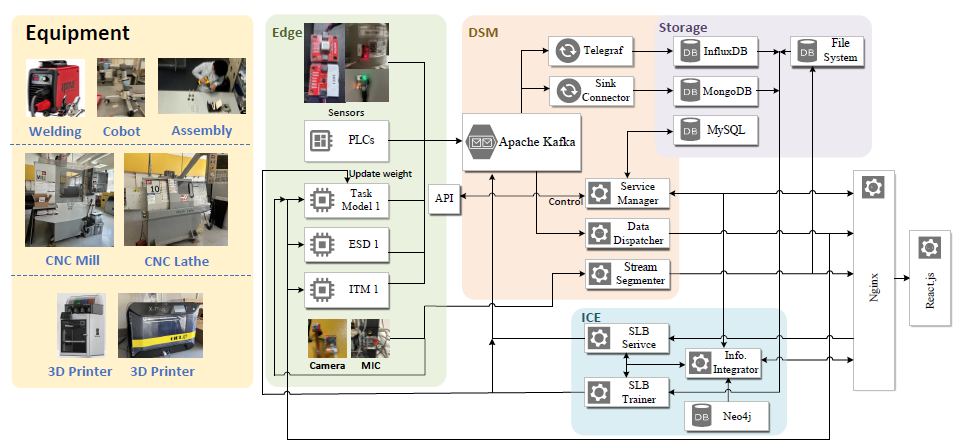
|-------------------------------|
| 图 4 硬件和软件基础设施每个区块代表一个容器化软件服务。 |
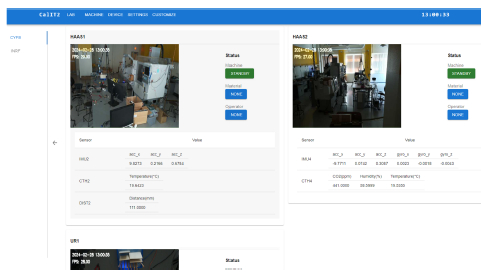
|-----------------------------|
| 图 5:显示实时数据和 ML 结果的网络图形用户界面。 |
4.6 数据流
AdaptIoT 数据流按以下步骤描述了从边缘传感器到 ML 服务的完整数据流:
- 数据生成:边缘传感器生成样本并将其发送到 Kafka 集群。
- 数据路由:样本在 Kafka 集群内处理并存储在 InfluxDB 中。数据分派器还会将它们路由为 HTTP 数据流,然后由 ML 服务接收数据流。
- 存储结果:推断出的 ML 结果会再次发送到 Kafka 并存储在 MongoDB 中。
图 6 显示了从外部应用程序接收数据的单元服务模型的详细实施情况。
|--------------------------|
| 图 6. 从外部应用程序接收数据的单元服务示例。 |
4.7 交互式因果引擎(ICE)的实施
ICE 的实现包括用于节点间因果关系和管理因果逻辑关系的数据结构。因果知识图谱存储在 Neo4j 数据库中,真值表以键/值对形式存储在 MongoDB 中。
自标注服务定义了一个标准类 SlbService,允许在给定相关参数的情况下应用自标注。自标注的输出包括三个关键值:效果状态、原因状态的结束时间戳和原因状态的持续时间。
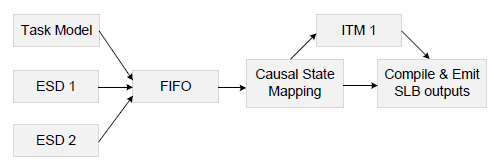
图 7:用于多重效果的自标签模块结构。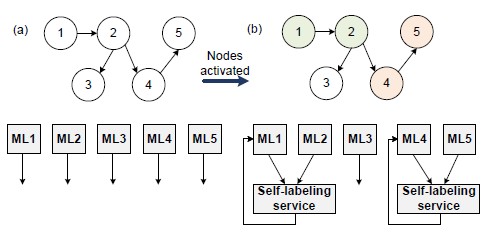
|-----------------------------------|
| 图 8:由于成对自我标签的初始化,ML 服务之间的虚拟交互示意图。 |
4.8 系统特性
进行了系统特征描述,以评估 AdaptIoT 系统的关键性能指标。评估内容如下
- 边缘节点吞吐量:一个边缘节点的平均吞吐量为 284 毫秒/秒,平均信息大小为 250.2 字节,平均延迟为 31 毫秒,最大延迟为 64 毫秒。
- 摄像头数据流:使用 Raspberry Pi 4B 和 Raspberry Pi 摄像头模块 3,摄像头数据流有两种模式:预览和全高清。预览模式下的平均延迟为 39 毫秒,而在全高清模式下可获取高质量图像数据。
表 1 显示了单个边缘节点的测试结果。
表 1:单边缘节点的测试结果

这些结果表明,AdaptIoT 系统具有高吞吐量和低延迟的特点,能够整合多种边缘服务和 ML 服务。
5.在 AdaptIoT 上运行的自我标签实验
本节将介绍一个自我标签应用的真实案例,以展示 AdaptIoT 系统的有效性。该自标注应用使用自适应模型来检测操作员与机器与 3D 打印机之间的交互。
5.1 实验概述
该实验旨在利用交互因果关系来调整操作员在 3D 打印机上的动作识别模型。在因果关系的一侧,使用摄像头来检测操作员的动作,而在另一侧,则使用功率计来检测机器以能耗形式做出的反应。
5.2 知识图谱构建
这种自标注应用是通过提取代表操作员、机器和材料之间因果关系的领域知识并构建因果知识图(KG)来实现的。图 3 显示了 3D 打印机的简化知识图谱。该图用于将操作员的操作与机器状态的变化联系起来。
5.3 实施传感器和 ML 服务
五个传感器对应五个节点,每个节点都有相应的 ML 服务来检测状态变化。已实施的节点如下
工人行为:使用级联 OpenPose 和图卷积网络 (GCN) 进行识别。
机器的功率变化:使用事件检测器和分类器进行检测。
图 9 显示了 3D 打印机自贴标签使用案例的实验装置。

|-----------------------------------------------------------------|
| 图 9:3D 打印机自贴标签用例的实验装置。(a) 显示了任务模型的数据处理流水线,(b) 说明了电流信号的 ESD 流水线。 |
5.4 进行自我贴标签
在这项实验中,400 个样本数据集由人工收集和标记,用于验证和测试;3D 打印机使用了三周,200 个自标记数据集由 AdaptIoT 系统自动收集和标记。
5.5 模型评估
使用自我标签生成的数据集对任务模型进行了重新训练,并对其准确性进行了评估。表 3 显示了与几种半监督学习方法相比的准确率。
表 3:在实验数据集上训练出的模型的准确率(%)。
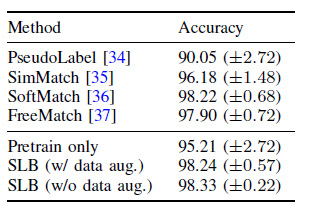
结果表明,与其他半监督学习方法相比,自标注方法始终显示出更高的准确性,并提高了训练的稳定性。
6. 结论
本研究设计并演示了 AdaptIoT,这是一个支持自我标签工作流的物联网系统,利用交互因果关系支持网络物理系统中自适应机器学习应用的开发。AdaptIoT 是一个基于网络的微服务平台,用于实现物联网的数字化和智能化,包括端到端数据流组件、机器学习集成组件和自标签服务。AdaptIoT 是一个高吞吐量、低延迟的数据采集平台,可确保 ML 应用程序的无缝集成和部署。
AdaptIoT 系统将部署在作为大学实验室的创客空间中,并将作为未来自适应学习网络物理制造应用的基础。预计未来将开发出更多基于 AdaptIoT 的自适应 ML 应用。
该系统具有以下功能:
- 高吞吐量和低延迟数据采集:AdaptIoT 实时处理大量数据,并高效采集数据。
- 无缝集成 ML 应用程序:AdaptIoT 可促进 ML 应用程序的集成和部署,推动智能制造流程的发展。
- 自动自我标注:自我标注服务可自动实时调整任务模型,实现持续学习。
未来,更多基于 AdaptIoT 的自适应智能语言应用有望在网络物理制造领域得到开发和实践。