Meta AI最近发布了 Llama 3.2。这是他们第一次推出可以同时处理文字和图片的多模态模型。这个版本主要关注两个方面:
-
视觉功能:他们现在有了能处理图片的模型,参数量从11亿到90亿不等。
-
轻量级模型:这些模型参数量在1亿到3亿之间,设计得小巧玲珑,可以在手机或者边缘设备上运行,不需要联网。
接下来,我会详细聊聊这些新模型是怎么工作的,它们能做什么,还有怎么用它们。

Llama 3.2的视觉模型
Llama 3.2的一个关键特性是引入了具有11亿和90亿参数的视觉启用模型。
这些模型现在可以处理图片和文字了,给Llama生态系统带来了新的能力。
多模态能力
这些视觉模型在需要识别图片和处理语言的任务上特别棒。它们不仅能回答问题,还能给图片配上描述性的标题,甚至能理解复杂的视觉信息。
根据Meta的示例,这些模型可以分析嵌入文档中的图表并总结关键趋势。它们还可以解释地图,确定哪一部分远足径最陡,或者计算两个点之间的距离。
视觉模型的应用
这种结合了文本和图像理解的能力,让这些模型有了很多潜在的应用场景:
-
文档理解:这些模型可以从包含图片、图表的文档中提取信息。比如,公司可以用Llama 3.2自动分析销售数据。
-
视觉问题回答:模型能根据视觉内容回答问题,比如识别场景中的对象或者总结图片内容。
-
图像字幕:模型能给图片配上标题,这对于需要理解图片内容的数字媒体或辅助功能领域特别有用。
开放和可定制
Llama 3.2的视觉模型不仅开放,还可以根据需要进行定制。开发者可以用Meta的Torchtune框架来调整这些模型。
而且,这些模型可以通过Torchchat在本地部署,这样就不需要依赖云基础设施了。
这些视觉模型还可以通过Meta AI的智能助手进行测试。
视觉模型的工作原理
为了让Llama 3.2的视觉模型能理解文本和图片,Meta把一个预训练的图像编码器集成到了现有的语言模型中,还用了特殊的适配器。这些适配器把图像数据和模型处理文本的部分连接起来,让模型能处理两种输入。
训练过程是从Llama 3.1语言模型开始的。团队先是用大量图片和文字描述来训练它,教会模型怎么把这两者联系起来。然后,他们用更清晰、更具体的数据来优化模型,提高它理解和推理视觉内容的能力。
在最后阶段,Meta用了微调和合成数据生成等技术,确保模型能给出有用的答案,并且安全地表现。
基准测试:强项和弱点
Llama 3.2的视觉模型在理解图表和图形方面做得特别好。在AI2 Diagram和DocVQA这些基准测试中,Llama 3.2的得分比Claude 3 Haiku还要高,这让它在处理文档理解、视觉问题回答和从图表中提取数据的任务上很有优势。
而且,在多语言任务上,Llama 3.2也表现得相当不错,得分86.9,几乎和GPT-4o-mini的得分一样,这对需要处理多种语言的开发者来说是个好消息。
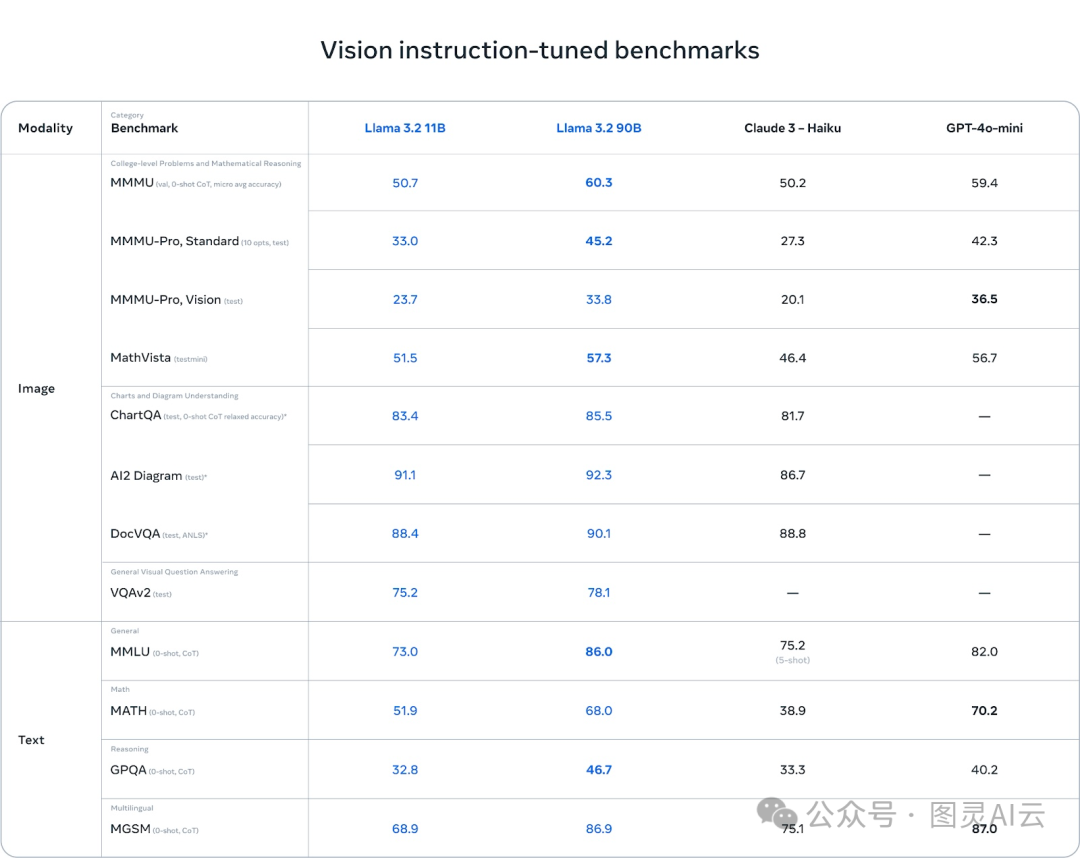
不过,虽然Llama 3.2在视觉任务上做得很好,但在其他方面还有待提高。比如在MMMU-Pro Vision这个测试视觉数据上数学推理能力的测试中,GPT-4o-mini的得分36.5就比Llama 3.2的33.8要高。
同样,在MATH基准测试中,GPT-4o-mini的得分70.2也明显超过了Llama 3.2的51.9,这说明Llama在数学推理方面还有提升的空间。
Llama 3.2的1B和3B轻量级模型
Llama 3.2的另一个亮点是推出了为边缘设备和移动设备设计的轻量级模型,参数量分别是10亿和30亿。这些模型在小设备上运行得又快又好,而且性能也还不错。
设备上的AI:快速和私密
这些模型可以在手机上运行,提供快速的本地处理,不需要把数据上传到云端。这样做有两个主要好处:
-
更快的响应时间:模型在设备上运行,可以几乎瞬间处理请求和生成回应,这对于需要快速反应的应用来说非常有用。
-
更好的隐私保护:数据在本地处理,不需要离开设备,这样可以更好地保护用户的敏感信息,比如私人消息或日历事件。
Llama 3.2的轻量级模型针对Arm处理器进行了优化,现在可以在很多移动和边缘设备上使用的高通和联发科硬件上运行。
Llama 3.2 1B和3B的应用
这些轻量级模型设计来满足各种实际的、在设备上的应用需求,比如:
-
摘要:用户可以直接在设备上对大量文本进行摘要,比如电子邮件或会议记录,不需要依赖云服务。
-
AI个人助理:模型可以理解自然语言指令并执行任务,比如创建待办事项列表或安排会议。
-
文本重写:这些模型能够即时增强或修改文本,非常适合用于自动编辑或改写工具等应用。
Llama 3.2轻量级模型的工作原理
Llama 3.2的轻量级模型(1B和3B)就是为了在手机和小型设备上也能跑得飞快,同时还得保持强大的性能。Meta用上了两种牛掰的技术:剪枝和蒸馏。
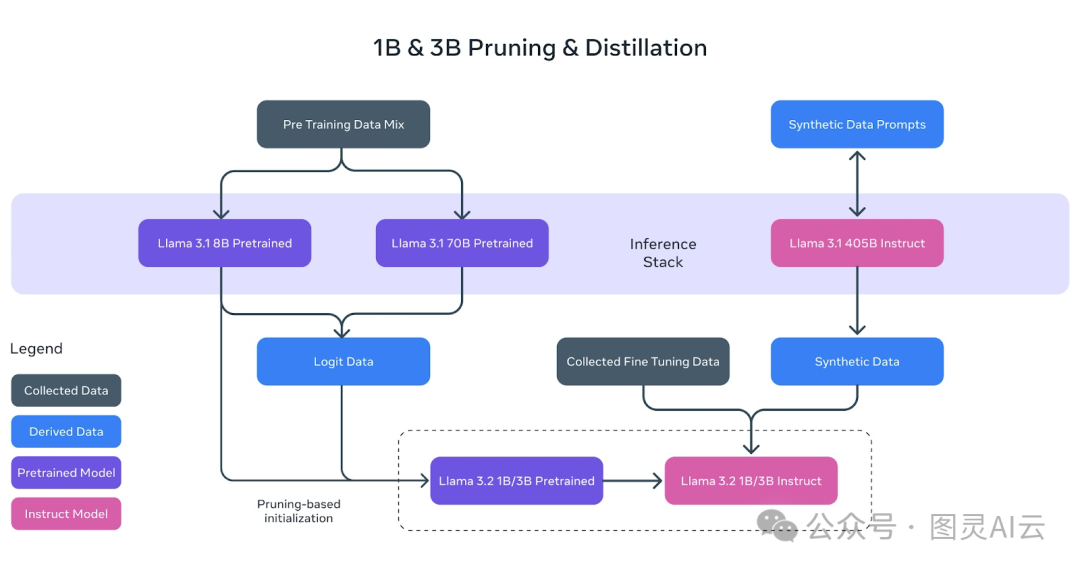
剪枝:让模型更苗条
剪枝就是把模型里不太重要的部分去掉,让模型变得更小,但知识还保留着。Llama 3.2的1B和3B模型就是从更大的Llama 3.1 8B预训练模型开始,一步步剪枝,变得更小更高效的。
Meta AI的团队通过这种方法,成功地把模型做得更小,但性能上并没有太大损失。就像上图里展示的,8B的预训练模型(紫色那个框)经过剪枝和提炼,就成了更小的Llama 3.2 1B/3B模型的基础。
蒸馏:把大模型的知识传给小模型
蒸馏就是把大模型(老师)的知识教给小模型(学生)。Llama 3.2用上了来自更大的Llama 3.1 8B和Llama 3.1 70B模型的预测结果来训练更小的模型。
这样,即使模型变小了,1B和3B的模型还是能很有效地完成任务。上图展示了这个过程,就是用大模型的预测数据来指导1B和3B模型在预训练期间的学习。
最终的磨练
剪枝和蒸馏之后,1B和3B模型还要经过一系列的后训练,和之前的Llama模型差不多。这个过程包括了监督微调、拒绝采样和直接偏好优化等技术,让模型的输出更符合用户的期望。
他们还生成了合成数据,确保模型能处理各种任务,比如摘要、重写和遵循指令。
就像上图展示的,最终的Llama 3.2 1B/3B指令模型是经过剪枝、蒸馏和广泛的后训练得到的。
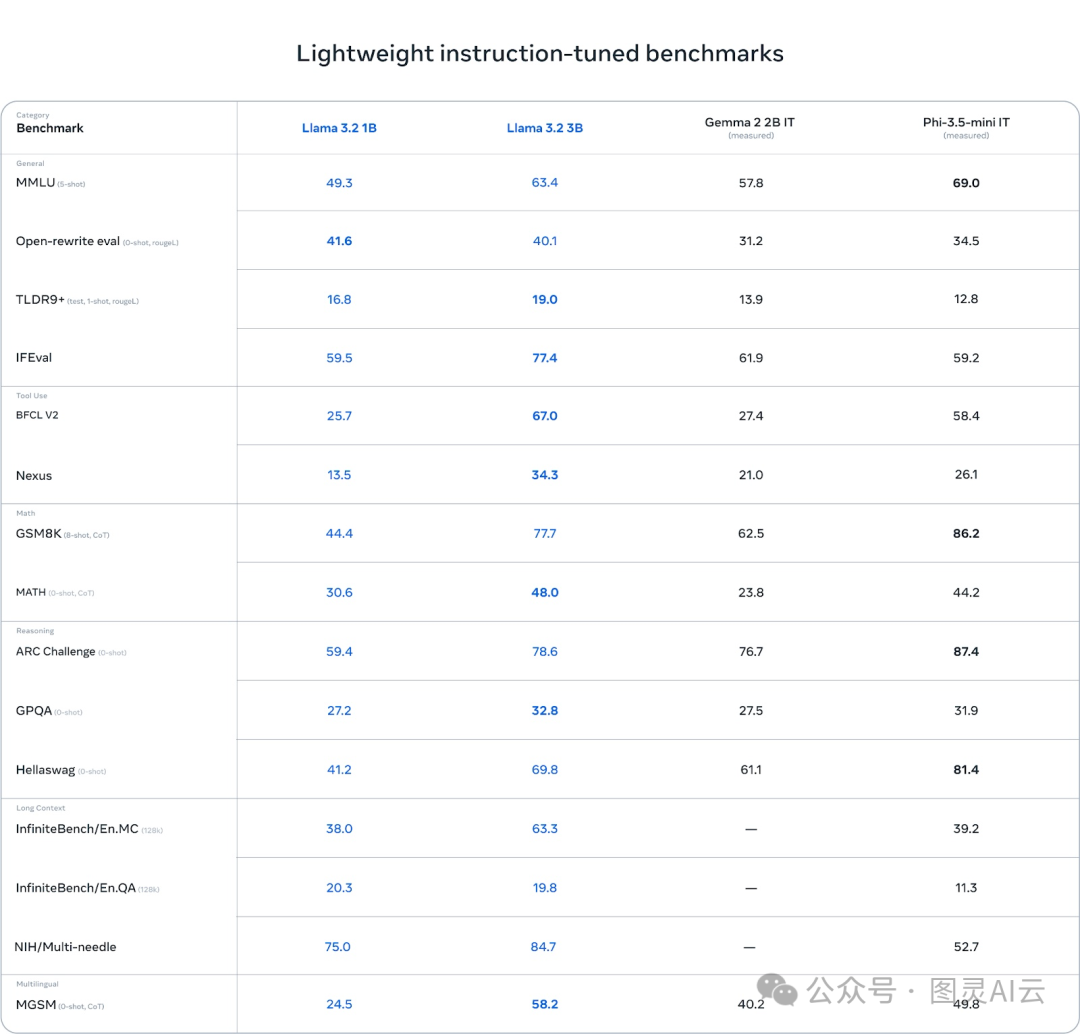
基准测试:优点和缺点
Llama 3.2的3B模型在某些领域特别出色,尤其是需要推理的任务。比如在ARC Challenge中,它的得分是78.6,超过了Gemma(76.7),虽然比Phi-3.5-mini(87.4)稍微低一点。在HellaWag基准测试中,它的得分是69.8,超过了Gemma,和Phi不相上下。
在BFCL V2这样的工具使用任务中,Llama 3.2的3B模型也表现得很棒,得分67.0,超过了两个竞争对手。这说明3B模型在处理指令遵循和与工具相关的任务上做得很好。
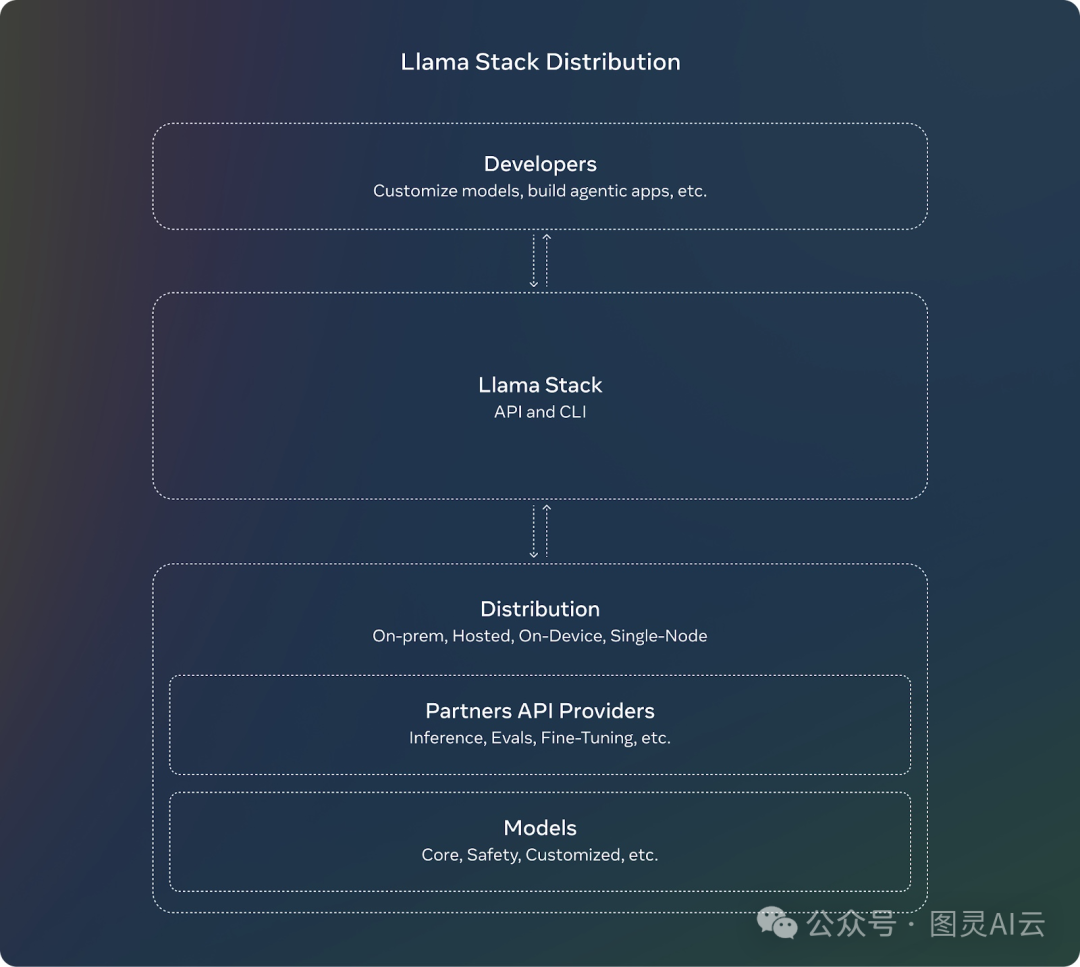
Llama堆栈分发
Meta为了配合Llama 3.2的推出,还搞了个Llama堆栈。这对开发者来说是个好消息,因为用Llama堆栈,他们就不用担心怎么配置或部署那些复杂的大型模型了。开发者们可以专注于自己的应用开发,剩下的重活累活都交给Llama堆栈来搞定。
Llama堆栈的亮点包括:
-
标准化API:开发者可以直接用这些API和Llama模型交互,不用什么都从头做起。
-
跨平台:Llama堆栈能在各种平台上运行:
-
单节点:在一台电脑上跑Llama模型。
-
本地:在自己的服务器或私有云上用模型。
-
云:通过AWS或Google Cloud这样的云服务商来部署Llama模型。
-
移动和边缘设备:让模型在不联网的手机上或小设备上也能跑。
-
-
预构建解决方案:Llama堆栈提供了现成的解决方案,专门针对一些常见任务,比如文档分析或问题回答,帮开发者省时省力。
-
集成安全:堆栈还自带了安全功能,确保AI在部署的时候能负责任地、符合道德地运行。
Llama 3.2安全
Meta对负责任的AI一直很上心,这次Llama 3.2的推出也不例外。Llama Guard 3更新了,现在支持Llama 3.2的新多模态功能,包括视觉功能。这保证了用新图像理解功能的应用能安全、合规。
而且,Llama Guard 3 1B也针对在资源受限的环境里部署做了优化,让它比之前的版本更小巧、更高效。
如何访问和下载Llama 3.2模型
获取Llama 3.2模型挺方便的。Meta已经在好几个平台上提供了这些模型,包括他们自己的网站和Hugging Face。
你可以直接从官方Llama网站上下载Llama 3.2模型。Meta给开发者提供了轻量级的模型(1B和3B)和视觉功能的大模型(11B和90B)。
Hugging Face也是个能拿到Llama 3.2模型的平台,它用起来很方便,在AI开发者社区里也很流行。
现在,Llama 3.2模型也能在我们众多的合作伙伴平台上马上用起来,包括AMD、AWS、Databricks、Dell、Google Cloud、Groq、IBM、Intel、Microsoft Azure、NVIDIA、Oracle Cloud、Snowflake等等。
结论
Meta这次推出的Llama 3.2,是系列中头一个多模态模型,主要关注两个方面:视觉功能和轻量级模型,后者是给边缘和移动设备用的。
11B和90B的多模态模型现在能处理文本和图像了,而1B和3B的模型则是为了在小设备上本地高效运行而优化的。
