
Python 中的 Pyppeteer 是什么?
Pyppeteer 是流行的 Node.js 库 Puppeteer 的 Python 移植版本,用于以编程方式控制无头 Chrome 或 Chromium 浏览器。
本质上,Pyppeteer 允许 Python 开发人员在 Web 浏览器中自动执行任务,例如抓取网页、测试 Web 应用程序或与网站交互,就好像真实用户在操作一样,但无需图形界面。
Browserless 是什么?
Browserless 是一种基于云的浏览器解决方案,可以有效地进行浏览器自动化、网站抓取和测试。
它利用了 Nstbrowser 的指纹库来实现随机指纹切换,从而实现无缝数据收集和自动化。Browserless 强大的云基础设施通过允许同时访问多个浏览器实例,简化了自动化活动的管理。
你是否对网页抓取和 Browserless 有任何奇妙的想法和疑问?
Pyppeteer 可以做什么?
使用 Pyppeteer 屏幕截图
使用 Browserless 时,你无法看到任何屏幕,因此当我们需要了解某些链接中浏览器的特定屏幕时,建议你使用 screenshot API 获取屏幕截图。
执行以下脚本将在当前脚本路径下生成名为 youtube_screenshot.png 的屏幕截图:
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
# 创建一个新页面
page = await browser.newPage()
# 访问 youtube
await page.goto("https://www.youtube.com/")
# 拍摄屏幕截图
await page.screenshot({"path": "youtube_screenshot.png"})
await page.close()
asyncio.run(main())与动态页面交互
在现代网站上,JavaScript 用于动态更新内容。例如,社交媒体平台通常在其帖子中使用无限滚动,页面数据的加载还需要等待后端的响应,以及各种表单操作和各种浏览器事件。
是的,Pyppeteer 也可以做到:等待加载、点击按钮、输入表单以及其他浏览器操作。
1. 等待页面加载
常用的等待页面加载的 API 是 waitForSelector 和 waitFor。
waitForSelector主要用于确保页面中某个元素正常加载waitFor只是等待指定时间。
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
# 访问 nasa
page = await browser.newPage()
await page.goto("https://www.disney.com/")
# 等待新闻加载
await page.waitForSelector('.content-body')
# 再等待 2 秒
await page.waitFor(2000)
# 拍摄屏幕截图
await page.screenshot({"path": "disney.png"})
await page.close()
asyncio.run(main())2. 滚动页面
在 page.evaluate 中,可以通过调用窗口 API 设置滚动条的位置,非常方便。
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
# 访问 HBO Max
page = await browser.newPage()
await page.goto('https://www.max.com/');
# 滚动到底部
await page.evaluate("window.scrollTo(0, document.documentElement.scrollHeight)");
# 拍摄屏幕截图
await page.screenshot({"path": "HBOMax.png"})
await page.close()
asyncio.run(main())3. 点击按钮
在 Python Pyppeteer 中,可以使用 page.click 来点击按钮或超链接。设置输入延迟使其更像真实用户的操作。
以下是一个简单的示例。
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
page = await browser.newPage()
await page.goto("https://example.com/")
# 点击链接
await page.click("p > a", {"delay": 200})
# 拍摄屏幕截图
await page.screenshot({"path": "example.png"})
await page.close()
asyncio.run(main())4. 表单输入
如何使用 Python Pyppeteer 输入数据?请使用 page.type 在指定的输入框中输入内容。
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
# 创建一个新页面
page = await browser.newPage()
# 访问 chrome 开发者
await page.goto("https://developer.chrome.com/")
await page.setViewport({"width": 1920, "height": 1080})
# 在搜索框中输入内容
await page.type(".devsite-search-field", "headless", {"delay": 200})
# 拍摄屏幕截图
await page.screenshot({"path": "developer.png"})
await page.close()
asyncio.run(main())使用 Pyppeteer 登录
通过以上示例,我们可以轻松想到登录涉及的交互,例如输入类型操作和按钮点击操作。
因此,在以下示例中,让我们改变编写方法。我们将尝试登录 Nstbrowser Client。登录后,我将拍摄屏幕截图以验证是否成功。
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
# 访问 Nstbrowser Client
page = await browser.newPage()
await page.goto("https://app.nstbrowser.io/account/login")
await page.waitForSelector("input")
inputs = await page.querySelectorAll("input")
# 在第一个输入框中输入你的电子邮件地址
await inputs[0].type("18552540330@163.com", delay=100)
# 在第二个输入框中输入你的密码
await inputs[1].type("9KLYUWn3GmrzHPRGQl0EZ1QP3OWPFwcB", delay=100)
buttons = await page.querySelectorAll("button")
# 点击登录按钮
await buttons[1].click()
# 等待登录请求响应
login_url = "https://api.nstbrowser.io/api/v1/passport/login"
await page.waitForResponse(lambda res: res.url == login_url)
await page.waitFor(2000)
# 拍摄屏幕截图
await page.screenshot({"fullPage": True, "path": "./nstbrowser.png"})
await page.close()
asyncio.run(main())- 运行结果:
我们可以看到我们的项目已被重定向到主页,这表明我们已成功登录 Nstbrowser!
如何在 Browserless 中使用 Pyppeteer?
Pyppeteer 可以与 Browserless 协同工作吗?
当然可以,你可以找到将 Pyppeteer 集成到 Browserless 的具体步骤!
步骤 1:获取 API KEY
在开始之前,我们需要拥有 Browserless 服务。使用 Browserless 可以解决复杂的 Web 抓取和大型自动化任务,并且现在已经实现了完全托管的云部署。
Browserless 采用以浏览器为中心的 approach,提供强大的无头部署功能,并提供更高的性能和可靠性。有关 Browserless 的更多信息,你可以访问官网了解更多。
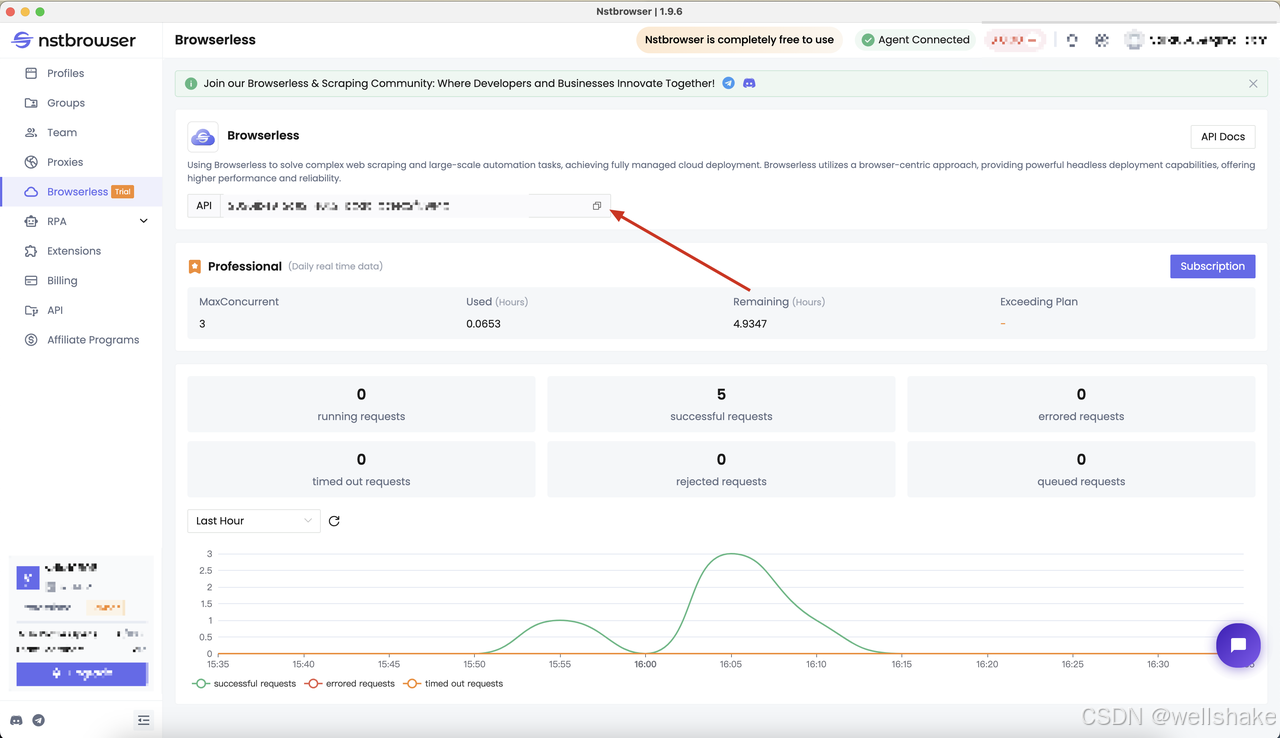
获取 API KEY 并转到 Nstbrowser 客户端的 Browserless 菜单页面,或者你可以进入 Browserless 页面进行访问:
步骤 2:安装 Pyppeteer
Pyppeteer 是 Puppeteer 的 Python 版本,提供类似的功能,允许开发人员使用 Python 脚本控制无头浏览器。它使开发人员能够通过 Python 代码自动执行与网页的交互,在爬虫、测试和数据采集等场景中非常常用。
pip install pyppeteer步骤 3:将 Pyppeteer 连接到 Browserless
我们需要准备以下代码。只需填写你的 API key 和 代理 即可连接到 Browserless。
python
from urllib.parse import urlencode
import json
token = "你的 api key" # '必填'
config = {
"proxy": "你的代理", # 必填;输入格式:schema://user:password@host:port 例如:http://user:password@localhost:8080
# "platform": "windows", # 支持:windows、mac、linux
# "kernel": 'chromium', # 只支持:chromium
# "kernelMilestone": '128', # 支持:128
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # 浏览器参数
# "fingerprint": {
# userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', # userAgent 支持从 v0.15.0 开始
# },
}
query = urlencode({"token": token, "config": json.dumps(config)})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"已连接,让我们开始抓取!
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
asyncio.run(main())步骤 4:在 Browserless 中使用 Pyppeteer
在本博文中,我们将深入了解一个简单的案例,帮助你快速开始使用 Browserless - 抓取 Books to Scrape。
在以下示例中,我们尝试抓取当前页面上的所有书籍标题:
- 打开页面
- 等待页面正常加载
- 打开调试控制台
- 确定任何位置的书籍标题对应的 HTML 元素:
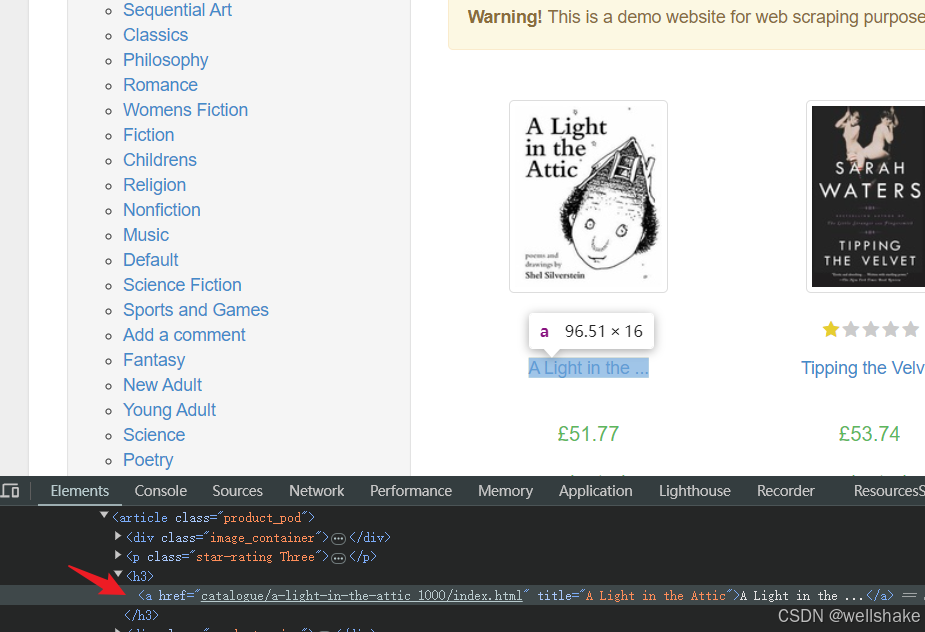
- 脚本:
python
import asyncio
from pyppeteer import connect
async def main():
# 连接到浏览器
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("已连接!")
# 创建一个新页面
page = await browser.newPage()
# 访问 Books to Scrape
await page.goto("http://books.toscrape.com/")
# 等待书籍列表加载
await page.waitForSelector("section")
# 选择所有书籍标题元素
books = await page.querySelectorAll("article.product_pod > h3 > a")
# 循环遍历所有元素以提取标题
for book in books:
title_element = await book.getProperty("textContent")
title = await title_element.jsonValue()
print(f"[{title}]")
await page.close()
# 运行脚本
asyncio.run(main())- 结果:
运行上述脚本将在控制台中输出所有捕获的数据:
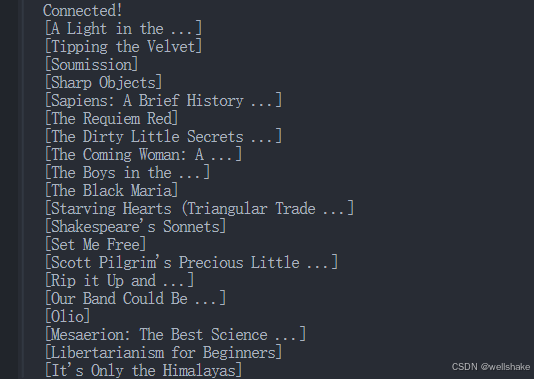
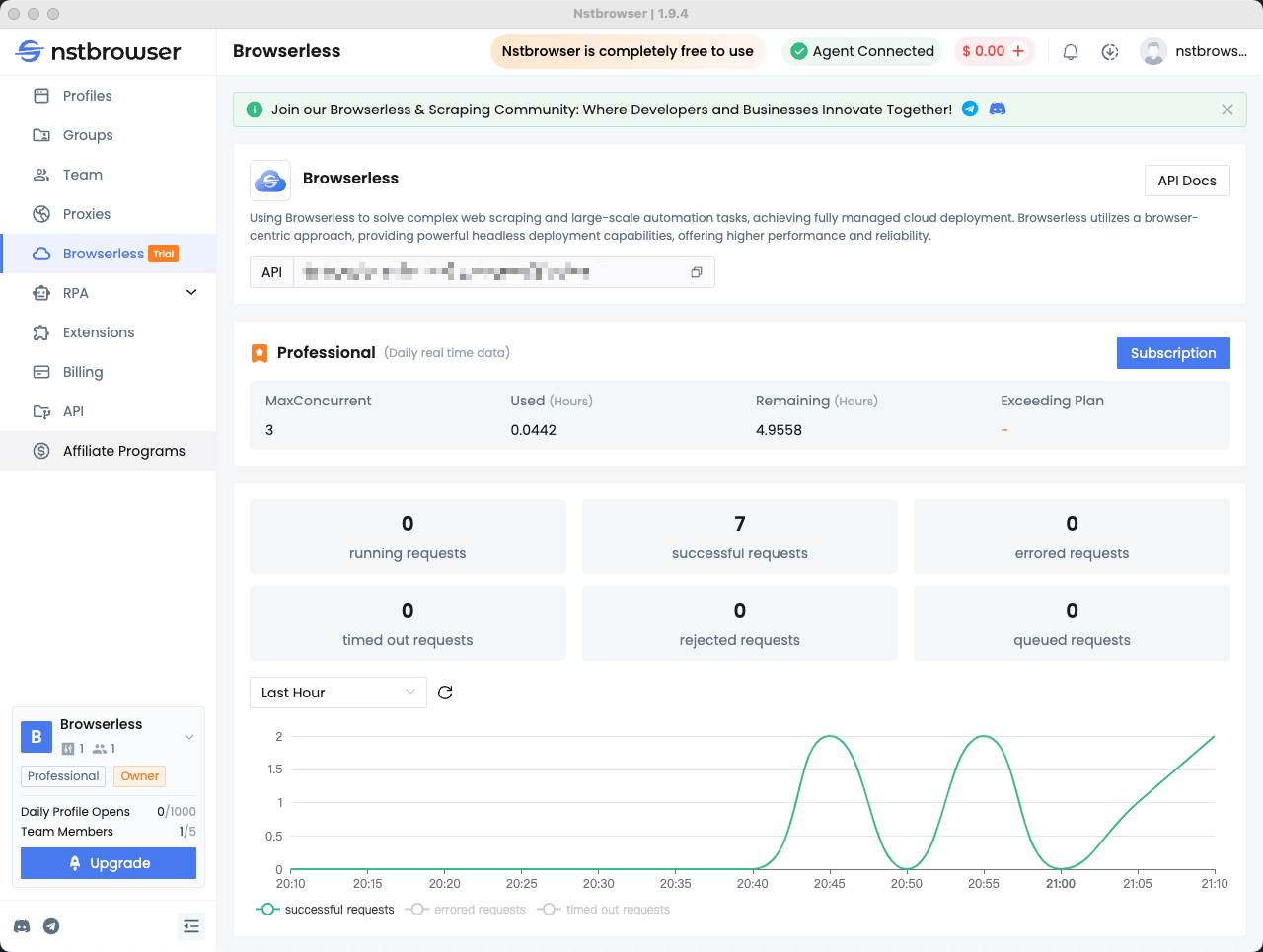
步骤 5:检查 Browserless 仪表板中的数据
你可以在 Nstbrowser 客户端的 Browserless 菜单中查看最近请求的统计信息和剩余会话时间。
使用 Pyppeteer 时常见的错误
大多数开发人员在设置和使用 Pyppeteer 时可能会遇到一些错误。别担心!你可以在这里找到解决方法。
错误 1:无法安装 Pyppeteer
在安装 Pyppeteer 时,你可能会遇到错误"无法安装 Pyppeteer"。
请检查系统上的 Python 版本。Pyppeteer 只支持 Python 3.6+。因此,请尝试 升级 Python 并重新安装 Pyppeteer。
错误 2:Pyppeteer 浏览器意外关闭
在首次安装后执行 Pyppeteer Python 脚本时,你可能会遇到此错误:pyppeteer.errors.BrowserError: Browser closed unexpectedly。
这意味着所有 Chromium 依赖项尚未完全安装。请使用以下命令手动安装 Chrome 驱动程序:
pyppeteer-install总结
Pyppeteer 是经典 Node.js Puppeteer 库的非官方 Python 移植版本。它是一个易于安装、轻量级且快速的包,用于 Web 自动化和动态网站抓取。
在本博文中,你已经学习了:
- Pyppeteer 是什么?
- 将 Pyppeteer 集成到 Browserless 的具体步骤。
- Pyppeteer 的其他用例。
如果你想了解更多关于 Browserless 的功能,请查看 官方手册。Nstbrowser 为你提供最佳的云浏览器,以解决自动化工作的本地局限性。