一、Fidder的安装
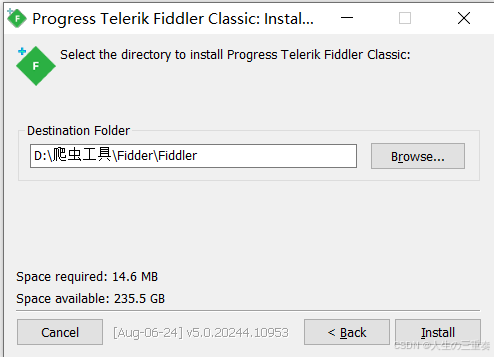

出现这样的界面就是安装成功了
二、Fiddler的配置
1.端监听手机端设置
但是如果你想要对手机上的app进行抓包怎么办呢,那么你还需要进行以下操作:
首先你的Fiddler所在的电脑和手机必须处在同一个局域网内(即连着同一个路由器)。
查看你的本机IP地址,在Fiddler的右上角有一个Online按钮,点击一下会显示你的IP信息
配置连接信息:Tools > Options >Connections
-
端口默认是8888,你可以进行修改。
-
勾选 Allow remote computers to connect 选项,然后重启Fiddler,再次打开时会弹出一个信息,选择ok即可。
-

-
fiddler默认只抓http请求,若要抓https请求,要进入tools-fiddler options设置

-
Connections端口中端口号改成86
2.手机的设置
打开你的手机,找到你所连接的WIFI,长按选择修改网络,输入密码后往下拖动,然后选择wifi
然后选择更多设置
然后点击已经连接的wifi

然后勾选显示高级选项 ,然后在代理一栏选择手动 ,再将你先前查看的IP地址 和端口号输入fiddler抓包的代理,然后保存。
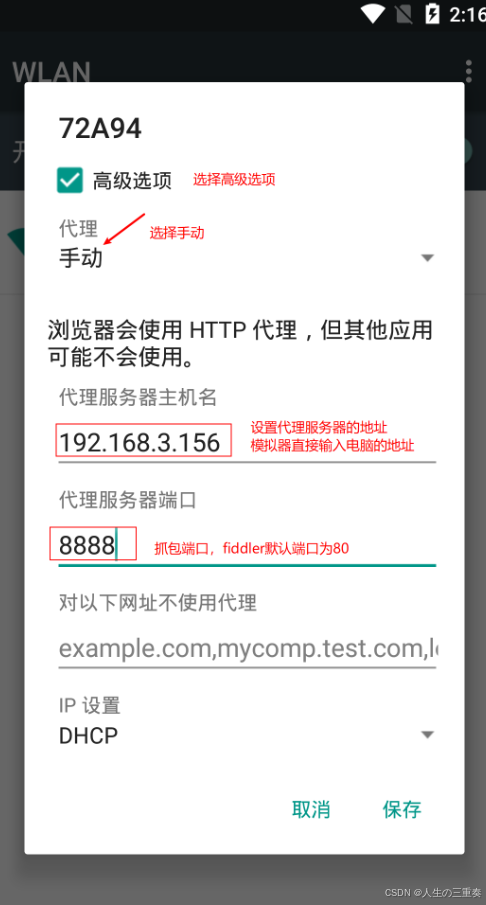
重启fiddler,最后安装手机证书,在手机浏览器一栏输入fiddler的运行地址
ipv4.fiddler:8888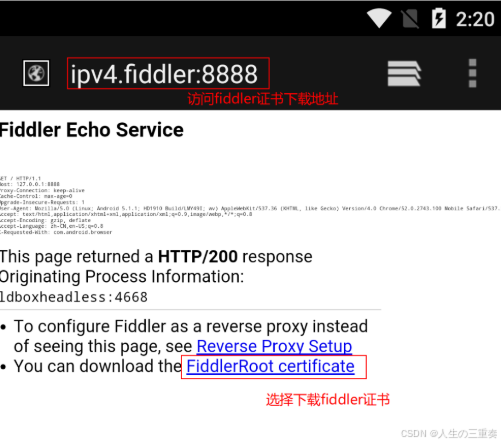
点击 FiddlerRoot certificate 就会下载证书,下载完之后点击下载证书,随便输入一个名字即可安装好。
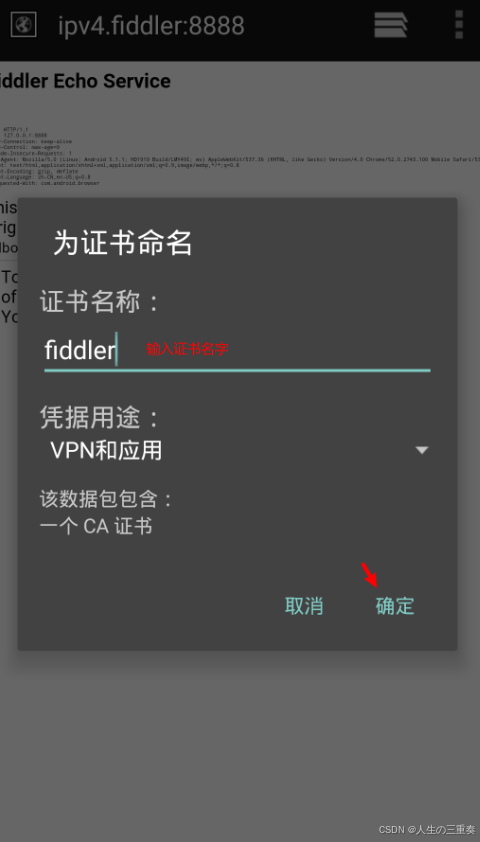
点击确定之后,就安装好了。
测试一下,比如在手机上打开app,找到评论的那一个请求。

重启Fiddler,使配置生效(这一步很重要,必须做)。
Fiddler 如何捕获Chrome的会话
1.安装SwitchyOmega 代理管理 Chrome 浏览器插件
Google Proxy SwitchyOmega安装 - zhshining - 博客园 (cnblogs.com)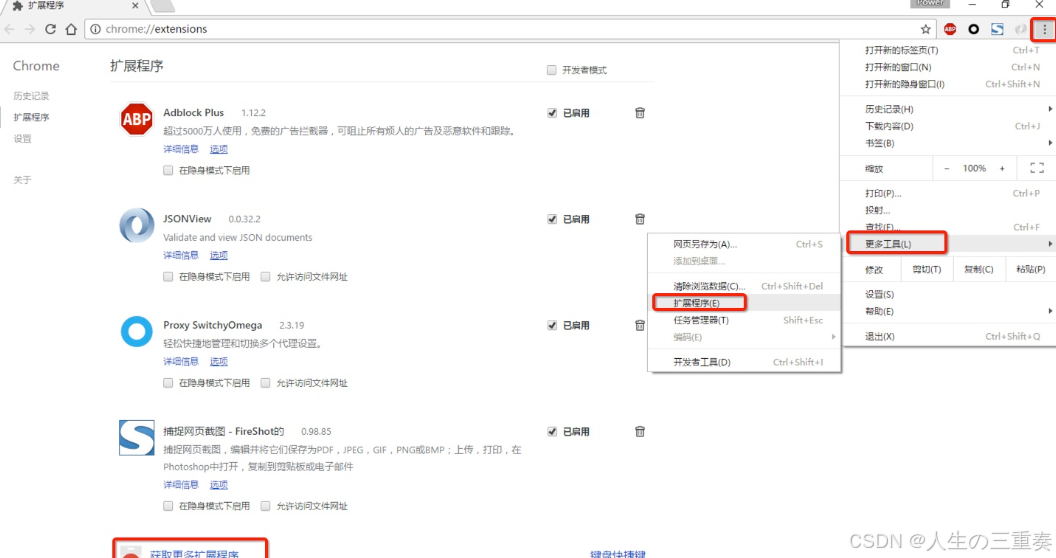
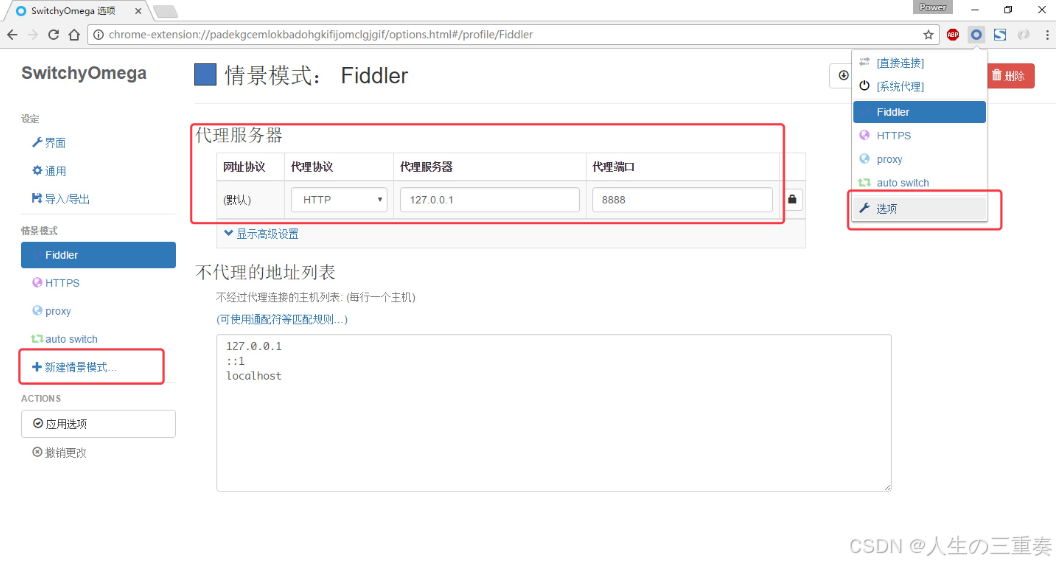
2.如图所示,设置代理服务器为127.0.0.1:8888
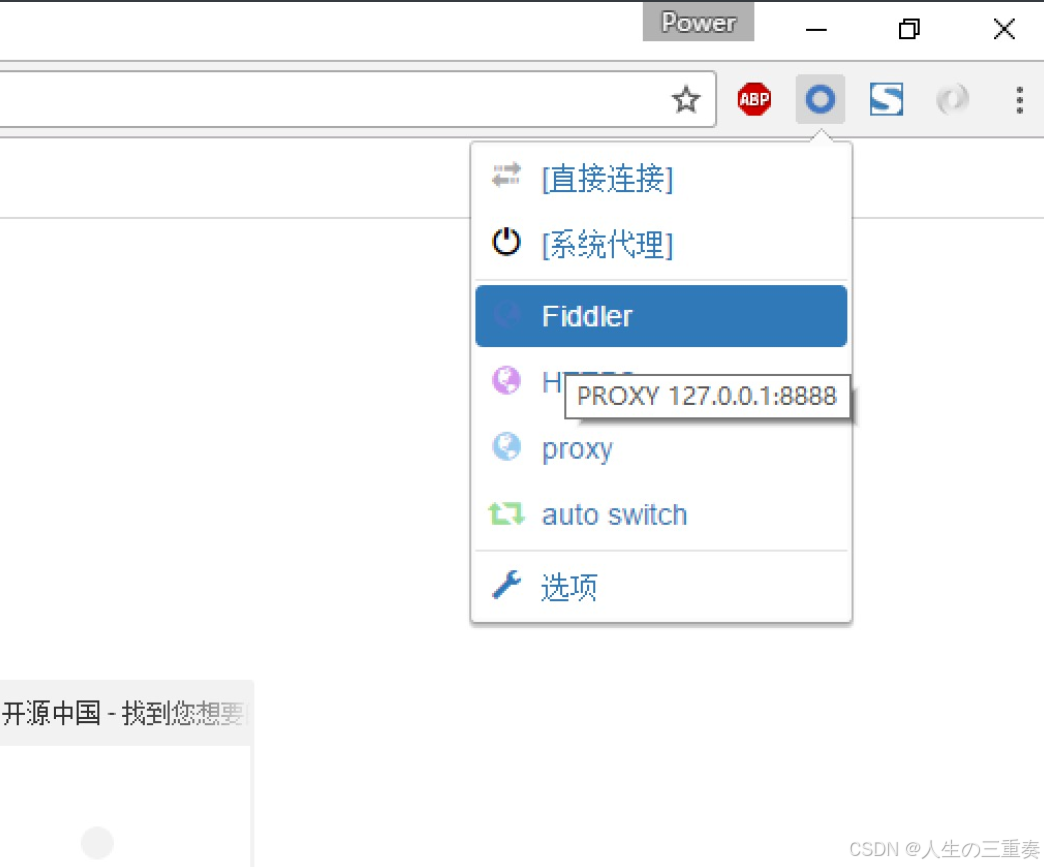
3.通过浏览器插件切换为设置好的代理。
Fiddler界面
设置好后,本机HTTP通信都会经过127.0.0.1:8888代理,也就会被Fiddler拦截到。
fiddler_show (1).png
请求 (Request) 部分详解
Headers ------ 显示客户端发送到服务器的 HTTP 请求的 header,显示为一个分级视图,包含了 Web 客户端信息、Cookie、传输状态等。
Textview ------ 显示 POST 请求的 body 部分为文本。
WebForms ------ 显示请求的 GET 参数 和 POST body 内容。
HexView ------ 用十六进制数据显示请求。
Auth ------ 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息.
Raw ------ 将整个请求显示为纯文本。
JSON - 显示JSON格式文件。
XML ------ 如果请求的 body 是 XML 格式,就是用分级的 XML 树来显示它。
响应 (Response) 部分详解
-
Transformer ------ 显示响应的编码信息。
-
Headers ------ 用分级视图显示响应的 header。
-
TextView ------ 使用文本显示相应的 body。
-
SyntaxView------响应数据
-
ImageVies ------ 如果请求是图片资源,显示响应的图片。
-
HexView ------ 用十六进制数据显示响应。
-
WebView ------ 响应在 Web 浏览器中的预览效果。
-
Auth ------ 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息。
-
Caching ------ 显示此请求的缓存信息。
-
Privacy ------ 显示此请求的私密 (P3P) 信息。
-
Raw ------ 将整个响应显示为纯文本。
-
JSON - 显示JSON格式文件。
-
XML ------ 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 。