ScribbleDiff可以通过简单的涂鸦帮助计算机生成图像。比如你在纸上随意画了一些线条,表示你想要的图像的轮廓。ScribbleDiff会利用这些线条来指导图像生成的过程。
首先,它会分析这些涂鸦,确保生成的图像中的对象朝着你画的方向。比如,如果你画了一条向右的线,生成的猫就会朝右看,而不是朝左。其次,这个方法会将你的涂鸦进行扩展,使得生成的图像更加完整和细致。
这样,即使你的涂鸦很简单,计算机也能理解并生成出你想要的图像。通过这种方式,ScribbleDiff让我们与计算机的互动变得更加直观和有效。
相关链接
论文链接:http://arxiv.org/abs/2409.08026v1
项目地址:https://github.com/kaist-cvml-lab/scribble-diffusion
论文阅读

涂鸦引导扩散:实现无需训练的文本到图像生成
摘要
文本到图像扩散模型的最新进展已显示出显著的成功,但它们往往难以完全捕捉用户的意图。现有的使用文本输入结合边界框或区域蒙版的方法无法提供精确的空间引导,常常导致对象方向错位或非预期。为了解决这些限制,我们提出了涂鸦引导扩散(ScribbleDiff),这是一种无需训练的方法,它利用用户提供的简单涂鸦作为视觉提示来指导图像生成。然而,将涂鸦纳入扩散模型会带来挑战,因为它们具有稀疏和薄弱的性质,很难确保准确的方向对齐。为了克服这些挑战,我们引入了矩对齐和涂鸦传播,这使得生成的图像和涂鸦输入之间可以更有效、更灵活地对齐。在 PASCAL-Scribble 数据集上的实验结果显示空间控制和一致性有了显著改善,展示了基于涂鸦的引导在扩散模型中的有效性。

方法
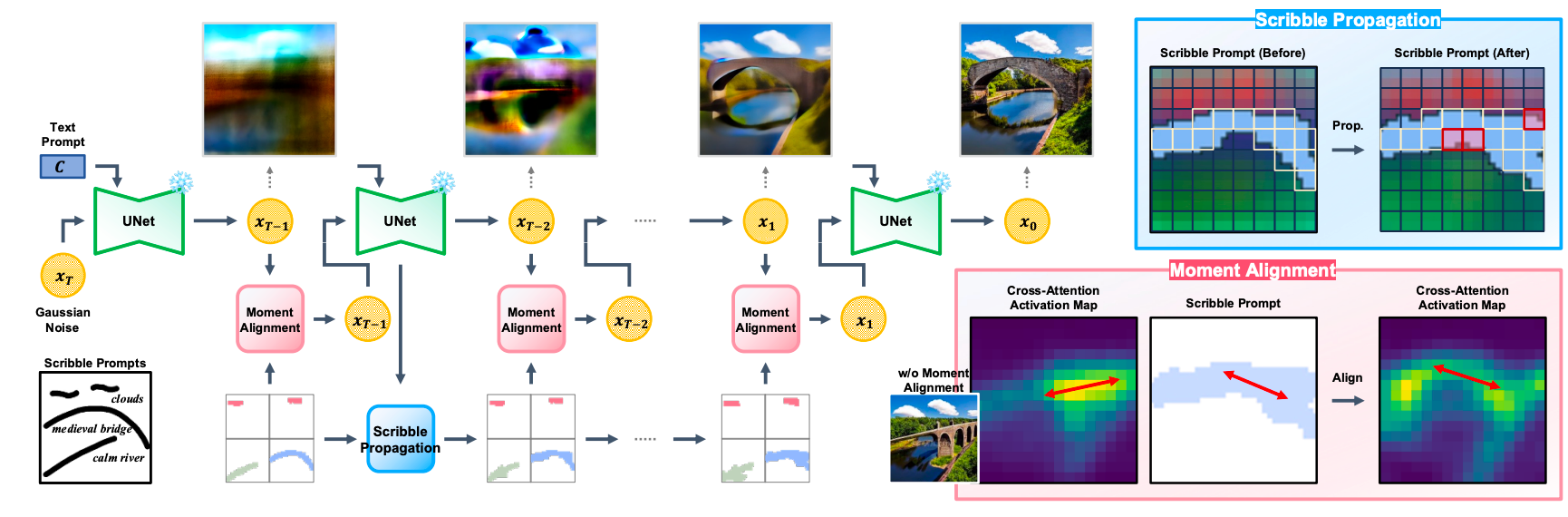
整体架构。 无需训练的 Scribble-Guided Diffusion (ScribbleDiff) 由两个主要组件组成:矩对齐和涂鸦传播。红色箭头表示分布的主要方向。相似度较高的锚点(红色矩形)是根据涂鸦的锚点(黄色矩形)收集的。(文字提示:云朵在天空中飘浮,在平静的河流上投下柔和、变幻的阴影。一座中世纪的桥梁横跨水道的宽度。)
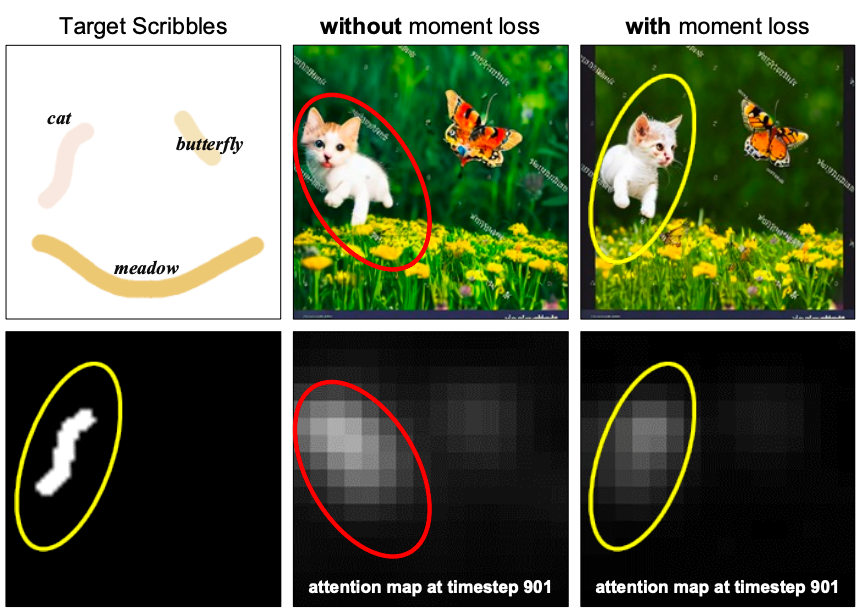
力矩损失对物体方向的影响。力矩损失可改善物体方向与涂鸦方向之间的对齐。如果没有力矩损失,猫会面向涂鸦方向的反方向。

涂鸦传播的效果。通过稳定扩散中的涂鸦传播,涂鸦会随时间显著扩大,从而改善物体形状并增强视觉连贯性。
实验


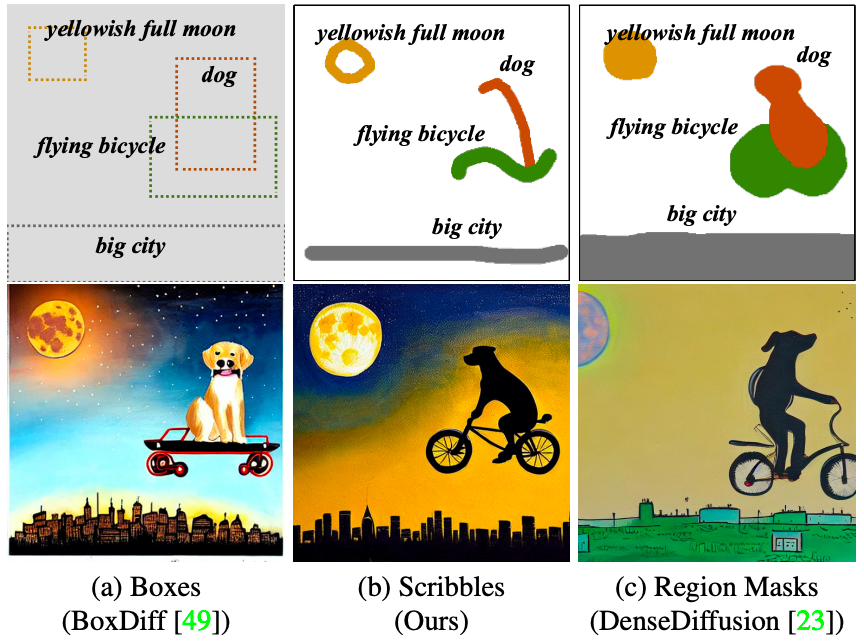
使用涂鸦提示对文本到图像生成方法进行定性比较。ScribbleDiff 产生的结果与涂鸦输入更加一致,特别是在对象的方向和抽象形状方面。

PASCAL-Scribble 数据集的定性结果。各种文本到图像生成方法的比较,包括在训练数据集上微调的 ControlNet。ScribbleDiff 表现出与输入涂鸦的出色对齐效果,特别是在处理抽象形状和对象方向时。

PASCAL-Scribble数据集的消融研究。 同一随机种子加关键成分与不加关键成分定性结果的比较。
结论
ScribbleDiff方法克服了传统边界框和区域蒙版的局限性,这些局限性通常无法有效捕捉抽象形状和物体方向。然而,涂鸦的稀疏和稀疏性质可能会妨碍精确控制,通过引入两个关键组件来缓解这种情况:
-
矩损失以使物体方向与涂鸦方向对齐
-
涂鸦传播以增强稀疏涂鸦输入到完整蒙版中。
实验结果表明,ScribbleDiffurpass 在各种指标(包括新的涂鸦比率)中都通过了无训练和微调方法。我们的方法在保持对文本提示的保真度的同时,持续改进了物体方向和空间对齐