2.1 安装虚拟机
在本地搭建集群就需要这么几个事
装虚拟机
安装环境
配置集群
启动
这篇博客主要就是讲的装虚拟机这一个环节的
装虚拟机就是和组装一台现实中的电脑一样,首先来说就是要有硬件,就是组装硬件,然后就是装系统,装完系统要上网所以就要配置一下ip地址。
话不多说上实操
2.1.1 安装硬件
1)选择自定义
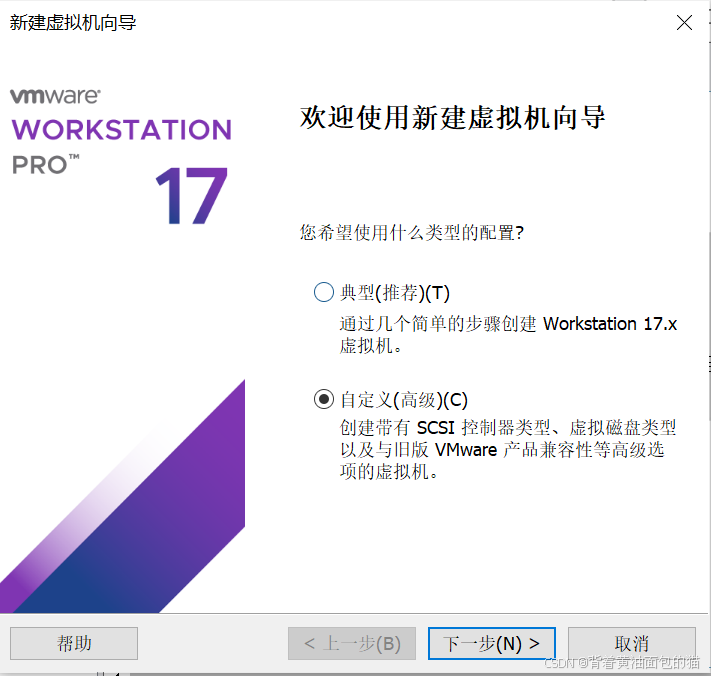
2)然后默认
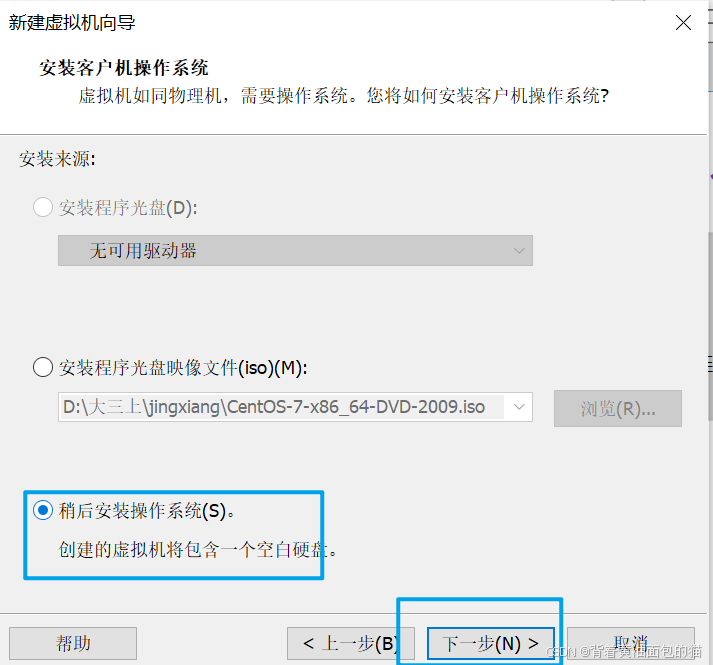
3)选择稍后安装操作系统
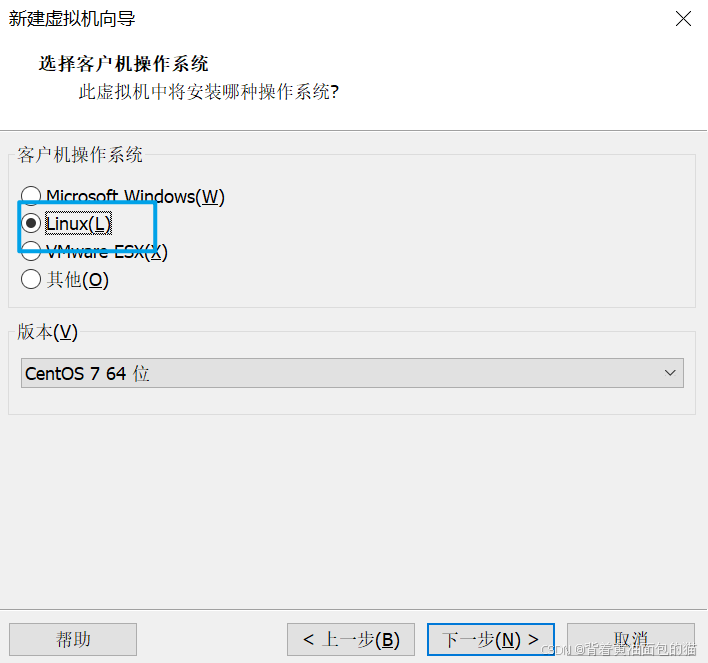
4)选择Linux系统
5)自己给虚拟机取一个名字,选择存储位置,一般不存在C盘
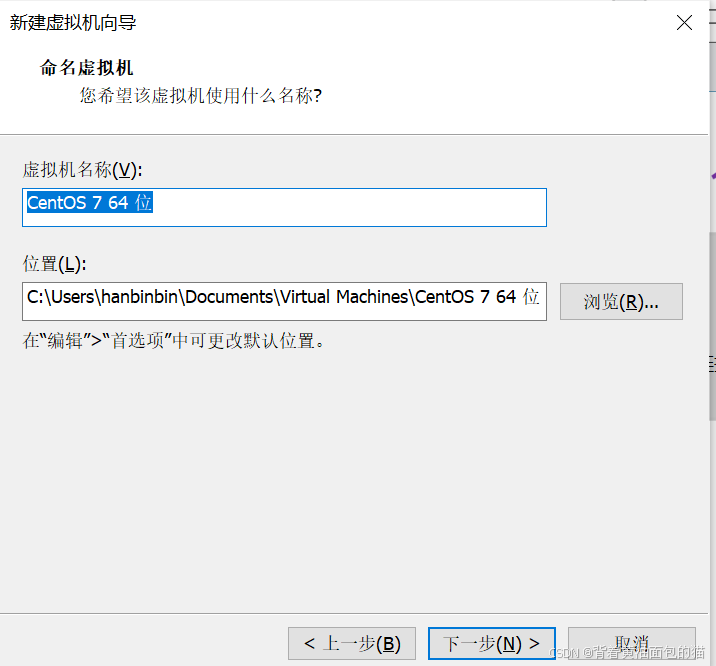
6)配置内核数
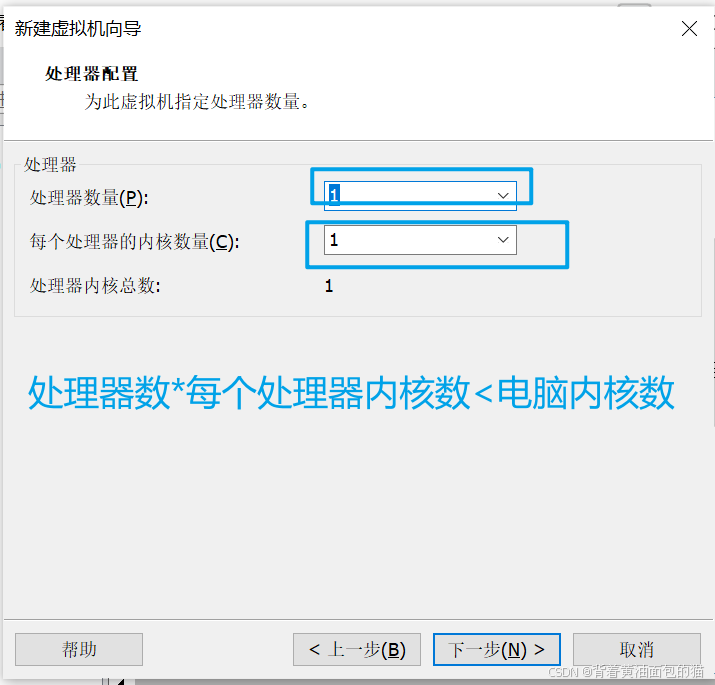
7)配置内存
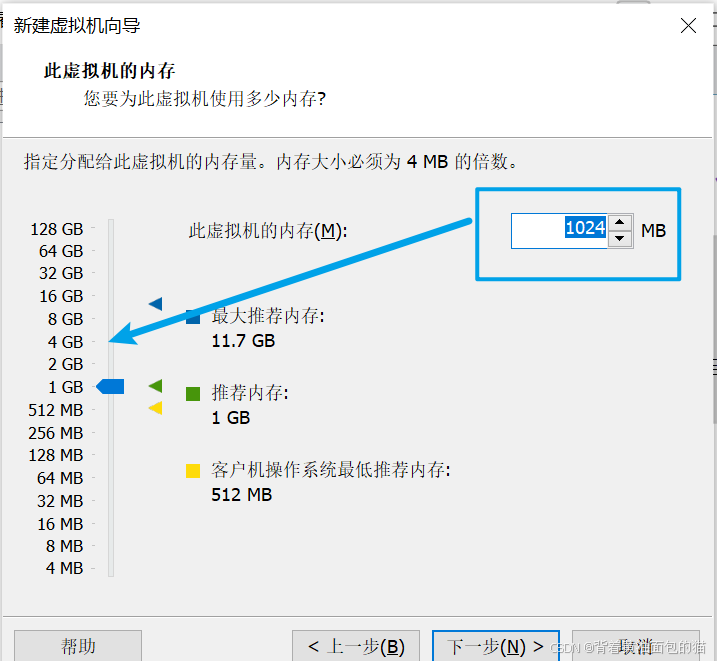
8)使用NAT
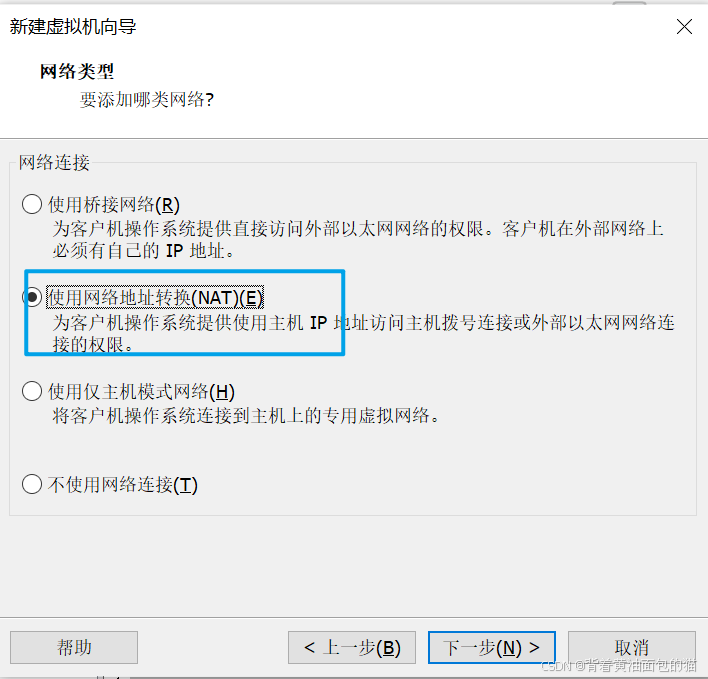
后面就一直选择默认
9)磁盘最大大小50GB,并选择拆分成多个文件,最后选择磁盘所在位置,生成配置单自己检查一下。
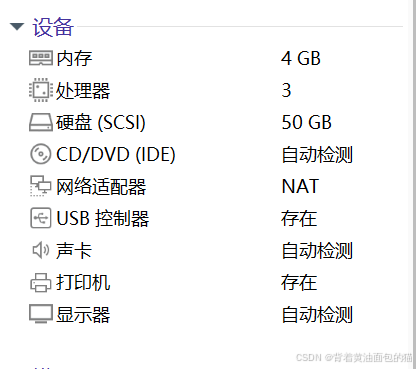
2.1.2 装操作系统
然后选择镜像安装,语言选择中文,时间选择中国上海,软件选择选择GNOME桌面
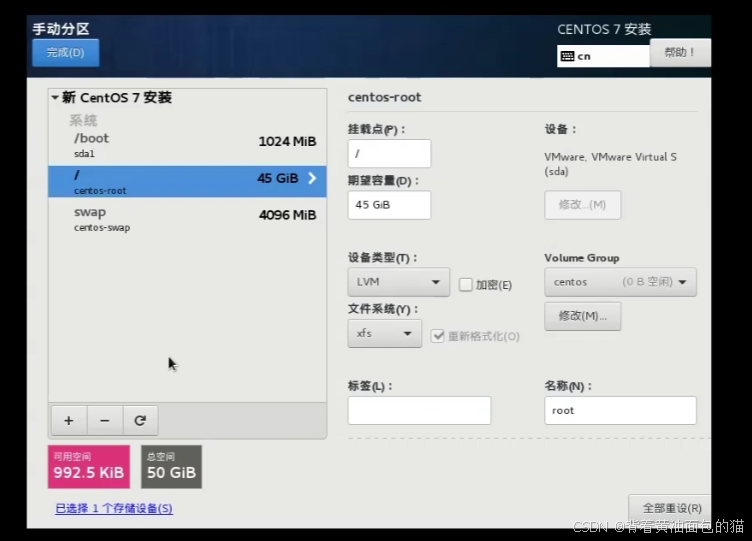
磁盘手动分区如下:
如果电脑内存不够的话可以不开dump,dump就是系统崩溃的转储机制
进行网络配置,选择打开就行。
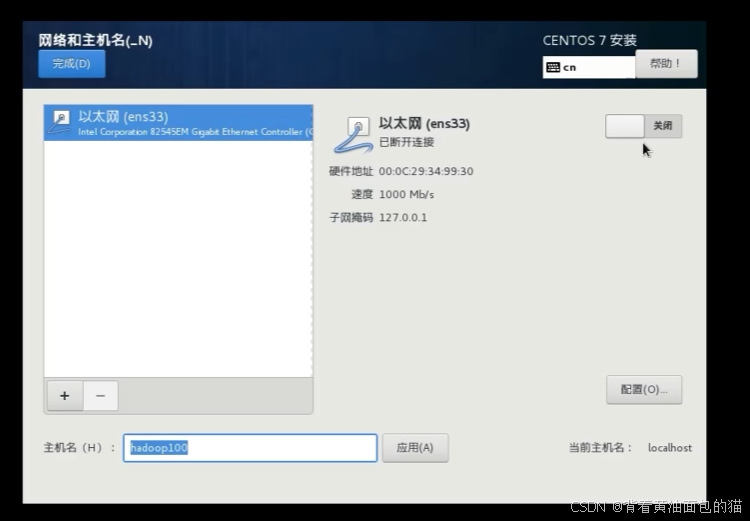
安全策略默认就行
然后安装就行,最后会要你设置一个普通的账号
2.1.3 配置ip地址
首先先配置VMware的ip
配置VMware的ip在编辑中的虚拟网络编辑器中编辑,选择VMnet8,然后选择更改设置。
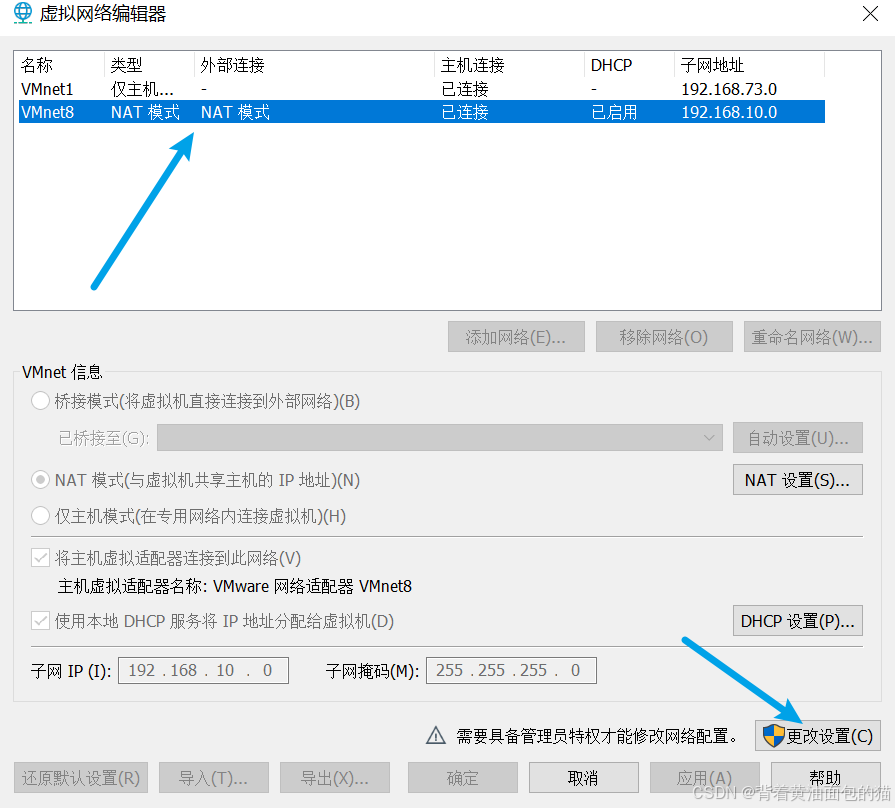
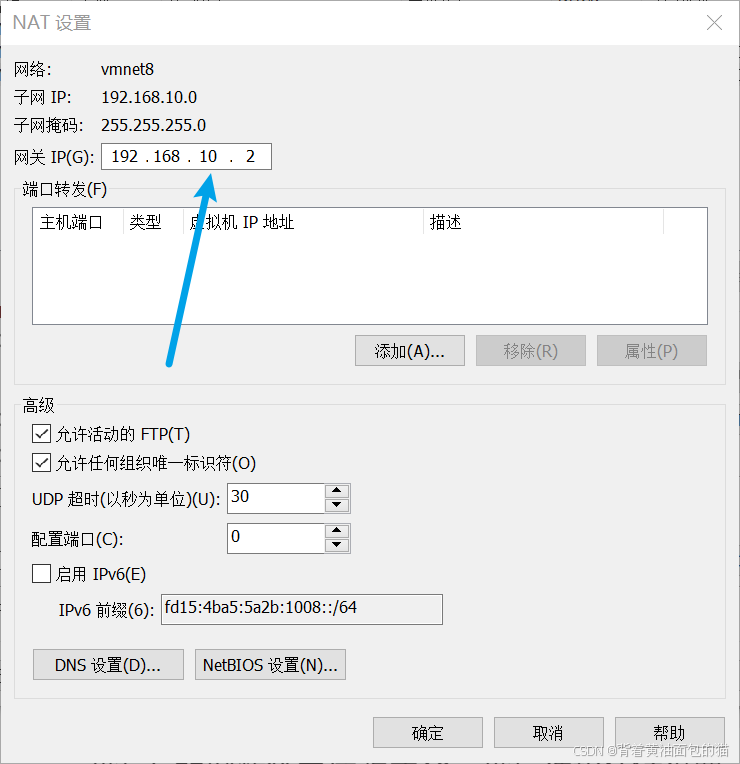
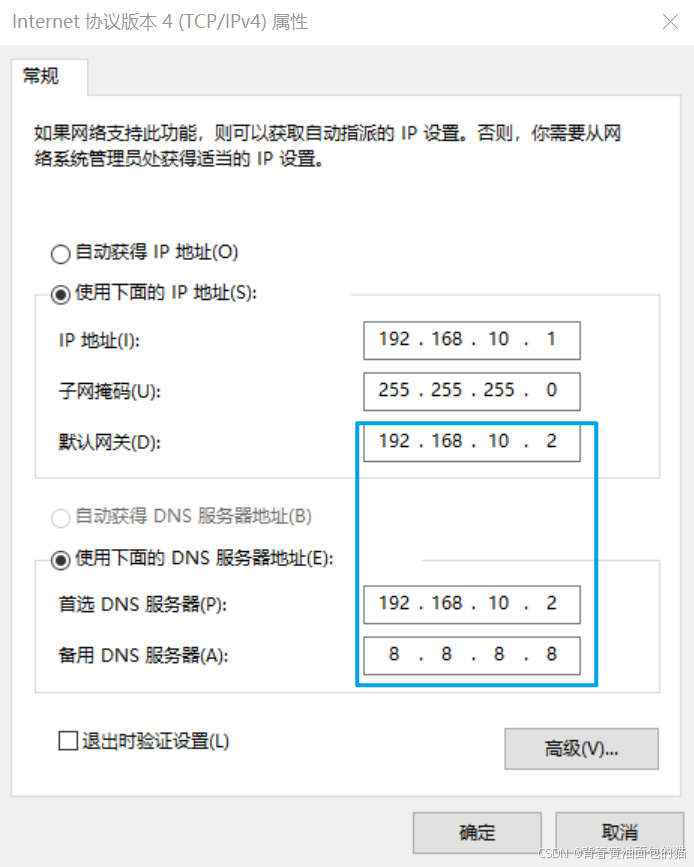
然后ip的倒数第二位改成10,然后选择NAT设置,网关中的倒数第二位也是10
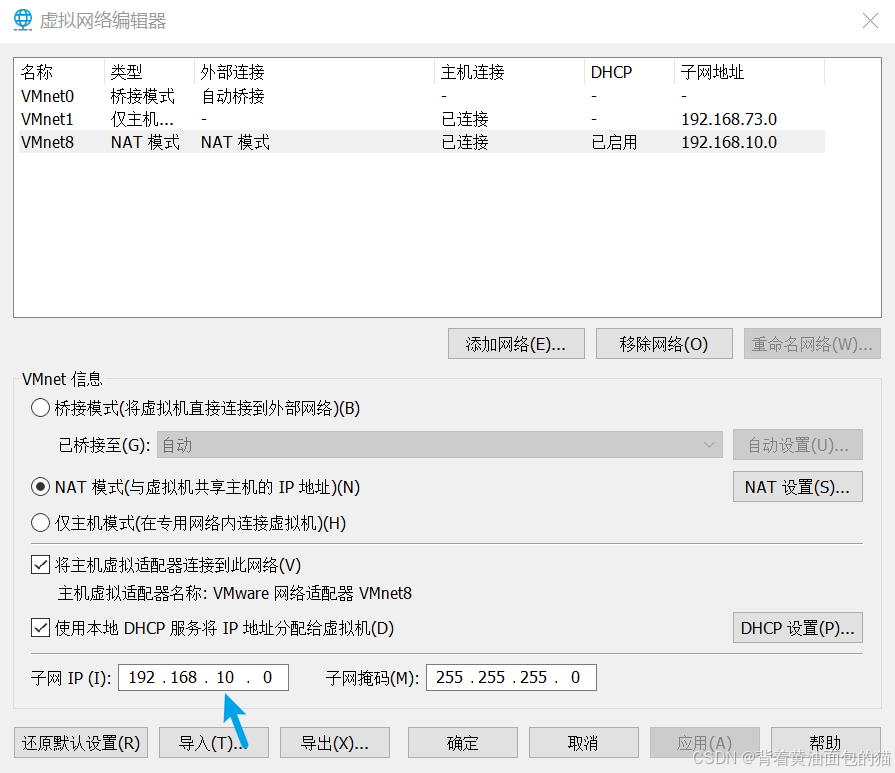
然后我们打开我们电脑的网络和Internet中心,然后去找VMnate8
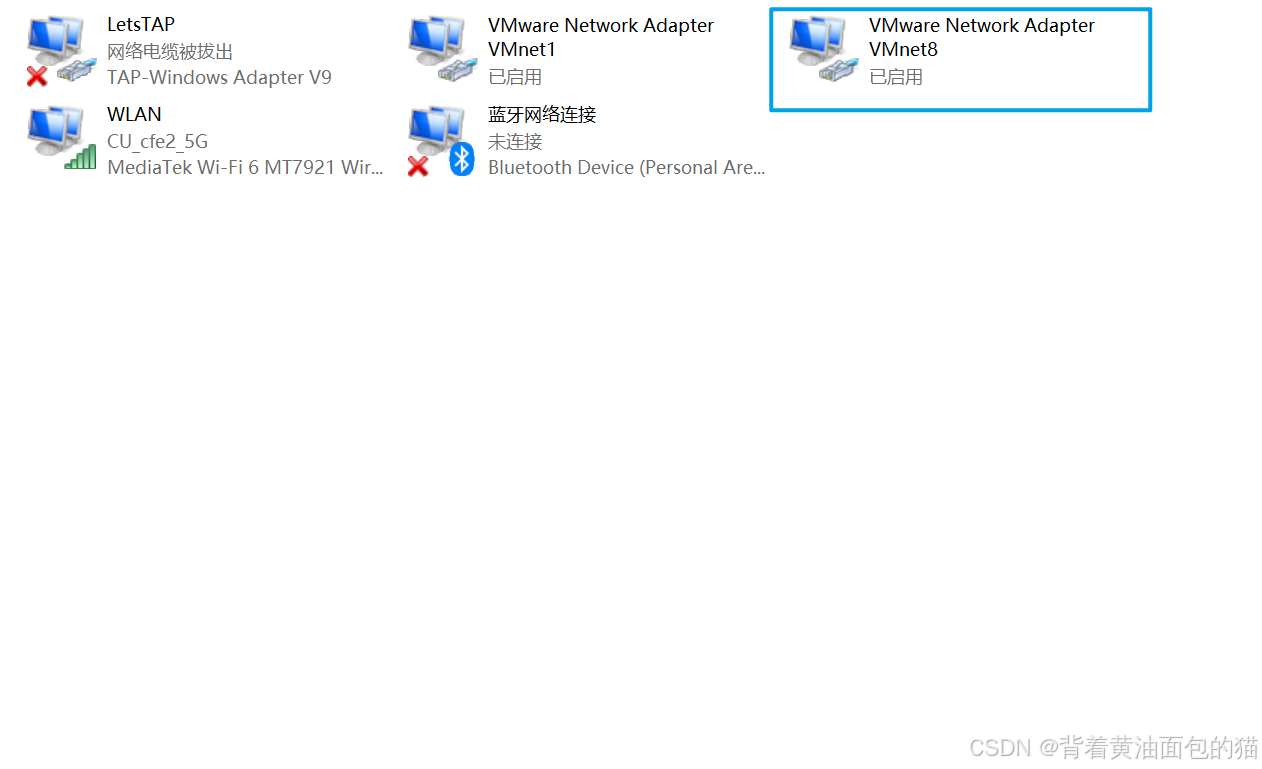
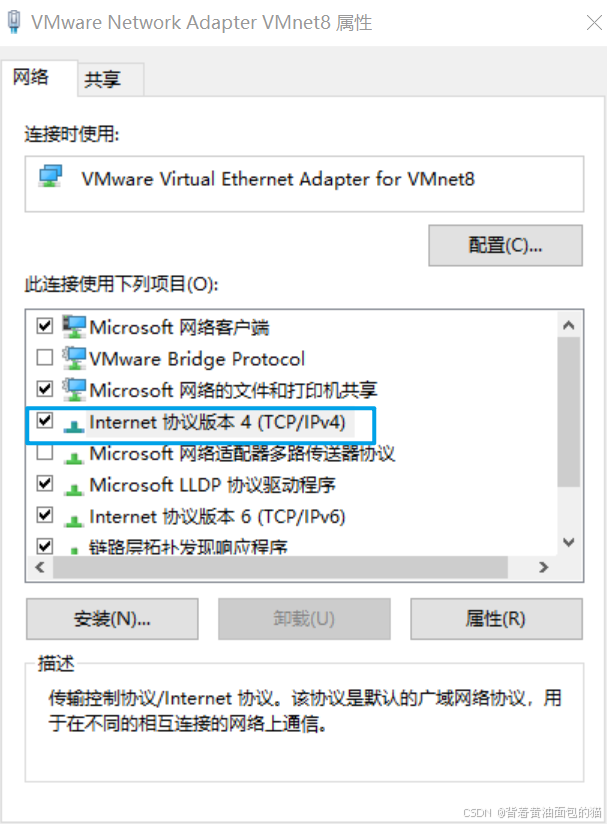
配置网关
然后打开终端,进入管理者模式
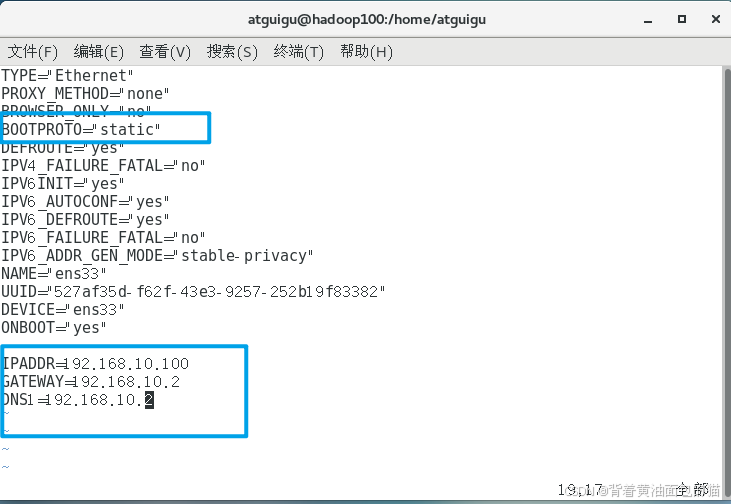
编辑网络配置,输入命令
vim /etc/sysconfig/network-scripts/ifcfg-ens33
动态改为静态,然后配置IP地址,网关地址,DNS1解析域名
4.配置主机名称
输入命令
vim /etc/hostname
主机名称映射

然后 reboot一下(输入命令reboot)
然后使用root账户登录一下,打开终端,查看此虚拟机的ip地址
ifconfig
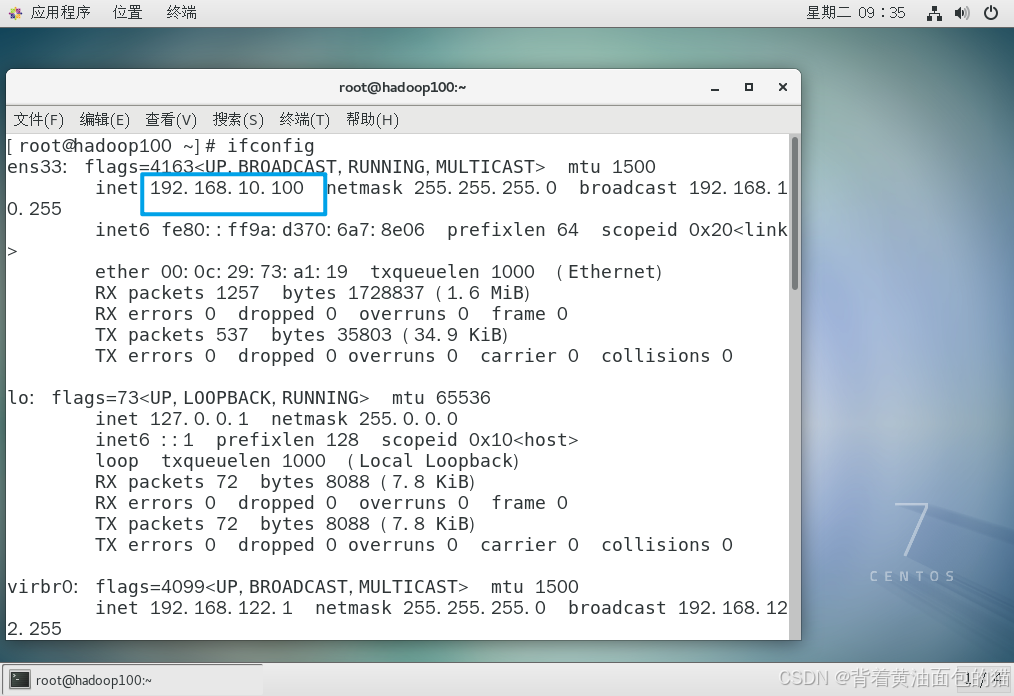
让后ping一下外网,看一下是否能ping通
查看主机名称
hostname
