摘要
我们介绍了 MM1.5,一个新的多模态大型语言模型 (MLLM) 家族,旨在增强在富文本图像理解、视觉参照和定位以及多图像推理方面的能力。 在 MM1 架构的基础上,MM1.5 采用以数据为中心的模型训练方法,系统地探索了整个模型训练生命周期中各种数据混合的影响。 这包括用于持续预训练的高质量 OCR 数据和合成字幕,以及用于监督微调的优化视觉指令调优数据混合。 我们的模型参数范围从 10 亿到 300 亿,涵盖密集型和专家混合 (MoE) 变体,并证明即使在较小规模(10 亿和 30 亿)下,仔细的数据整理和训练策略也能产生强大的性能。 此外,我们还介绍了两种专门的变体:MM1.5-Video,专为视频理解而设计,以及 MM1.5-UI,专为移动 UI 理解而设计。 通过广泛的经验研究和消融实验,我们提供了关于训练过程和决策的详细见解,这些见解为我们最终的设计提供了依据,并为 MLLM 开发的未来研究提供了宝贵的指导。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
前排提示,文末有大模型AGI-CSDN独家资料包哦!
1引言
近年来,多模态大型语言模型 (MLLM) 已成为一个越来越活跃的研究课题。 闭源模型,如 GPT-4o 51、GPT-4V 125、Gemini-1.5 149, 130 和 Claude-3.5 5,在高级多模态理解方面表现出非凡的能力。 同时,开源模型,如 LLaVA 系列工作 102, 100, 101, 74、InternVL2 21、Cambrian-1 151 和 Qwen2-VL 9, 150,正在迅速缩小性能差距。 越来越多的兴趣在于开发能够使用一组模型权重来理解单图像、多图像和视频数据的模型 74。
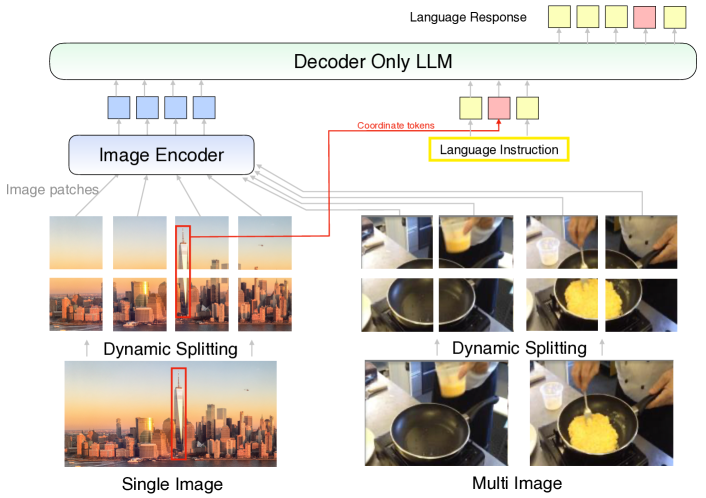
图 1: 模型架构概述。 MM1.5 擅长于 (𝑖) 使用动态图像分割的富文本图像理解,(𝑖𝑖) 使用坐标符元进行视觉参照和定位,以及 (𝑖𝑖𝑖) 多图像推理。
基于 MM1 118 的成功,我们推出了 MM1.5,一个新的大型语言模型 (MLLM) 家族,经过精心设计以增强一组核心功能。 具体来说,我们关注以下几个方面。
-
•
光学字符识别 (OCR). 基于最近在开发具有高分辨率图像理解能力的 MLLM 方面的趋势 182, 21,MM1.5 支持高达 400 万像素的任意图像纵横比和分辨率。 通过在不同的训练阶段纳入精心挑选的 OCR 数据来增强文本理解能力,MM1.5 在理解富含文本的图像方面表现出色。
-
•
视觉参照和定位。 MM1.5 提供强大且细粒度的图像理解,超越文本提示,可以解释 视觉 提示,例如点和边界框。 此外,MM1.5 可以通过将文本输出与图像边界框相结合来生成定位响应。 这种能力在大多数开源模型中尚未得到充分探索(例如,LLaVA-OneVision 74 和 Phi-3-Vision 3),甚至在像 GPT-4o 这样的强大专有模型中也是如此,这些模型依赖于标记集 (SoM) 提示 167 来引用图像区域。
-
•
多图像推理和上下文学习。 MM1.5 得益于大规模交错预训练,从而在开箱即用时具备强大的上下文学习和多图像推理能力。 我们通过对额外的高质量多图像数据进行监督微调 (SFT) 来进一步提高其能力,类似于 53, 77 中探讨的方法。
我们的主要重点是最有效的模型规模,10 亿和 30 亿,并证明即使是相对较小的 MLLM 也能在各种下游任务上取得具有竞争力的性能。 具体来说,我们在此模式下展示了两种类型的模型。
-
•
密集模型:这些模型以 10 亿和 30 亿的尺寸提供,足够紧凑,便于在移动设备上部署,但功能强大,足以胜过更大的开源模型。
-
•
专家混合 (MoE) 模型:MoE 模型也以 10 亿和 30 亿的变体提供,具有 64 个专家,在推断期间保持固定数量的激活参数,从而提高性能。
在更小的模型规模之外,我们进一步证明了 MM1.5 方法在高达 300 亿参数的范围内表现出强大的扩展行为,在广泛的基准测试中取得了具有竞争力的性能。
MM1.5 是一款通用模型;但是,在某些情况下,特定下游应用需要专门的模型。 为此,我们开发了另外两个变体:
-
•
MM1.5-Video,一种用于视频理解的变体。 我们探索了两种训练方法:使用仅在图像数据上训练的 MM1.5 的无训练方法,以及在视频特定数据上的监督微调。
-
•
MM1.5-UI,一个定制版本的 MM1.5,专注于移动 UI 理解(e.g.,iPhone 屏幕)44, 171,其中视觉引用和定位起着至关重要的作用。
构建高效的 MLLM 是一项高度经验性的工作。 虽然总体目标和高级训练流程定义明确,但其执行的细节仍然不清楚。 在开发 MM1.5 时,我们选择保留与 MM1 相同的模型架构118,使我们能够专注于完善和研究数据中心训练方法的复杂性。 我们的注意力集中在以下关键方面:
-
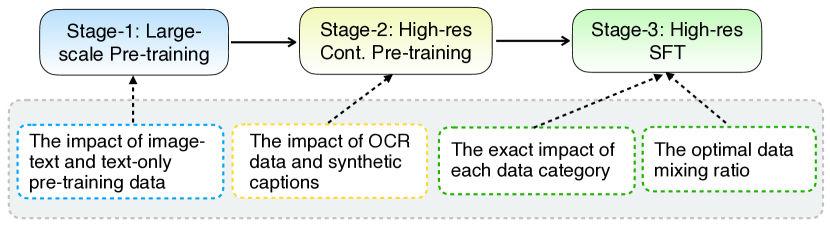
图 2: 用于构建 MM1.5 的方法。 模型训练包含三个阶段:(𝑖)使用低分辨率图像(378×378)的大规模预训练,(𝑖𝑖)使用高分辨率(高达 400 万像素)OCR 数据和合成字幕的持续预训练,以及(𝑖𝑖𝑖)监督微调 (SFT)。 在每个阶段,我们的目标是确定最佳数据组合并评估每种数据类型的影響。
-
•
持续预训练。 我们在 SFT 阶段之前引入了一个额外的、高分辨率的持续预训练阶段,我们发现这对于提升富文本图像理解性能至关重要。 我们消除了此阶段两种高质量数据的影响:
-
--
我们探索了文本丰富的 OCR 数据以进行持续预训练,重点关注图像中文本的详细转录 46, 68。
-
--
我们还尝试了高质量的合成图像标题,这些标题要么是公共数据,要么是使用基于先前训练的 MM1 模型的图像标题生成器生成的。
-
•
SFT。 虽然之前有大量工作讨论了用于 MLLM 的 SFT 数据,但关于混合物中每类 SFT 数据如何影响最终模型性能的探索仍然有限。 特别是,支持每个能力的数据对其他能力的影响尚待研究。 我们进行了广泛的消融以确定权衡和协同作用,最终从公共数据集中构建了一种混合,这有助于在 MM1.5 中的一组广泛能力中实现均衡的性能。
-
•
动态高分辨率。 此外,对于 高分辨率 图像编码,我们遵循流行的任何分辨率方法,动态地将图像划分为子图像 99, 93, 182,并进行彻底的消融以细化设计中的关键细节。
与大多数仅关注 SFT 102, 100, 101 的开源模型不同,MM1 通过大规模预训练展示了强大的零样本和少样本学习能力。 在开发 MM1.5 时,我们的目标是保留这些优势,并更有效地将它们转移到 SFT 阶段。 为此,我们通过探索纯文本数据的影响和优化不同预训练数据类型的比例来进一步扩展 MM1 的预训练。 此方法提高了知识密集型基准测试的性能,并增强了整体多模态理解能力。
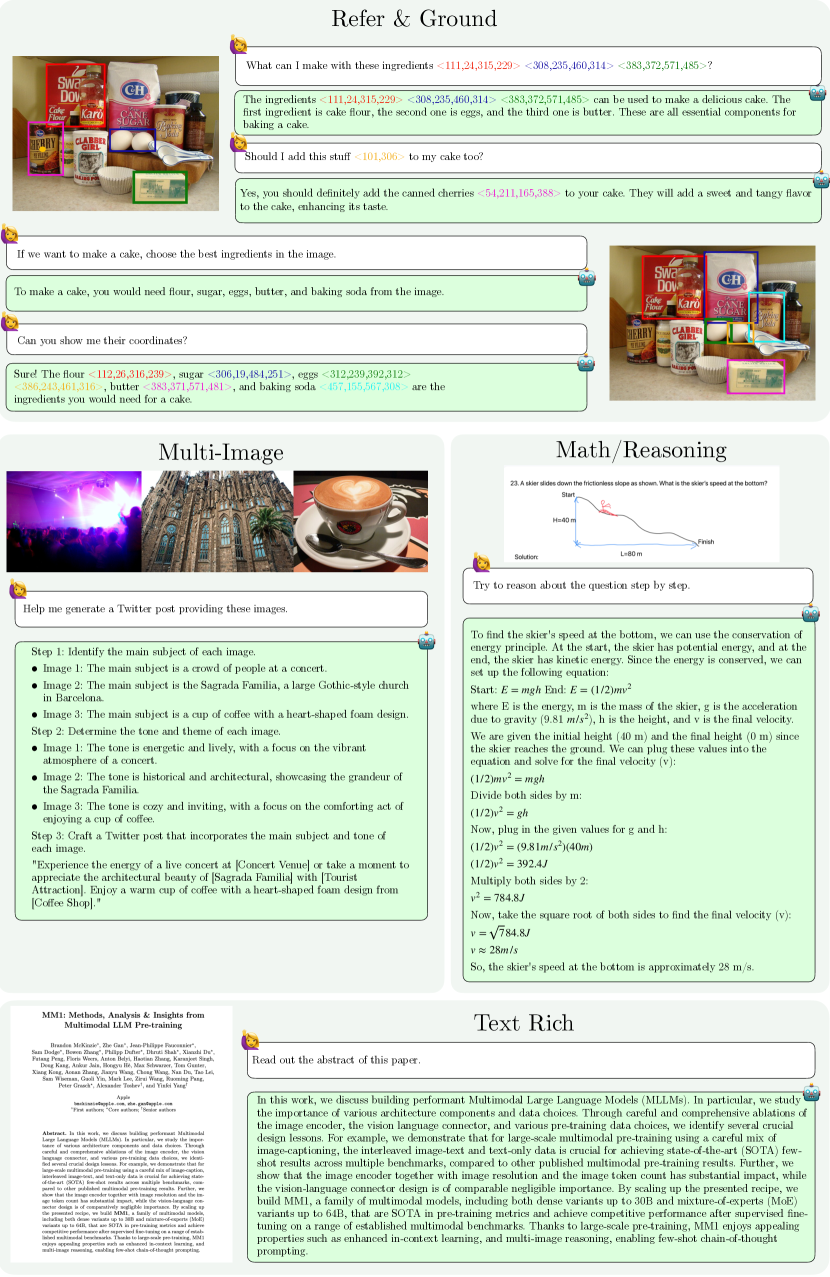
图 3: MM1.5 功能示例。 我们展示的示例是由 MM1.5-3B 模型生成的。 在附录 A.8 中可以找到更多示例。
我们的主要贡献总结如下:(𝑖) 我们介绍了 MM1.5,这是一个包含密集模型(范围从 1B 到 30B)和 MoE 变体的 MLLM 系列。 MM1.5 代表了对 MM1 118 的重大升级,在处理各种多模态任务方面表现出色,从通用领域到文本丰富的图像理解、从粗粒度到细粒度的理解以及从单图像到多图像推理。 (𝑖𝑖) 我们提出了两种专门的变体:MM1.5-Video,专为视频理解而设计,以及 MM1.5-UI,专为移动 UI 理解而设计。 (𝑖𝑖𝑖) 我们进行了一项彻底的实证研究,详细介绍了导致我们最终设计选择的流程和决策。
2相关工作
多模态大型语言模型 (MLLM) 125, 51, 149, 76, 49 近年来成为研究的重点领域。 MLLM 的发展可以追溯到 Frozen 153 和 Flamingo 4, 6,最近的进展如 LLaVA 102 和 MiniGPT-4 191 引入了视觉指令调优的概念。 过去一年见证了开源 MLLM 的繁荣,其中一些声称在某些基准测试中与 GPT-4o 相媲美。 值得注意的例子包括 Emu2 144, 143、VILA 97、Idefics2/3 68, 66、Cambrian-1 151、InternLM-XComposer-2.5 26, 182、InternVL2 22, 21、MiniCPM-V 169、CogVLM2 156, 43、BLIP-3 82, 166、LLaVA-OneVision 77、Llama3.1-V 29 以及最新的 Qwen2-VL 9。
MLLM 的研究已在多个方面扩展:(𝑖) 扩展预训练数据 97, 118, 166, 7, 87 和监督指令调优数据 47, 148, 68, 151;(𝑖𝑖) 增强高分辨率图像理解 99, 93, 101, 26, 37, 38, 17, 185, 165, 91;(𝑖𝑖𝑖) 探索各种视觉编码器 152, 135 和视觉语言连接器 14, 168, 88, 13;(𝑖𝑣) 使用专家混合 95, 80;(𝑣) 将 LLaVA 类架构扩展到区域级 157, 187, 179, 127, 16, 184, 170, 181 和像素级 65, 129, 176, 131 理解、多图像推理 53, 77、UI 理解 171, 44 和视频理解 96, 163, 164 等。
在关于 MLLM 的大量文献中,MM1.5 作为其前身 MM1 118 的重大升级而脱颖而出。 MM1.5 模型系列集成了各种核心功能,包括文本丰富的图像理解、视觉引用和定位以及多图像推理。 相比之下,最近的通用 MLLM,如 Cambrian-1 151 和 LLaVA-OneVision 77,在处理引用和定位任务方面表现不太令人满意,GPT-4o 必须依赖于标记集 (SoM) 提示 167 来理解图像区域。
尽管最近有几项工作开源了详细的 SFT 数据混合供公众使用 68, 151,但每个数据类别的确切影响以及最佳组合方法仍未得到充分探索。 这对于需要多种功能的模型尤其如此。 MM1.5 凭借其全面实证研究脱颖而出,该研究展示了构建高效多模态大语言模型 (MLLMs) 的成熟方案。 MM1.5 扩展到移动 UI 理解进一步增强了这项工作的独特性。
该领域另一个新兴趋势是开发轻量级 MLLMs,以实现潜在的边缘部署 55, 48, 11, 104, 42, 91, 190, 41。 在 MM1.5 中,提供了具有 10 亿和 30 亿参数的模型,这些模型的性能优于类似规模的模型,例如 Phi-3-Vision 3 和 MiniCPM-V 169。
3构建 MM1.5 的方案
开发和改进 MLLMs 是一种高度经验性的实践。 在这项工作中,除了包含 MM1 中的预训练和监督微调 (SFT) 阶段 118,我们还引入了一个使用高质量 OCR 数据和合成字幕的持续预训练阶段。 如图 2 所示,为了获得最佳数据方案,
-
•
我们首先对 SFT 数据混合进行全面消融研究(第 3.2 节)。 我们根据 SFT 数据旨在支持的功能将其分类为多个组。 我们仔细评估了每个类别数据集的影响,并调整了最终混合中每个类别的比例,以平衡不同的核心功能。
-
•
为了进一步提高模型性能,特别是对于富文本图像理解,我们进一步对持续预训练的数据选择进行了消融研究(第 3.3 节)。 这包括 4500 万个丰富的 OCR 数据和 700 万个由先前训练的基于 MM1 的图像字幕器生成的优质图像字幕。 VILA2 30 和 LLaVA-OneVision 74 中也探索了类似的想法。
-
•
最后,为了提高在 MMMU 等知识密集型基准上的性能 177,我们进一步研究了预训练数据的影响(第 3.4 节)。 我们保留了与 MM1 相同的图像字幕和交织图像文本数据 118,更新了纯文本数据,并仔细调整了数据混合比例,从而产生了经过显著细化的最终数据组合。
除了数据消融外,我们还提供了关于动态图像分割的详细消融,也称为 AnyRes 101(第 3.5 节,另见图 1),用于高分辨率图像理解。
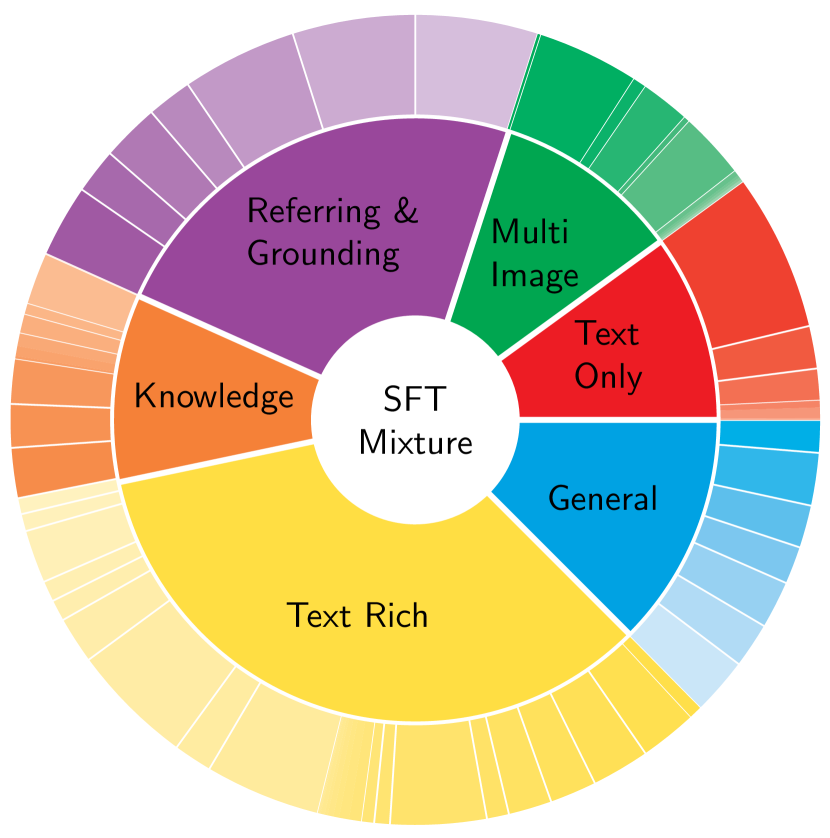
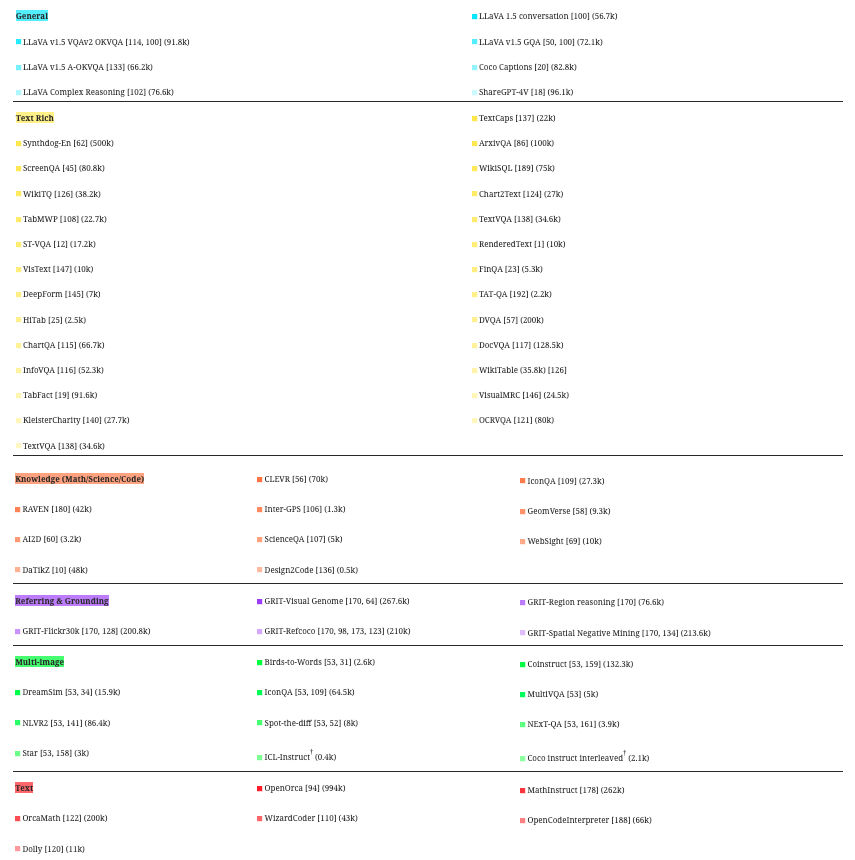
图 4: 用于 MM1.5 监督微调的高质量数据混合,包括 (𝑖) 用于增强数学/科学推理、富文本图像理解以及视觉参照和定位的单图像数据,(𝑖𝑖) 多图像数据,以及 (𝑖𝑖𝑖) 纯文本数据。 (†) 表示内部数据集,其整理详细信息在附录 A.3 中。
3.1消融的经验设置
除非另有说明,否则我们在消融研究中遵循以下默认设置。
模型架构和数据预处理。 我们使用与 MM1 118 相同的架构,专注于 3B 密集模型,用于本节中的所有消融研究。 具体来说,
-
•
静态图像分割 99 启用了 4 个子图像分割(加上一个概述图像),每个子图像通过位置嵌入插值调整为 672×672 分辨率。 请注意,我们在消融期间没有使用动态图像分割,以加快实验迭代速度。
-
•
关于多图像数据的编码,我们仅在当前训练样本包含少于三个图像时启用图像分割,以避免过长的序列长度。
-
•
与 Ferret 170 中介绍的功能类似,MM1.5 直接支持参照和定位。 应请求,MM1.5 可以在其文本输出中生成边界框以定位其响应。 此外,该模型可以解释对输入图像中的点和区域的引用,以参照坐标和边界框的形式(见图 1)。
-
•
与 MM1 一样,CLIP 图像编码器和 LLM 主干基于我们的内部模型,其中 C-Abstractor 14 作为视觉语言连接器。
模型优化。 对于持续预训练和 SFT,我们将批次大小设置为 256。 我们使用 AdaFactor 优化器,峰值学习率为 1e-5,余弦衰减为 0。 对于持续预训练,我们最多训练 30k 步。 在 SFT 期间,所有模型都经过一个 epoch 的优化。
持续预训练。 模型使用 MM1 预训练检查点进行初始化。 默认情况下,我们在 45M 高分辨率 OCR 数据(包括 PDFA、IDL、渲染文本 68 和 DocStruct-4M 46 1 )上进行持续预训练。 在每个训练批次中,数据从这四个数据集中等量采样。 与 SFT 阶段类似,我们使用静态图像分割,将每个图像分成五个子图像,每个子图像调整大小到 672×672 分辨率。 我们发现这种高分辨率设置对于持续预训练至关重要。
SFT 数据分类。 将数据集分组到类别中可能有助于数据平衡和简化分析 68, 151。 在高级别上,我们根据每个示例中呈现的图像数量将数据集聚类到 单图像、多图像 和 纯文本 类别中。 对于单图像组,我们进一步将每个数据集分类为以下子类别:general,text-rich,refer&ground,science,math 和 code。 请参见附录 A.2 中的表格 13,以了解用于消融研究的每个类别的详细信息,以及图 4,以了解组类别的概述。
评估基准。 我们根据基准主要衡量的能力将基准分组。 我们的基准组包括一般、文本丰富、参考和接地、知识和多图像。 请参见附录 A.4 中的表格 14 以了解更多详细信息。 我们提出Category Average Score,即每个子类别所有基准数字的平均分数,以表示该能力的平均性能。 我们专注于一般、文本丰富和知识类别,因为这些能力被广泛认为是 MLLM 的必要条件。 为了评估模型对这些能力的影响,我们参考一个 MMBase 分数,定义为一般、文本丰富和知识类别的平均分数。 评估指标的详细信息见附录 A.4。
3.2SFT 消融

图 5: 不同 SFT 数据类别对不同模型能力(一般、文本丰富、知识和参考和接地)的影响。 文本丰富数据平均显着提高了文本丰富和知识基准。 科学数据提高了知识平均得分。 参考和接地数据使这种能力成为可能。
为了确定最佳的 SFT 方案,我们首先在第 3.2.1 节中研究了不同数据类别带来的影响,然后在第 3.2.2 节中研究了如何最佳地混合所有数据。
CSDN独家福利
最后,感谢每一个认真阅读我文章的人,礼尚往来总是要有的,下面资料虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

3.2.1不同数据类别的影响
在本小节中,我们重点评估单图像数据类别。 我们首先评估通用数据类别,然后逐步评估单独添加其他子类别带来的影响。 在训练过程中,我们混合来自不同子类别的数据,并通过随机抽样对应混合中的数据来构建每个训练批次。 我们使用 类别平均得分 来比较每个能力的模型。
我们的结果总结在图 5 中。 我们观察到,添加文本丰富的数据可以显著提高文本丰富和知识基准的性能。 数学数据的加入遵循类似的趋势,尽管我们观察到文本丰富平均得分提高的程度较小。 当添加科学数据时,我们观察到知识基准的预期改进,以及文本丰富性能的轻微改进。 添加代码类别会导致文本丰富平均得分略微增加,而其他基准的性能没有提高。 包括参照与定位数据将赋予模型参照和定位能力,但我们也观察到所有其他能力类别的轻微下降。
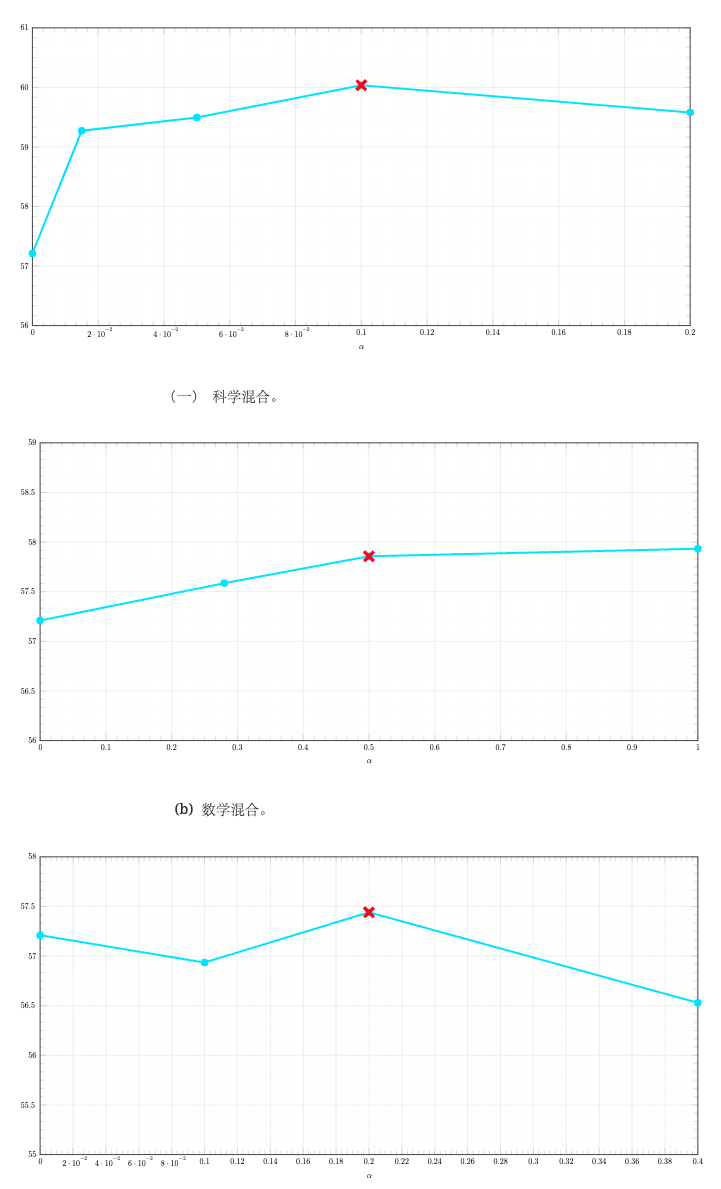
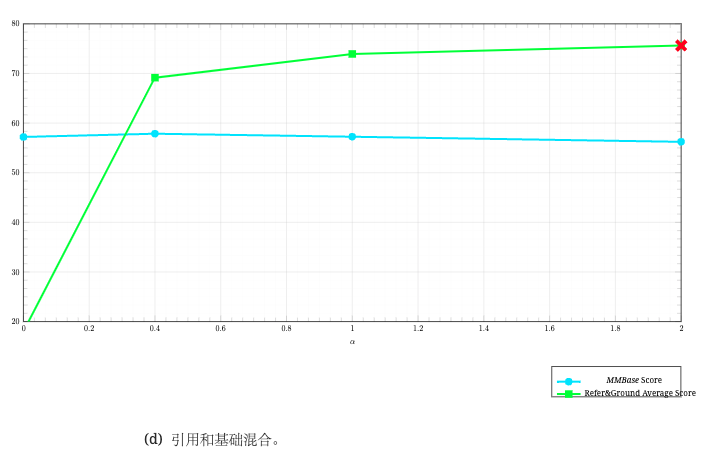
图 6:不同数据类别的 𝛼 对模型不同功能的影响。 所选比例用红色"x"标记。 𝛼 表示目标类别(科学、数学、代码、引用和基础)与一般类别的比较数据比例。
3.2.2数据混合比例研究
我们首先研究单图像类别内的混合比例。 由于根据数据大小直接混合一般数据和文本丰富数据在各种基准测试中显示出强大的结果(见图 5),我们使用这种组合作为起点来研究如何将其他类别混合到该集合中。 然后,我们将整个单图像集与多图像集和仅文本集结合在一起,采样权重分别为 𝑤single、𝑤multi 和 𝑤text,其中 𝑤single+𝑤multi+𝑤text=1。
单图像数据的混合。 由于不同子类别的数据样本数量不平衡,直接混合来自不同类别的所有数据集可能并不理想。 例如,一般数据类别的规模大约是科学数据类别规模的 68× 倍。 在本研究中,我们使用一般数据类别作为参考,并对来自目标类别的数据进行上采样/下采样,以便在每个训练批次中,来自一般类别和目标类别的数据比率为 1:𝛼。
为了衡量 𝛼 的平均影响,我们提出了 MMBase 分数,它是模型比较的通用、富文本和知识平均分数的平均值。 如图 6 所示,我们为不同的数据类别改变了 𝛼。 对于科学、数学和代码类别,我们发现 𝛼 的最佳比例分别为 0.1、0.5 和 0.2。 如第 3.2.1 节所示,参考和基础数据是改进参考和基础基准的主要驱动力。 因此,除了 MMBase 分数外,我们还将参考和基础平均分数作为另一个指标用于 𝛼 选择。 如图 6(d) 中所总结的那样,MMBase 分数将略微下降,而参考和基础平均分数将显着提高。 因此,我们选择 𝛼=2.0 作为一种良好的权衡方案。
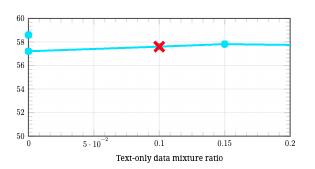
图 7: 仅文本和多图像 SFT 数据的混合比例的影响。 选择的比例用红色"x"标记。
单张图像、多张图像和纯文本数据的混合。 现在,我们研究混合比例,𝑤single、𝑤multi 和 𝑤text。 枚举这三种比例之间所有组合将产生巨大的计算成本。 因此,我们分别对纯文本数据和多图像数据进行了 𝑤text 和 𝑤multi 的消融研究,以评估我们的模型对这些比例的敏感程度。 最后,𝑤single 由 1−𝑤text−𝑤multi 决定。
与单张图像混合研究类似,我们也从通用数据和文本丰富数据的组合开始,并枚举 𝑤multi 和 𝑤text 的不同值。 对于纯文本数据,我们测试了 𝑤text 从 0 到 0.2 的范围。 图 7(左) 显示,改变 𝑤text 的不同值对模型在一般情况下的基本能力影响很小。 我们选择 𝑤text=0.1 为单张图像数据分配更高的权重,以获得潜在的性能提升。
对于多图像数据,我们使用多图像平均得分(在表 14 中的多图像基准上评估)作为额外的指标来评估模型处理多图像任务的能力。 结果总结在图 7(右) 中。 我们观察到,增加多图像数据的采样比例会降低基本能力的性能,如 MMBase 得分减少所示,而多图像平均得分会增加。 我们选择 𝑤multi=0.1,因为它会导致多图像平均得分大幅上升。
混合多个类别。 基于以上研究,我们展示了三种混合,即 Base 混合,Single-image 混合和 All 混合,并分析它们的权衡。 Base 混合包括通用数据、文本丰富数据、科学 (𝛼science=0.1)、数学 (𝛼math=0.5) 和代码 (𝛼code=0.2) 数据组。 单图像 Single-image 混合体还将参考和接地数据 (𝛼rg=2.0) 添加到 Base 混合体中。 All 混合体包含来自单图像、多图像和仅文本数据的所有数据,以及 𝑤single=0.8、𝑤multi=0.1 和 𝑤text=0.1。
我们的结果总结在图 8 中。 前三列表明,包含参考和接地数据以及多图像数据略微降低了文本密集、知识和一般基准的平均性能。 第四列显示,添加参考和接地数据显着提高了参考和接地性能,而第五列则强调,添加多图像数据极大地提高了多图像基准。 最后一列表明,我们优化的混合体在所有基准上平衡了所有能力,从而实现了最佳的整体性能。
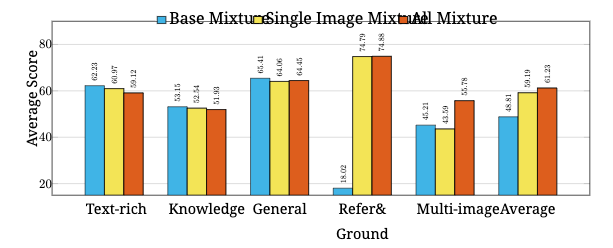
图8: 对混合所有 SFT 数据进行消融研究。 Base Mixture 表示一般、文本密集和知识(科学、数学和代码)。 "平均"列表示在前面五个基准类别中计算的平均性能。
3.3持续预训练消融
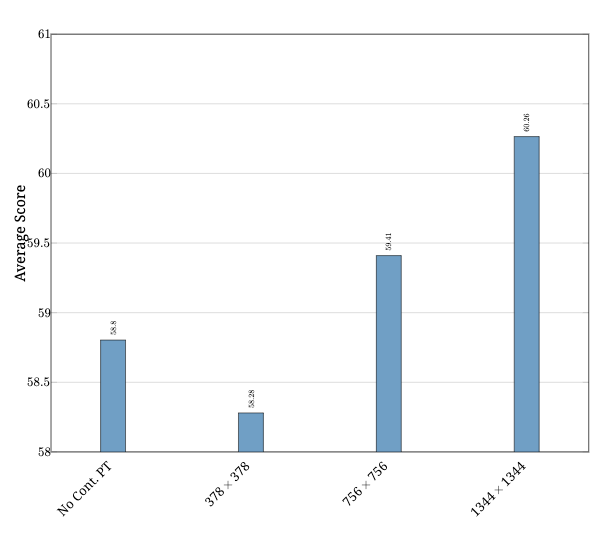
(一) 输入分辨率的影响。 OCR 数据用于所有持续预训练实验。
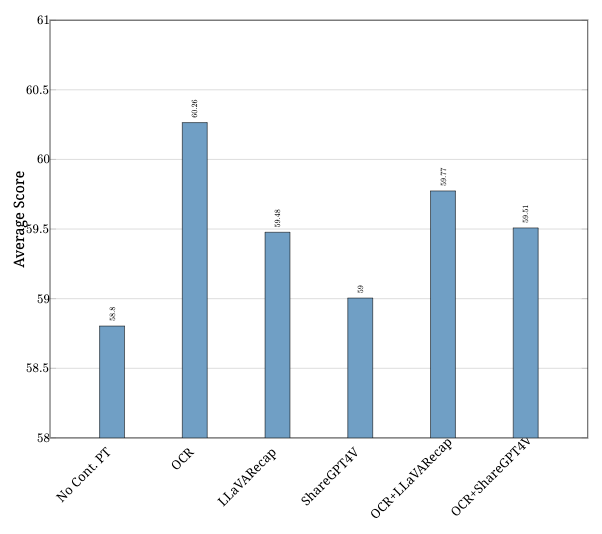
(b) 数据源的影响。 持续预训练在高分辨率 (1344×1344) 设置中进行。
图 9: 持续预训练的消融研究。 平均得分表示 MMBase 得分。 持续 PT 表示持续预训练。
除非另有说明,否则我们在高分辨率设置 (1344×1344) 中使用 OCR 数据(总共 45M),包括 PDFA、IDL、渲染文本68 和 DocStruct-4M46 进行持续预训练。 在 SFT 阶段,本节中的所有持续预训练模型都使用来自 Base Mixture 的数据进行微调,包括一般、文本丰富的知识(科学、数学和代码),以及它们在第 3.2.2 节中描述的所选混合比率。
图像分辨率的影响。 直观地说,使用 OCR 数据训练时,更高分辨率的图像更可取。 我们首先通过建立两个基线来消除此阶段图像分辨率的影响,分别使用 378×378 和 756×756 分辨率进行持续预训练。 对于前者,我们禁用了图像分割和位置嵌入插值(我们的 CLIP 图像编码器原生支持 378×378 的图像分辨率)。 对于后者,我们启用了图像分割并关闭位置嵌入插值。 结果如 图 9(a) 所示。 注意,在这些实验中,最终的 SFT 阶段始终使用 1344×1344 的图像分辨率,因此训练仅在持续预训练中使用的图像分辨率方面有所不同。
我们可以清楚地看到,使用 1344×1344 的图像分辨率进行持续预训练可以实现最佳的整体性能。 降低分辨率始终会导致最终分数降低。 特别是,使用 378×378 分辨率进行持续预训练的模型可能会比没有持续预训练的模型表现更差。 我们假设这是由于较低分辨率下可见细节不足,这可能会阻碍模型有效地从持续预训练混合中的基于文档的 OCR 数据中学习。
OCR 数据和合成字幕的影响。 除了 OCR 数据,高质量的合成图像字幕 18, 71 也被广泛认为对预训练很有用。 为了研究其影响,我们使用默认设置,除了在持续预训练中使用的数据。 我们研究了两个合成字幕数据集:LLaVA-Recap-3M 71 和 ShareGPT4V-PT 18,以及它们与我们的 OCR 数据的组合。 当我们将 ShareGPT4V-PT 或 LLaVA-Recap-3M 与我们的 OCR 数据组合时,我们在每个训练批次中从各个数据集平等地采样数据。 结果如 图 9(b) 所示。 我们观察到所有持续预训练的模型都比没有持续预训练的基线模型表现更好。 但是,我们没有找到确凿的证据表明这些高质量的合成字幕比可以说更简单的 OCR 数据更能提高性能。 虽然之前的一些研究 74 表明合成字幕可以提高性能,但我们的结果表明需要进一步研究其确切的影响。
因此,我们进一步研究了通过自训练生成的合成字幕对更大规模(高达 7M)和更可控风格的影响,使用在人类标注的字幕上微调的预训练 MM1 模型,类似于 30。 这组新数据集在某些环境中展现出了一些希望,详见附录 A.1。 我们将在未来的工作中进一步研究这个课题。
3.4预训练消融
除了 SFT 和持续预训练之外,我们强调在预训练过程中使用大规模、特定任务的数据对于建立模型有效处理各种任务的稳固基础的重要性。 对于像 MMMU 177 这样对知识要求很高的基准测试,我们发现模型性能对它的文本理解能力高度敏感。 LLM 理解和处理文本内容的能力对于解决这些基准测试中提出的复杂推理和知识表示挑战至关重要,正如在 Cambrian-1 151 中观察到的那样。
我们在预训练阶段加入了 39 提出的更高质量、更多样化的纯文本数据集,称为 HQ-Text。 这些数据集经过专门策划,通过提供更深入、更多样的文本内容来增强模型的语言能力,重点关注常识、数学和编码。 此更新旨在增强模型在基于语言的推理方面的能力。
如图 10 所示,只需用新数据替换,知识方面的平均得分就提高了 0.85 分。
结合纯文本数据集和第 3.2 节中讨论的最新 SFT 方法,我们进一步完善了预训练数据组合。 MM1 118 中提出的原始数据比例分别为图像-标题、交错图像-文本和纯文本数据的 45:45:10。 进一步的实验表明,减少交错预训练数据的数量,同时相应地将纯文本数据的权重增加到 50:10:40 的比例,可以在 SFT 之后提高大多数任务的性能。 我们注意到,与 MM1 中的预训练消融不同,对于 MM1.5,我们在 SFT 后的下游基准测试上进行评估以选择我们最终的预训练混合。 我们假设主要依赖于少样本预训练指标可能不是理想的,因为这种评估上的改进可能无法有效地转移到下游性能。 我们为 MM1.5 优化的新数据混合不仅增强了多模态能力,还加强了语言理解,从而在各基准测试中取得了优异的整体性能。
通过更新混合数据,文本丰富类平均性能提升了 0.85,知识类平均提升了 0.99,参考和地面任务提升了约 1.4,如图 10 所示。 尽管由于交叉数据的权重较低,多图像数据集略有下降 0.05,但我们认为这种权衡是合理的,因为它可以保证所有任务都能保持良好的性能。
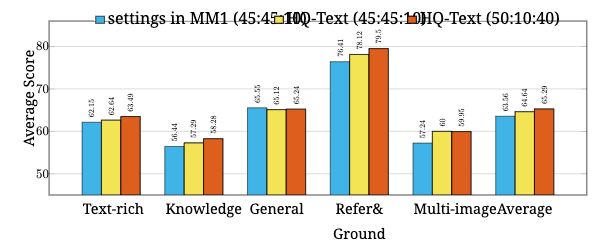
图 10: 所有类别在不同纯文本数据和预训练数据比例上的性能比较。 该图突出了用 HQ-Text 数据替换后的性能提升,以及将比例调整为 50:10:40 所取得的额外收益。 注意,所有模型都使用持续预训练(OCR)的默认设置和 SFT 的 All Mixture 设置。
3.5动态图像分割消融研究
为了有效地处理具有可变纵横比和分辨率的图像,我们引入了 动态 图像分割方法,用于高分辨率图像编码。 我们还详细说明了这种提出的分割方法的消融设置和相应结果。
动态图像分割。 处理高分辨率图像对于文本丰富的图像理解至关重要。 在 静态 图像分割 99 中,图像被分割成多个子图像,并由视觉编码器分别编码。 LLM 然后可以访问同一图像的多个块,从而实现更高的有效分辨率。 然而,将每个图像分割成一个严格的 2×2 网格通常效率低下。 低分辨率图像在不需要的情况下被分割,而具有非正方形纵横比的图像会导致子图像仅被填充。 因此,我们采用动态图像分割方法,这在文献 71, 27, 46, 99, 165, 185中很常见,用于 MM1.5。

图 11: 用于高分辨率图像编码的动态图像分割中使用的图像网格选择说明。 (左) 如果网格可以在不缩小的前提下覆盖整个图像,我们选择最小化填充的网格。 (右) 否则,我们选择最小化由于缩小而导致的分辨率损失的网格。
给定最小和最大子图像数量,𝑛min 和 𝑛max,考虑所有候选网格 𝐺={(𝑛ℎ,𝑛𝑤)∈ℕ|𝑛min≤𝑛ℎ⋅𝑛𝑤≤𝑛max}。 此外,考虑视觉编码器的分辨率 𝑟 和输入图像分辨率 (ℎ,𝑤)。 如果存在一个网格可以覆盖图像,我们选择在长边调整到网格后最小化填充量的网格,即,
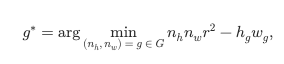
受制于 𝑛ℎ𝑟≥ℎ𝑔≥ℎ 和 𝑛𝑤𝑟≥𝑤𝑔≥𝑤,其中 ℎ𝑔,𝑤𝑔 表示候选网格长边调整后图像的高度和宽度。 如果不存在这样的网格,我们选择最小化由于将图像缩小而导致的分辨率损失并完全覆盖长边调整后的图像的网格。
图 11 可视化了两种情况下最小化的区域。 假设我们允许最多 4 个子图像。 使用静态图像分割方法,所有图像都使用网格 (2,2)。 动态分割方法允许以下网格:{(1,1),(1,2),(2,1),(1,3),(3,1),(1,4),(4,1),(2,2)}。
全局-局部格式。 除了子图像之外,我们还始终将长边调整到编码器分辨率 𝑟 的原始图像馈送到模型。 这确保了模型对图像有一个全局的理解。 如果网格是 (1,1),我们省略概览图像。 我们考虑两种变体: (𝑖) 之前:概览图像放在子图像之前; (𝑖𝑖) 之后:概览图像放在子图像之后。 这些变体产生不同的结果,因为在 LLM 解码器中使用了自回归掩码,因此,选择决定了解码器在处理子图像时是否可以关注概览图像 (𝑖),或者在处理概览图像时是否可以关注子图像 (𝑖𝑖)。
子图像位置指示器。 鉴于输入图像被动态地分割成多个子图像,我们探索是否可以帮助指示每个子图像在原始高分辨率图像中的位置,以确保模型能够理解原始二维图像结构。 具体来说,我们考虑两种方法。
-
•
索引。 一个 (𝑘,𝑖,𝑗) 元组用于表示子图像位置信息,其中 𝑘 是示例中图像的零索引编号(假设训练样本中可能有多个图像),𝑖 和 𝑗 是单索引行和列 ID,例如,(0,0,0) 是图像 0 的概览图像,而 (0,2,1) 是图像 0 中第二行第一列的子图像。
-
•
间隔。 我们使用三个文本符元来代替使用索引。 具体来说,':' 是概览图像指示器,',' 是列分隔符,而 '' 是行分隔符。 后两个符元插入到对应于每个子图像的图像符元集中,以便从扁平化的图像符元序列中恢复原始二维图像结构。
|------|---------|----|------------------------------------|----------------------|---------------------|-----------|-----------|---------|----------------|---------|
| Row# | Mode | 𝑛 | #image tokens(per sub-img / total) | Image Enc.Resolution | EffectiveResolution | Text-rich | Knowledge | General | Refer &Ground | Average |
| 1 | Static | 1 | 144/144 | 672×672 | 0.45MP | 49.4 | 53.6 | 62.6 | 71.3 | 59.2 |
| 2 | Static | 5 | 144/720 | 672×672 | 1.8MP | 57.7 | 53.8 | 64.4 | 74.8 | 62.7 |
| 3 | Dynamic | 5 | 144/720 | 672×672 | 1.8MP | 58.6 | 53.7 | 64.1 | 74.0 | 62.5 |
| 4 | Dynamic | 10 | 81/810 | 378×378 | 1.3MP | 57.6 | 53.3 | 62.9 | 74.0 | 62.0 |
| 5 | Dynamic | 10 | 81/810 | 672×672 | 4.1MP | 58.3 | 53.8 | 64.3 | 74.9 | 62.8 |
| 6 | Dynamic | 10 | 144/1440 | 378×378 | 1.3MP | 58.5 | 54.0 | 63.2 | 74.5 | 62.6 |
| 7 | Dynamic | 10 | 144/1440 | 672×672 | 4.1MP | 59.8 | 54.0 | 64.5 | 75.2 | 63.3 |
表 1: 关于动态图像分割中使用的图像分辨率和图像符元数量的消融研究。 𝑛 表示子图像的总数。 第 3 行: (𝑛min,𝑛max)=(4,4); 第 4-7 行: (𝑛min,𝑛max)=(9,9). 图像编码器分辨率: (𝑖) 378×378: 无位置嵌入插值; (𝑖𝑖) 672×672: 有位置嵌入插值。
|-----|--------|-----------|--------|---------|-----------|-----------|---------|----------|---------|
| Row | (𝑛min,𝑛max) || DocVQA | InfoVQA | Text-rich | Knowledge | General | Refer & | Average |
| # | Train | Inference | DocVQA | InfoVQA | Text-rich | Knowledge | General | Ground | Average |
| 3B Model Comparison ||||||||| |
| 1 | (4,4) | (4,4) | 73.2 | 48.3 | 58.6 | 53.3 | 64.1 | 74.0 | 62.5 |
| 2 | (4,9) | (4,9) | 75.7 | 53.8 | 60.0 | 54.0 | 63.9 | 74.6 | 63.1 |
| 3 | (4,16) | (4,16) | 76.3 | 55.2 | 60.7 | 53.4 | 64.0 | 73.8 | 63.0 |
| 4 | (1,9) | (1,9) | 76.2 | 54.1 | 60.4 | 53.7 | 62.5 | 71.5 | 62.0 |
| 5 | (4,4) | (4,9) | 73.4 | 52.9 | 59.7 | 53.5 | 63.8 | 74.0 | 62.8 |
| 6 | (4,4) | (4,16) | 72.3 | 53.5 | 59.6 | 53.8 | 63.5 | 74.0 | 62.7 |
| 7 | (4,4) | (1,9) | 73.5 | 52.7 | 59.8 | 50.7 | 62.6 | 24.5 | 49.4 |
| 7B Model Comparison ||||||||| |
| 8 | (4,4) | (4,4) | 77.0 | 54.3 | 64.5 | 61.1 | 66.8 | 77.7 | 67.5 |
| 9 | (4,9) | (4,9) | 81.7 | 62.1 | 67.4 | 60.1 | 66.6 | 78.0 | 68.0 |
| 10 | (4,16) | (4,16) | 83.3 | 64.1 | 68.0 | 58.7 | 67.7 | 77.2 | 67.9 |
表 2: 动态图像分割中使用的图像网格配置 (𝑛min,𝑛max) 的消融研究。
更高分辨率的推理。 元组 (𝑛min,𝑛max) 用于决定模型训练的动态图像分割配置。 在推理过程中,可以通过简单地增加这些参数来支持更高分辨率的图像处理。 例如,我们探索在 (𝑛min,𝑛max)=(4,9) 处进行训练以节省模型训练计算量,而在推理过程中,我们使用 (𝑛min′,𝑛max′)=(4,16) 以更高的有效分辨率处理图像。
3.5.1消融研究结果
在本节中,我们使用最终的 单图像混合 作为我们的默认实验设置,包括通用、富文本、知识(科学、数学和代码)和参考与地面真实数据。 为了快速迭代实验,所有模型都使用 MM1 预训练检查点初始化,没有进行持续预训练。 遵循图 5,我们报告了在富文本、知识、通用和参考与地面真实基准上的平均性能。 我们的发现总结如下。
图像分辨率和图像符元数量的影响(表 1)。 即使在两者都使用相同最大 5 个子图像的情况下,动态图像分割也比静态图像分割(第 2 行与第 3 行)获得了更好的富文本性能。 我们观察到,富文本任务对图像分辨率和子图像数量都很敏感,而其他任务则不太受影响。 请注意,增加子图像的数量意味着图像符元总数的增加。 具体而言,在相同有效分辨率的情况下,更多图像符元会提高富文本性能(第 4 行与第 6 行,第 5 行与第 7 行)。 反之,在相同图像符元数量的情况下,更高的有效分辨率会带来更好的富文本性能(第 4 行与第 5 行,第 6 行与第 7 行)。 总体而言,使用最多 10 个子图像,图像编码器分辨率为 672×672,每个子图像使用 144 个符元(第 7 行)可以实现最佳性能。
图像网格配置的影响(表 2)。 使用更大的 𝑛max 的动态图像分割特别适合于不寻常的长宽比,例如文档和信息图表理解。 它通过将 𝑛max 从 4 更改为 16(第 1 行至第 3 行),分别将 DocVQA 和 InfoVQA 的性能提高了 3.1 和 6.9 个点。 在推理过程中,仅增加子图像数量也可以提高性能,但针对其进行本地训练会带来更好的结果(第 2 行与第 5 行,第 3 行与第 6 行,第 4 行与第 7 行)。 地面真相性能对最小网格尺寸的变化高度敏感,例如仅在推理过程中将最小子图像数量从 4 更改为 1(第 7 行),因为这会影响大量数据的本地坐标到全局坐标的转换。 最后,我们观察到,随着 LLM 主干的增大,性能改进也更大。 具体来说,对于 7B 大小,我们观察到 DocVQA 和 InfoVQA 分别增加了 6.3 和 9.8 个点(第 8 行与第 10 行)。 相比之下,3B 大小模型显示出 3.1 和 6.9 个点的改进(第 1 行与第 3 行)。
子图像位置指示器和概述图像位置的影响(表 3)。 我们发现位置指示器并非严格必要(第 1 行至第 3 行)。 之前的消融研究,例如在 27 中,表明这可能是有益的,特别是对于 DocVQA 和 InfoVQA,这与我们的发现一致。 但是,平均而言,我们没有看到对富文本任务的显著影响。 索引位置指示器似乎有助于参照和定位,这是预期的,因为空间理解对于这些任务至关重要。 将概述图像放在子图像之后略微提高了性能(第 1 行与第 4 行),因为解码器注意力掩码允许概述图像关注所有子图像。
|------|-----------------------|--------------------|--------|---------|-----------|-----------|---------|----------------|---------|
| Row# | Sub-imgpos. indicator | Overviewimage pos. | DocVQA | InfoVQA | Text-rich | Knowledge | General | Refer &Ground | Average |
| 1 | none | before | 73.2 | 48.3 | 58.6 | 53.5 | 64.1 | 74.0 | 62.5 |
| 2 | seps | before | 74.3 | 49.7 | 58.8 | 53.0 | 63.8 | 74.5 | 62.5 |
| 3 | index | before | 73.4 | 48.6 | 58.6 | 52.7 | 63.4 | 74.8 | 62.4 |
| 4 | none | after | 73.3 | 49.7 | 59.2 | 54.3 | 64.1 | 73.8 | 62.8 |
表 3: 子图像位置指示器和概述图像位置的消融研究。 我们为实验设定了 (𝑛min,𝑛max)=(4,4) 。
效率。 虽然动态图像分割优于静态分割的一个可能解释是,为了性能而牺牲额外的计算量,因此允许高分辨率输入具有更多总子图像,但这并不一定总是这样。 在从附录 A.2 中描述的单图像训练数据混合中随机抽取的 100,000 个示例中,静态分割总共生成了 500,000 个子图像。 相比之下,具有 (𝑛min,𝑛max)=(4,9) 的动态分割产生的图像略多,总共只有 539,000 个图像。
4最终模型和训练方案
|---------------------|---------------------------------------------------------|----------|----------------|----------|---------------|-----------------|--------------|
| Capability | Benchmark | MM1.5 1B | MM1.5 1B (MoE) | MM1.5 3B | MiniCPM-V2 3B | Phi-3-Vision 4B | InternVL2 2B |
| GeneralVQA | MME 32 (SUM) Multi-discip | 1611.4 | 1873.0 | 1798.0 | 1808.2 | 1761.6 | 1864.3 |
| GeneralVQA | SeedBench 75 (image) Multi-discip; Large-scale | 70.2% | 71.4% | 72.4% | 67.1% | 71.8% | 70.9% |
| GeneralVQA | POPE 92 Obj. Hallu | 88.1% | 88.6% | 88.1% | 87.8% | 85.8% | 85.2% |
| GeneralVQA | LLaVAW 102 OOD General | 71.6 | 75.5 | 73.0 | 69.2 | 71.6 | 60.0 |
| GeneralVQA | MM-Vet 174 Multi-discip | 37.4% | 39.8% | 41.0% | 38.2% | 46.2% | 39.7% |
| GeneralVQA | RealworldQA 160 Realwold QA | 53.3% | 57.8% | 56.9% | 55.8% | 59.4% | 57.4% |
| Text-rich | †WTQ 126 Wiki-table Questions | 34.1% | 38.9% | 41.8% | 24.2% | 47.4% | 35.8% |
| Text-rich | †TabFact 19 Table Fact Verification | 66.1% | 71.4% | 72.9% | 58.2% | 67.8% | 56.7% |
| Text-rich | OCRBench 103 OCR; Multi-discip | 60.5% | 62.6% | 65.7% | 60.5% | 63.7% | 78.1% |
| Text-rich | †ChartQA 115 Chart Understanding | 67.2% | 73.7% | 74.2% | 59.8% | 81.4% | 76.2% |
| Text-rich | †TextVQA 138 OCR; Reason | 72.5% | 76.1% | 76.5% | 74.1% | 70.1% | 73.4% |
| Text-rich | †DocVQA 117 (test) Document Understanding | 81.0% | 84.8% | 87.7% | 71.9% | 83.3% | 86.9% |
| Text-rich | †InfoVQA 116 (test) Infographic Understanding | 50.5% | 55.9% | 58.5% | 37.6% | 49.0% | 58.9% |
| Knowledge | †AI2D 61 Science Diagrams | 59.3% | 67.1% | 65.7% | 62.9% | 76.7% | 74.1% |
| Knowledge | †ScienceQA 107 High-school Science | 82.1% | 87.6% | 85.8% | 80.7% | 90.8% | 94.1% |
| Knowledge | MMMU 177(val, w/o CoT) College-level Multi-discip | 35.8% | 41.2% | 37.1% | 38.2% | 40.4% | 36.3% |
| Knowledge | MathVista 105 (testmini) General Math Understanding | 37.2% | 42.9% | 44.4% | 38.7% | 44.5% | 46.0% |
| Refer&Ground | †RefCOCO 59 (avg) Visual Ground | 81.4% | 83.9% | 85.6% | -- | 38.1% | 77.7% |
| Refer&Ground | †Flickr30k 172 (test) Phrase Ground | 83.0% | 85.4% | 85.9% | -- | 27.1% | 51.6% |
| Refer&Ground | LVIS-Ref 170 (avg) Obj. Refer | 62.2% | 64.1% | 67.9% | 48.0% | 54.2% | 51.1% |
| Refer&Ground | Ferret-Bench 170 Refer Reason | 67.4 | 69.6 | 69.5 | 22.1 | 32.2 | 34.9 |
| Multi-image | †Q-Bench2 186 Low-level percep | 66.4% | 70.9% | 73.2% | -- | 56.8% | 52.0% |
| Multi-image | Mantis 53 Multi-image in the Wild | 50.7% | 51.2% | 54.8% | -- | 47.9% | 53.0% |
| Multi-image | †NLVR2 141 Visual Reason | 79.0% | 83.2% | 83.8% | -- | 53.6% | 67.4% |
| Multi-image | MVBench 85 Multi-discip | 45.8% | 48.3% | 47.7% | -- | 46.7% | 60.2% |
| Multi-image | BLINK 35 Unusual Visual Scenarios | 46.3% | 43.7% | 46.8% | 41.2% | 44.2% | 42.8% |
| Multi-image | MuirBench 155 Comprehensive Multi-image | 34.7% | 40.9% | 44.3% | -- | 38.0% | 23.1% |
| In-context Learning | VL-ICL 193 (avg) Multimodal In-context | 51.0% | 56.0% | 56.3% | -- | 19.5% | 18.5% |
表 4: 与跨不同基准的 SOTA 移动友好模型的比较。 (†) 表示训练集在我们数据混合中被观察到。 MiniCPM-V2 169 和 InternVL2 21 使用集束搜索解码,而 Phi-3-Vision 3 和我们的 MM1.5 模型使用贪婪解码。 对于所有多项选择题(MCQ)基准(例如 ,AI2D、OCRBench),我们的模型输出 不 由 ChatGPT 后处理,保持顺序、标点符号和大小写敏感性不变。
7结论
在这项工作中,我们在 MM1 118 的见解基础上,引入了 MM1.5,这是一系列高性能的通用 MLLM。 MM1 对关键预训练选择进行了广泛的研究,这项工作通过关注如何进一步提高预训练后的性能来补充 MM1,超越 MM1 设置的强大基线。 具体来说,我们专注于完善持续预训练技术、动态高分辨率图像处理以及对监督微调数据集的精心策划。 我们提供了大量的消融实验和论证,并表明我们的选择使 MM1.5 模型家族能够在各种核心能力中取得优异的结果,包括富文本图像理解、视觉引用和定位以及多图像推理。 此外,我们还展示了如何将我们的通用模型进一步微调以用于视频和 UI 理解。 未来工作将旨在将这些能力统一成一个更强大的通用模型。 我们希望这些见解能够通过帮助他们构建超越任何特定架构或代码库的强大模型,使社区受益。
CSDN独家福利
最后,感谢每一个认真阅读我文章的人,礼尚往来总是要有的,下面资料虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走: