1.项目背景
随着二手车市场的快速发展,消费者对二手车的需求逐渐增加,然而,由于二手车的定价涉及多种复杂因素,不同条件下的车辆价值差异较大,如何精准地评估二手车的市场价值成为了一个亟待解决的问题。本项目通过数据分析和机器学习建模,尝试识别并量化影响二手车价格的主要因素,并构建一个价格预测模型,为消费者和行业从业者提供数据支持。
2.数据说明
| 字段 | 说明 |
|---|---|
| id | 唯一标识符 |
| brand | 品牌 |
| model | 具体型号 |
| model_year | 汽车的制造年份 |
| milage | 汽车的行驶里程 |
| fuel_type | 汽车所使用的燃料类型 |
| engine | 发动机规格 |
| transmission | 变速器类型 |
| ext_col | 外观颜色 |
| int_col | 内饰颜色 |
| accident | 车辆是否有事故或损坏的历史记录 |
| clean_title | 是否拥有健全良好的所有权证明 |
| price | 汽车标价 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import re
from scipy.stats import chi2_contingency,ks_2samp,spearmanr,f_oneway
from datetime import datetime
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import RidgeCV, Ridge
from sklearn.preprocessing import StandardScaler
train_data = pd.read_csv("/home/mw/input/10128271/train.csv")
test_data = pd.read_csv("/home/mw/input/10128271/test.csv")4.数据预处理
4.1数据预览

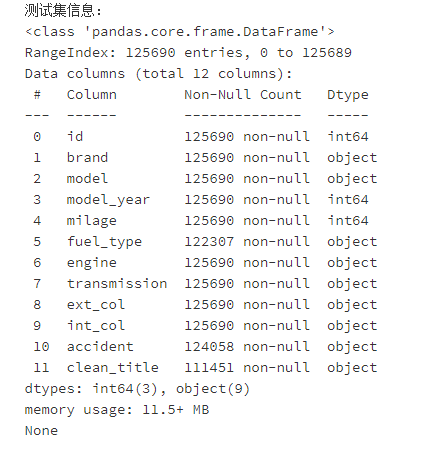
两个数据均存在不同程度的缺失值。
训练集中存在的重复值:0
测试集中存在的重复值:0

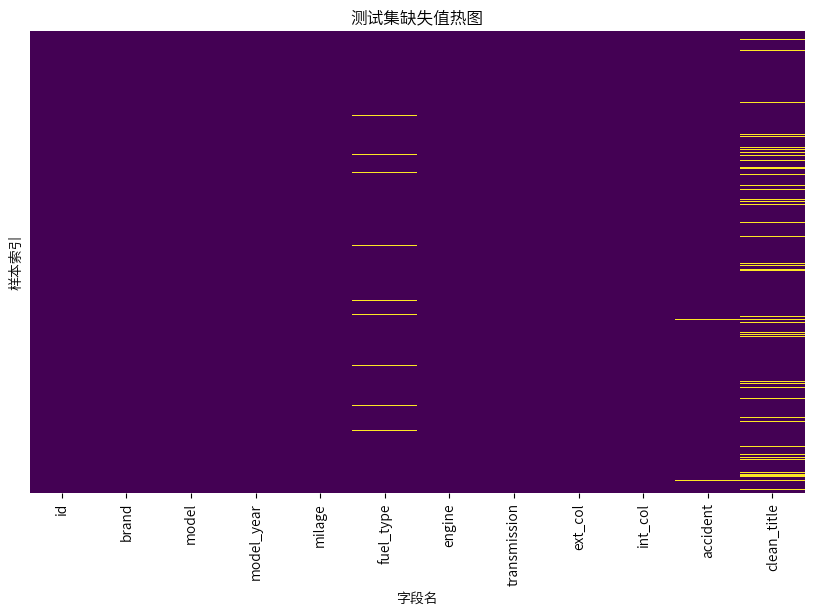
训练集和测试集均在燃料类型、事故历史、所有权证明存在缺失值,而所有权证明的缺失值占比较大,这里这样考虑:
-
针对燃料类型,首先按品牌和具体型号对应的情况来填充,假如这个型号均为缺失值,则使用该品牌众数来填充。
-
针对事故历史,由于缺失值占比较小,采用直接删除缺失值。
-
针对所有权证明,由于未缺失的部分全是Yes,这里也是填充为Yes,但是考虑到只有唯一一个值,没有分析的价值,还是直接删除比较好。
-
考虑部分特征中存在"--",这里也认为是缺失值,同样在后续的处理中,考虑这个情况。

现在开始处理唯一值特别多,以及部分未处理含"--"的特征列,通过之前的分析发现具体型号、发动机规格、变速器类型、 外观颜色、内外饰颜色的唯一值特别多,因为过多的独特值会对模型带来噪声,增加计算复杂度且影响模型的泛化能力,考虑如下处理方法:
-
针对具体型号,有条件的话,可以按车型划分为轿车、SUV等,这里由于没太多精力,暂不处理。
-
针对发动机规格,这里就初步用正则提取排量情况,然后根据排量划分大小,微型轿车的排量小于等于1.0L;普通级轿车的排量在1.0---1.6L范围内;中级轿车的排量在1.6---2.5L范围内;中高级轿车的排量在2.5---4.0L范围内;高级轿车的排量则大于4.0L(百度百科),因此,构建一个新的特征"排量",来划分Small、Medium、Large、Extra-large、Ultra-large,而且考虑有些纯电动汽车,增加一个Electric。
-
针对变速器类型,划分为自动挡、手动挡、其他三类。
-
针对外饰颜色,根据懂车帝上说的汽车上常用的颜色主要有以下几种:银灰色、白色、黑色、红色、蓝色、黄色、绿色,因此将这7种颜色保留,其他颜色作为其他,分成8类。
-
针对内饰颜色,根据知乎------车早茶的说法,常见的内饰颜色有:黑色、白色、棕色、红色、米黄色,同样的把其他颜色分为其他,共分成6类。
数据中已经不存在缺失值的情况了,但是考虑价格的分布特别广,这里使用对数变化来处理价格,减小大值和小值之间的差异。
4.2一致性检验


通过卡方检验,发现所有分类变量的p值均大于0.05,说明训练集和测试集在这些特征上的分布没有显著差异。

通过KS检验,所有数值变量的p值均大于0.05,说明训练集和测试集在这些特征上的分布没有显著差异。
综上所述,可以认为训练集和测试集在特征分布上是一致的,因此可以只对训练集进行进一步的分析和模型训练,将简化分析过程,并确保模型在测试集上的评估具有代表性。
5.二手车价格的影响因素分析
5.1可视化分析

红线显示了一个明显的上升趋势,表明随着制造年份越新,汽车的平均价格呈现稳定增长。
对于每个年份,价格都呈现出较大的垂直分布范围,表明同一年份的车型存在显著的价格差异,这种价格差异在2000年以后变得更加明显,分布范围更广。
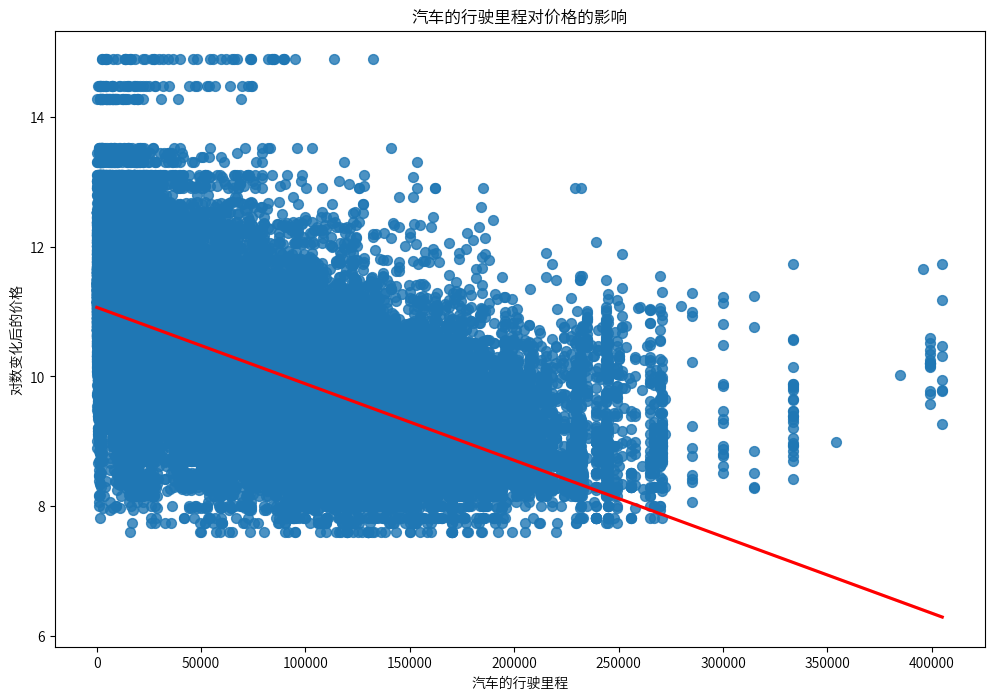
红线清晰地显示了一个下降趋势,表明随着行驶里程的增加,汽车价格整体呈下降趋势。
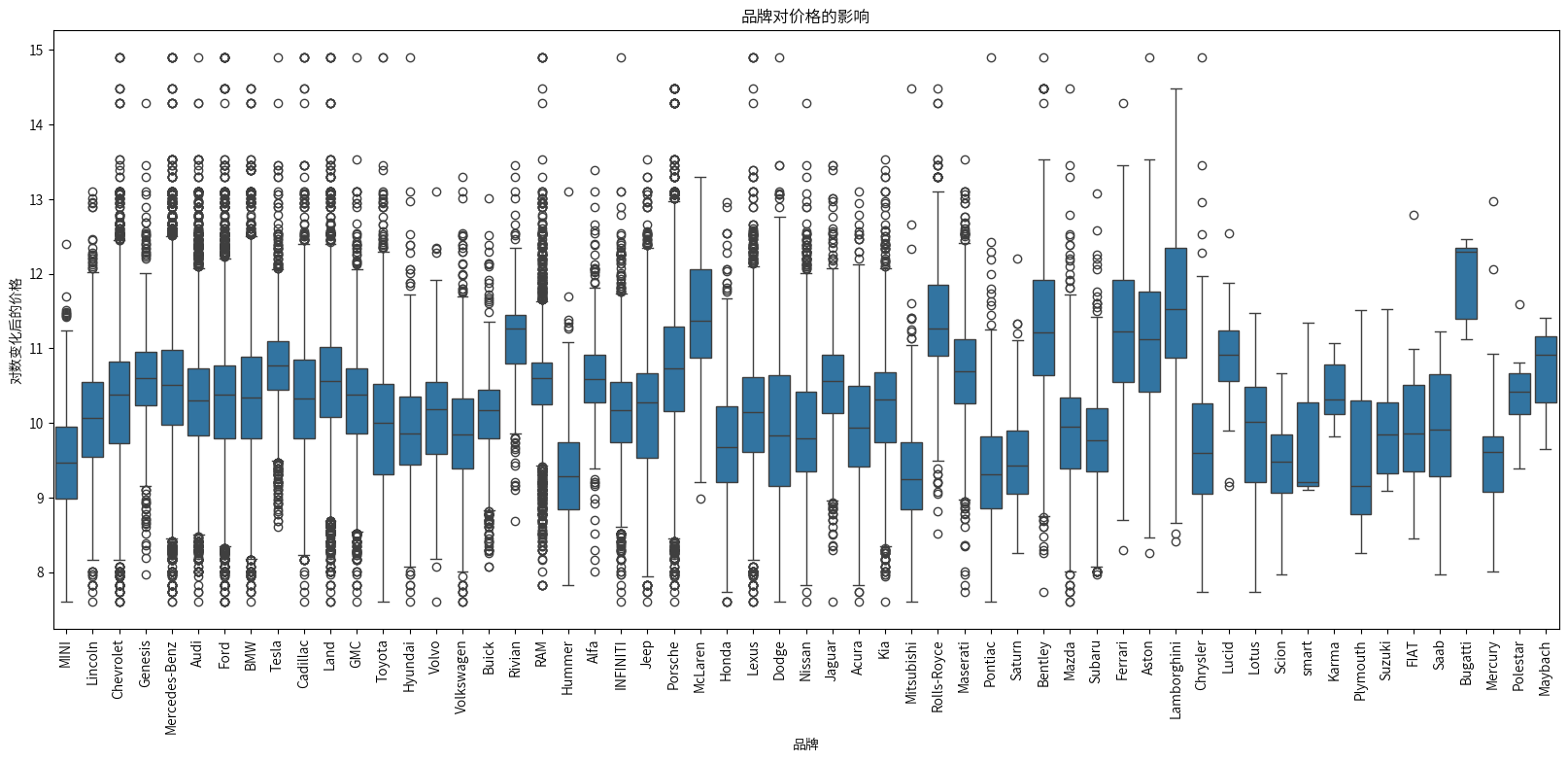
Bugatti(布加迪)的价格中位数最高,并且价格分布比较窄,总体价格较高。
Lamborghini(兰博基尼)的价格中位数第二高,价格分布比较广,也是豪华品牌代表。
Hummer(悍马)、Mitsubishi(三菱)、Pontiac(庞蒂亚克)、Plymouth(普利茅斯)的价格中位数相对较低。
可以看出,不同的品牌价格不同,因此品牌可能是影响汽车价格的因素之一。

Hybrid(混合动力)和Plug-In Hybrid(插电式混合动力)的二手车中位数价格高于其他类型。
not supported(不支持)类别价格分布最窄,中位数价格最低,可能代表一些特殊或老旧车型。
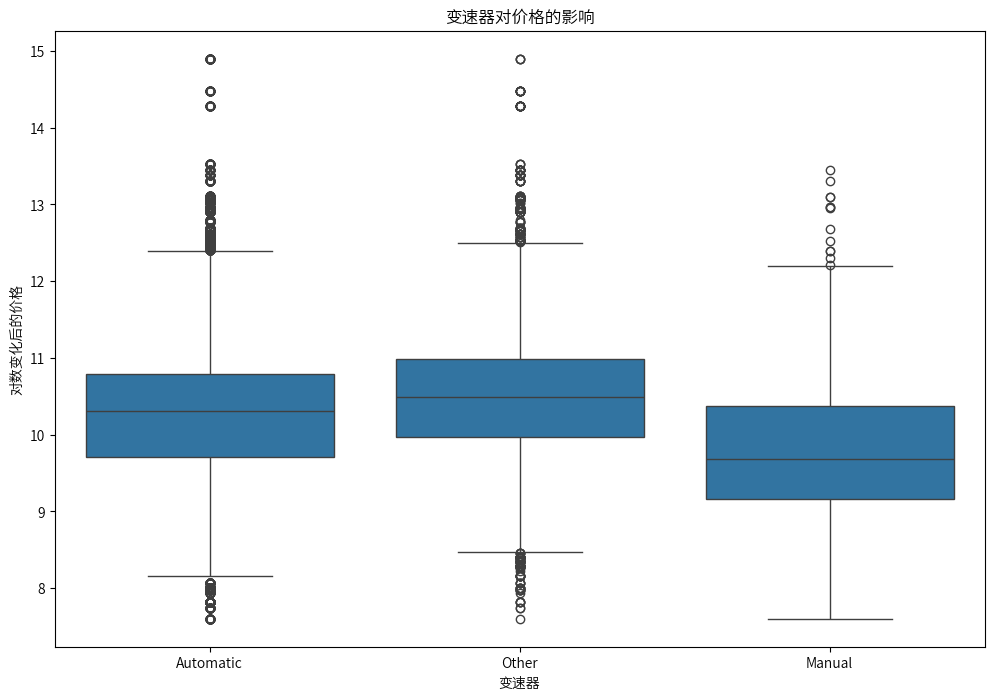
其他类型变速器的中位数价格最高,其次是自动档,手动档最低。
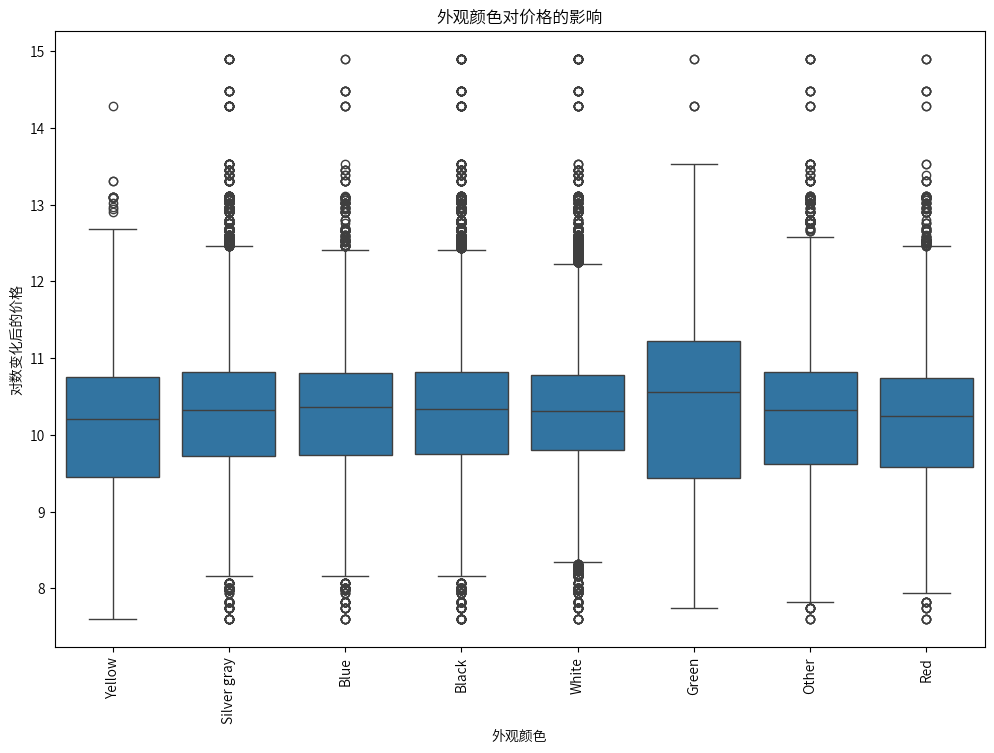
外观颜色整体差异不大,就绿色车辆的中位数价格相对高一些,而黄色车辆的中位数价格低一些。

白色内饰的车辆中位数价格最高,而米色(Beige)内饰的中位数价格最低。

没发生过事故的二手车价格更高,发生过事故或者损坏的二手车价格就比较低。
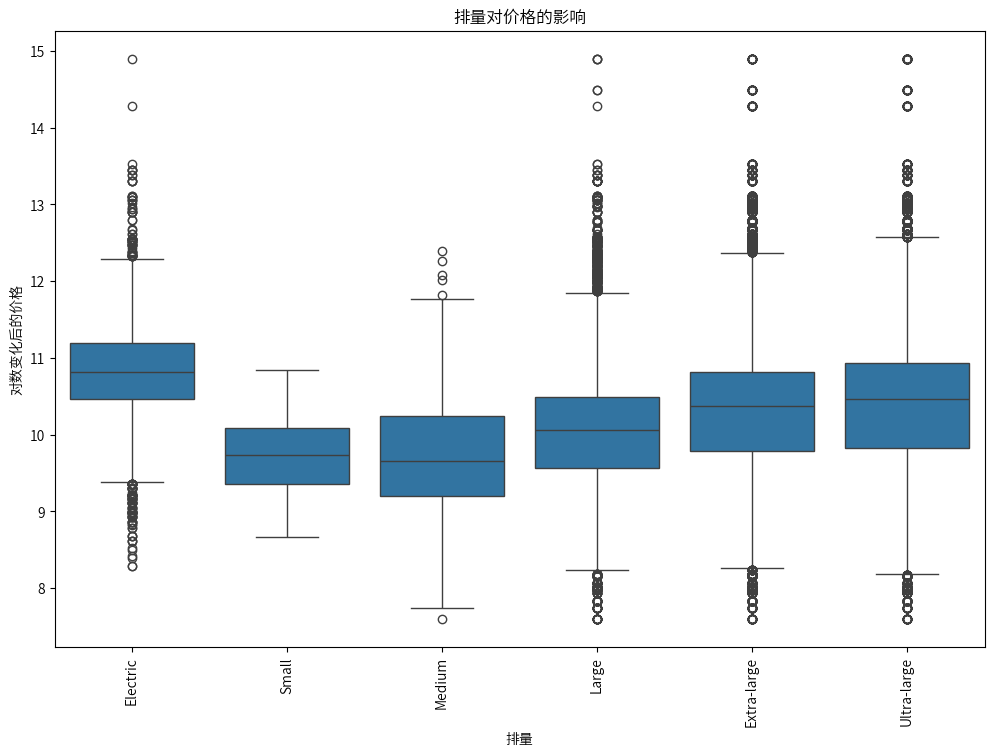
汽车排量大小与价格有着明显的正相关关系。一般来说,排量越大,价格越高。这可能是因为大排量车型通常与更高的性能、更豪华的配置相关联。
电动车作为一个特殊类别,其中位数价格最高,且价格分布最为广泛,反映了电动车市场的多样性和快速发展。
5.2相关性分析
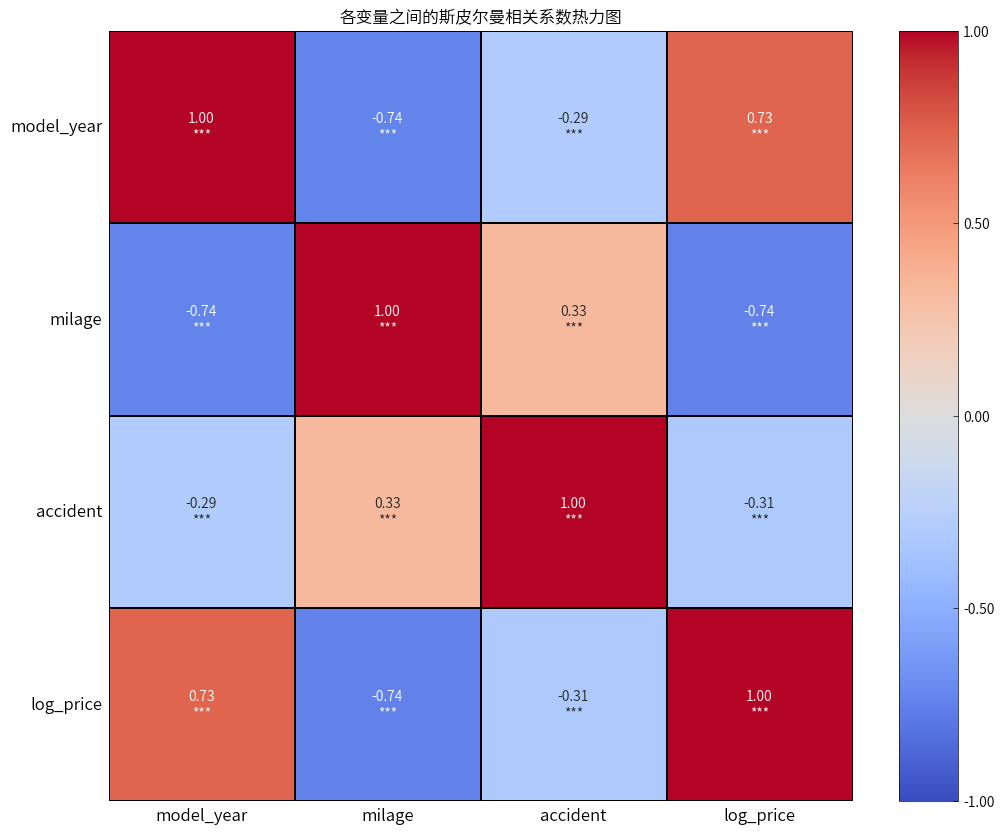
通过斯皮尔曼相关性分析,发现价格与车辆制造年份、车辆行驶里程、事故情况有显著的相关关系,并且与之前可视化分析观察到的结果一致。
5.3ANOVA
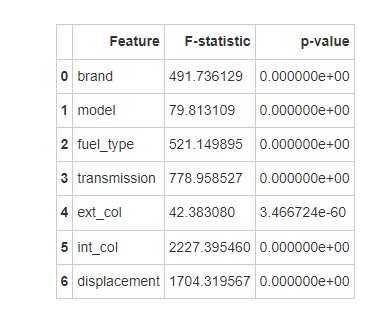
所有特征p值均小于0.05,可以认为这些都是显著影响二手车价格的特征。
6.随机森林模型
6.1数据预处理
-
把汽车的制造年份,转为车龄:当前年份-汽车的制造年份,这样可以使模型更直接地学习车辆新旧程度对价格的影响。
-
由于汽车的行驶里程的波动范围较大,且较高里程数对价格影响呈递减趋势,采取对数变换可以使其分布更均匀,减小极端值的影响。
-
针对分类特征,由于使用的是树模型,可以使用标签编码,如果使用独热编码的话,会导致纬度大幅度增加,增加计算负担。
6.2建立回归模型
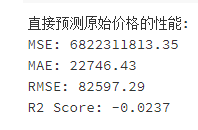
预测效果并不理想,甚至很差,现在考虑先预测对数价格,再还原对比一下看看,会不会好一些?
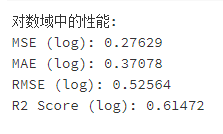

相比直接预测价格,有一定的提升,但是仍然不够理想。
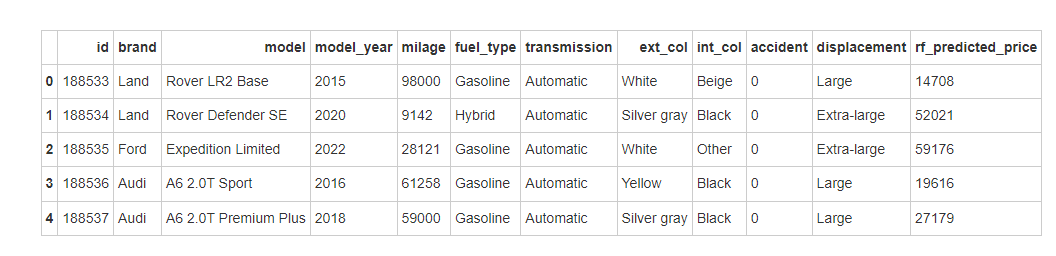
6.3预测测试集
7.岭回归
7.1数据预处理
由于树模型和岭回归的数据预处理不一样,这里重新处理数据,确保能够较好的适应岭回归模型,这里使用独热编码,但是考虑到model列有1800多条唯一值,使用独热编码的话,可能会导致维度爆炸,所以直接删除model列。
7.2建立回归模型

可以发现预测的效果比随机森林好的多,如果预测对数价格再转换会不会更好呢?
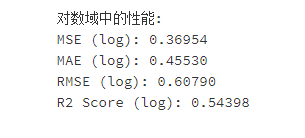

相比直接预测价格,反而下降了很多。
7.3预测测试集

8.总结
本项目通过系统的数据分析和建模过程,深入探讨了影响二手车价格的多方面因素,并尝试构建预测模型。主要结论如下:
-
通过可视化分析、斯皮尔曼相关性分析及方差分析,发现二手车价格受到多个维度因素的综合影响,这些因素包括:汽车品牌、具体型号、制造年份、行驶里程、燃料类型、变速器类型、外观及内饰颜色、事故历史记录以及发动机排量。这表明二手车定价是一个复杂的多变量决策过程。
-
尽管采用了随机森林和岭回归这两种常用的机器学习模型,但在预测二手车价格方面的表现均未达到理想效果,原因可能是:
-
二手车价格分布大,难以捕捉高价车和低价车。
-
不同车型、年份、配置的样本量可能不均衡,稀疏样本的极值可能会影响模型的稳定性。
-