
Harmonizing Visual Text Comprehension and Generation
论文:
https://arxiv.org/abs/2407.16364v1
前排提示,文末有大模型AGI-CSDN独家资料包哦!
TextHarmony 是由华东师范大学和字节跳动的研究人员共同开发的一款多模态生成模型,它在视觉文本理解与生成领域展现出卓越的能力。该模型通过创新的Slide-LoRA技术,有效解决了在单一模型中同时生成图像和文本时遇到的性能下降问题。Slide-LoRA通过动态聚合特定于模态和模态无关的低秩适应(LoRA)专家,实现了在保持参数增加极小化的同时,提高了模型对视觉和语言模态的生成一致性。
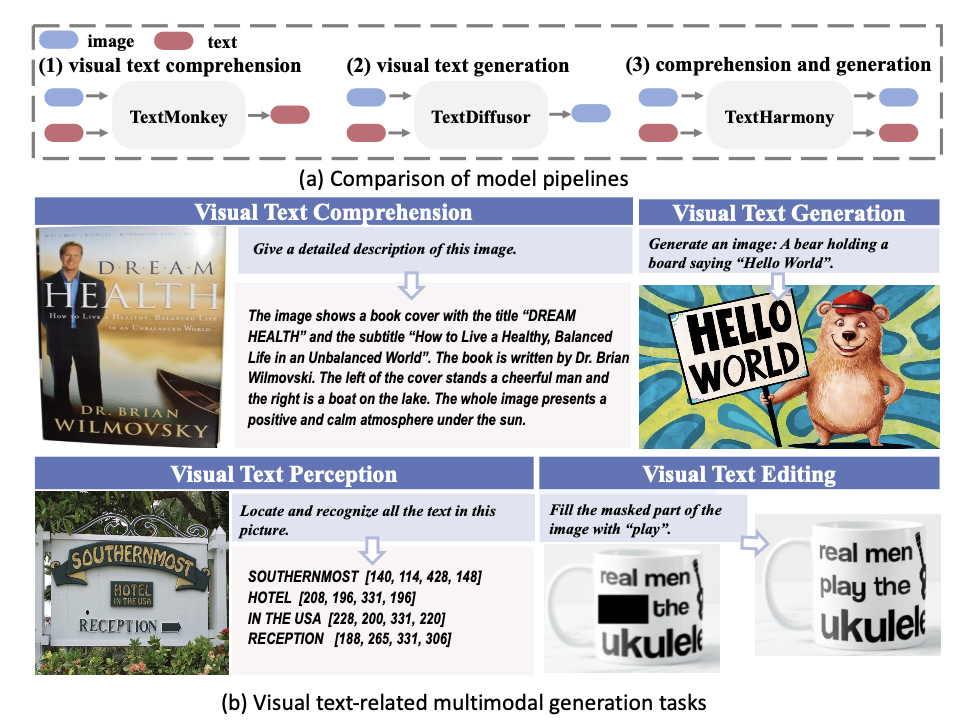
TextHarmony 能够处理多种以文本为中心的多模态任务,包括文本检测、识别、视觉问答(VQA)、关键信息提取(KIE)以及视觉文本的生成、编辑和擦除等。


它不仅在视觉文本感知任务中表现出与现有最先进方法相媲美的性能,在视觉文本理解任务中也展现出与专门模型相仿的效果。此外,TextHarmony 在图像生成任务中的表现也与专门的视觉文本生成模型相当,证明了其在多模态生成任务中的全面性和高效性。
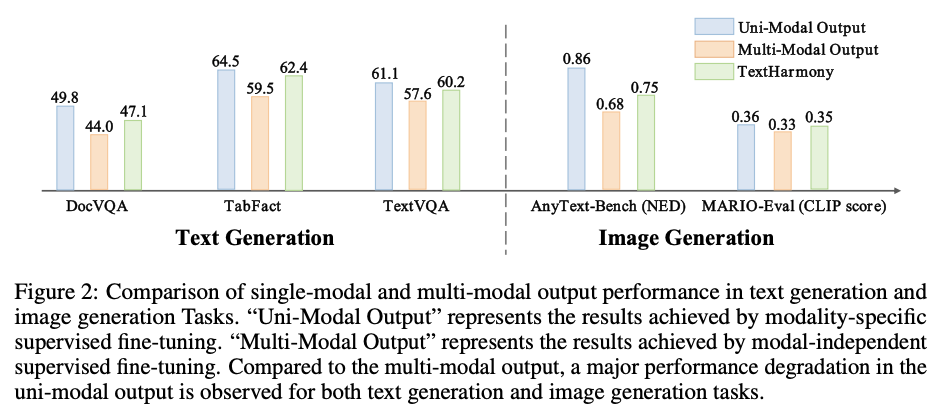
为了进一步提升视觉文本生成的质量,研究团队还开发了一个名为DetailedTextCaps-100K的高质量图像字幕数据集。该数据集利用先进的闭源MLLM通过提示工程技术合成,为TextHarmony提供了丰富的、详细的图像和文本对,从而显著提高了模型在图像生成方面的性能。TextHarmony的提出,不仅为视觉文本领域的研究提供了新的思路和工具,也为多模态人工智能的应用开辟了更广阔的前景。
技术解读
TextHarmony 的核心技术思路包括:
-
多模态生成模型:TextHarmony作为一个多模态生成模型,旨在同时理解和生成视觉文本。这要求模型不仅要处理图像数据,还要处理与之相关的文本信息。
-
Slide-LoRA技术:为了克服视觉和语言模态在生成过程中的不一致性问题,TextHarmony采用了Slide-LoRA技术。Slide-LoRA通过动态聚合特定于模态(如图像或文本)和模态无关的低秩适应(LoRA)专家,实现了在单一模型实例中对视觉和语言生成的有效协调。
-
模型架构:TextHarmony的模型架构包括视觉编码器、大型语言模型(LLM)、文本分词器、文本解分词器和基于扩散的图像解码器。这些组件共同工作,使模型能够生成交织的图像和文本标记序列。
-
多阶段训练:TextHarmony的训练分为两个阶段。首先是多模态预训练阶段,模型在包含丰富文本的图像-文本语料库上进行训练,学习生成多模态输出。其次是全面微调阶段,通过在多种文本中心任务上的训练,进一步提升模型在文本和图像生成方面的能力。
-
高质量数据集:为了提高图像生成的质量,研究者开发了DetailedTextCaps-100K数据集。该数据集通过高级闭源MLLM合成,提供了详细的图像字幕,有助于提升模型在视觉文本生成任务中的表现。
-
任务特定的处理:TextHarmony在处理不同类型的视觉文本任务时,采用特定的提示和数据格式化方法。例如,在视觉文本感知任务中,模型需要识别和提取图像中的文本;在视觉文本生成任务中,模型根据文本描述生成图像。
-
损失函数和优化:在训练过程中,TextHarmony使用特定的损失函数来优化文本生成和图像生成的目标。文本生成采用交叉熵损失函数,而图像生成则采用均方误差损失函数。模型通过自适应调整前向传播来解决训练目标的不一致性问题。
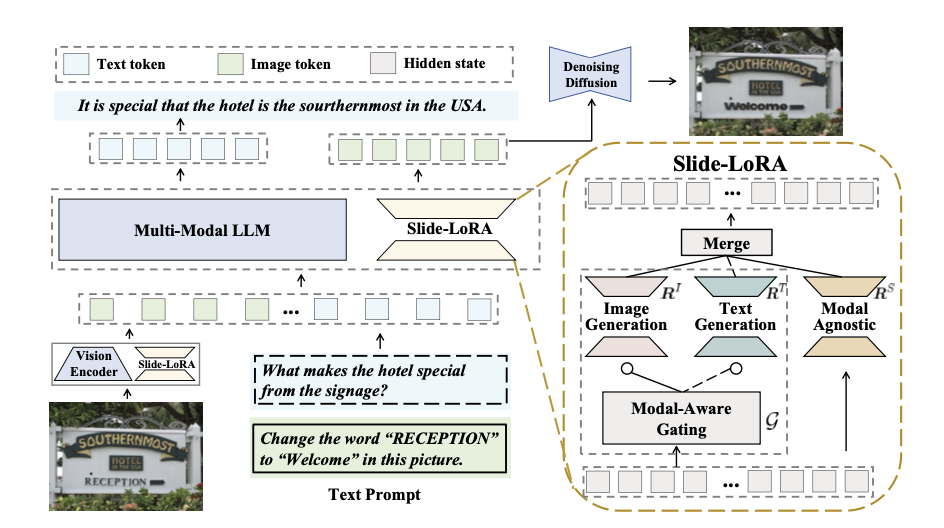
通过这些技术思路和处理步骤,TextHarmony能够有效地执行视觉文本理解与生成任务,同时保持生成过程的统一性和高效性。
论文解读
本文介绍了一个名为TextHarmony的多模态生成模型,它擅长理解并生成视觉文本。
主要内容概括如下:
-
引言:介绍了视觉文本理解与生成任务的重要性,如场景文本检测、文档理解、视觉问答等,并指出了现有多模态大型语言模型(MLLMs)和扩散模型在这些任务中的应用和进展。
-
TextHarmony模型介绍:提出了TextHarmony模型,这是一个统一且多功能的多模态生成模型,能够理解并生成视觉文本。通过Slide-LoRA技术,模型在单一实例中协调视觉和语言的生成,解决了不同模态间的不一致性问题。
-
Slide-LoRA技术:介绍了Slide-LoRA模块,它通过动态聚合特定于模态和模态无关的LoRA专家,部分解耦多模态生成空间,提高了图像和文本生成的一致性。
-
数据集构建:开发了DetailedTextCaps-100K数据集,这是一个高质量的图像字幕数据集,通过使用高级闭源MLLM合成,以增强视觉文本生成的性能。
-
方法论:详细描述了TextHarmony的模型架构,包括视觉编码器、LLM和图像解码器的集成,以及如何通过最大条件概率生成交织的标记序列。
-
预训练和微调:介绍了TextHarmony的两阶段训练过程,包括多模态预训练和全面微调,以及在不同阶段使用的数据集和训练策略。
-
实验:通过一系列实验验证了TextHarmony在多种视觉语言任务上的有效性,包括文档定向的视觉问答、表格视觉问答、场景文本中心的视觉问答和OCR任务等。
-
局限性:讨论了TextHarmony在视觉文本感知和理解任务中的一些局限性,以及在生成密集文本图像时的不足之处。
-
结论:总结了TextHarmony在统一视觉文本理解和生成任务中的成果,强调了其在多模态生成模型领域的潜力和应用前景。
