
咱们今天聊聊 DETR (DEtection TRansformer) ,这个技术是Facebook AI Research在2020年推出来的。DETR其实是一种深度学习模型,它用到了现在特别火的Transformers来实现目标检测。
目标检测,简单来说,就是让计算机能从图片或者视频里识别出不同的物体。
你可能知道,Transformers在处理自然语言处理(NLP)任务时表现得特别好,比如做机器翻译或者理解语言的模式。这是因为Transformers有一个很牛的特性,叫做自注意力机制,它能够识别出数据中哪些部分是特别重要的。
DETR就是利用了Transformers这个特性来做目标检测的。而且,DETR把目标检测的过程简化了,不像以前那样需要分好几个步骤来完成。这样一来,不仅操作起来更简单,效率也提高了。

本文会详细讲解DETR的工作原理、它的架构、优势和性能,还会聊聊怎么把它和向量数据库结合起来,用在比如图像检索系统和多模态搜索解决方案这样的高级应用上。
在深入讲DETR之前,我们先来聊聊目标检测是啥?目标检测就是用计算机视觉技术在图片或视频里找出并确定物体的位置。就像你有个朋友特别会找东西,你给他看张照片,他就能告诉你照片里都有啥,比如,"嘿,那里有一只狗,还有一棵树,那边有一个人!"。目标检测就是用计算机算法来做到这一点。
目标检测主要做两件事:
-
目标分类(Object Classification):就是确定图片里有哪些东西。
-
目标定位(Object Localization):就是确定这些东西在图片里的具体位置,通常是通过画个边界框来标出来。
目标检测能帮助我们在很多领域理解视觉信息,比如自动标记、汽车安全、零售、安全等等。
DETR这个模型就是用Transformers来预测图片里物体的边界框和类别标签。Transformers是一种由编码器-解码器架构组成的神经网络,有自注意力机制。这样DETR就能理解图片里物体之间的关系,做到更准确的检测。
传统的目标检测方法,比如YOLO(You Only Look Once)和R-CNN(Region Convolutional Neural Network),会先提出很多区域建议或者锚定框,然后用非极大值抑制(Non-Maximum Suppression,NMS)来筛选。这种方法比较复杂,训练起来效率也不高。
但是DETR把目标检测看作是一个直接的集合预测问题。它的目标是把图片里所有的物体看作一个集合,一次性预测出它们的边界框和类别。这种方法提高了检测的准确性,特别是在很多物体靠得很近的时候。
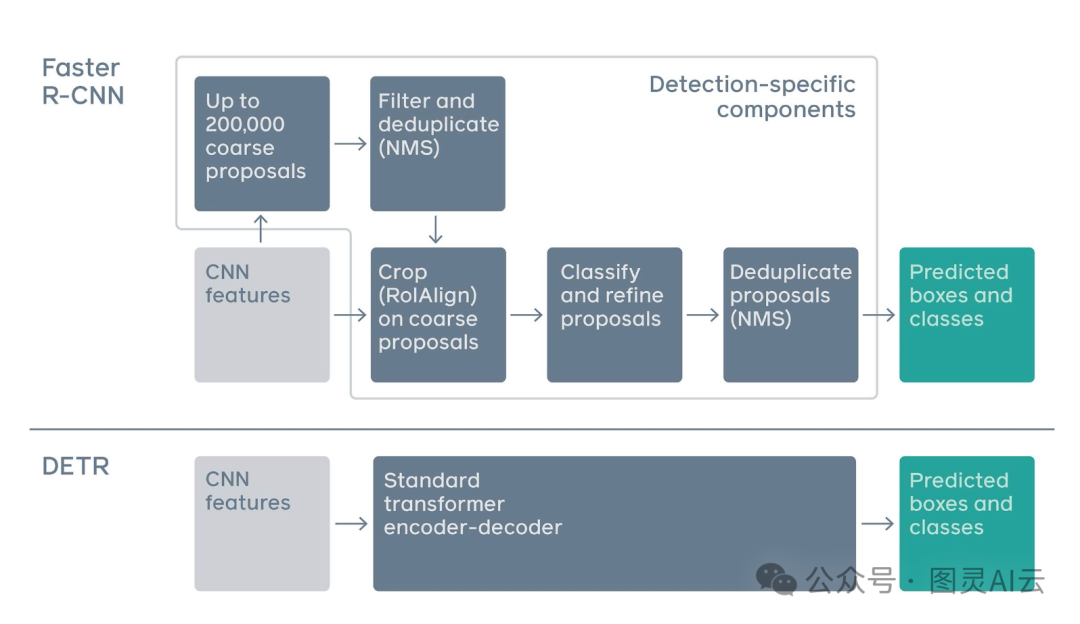
Faster R-CNN(区域卷积神经网络)和DETR之间的流程差异
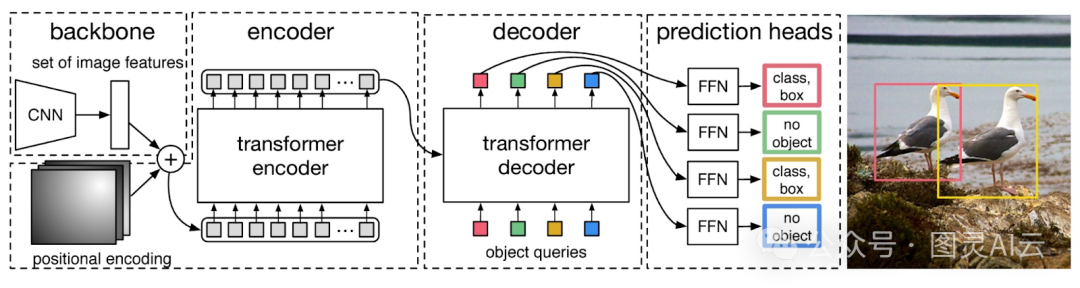
DETR的架构主要由几个部分组成:卷积神经网络(CNN)作为骨干网络,变换器(Transformer)的编码器和解码器,以及预测头。下面这张图展示了DETR的架构:
-
CNN骨干(CNN Backbone):图像先通过CNN骨干网络,得到图像的高级特征表示。像视觉几何组(VGG)和ResNet这样的网络经常被用作CNN骨干。这些特征包含了图像中物体的空间信息,然后这些信息会传递给变换器编码器。
-
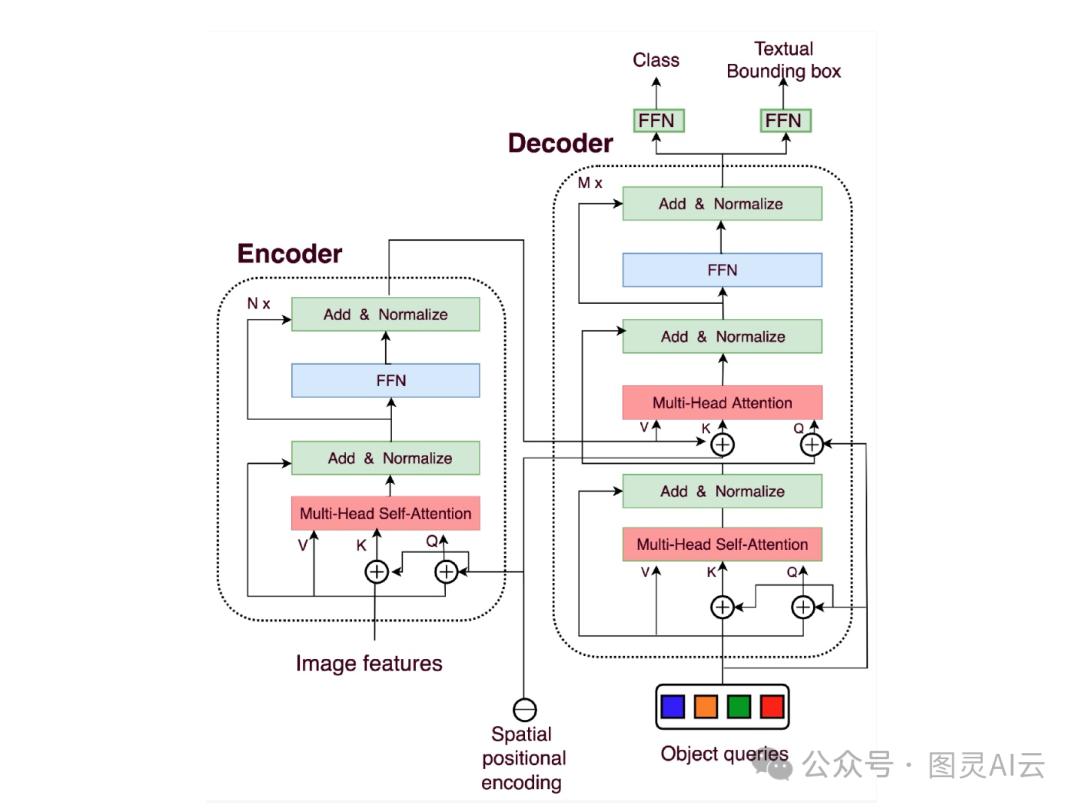
变换器编码器(Transformer Encoder):变换器编码器将这些特征转换成一系列特征向量。编码器里有多头自注意力机制,这让它能够捕捉图像不同部分之间的上下文信息。在这个过程中,还会给CNN的输出加上位置编码,因为变换器本身不具备空间理解能力,位置编码告诉变换器图像中物体的相对位置。
-
变换器解码器(Transformer Decoder):变换器解码器学习CNN编码的特征和可学习的对象查询之间的关系。在自然语言处理中,我们用查询、键和值来计算自注意力。在DETR中,引入了对象查询的概念,这是模型需要预测的物体的可学习表示。对象查询的数量是预先设定好的。键代表图像中的空间位置,值则包含了特征信息。
-
预测头(Prediction Heads):预测头负责输出检测到的物体的边界框和类别。它由前馈网络组成,可以预测物体的边界框和类别,或者在没有检测到物体时预测"无物体"类别。此外,DETR还使用了二分图匹配技术,确保预测的边界框与真实物体相对应,这有助于优化模型的训练。
训练过程中,损失函数是关键组成部分,它结合了分类损失和回归损失,因为模型需要预测边界框和类别。
-
集合预测损失(Set Prediction Loss:):DETR用集合预测损失来衡量预测的物体类别的准确性。通过计算预测和真实物体类别之间的差异,我们可以了解缺失的物体类别。
-
边界框损失(Bounding Box Loss:):DETR还用边界框损失来衡量预测和真实边界框坐标之间的差异。这种损失函数有助于在图像中精确地定位物体。
DETR的优点和缺点
先谈谈其优点:
-
简化的架构:DETR把边界框和类别预测一次性搞定,省去了多阶段流水线的麻烦。它的端到端方法让目标检测的过程变得更简洁。
-
全局上下文意识:因为用了自注意力机制,DETR能考虑到图像里其他物体的位置和关系,从而捕捉到全局上下文。这和以前的目标检测方法不一样,那些方法往往是孤立地预测每个物体。
-
高效的训练:以前的架构,比如递归神经网络,是按顺序一个接一个做预测,速度慢,效率也不高。但是DETR用基于集合的方法,可以并行处理最终的预测集,这让训练过程变得更简单、更高效。
也有一些缺点,如下:
-
计算资源:DETR是个基于变换器的模型,所以训练起来需要很多计算资源,尤其是数据量大、图像分辨率高或者骨干模型复杂的时候。
-
固定的对象查询数量:DETR需要提前设定好一个固定的对象查询数量,这可能会限制在需要预测不同数量物体的场景下的应用。要让模型能够动态处理不同数量的物体,这是一个挑战。
-
推理速度:虽然DETR简化了训练过程,但是因为变换器架构比较复杂,所以推理速度可能会比传统方法慢,这让它不太适合需要实时处理的场合。
DETR的实验和结果
DETR是一个有监督的深度学习模型,它用一些大型数据集来训练,比如COCO目标检测数据集和Pascal VOC。为了帮助模型更好地泛化,还用到了数据增强技术,比如翻转、裁剪、缩放和随机抖动。在实验中,研究者们考虑了四种不同的DETR模型:
-
用ResNet-50作为骨干网络的基本DETR;
-
用ResNet-101作为骨干网络的DETR;
-
还有两个叫做DC5的模型,它们在CNN的最后阶段增加了膨胀C5,这样可以提高特征图的分辨率,对小目标的预测效果更好。
DETR论文的主要目标是在COCO 2017目标检测数据集上,和Faster R-CNN这个竞争对手比较一下。DETR刚发布的时候,它的表现超过了Faster R-CNN的基线。但现在,Faster R-CNN ResNet50 FPN V2的性能又超过了DETR模型。
下面这张图比较了DETR的不同变体和Faster R-CNN的不同版本之间的结果:
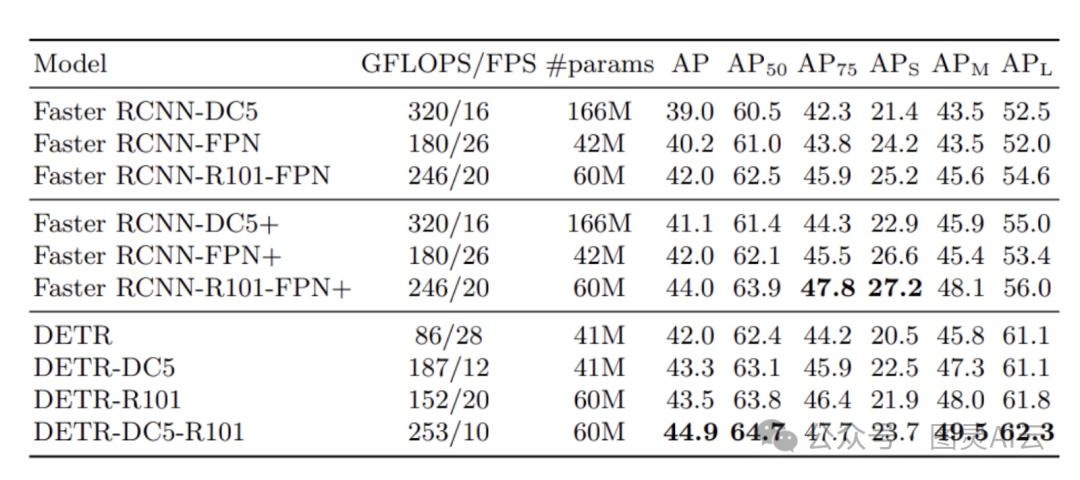
从结果来看,DETR模型和Faster R-CNN模型的表现差不多。其中表现最好的是DETR-DC5-R101,它的mAP得分是44.9。还有一个有趣的发现是,DETR在检测大物体的时候表现得比小物体好很多。
总结
DETR给我们带来了一种全新的方法来用变换器做目标检测。这个端到端的模型能够一次性完成目标检测和分类,这和以前的多阶段模型,比如RCNN和Faster R-CNN,是不一样的。DETR的直接集合预测方法允许并行处理,这样也简化了整个架构。虽然DETR有不少优点,但它在计算资源消耗和推理速度上还是面临一些挑战。目前,研究人员正在努力解决这些问题,希望能进一步提升DETR的性能。另外,变换器的使用为涉及自然语言处理(NLP)和计算机视觉的双模态任务提供了一个统一的解决方案。所以,DETR是一个很有前景的方法,它可能会彻底改变我们处理目标检测和双模态任务的方式。
参考资料:
- End-to-End Object Detection with Transformers(https://arxiv.org/abs/2005.12872)