1、什么是依赖关系?

2、什么是宽窄依赖?
窄依赖:Narrow Dependencies
定义:父RDD的一个分区的数据只给了子RDD的一个分区 【 不用经过Shuffle 】
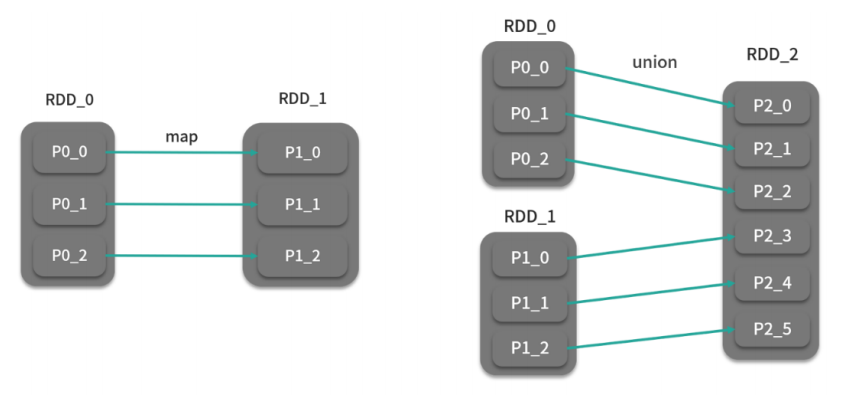
特点:一对一或者多对一 ,不经过Shuffle,性能相对较快, 但无法实现全局分区、排序、分组等
一个Stage内部的计算都是窄依赖的过程,全部在内存中 完成。
宽依赖:Wide/Shuffle Dependencies
定义:父RDD的一个分区的数据给了子RDD的多个分区【需要调用Shuffle的分区器来实现】

特点:一对多,必须经过Shuffle,性能相对较慢,可以实现全 局分区、排序、分组等
Spark的job中按照宽依赖来划分 Stage
本质:只是一种标记,标记两个RDD之间的依赖关系
3、为什么要标记宽窄关系?
宽窄依赖是在说哪个算子是宽哪个算子是窄吗?不是,说的是两个算子之间的关系。
1)提高数据容错的性能,避免分区数据丢失时,需要重新构建整个RDD
场景:如果子RDD的某个分区的数据丢失
不标记:不清楚父RDD与子RDD数据之间的关系,必须重新构建整个父RDD所有数据
标记了:父RDD一个分区只对应子RDD的一个分区,按照对应关系恢复父RDD的对应分区即可
2)提高数据转换的性能,将连续窄依赖操作使用同一个Task都放在内存中直接转换
算子之间,能在内存中转换的就在内存中转换,效率高,碰到需要shuffler的算子,就只能把数据放在磁盘,让shuffer算子,去拉取数据,效率低,如果不标记,怎么知道哪些算子需要shuffer呢?
场景:如果RDD需要多个map、flatMap、filter、 reduceByKey、sortByKey等算子的转换操作
不标记:每个转换不知道会不会经过Shuffle,都使用不同的 Task来完成,每个Task的结果要保存到磁盘
标记了:多个连续窄依赖算子放在一个Stage中,共用一套 Task在内存中完成所有转换,性能更快。
