一、问题来源
在日常的业务系统中,操作日志 是不可或缺的一部分。它能帮助我们追踪用户的操作行为,记录关键数据的变更,甚至在必要时支持操作回滚。最近,我们接到客户的需求,希望在系统中实现一个业务操作日志管理的功能,具体包括:
-
记录用户的业务操作行为:包括操作人、操作时间、操作功能、日志类型、操作内容描述、操作前后的数据报文等。
-
提供可视化的查询页面:方便查询用户的操作记录,对重要操作进行回溯。
-
支持误操作回滚:在必要时,对用户的误操作进行回滚处理。
这个需求看似简单,但要在不影响现有业务逻辑的情况下,实现高效、通用的操作日志记录,确实需要好好思考一番。
二、问题描述
2.1 日志的类型
在业务系统中,常见的日志类型主要有两种:
-
系统日志:
-
记录程序执行过程中的关键步骤,用于输出
debug、info、warn、error等不同级别的信息。 -
这类日志主要供程序员和运维人员查看,帮助快速排查故障。
-
-
操作日志:
-
记录用户的实际业务操作行为,如哪个用户在什么时间点击了某个菜单,修改了哪个配置等。
-
这类日志一般存储在数据库中,供普通用户或系统管理员查看。
-
2.2 传统实现方式的局限
2.2.1 业务代码嵌套日志
最直接的方法是在业务代码中手动添加日志记录。
例如,在每个数据库操作的前后,记录操作名称、时间、影响的数据等信息。然而,这种方式需要修改大量的业务代码,增加了编码的复杂度,而且不够通用。
2.2.2 AOP(面向切面编程)
AOP 是一种编程范式,能够将日志记录等通用功能与业务逻辑分离。
在 Spring 框架中,常用 AOP 来实现操作日志的记录。然而,AOP 在处理数据变更前后的值、批量操作、多表关联等复杂场景时,显得力不从心。
举个例子,我之前尝试过一种方案,通过在数据对象中设置 newData 和 oldData 两个属性来记录数据的前后变化:
go
@Valid
@NotNull(message = "新值不能为空")
@UpdateNewDataOperationLog
private T newData;
@Valid
@NotNull(message = "旧值不能为空")
@UpdateOldDataOperationLog
private T oldData;这种方式存在以下问题:
-
旧值的获取问题 :如果不再次查询数据库,就需要前端将旧值封装到
oldData对象中,但这可能导致数据不一致。 -
无法处理批量数据 :对于
List类型的数据,处理起来相当麻烦。 -
不支持多表操作:当一个业务操作涉及多个表时,很难完整地记录操作日志。
三、方案探讨
面对上述问题,我们需要一种更高效、更通用的解决方案。经过调研,我们发现了 Canal 这款神器(咱们之前文章也提及和验证过这个方案)。
3.1 Canal 的技术原理
Canal 是阿里巴巴开源的一款基于 MySQL 二进制日志(Binlog)的增量数据订阅和消费组件。它的主要功能是实时监听 MySQL 数据库的变更,包括表结构和数据的变化。
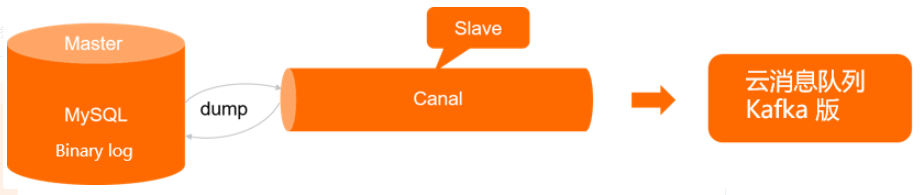
通过捕获 Binlog,Canal 能够获取数据库层面的原始变更事件(如 INSERT、UPDATE、DELETE),并将其解析为可消费的数据。
3.2 为什么选择 Canal?
-
解耦业务代码:
- 不需要修改现有的业务代码,降低了系统的耦合度。
-
支持批量操作和多表关联:
- 由于直接从数据库层面获取变更数据,能够方便地处理复杂的业务场景。
-
不依赖开发语言:
- Canal 与具体的编程语言无关,适用于各种技术栈的项目。
3.3 Canal 的优缺点
-
优点
-
解除了数据新旧变化的耦合。
-
支持批量操作和多表关联拓展。
-
不依赖于特定的开发语言。
-
-
缺点
-
数据库表设计需要统一的约定。
-
对于多表级联保存和更新的数据,可能存在兼容性问题。
-
需要处理非业务层面的数据变更(如手动修改数据库)。
-
四、方案实施
4.1 数据解析与转换
首先,Canal 采集并解析业务库的 Binlog 日志,将其投递到 Kafka 中。解析后的数据包括操作类型(如删除、修改、新增)以及新旧值,格式大致如下:
go
{
"data": [
{
"id": "122158992930664499",
"goodsName": "新商品名称",
"update_time": "2020-08-26 13:45:46"
}
],
"old": [
{
"goodsName": "旧商品名称",
"update_time": "2020-08-26 09:15:13"
}
],
"database": "db_business",
"table": "goods",
"type": "UPDATE",
"ts": 1587879945698
}4.2 定义通用接口规则
为了兼容不同业务的字段定义,我们设计了一个通用的接口规范,返回变更前后的数据和字段描述。

以商品修改为例,接口如下:
go
{
"id": "10001",
"groupID": 1700,
"system": "01",
"newObject": {
"goodsName": "商品名称001",
"goodsCode": "商品编码001"
},
"oldObject": {
"goodsName": "商品名称",
"goodsCode": "商品编码"
},
"fieldsDescription": {
"goodsID": "商品ID",
"goodsName": "商品名称",
"goodsCode": "商品编码"
},
"action": 2,
"description": "修改商品信息",
"operator": "user001",
"databaseName": "db_business",
"tableName": "goods",
"module": "商品管理",
"txID": "36aef98585db4e7a98f9694c8ef28b8c",
"timestamp": 1587879945698
}字段解释:
-
groupID:集团 ID -
databaseName:数据库名称 -
tableName:表名称 -
oldObject:变更前的数据 -
newObject:变更后的数据 -
fieldsDescription:字段描述,方便前端展示 -
operator:操作人 -
module:业务模块 -
action:操作类型(0:新增,1:删除,2:修改) -
description:操作描述 -
txID:事务 ID
通过这个接口,我们可以将变更的数据直观地展示出来,也可以使用 JSONDiff 等工具高亮显示差异。
小提示 :如果同一个事务操作了多个表,为了完整地串联相关表的变更并支持回滚,可以使用 txID 将 Binlog 进行聚合处理。
4.3 数据存储
由于业务字段的变更不确定,我们选择使用 NoSQL 数据库来存储这些操作日志。
这里,我们采用了 Elasticsearch,并按照月份对各个业务线的索引进行切割。
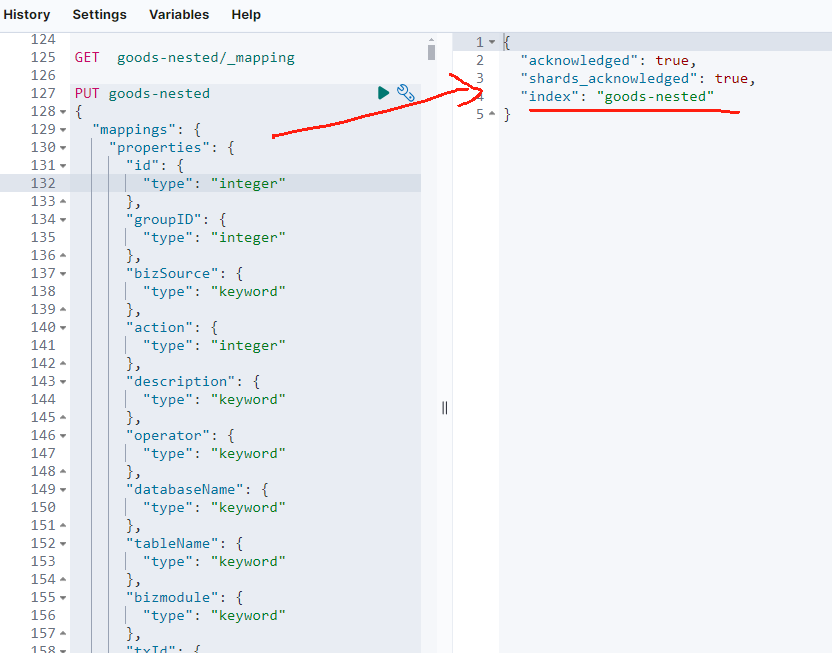
4.3.1 Elasticsearch 索引与映射
首先,定义索引和映射:
javascript
PUT goods-nested
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"groupID": {
"type": "integer"
},
"bizSource": {
"type": "keyword"
},
"action": {
"type": "integer"
},
"description": {
"type": "keyword"
},
"operator": {
"type": "keyword"
},
"databaseName": {
"type": "keyword"
},
"tableName": {
"type": "keyword"
},
"bizmodule": {
"type": "keyword"
},
"txId": {
"type": "keyword"
},
"newObject": {
"type": "nested",
"properties": {
"goodsID": {
"type": "integer"
},
"goodsName": {
"type": "keyword"
},
"goodsCode": {
"type": "keyword"
}
}
},
"oldObject": {
"type": "nested",
"properties": {
"goodsID": {
"type": "integer"
},
"goodsName": {
"type": "keyword"
},
"goodsCode": {
"type": "keyword"
}
}
},
"fieldsDescription": {
"type": "nested",
"properties": {
"goodsID": {
"type": "integer"
},
"goodsName": {
"type": "keyword"
},
"goodsCode": {
"type": "keyword"
}
}
}
}
}
}
4.3.2 数据插入示例
插入操作日志数据:
javascript
POST goods-nested/_bulk
{"index":{"_index":"goods-nested","_id":"10001"}}
{"id":"10001","groupID":1700,"bizSource":"Scm","newObject":{"goodsID":1001,"goodsName":"商品名称001","goodsCode":"商品编码001"},"oldObject":{"goodsID":1001,"goodsName":"商品名称","goodsCode":"商品编码"},"fieldsDescription":{"goodsName":"商品名称","goodsCode":"商品编码"},"action":2,"description":"修改集团品相","operator":"001","databaseName":"db_supply_chain_basic","tableName":"tbl_chain_distribution","bizmodule":"集团品相","txId":"36aef98585db4e7a98f9694c8ef28b8c"}
{"index":{"_index":"goods-nested","_id":"10002"}}
{"id":"10002","groupID":1700,"bizSource":"Scm","newObject":{"goodsID":1002,"goodsName":"商品名称002","goodsCode":"商品编码002"},"oldObject":{"goodsID":1002,"goodsName":"商品名称","goodsCode":"商品编码"},"fieldsDescription":{"goodsName":"商品名称","goodsCode":"商品编码"},"action":2,"description":"修改集团品相","operator":"001","databaseName":"db_supply_chain_basic","tableName":"tbl_chain_distribution","bizmodule":"集团品相","txId":"36aef98585db4e7a98f9694c8ef28b8c"}
{"index":{"_index":"goods-nested","_id":"10003"}}
{"id":"10003","groupID":1700,"bizSource":"Scm","newObject":{"goodsID":1003,"goodsName":"商品名称003","goodsCode":"商品编码003"},"oldObject":{"goodsID":1003,"goodsName":"商品名称","goodsCode":"商品编码"},"fieldsDescription":{"goodsName":"商品名称","goodsCode":"商品编码"},"action":2,"description":"修改集团品相","operator":"001","databaseName":"db_supply_chain_basic","tableName":"tbl_chain_distribution","bizmodule":"集团品相","txId":"36aef98585db4e7a98f9694c8ef28b8c"}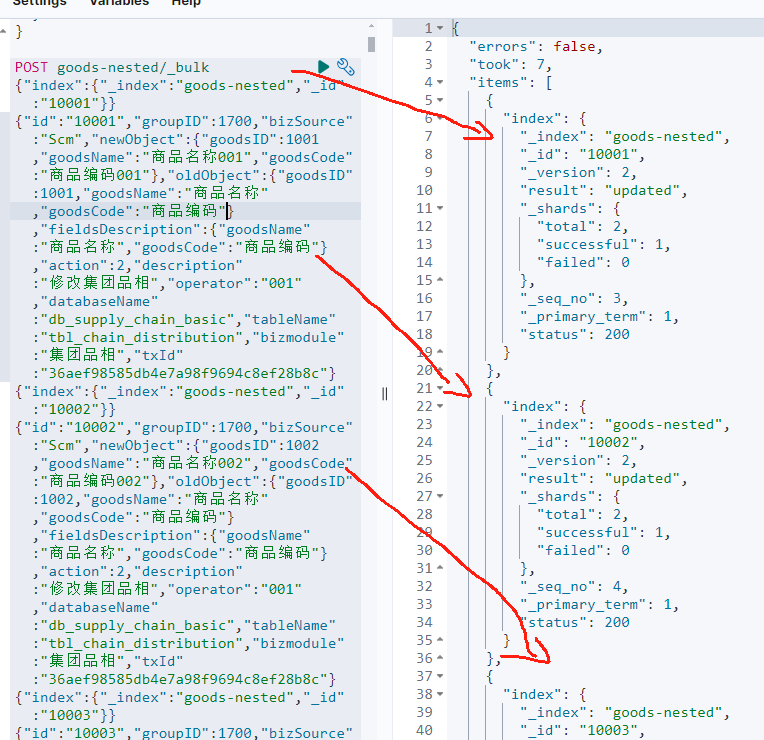
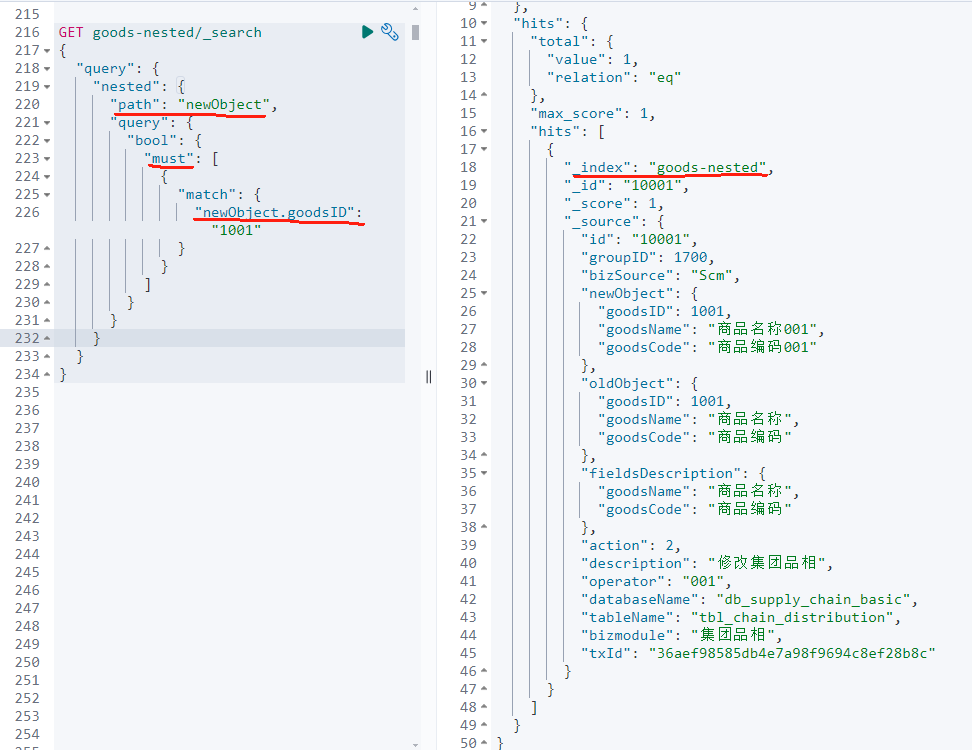
4.3.3 数据查询示例
根据商品 ID 查询操作日志:
javascript
GET goods-nested/_search
{
"query": {
"nested": {
"path": "newObject",
"query": {
"bool": {
"must": [
{
"match": {
"newObject.goodsID": "1001"
}
}
]
}
}
}
}
}
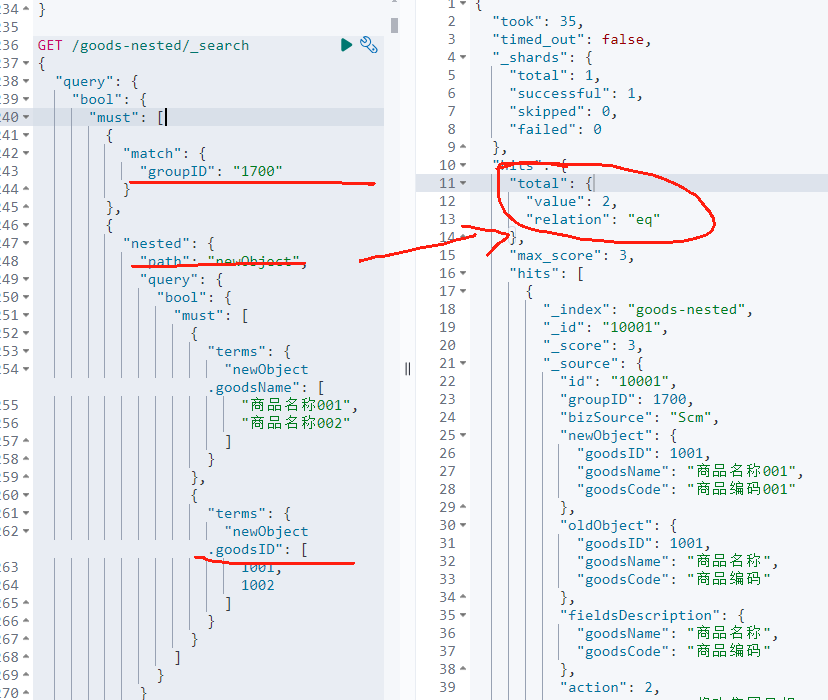
如下查询是在索引 goods-nested 中查找满足以下条件的文档:groupID 等于 "1700",并且其嵌套字段 newObject 中的 goodsName 是 "商品名称001" 或 "商品名称002",同时 goodsID 是 1001 或 1002:
javascript
GET /goods-nested/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"groupID": "1700"
}
},
{
"nested": {
"path": "newObject",
"query": {
"bool": {
"must": [
{
"terms": {
"newObject.goodsName": [
"商品名称001",
"商品名称002"
]
}
},
{
"terms": {
"newObject.goodsID": [
1001,
1002
]
}
}
]
}
}
}
}
]
}
}
}
五、多表关联问题处理
在实际业务中,一个操作可能涉及多个表的级联保存和更新。
然而,Binlog 的数据是无序的,如果上游数据的操作不在同一个事务中,处理起来会有一定困难。
解决方案:
-
使用事务 ID(txID):通过事务 ID,将同一事务内的操作聚合在一起,便于追踪和回滚。
-
统一更新操作人:确保系统在进行数据更新时,正确记录操作人信息,方便后续的日志分析。
六、过滤非业务层面的数据变更
需要注意的是,Binlog 中包含的不仅仅是业务系统的操作,还可能包括数据库工单、跑批等产生的数据变更。
为了避免干扰,需要对 Binlog 进行过滤,只保留业务层面的操作日志。
七、小结
通过以上的方案设计和实践,我们成功地实现了对业务操作日志的高效、通用记录。使用 Canal 捕获数据库层面的数据变更,再结合 Elasticsearch 进行存储和查询,不仅解耦了业务逻辑,还满足了客户的需求。
当然,这个方案并非完美,仍存在一些挑战:
-
多表关联的处理:需要更复杂的逻辑来聚合和关联数据变更。
-
操作人的准确性:需要业务系统配合,确保每次数据变更都能正确记录操作人。
但在系统架构设计中,没有完美的方案。我们需要在实用性和完美性之间找到平衡,适应业务的需求,不断优化和迭代。
最后,技术的发展是一个不断演进的过程。我们需要拥抱变化,灵活运用各种工具和方法,为业务提供最合适的解决方案。
作者:海鸥
14 年开发经验,现任某互联网 SaaS 公司TL+架构师,目前专注于 ERP 供应链 、新零售业务 、企业架构、中台架构、领域驱动设计、技术领导力等领域。死磕 Elasticsearch 知识星球常驻技术专家。
对于高并发、高可用、高性能、大数据处理有过丰富项目实战经验,乐于技术沟通分享。

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn------ElasticStack进阶助手

抢先一步学习进阶干货!