《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- [为什么Meta Sapiens脱颖而出?](#为什么Meta Sapiens脱颖而出?)
- [Meta Sapiens的三大支柱](#Meta Sapiens的三大支柱)
- 架构解析
- [1. 2D姿态估计-了解人体运动](#1. 2D姿态估计-了解人体运动)
- 2.身体部位分割-了解人体骨骼
- 3.深度估计
- 4.表面法线估计
- [Meta Sapiens的局限](#Meta Sapiens的局限)
- 结论
引言

Meta一直是开发图像和视频模型的领导者,现在他们增加了一些新的东西:Meta Sapiens。就像"Homo sapiens"(人类)一样,这个模型完全是关于人类的。它旨在执行与人类相关的任务,例如理解身体姿势,识别身体部位,预测深度,甚至确定皮肤纹理等表面细节。
为什么Meta Sapiens脱颖而出?
在2023-2024年,许多计算机视觉模型都专注于创建逼真的人类图像。虽然存在许多用于姿势估计和分割等任务的模型,但Meta的Sapiens模型是专门为人类相关任务设计的。
这个博客介绍了Meta是如何创建这个统一模型的,它的优点和缺点,以及它与其他模型的比较。
Meta Sapiens的三大支柱
Meta声称,与人类相关的任务模型应该满足这三个关键品质:
- **泛化:**这意味着模型在许多不同的情况下都能很好地工作。例如,它可以处理不同的照明条件,摄像机角度,甚至各种类型的服装。
- **广泛的适用性:**模型可以做不止一件事。它可以估计姿势,识别身体部位,甚至预测物体离相机有多远,所有这些都不需要大的改变。
- **高保真度:**它可以创建高质量,详细的结果。例如,如果任务是生成一个人的3D模型,结果将看起来非常逼真,具有清晰的细节,如面部特征和身体形状。
架构解析
Meta Sapiens使用一些强大的技术来完成这些任务。让我们简单地看一下其中的几个:
MAE(Masked Autoencoder):可以把这看作是一种通过使用分解块来有效学习的方法。模型会查看缺少某些部分的图像(就像缺少部分的拼图),并尝试填充空白。这使得模型更好地理解图像,并节省训练时间。例如,如果模型在图像中看到一个人的手臂的一部分缺失,它可以通过理解图像的其余部分来猜测手臂应该是什么样子。
**使用关键点和分割:**该模型识别人体上的308个点,包括手、脚、脸和躯干。它还知道大约28个不同的身体部位,从头发到嘴唇到四肢,使其非常详细。为了训练模型,Meta使用了真实的人体扫描和合成数据,这有助于它非常详细地了解人类。
1. 2D姿态估计-了解人体运动
这个任务就像给模型一张图片,让它猜出关键的身体部位在哪里。该模型会查找眼睛、肘部、膝盖等位置。例如,如果您上传了某人跑步的照片,该模型可以准确识别他们的手臂、腿和头部在图像中的位置。
这个过程的工作原理是创建"热图",显示身体部位在特定位置的可能性。该模型经过训练,通过调整直到其猜测(热图)与身体部位的真实的位置紧密匹配,从而将误差降至最低。
体系结构:
- 输入: 图像(
I ∈ R^H×W×3,其中H为高度,W为宽度)。 - 第1步:重新缩放图像 -输入图像的大小调整为固定的高度
H和宽度W。这样做是为了标准化所有图像的输入大小。 - 步骤2:姿态估计Transformer(P)-Transformer模型处理图像以预测关键点位置。
这涉及:
边界框输入: 在图像中的人周围提供边界框。
关键点热图: 该模型生成K个热图,其中每个热图表示关键点位于某个位置的概率。例如,一个热图用于右肘,另一个热图用于左膝,依此类推。
- 步骤3:损失函数(均方误差) -这里使用的损失函数是均方误差(MSE)。该模型将预测的热图与地面实况关键点
y进行比较,并使用MSE计算差异:``
L_pose = MSE(y,y) - 步骤4:编码器-解码器架构 -姿态估计模型使用编码器-解码器设置。编码器 使用来自预训练的权重初始化,而解码器随机初始化。然后,整个系统针对关键点预测的任务进行微调。
- 关键点差异: 与以前的模型(可能只能检测68个面部点)相比,Meta的Sapiens模型可以检测多达243个面部关键点,捕获眼睛,嘴唇,鼻子,耳朵等周围的更精细的细节。
操作步骤
下载姿势模型的检查点,并执行进一步的步骤:
python
TASK = 'pose'
VERSION = 'sapiens_1b'
model_path = get_model_path(TASK, VERSION)
print(model_path)使用"sapiens"模型函数定义姿势函数:
python
def get_pose(image, pose_estimator, input_shape=(3, 1024, 768), device="cuda"):
# Preprocess the image
img = preprocess_image(image, input_shape)
# Run the model
with torch.no_grad():
heatmap = pose_estimator(img.to(device))
# Post-process the output
keypoints, keypoint_scores = udp_decode(heatmap[0].cpu().float().numpy(),
input_shape[1:],
(input_shape[1] // 4, input_shape[2] // 4))
# Scale keypoints to original image size
scale_x = image.width / input_shape[2]
scale_y = image.height / input_shape[1]
keypoints[:, 0] *= scale_x
keypoints[:, 1] *= scale_y
# Visualize the keypoints on the original image
pose_image = visualize_keypoints(image, keypoints, keypoint_scores)
return pose_image
def preprocess_image(image, input_shape):
# Resize and normalize the image
img = image.resize((input_shape[2], input_shape[1]))
img = np.array(img).transpose(2, 0, 1)
img = torch.from_numpy(img).float()
img = img[[2, 1, 0], ...] # RGB to BGR
mean = torch.tensor([123.675, 116.28, 103.53]).view(3, 1, 1)
std = torch.tensor([58.395, 57.12, 57.375]).view(3, 1, 1)
img = (img - mean) / std
return img.unsqueeze(0)
def udp_decode(heatmap, img_size, heatmap_size):
# This is a simplified version. You might need to implement the full UDP decode logic
h, w = heatmap_size
keypoints = np.zeros((heatmap.shape[0], 2))
keypoint_scores = np.zeros(heatmap.shape[0])
for i in range(heatmap.shape[0]):
hm = heatmap[i]
idx = np.unravel_index(np.argmax(hm), hm.shape)
keypoints[i] = [idx[1] * img_size[1] / w, idx[0] * img_size[0] / h]
keypoint_scores[i] = hm[idx]
return keypoints, keypoint_scores
def visualize_keypoints(image, keypoints, keypoint_scores, threshold=0.3):
draw = ImageDraw.Draw(image)
for (x, y), score in zip(keypoints, keypoint_scores):
if score > threshold:
draw.ellipse([(x-2, y-2), (x+2, y+2)], fill='red', outline='red')
return image加载输入图像:
python
from utils.vis_utils import resize_image
pil_image = Image.open('path/to/input/image')
if pil_image.mode == 'RGBA':
pil_image = pil_image.convert('RGB')
resized_pil_image = resize_image(pil_image, (640, 480))
resized_pil_image
输出:
python
from PIL import Image, ImageDraw
output_pose = get_pose(resized_pil_image, model)
2.身体部位分割-了解人体骨骼
在这个任务中,模型对图像中的每个像素进行分类,将其分解为手臂,腿或面部等身体部位。例如,如果你上传一张照片,模型可以将你的脸和头发分开,将你的手和手臂分开。这有助于虚拟试穿系统或动画角色等任务。
Meta的Sapiens模型使用了一个巨大的词汇表(28个身体部位)来给出详细的结果。它不仅仅是手臂和腿,还可以区分上下嘴唇,牙齿甚至手指。
体系结构:
- 输入: 图像(
I ∈ R^H×W×3),类似于姿态估计。 - 步骤1:编码器-解码器架构 -身体部位分割模型遵循与姿势估计相同的编码器-解码器设置。编码器 从输入图像中提取特征,解码器将这些特征转换为逐像素预测。
- 步骤2:像素分类 -该模型将图像的每个像素分类为
C个身体部位类别之一(例如,头部、手臂、躯干等)。例如,标准分割中的C = 20,但Meta将其扩展到C = 28,并使用更详细的词汇,包括上/下唇,牙齿和舌头等区别。 - 步骤3:损失函数(加权交叉熵) -使用加权交叉熵损失对模型进行微调,该加权交叉熵损失 将预测的身体部位类别
p与基础事实p进行比较。
L_seg =加权CE(p,p <0) - 第4步:扩展词汇分辨率-智人模型使用高分辨率图像(4K分辨率),并使用这些详细的身体部位标签手动注释超过100 K的图像。与以前的模型相比,分割词汇量要大得多,使其对人体部位有更细粒度的理解。
注意:尽管Meta Sapiens在身体部位分割方面取得了进步,但它仍然无法达到与SAM 或SAM 2 等基于掩码的分割模型相同的精度水平。这些模型提供了更准确和详细的掩模,特别是对于细粒度的对象边界。
具体步骤:
加载分段权重并执行以下步骤:
python
def get_model_path(task, version):
try:
model_path = SAPIENS_LITE_MODELS_PATH[task][version]
if not os.path.exists(model_path):
print(f"Warning: The model file does not exist at {model_path}")
return model_path
except KeyError as e:
print(f"Error: Invalid task or version. {e}")
return None
# Example usage
TASK = 'seg'
VERSION = 'sapiens_0.3b'
model_path = get_model_path(TASK, VERSION)
print(model_path)从"sapiens"模型实现分割函数:
python
def segment(image):
input_tensor = transform_fn(image).unsqueeze(0).to("cuda")
preds = run_model(input_tensor, height=image.height, width=image.width)
mask = preds.squeeze(0).cpu().numpy()
mask_image = Image.fromarray(mask.astype("uint8"))
blended_image = visualize_mask_with_overlay(image, mask_image, LABELS_TO_IDS, alpha=0.5)
return blended_image加载输入图像:
python
pil_image = Image.open('sapiens2.jpg')
if pil_image.mode == 'RGBA':
pil_image = pil_image.convert('RGB')
resized_pil_image = resize_image(pil_image, (640, 480))
resized_pil_image
输出:
元分割的输出结果并不令人满意,它没有清楚地显示人体分割;相反,Meta的SAMsegment anything model更好地分割图像。


3.深度估计
深度估计帮助模型了解图像的不同部分有多远。这就像赋予模型分辨照片中什么是近的,什么是远的能力。例如,在一张站在汽车附近的人的照片中,模型可以估计这个人离汽车有多远,这对于增强现实等任务很重要。
体系结构:
- 输入: 图像(
I ∈ R^H×W×3)。 - 步骤1:编码器-解码器架构 -与身体部位分割类似,编码器 从图像中提取特征,解码器预测每个像素的深度。
- 步骤2:单通道深度图 -深度估计的关键区别在于输出通道 设置为1,这会生成深度图 。这个深度图(
d ∈ R^H×W)预测图像中的每个点离相机有多远。 - 步骤3:损失函数(回归) -深度估计任务被视为回归 问题。模型将其预测深度值(
d_depth)与地面实况(d)进行比较,并使用回归损失使差异最小化:||d − d|| 1 - 第4步:合成数据训练-为了提高深度预测,Meta Sapiens使用合成人类数据,包括来自RenderPeople的600个高分辨率3D人体扫描。这使得该模型即使在困难的情况下也能生成详细和现实的深度估计。
实现步骤:
加载深度权重:
python
TASK = 'depth'
VERSION = 'sapiens_0.3b'
model_path = get_model_path(TASK, VERSION)
print(model_path)使用"sapiens"模型编写深度函数:
python
def get_depth(image, depth_model, input_shape=(3, 1024, 768), device="cuda"):
# Preprocess the image
img = preprocess_image(image, input_shape)
# Run the model
with torch.no_grad():
result = depth_model(img.to(device))
# Post-process the output
depth_map = post_process_depth(result, (image.shape[0], image.shape[1]))
# Visualize the depth map
depth_image = visualize_depth(depth_map)
return depth_image, depth_map
def preprocess_image(image, input_shape):
img = cv2.resize(image, (input_shape[2], input_shape[1]), interpolation=cv2.INTER_LINEAR).transpose(2, 0, 1)
img = torch.from_numpy(img)
img = img[[2, 1, 0], ...].float()
mean = torch.tensor([123.5, 116.5, 103.5]).view(-1, 1, 1)
std = torch.tensor([58.5, 57.0, 57.5]).view(-1, 1, 1)
img = (img - mean) / std
return img.unsqueeze(0)
def post_process_depth(result, original_shape):
# Check the dimensionality of the result
if result.dim() == 3:
result = result.unsqueeze(0)
elif result.dim() == 4:
pass
else:
raise ValueError(f"Unexpected result dimension: {result.dim()}")
# Ensure we're interpolating to the correct dimensions
seg_logits = F.interpolate(result, size=original_shape, mode="bilinear", align_corners=False).squeeze(0)
depth_map = seg_logits.data.float().cpu().numpy()
# If depth_map has an extra dimension, squeeze it
if depth_map.ndim == 3 and depth_map.shape[0] == 1:
depth_map = depth_map.squeeze(0)
return depth_map
def visualize_depth(depth_map):
# Normalize the depth map
min_val, max_val = np.nanmin(depth_map), np.nanmax(depth_map)
depth_normalized = 1 - ((depth_map - min_val) / (max_val - min_val))
# Convert to uint8
depth_normalized = (depth_normalized * 255).astype(np.uint8)
# Apply colormap
depth_colored = cv2.applyColorMap(depth_normalized, cv2.COLORMAP_INFERNO)
return depth_colored
# You can add the surface normal calculation if needed
def calculate_surface_normal(depth_map):
kernel_size = 7
grad_x = cv2.Sobel(depth_map.astype(np.float32), cv2.CV_32F, 1, 0, ksize=kernel_size)
grad_y = cv2.Sobel(depth_map.astype(np.float32), cv2.CV_32F, 0, 1, ksize=kernel_size)
z = np.full(grad_x.shape, -1)
normals = np.dstack((-grad_x, -grad_y, z))
normals_mag = np.linalg.norm(normals, axis=2, keepdims=True)
with np.errstate(divide="ignore", invalid="ignore"):
normals_normalized = normals / (normals_mag + 1e-5)
normals_normalized = np.nan_to_num(normals_normalized, nan=-1, posinf=-1, neginf=-1)
normal_from_depth = ((normals_normalized + 1) / 2 * 255).astype(np.uint8)
normal_from_depth = normal_from_depth[:, :, ::-1] # RGB to BGR for cv2
return normal_from_depth加载输入图像:
python
from utils.vis_utils import resize_image
pil_image = Image.open('/home/user/app/assets/image.webp')
# Load and process an image
image = cv2.imread('/home/user/app/assets/frame.png')
depth_image, depth_map = get_depth(image, model)输出:
python
surface_normal = calculate_surface_normal(depth_map)
cv2.imwrite("output_surface_normal.jpg", surface_normal)
# Save the results
output_im = cv2.imwrite("output_depth_image2.jpg", depth_image)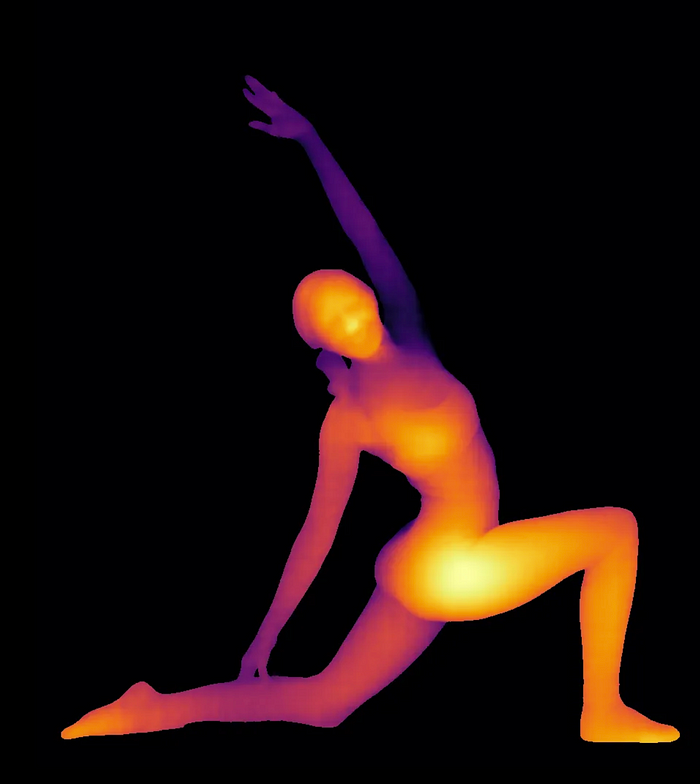
4.表面法线估计
此任务允许模型计算出人体的3D表面细节,例如表面在每个点处的角度或方向。例如,它可以理解一个人的面部曲线或手臂和腿的角度。
体系结构:
- 输入: 图像(
I ∈ R^H×W×3)。 - 步骤1:编码器-解码器架构-与前面的任务一样,正常估计模型使用编码器-解码器框架。编码器从图像中提取特征,解码器被调整为正常预测。
- 步骤2:曲面法线的三通道输出 -对于法线估计,解码器 输出通道设置为3,对应于法线向量的
xyz分量。每个像素都会获得一个xyz值,该值表示该点处的表面所面向的方向。 - 步骤3:损失函数(余弦相似性) -该模型使用L1损失 和余弦相似性 的组合来比较预测的法向矢量(
n)与地面真实法向(n)。损失计算为:L_normal = ||n − n̂||1 + (1 − n · n̂) - 第4步:来自合成数据的监督-就像深度估计一样,正常估计依赖于合成的人类数据进行监督。这使得模型能够准确预测表面方向,即使是在复杂的情况下,如弯曲的身体部位或极端的姿势。
实现步骤:
加载正常重量:
python
TASK = 'normal'
VERSION = 'sapiens_0.3b'
model_path = get_model_path(TASK, VERSION)
print(model_path)从"sapiens"模型定义正常函数:
python
import torch
import torch.nn.functional as F
import numpy as np
import cv2
def get_normal(image, normal_model, input_shape=(3, 1024, 768), device="cuda"):
# Preprocess the image
img = preprocess_image(image, input_shape)
# Run the model
with torch.no_grad():
result = normal_model(img.to(device))
# Post-process the output
normal_map = post_process_normal(result, (image.shape[0], image.shape[1]))
# Visualize the normal map
normal_image = visualize_normal(normal_map)
return normal_image, normal_map
def preprocess_image(image, input_shape):
img = cv2.resize(image, (input_shape[2], input_shape[1]), interpolation=cv2.INTER_LINEAR).transpose(2, 0, 1)
img = torch.from_numpy(img)
img = img[[2, 1, 0], ...].float()
mean = torch.tensor([123.5, 116.5, 103.5]).view(-1, 1, 1)
std = torch.tensor([58.5, 57.0, 57.5]).view(-1, 1, 1)
img = (img - mean) / std
return img.unsqueeze(0)
def post_process_normal(result, original_shape):
# Check the dimensionality of the result
if result.dim() == 3:
result = result.unsqueeze(0)
elif result.dim() == 4:
pass
else:
raise ValueError(f"Unexpected result dimension: {result.dim()}")
# Ensure we're interpolating to the correct dimensions
seg_logits = F.interpolate(result, size=original_shape, mode="bilinear", align_corners=False).squeeze(0)
normal_map = seg_logits.float().cpu().numpy().transpose(1, 2, 0) # H x W x 3
return normal_map
def visualize_normal(normal_map):
normal_map_norm = np.linalg.norm(normal_map, axis=-1, keepdims=True)
normal_map_normalized = normal_map / (normal_map_norm + 1e-5) # Add a small epsilon to avoid division by zero
# Convert to 0-255 range and BGR format for visualization
normal_map_vis = ((normal_map_normalized + 1) / 2 * 255).astype(np.uint8)
normal_map_vis = normal_map_vis[:, :, ::-1] # RGB to BGR
return normal_map_vis
def load_normal_model(checkpoint, use_torchscript=False):
if use_torchscript:
return torch.jit.load(checkpoint)
else:
model = torch.export.load(checkpoint).module()
model = model.to("cuda")
model = torch.compile(model, mode="max-autotune", fullgraph=True)
return model输入图像:
python
import cv2
import numpy as np
# Load the model
normal_model = load_normal_model(model_path, use_torchscript='_torchscript')
# Load the image
image = cv2.imread("/home/user/app/assets/image.webp")输出:

Meta Sapiens的局限
尽管Meta Sapiens擅长理解与人类相关的任务,但它在更复杂的场景中面临挑战。例如,当多个人站在一起(拥挤),或者当个人处于不寻常或罕见的姿势时,模型很难准确估计姿势和分割身体部位。此外,当身体的部分被隐藏时,严重的遮挡会使模型提供精确结果的能力进一步复杂化。
结论
Meta Sapiens代表了以人为中心的AI向前迈出的重要一步,提供了跨姿态估计,分割,深度预测和表面法线估计的强大功能。然而,像许多模型一样,它仍然有局限性,特别是在拥挤或高度复杂的场景中。随着人工智能的不断发展,像Sapiens这样的模型的未来迭代有望解决这些挑战,使我们更接近更准确和可靠的以人为本的应用程序。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!