在深度学习,特别是计算机视觉任务中,感受野(Receptive Field)是一个至关重要的概念。它指的是在神经网络中某一层的神经元在输入图像上"看到"的区域大小。感受野的大小影响了网络能捕捉的特征层级,从而决定了它的特征提取能力。因此,理解感受野如何逐层扩展、如何对不同特征进行分级,是深入理解深度学习图像处理的关键。本文将通过一个分层特征提取示例,解释感受野在多层卷积操作中的变化过程,并展示如何利用感受野进行多尺度特征提取。
感受野的基本概念
感受野可以简单理解为神经元"看到"的图像区域。当网络层数逐渐加深,感受野会逐渐增大,使得每一层的神经元能够"看到"更大的图像区域,从而提取到更高级的特征。一般来说,感受野较小的神经元只能提取到局部细节信息,而较大的感受野可以捕捉到全局信息,使得模型能够识别更复杂的图像模式。
示例代码:
python
# 简单展示卷积层如何影响感受野大小
import torch
import torch.nn as nn
# 定义一个简单的卷积网络
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1) # 第一层卷积
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1) # 第二层卷积
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
# 假设输入是 32x32 的图像
input_image = torch.randn(1, 1, 32, 32)
model = ConvNet()
output = model(input_image)
print("Output size:", output.size())
#输出为
#Output size: torch.Size([1, 32, 32, 32])这段代码定义了一个简单的两层卷积网络,每层卷积操作后感受野会逐渐扩大,最终在图像上"看到"更大的区域。
代码基本结构说明
代码定义了一个简单的卷积神经网络ConvNet,包含两个卷积层conv1和conv2。
conv1接收单通道的输入图像,并输出16个通道(即生成16个特征图)conv2接收16个通道的输入,输出32个通道(生成32个特征图)。- 每个卷积层的卷积核(kernel_size)大小都是
3×3。这意味着每个卷积核在输入特征图上查看一个3×3的区域。 - 步幅(stride)设置为
1,即卷积核每次移动一个像素,这会导致卷积层生成与输入大小相似的特征图。 - 填充(padding)设置为
1,即在输入的边缘填充一个像素宽的0,以确保卷积后的输出大小与输入一致。
感受野的概念
在卷积网络中,感受野可以理解为网络中某个层或某个神经元在输入图像上"看到"的区域。随着卷积层的叠加,感受野逐渐增大,使得网络能够提取到更大的区域信息。
在以上代码中,通过叠加两个卷积层,网络的感受野会比单层卷积更大,下面详细解释感受野在每一层的扩展过程。
逐层计算感受野
感受野计算公式
R o u t = R i n + ( K − 1 ) × S R_{out}=R_{in}+(K-1)×S Rout=Rin+(K−1)×S
其中:
- R o u t R_{out} Rout是输出的感受野大小,
- R i n R_{in} Rin是输入的感受野大小,
- K K K是卷积核的大小,
- S S S是卷积层的步幅。
第一层卷积conv1的感受野
-
初始时,输入图像的每个像素的感受野为
1(即输入自身)。 -
conv1的卷积核为3×3,步幅为1,意味着每个卷积输出对应的感受野扩大为3,因为卷积核在3×3的区域滑动。计算如下:R c o n v 1 = 1 + ( 3 − 1 ) × 1 = 3 R_{conv1}=1+(3-1)×1=3 Rconv1=1+(3−1)×1=3
因此,在
conv1之后,每个输出特征图的像素点"看到"输入图像上3×3的区域。
第二层卷积conv2的感受野
-
现在,进入第二层
conv2时,输入的感受野为3。 -
conv2的卷积核也是3×3,步幅为1。该层的感受野计算如下:R c o n v 2 = 3 + ( 3 − 1 ) × 1 = 5 R_{conv2}=3+(3-1)×1=5 Rconv2=3+(3−1)×1=5
这意味着在
conv2之后,每个输出特征图的像素点的感受野扩大到了5×5,即它们能够"看到"输入图像的5×5区域。
输出
代码中的输入input_image是一个32×32大小的图像,经过两层卷积后,输出的大小仍然是32×32,因为填充和步幅的设置保持了输出尺寸不变。
python
print("Output size:", output.size())
#输出为
#Output size: torch.Size([1, 32, 32, 32])感受野的作用
通过以上分析可以看出,随着卷积层的堆叠,感受野逐渐增大。这种逐层扩展的感受野使得模型能够捕捉到更大的区域信息,识别更复杂的特征。换句话说,堆叠卷积层的过程是感受野逐步扩大的过程,越深层的神经元就能"看到"更大的图像区域。
图像金字塔与分层特征提取
在多层卷积网络中,分层特征提取是一种常见的技术,我们可以通过逐层分解来提取不同尺度的特征。图像金字塔(Image Pyramid)是这种方法的直观表现,通过对图像进行多次降采样,逐渐提取更高级的特征。如下图所示,在图中,我们展示了一个图像金字塔的简单示例,图像在每一层被逐步分解为低频和高频成分。每一层的低频成分代表了较大的感受野,而高频成分则保留了更多的局部细节部分。
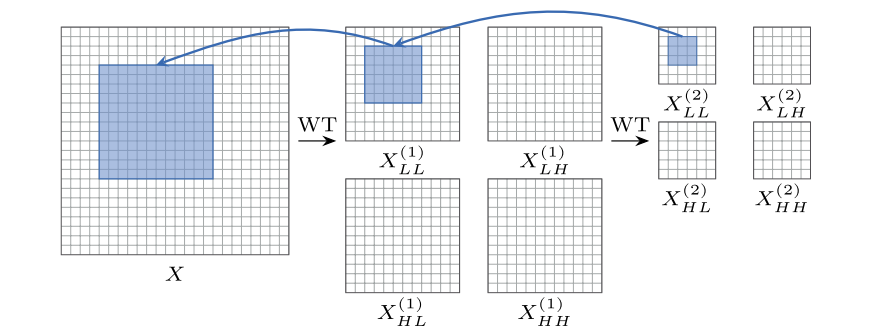
图中展示了如何通过小波变换(WT)操作逐层分解图像,扩大感受野,提取不同的特征:对输入的图像 X X X首先进行通过一次小波分解得到第一层低频 X L L ( 1 ) X_{LL}^{(1)} XLL(1)和高频 X L H ( 1 ) 、 X H L ( 1 ) X_{LH}^{(1)}、X_{HL}^{(1)} XLH(1)、XHL(1)和 X H H ( 1 ) X_{HH}^{(1)} XHH(1)成分,低频成分包含了全局信息,高频成分包含细节,然后对第一层分解后的低频部分再应用小波分解,获得更高层的分解,通过多层分解扩大感受野,逐步将模型分为低频和高频成分,使得模型可以同时关注全局信息和细节信息。
详细解释:假设输入的图像初始分辨率是256×256
第一次小波分解:
- 图像被分解为低频和高频,其中低频的部分分辨率降低一半为128×128
- 在128×128的低频图像上应用3×3的卷积核,每个像素在128×128的图像对应于原图的2×2像素(分辨率减半)
- 一个3×3卷积核在128×128的低频图像上相当于在原图上看到6×6像素区域(3×2),所以感受野扩大两倍为6×6
第二次小波分解:
- 在第一次的基础上再小波分解,低频成分的分辨率进一步减半为64×64
- 在64×64的低频图像上,每个像素对应于原图的4×4像素(两次分辨力减半2×2)
- 3×3的卷积和在64×64的图像上相当于覆盖了原图的12×12像素区域(3×4)
以上就是关于上图中感受野扩大的过程详解。
感受野扩展与特征提取能力
感受野的逐层扩展可以增强模型的特征提取能力,使其在同时关注全局信息和局部细节的基础上,对图像特征进行更准确的表征。在深度卷积神经网络中,通过逐层的卷积和池化操作,感受野可以被大大扩展,最终使得深层的神经元能够"看到"整个图像区域。
我们可以通过一下代码示例,计算卷积层和池化层对感受野的影响:
python
import torch
import torch.nn as nn
def calculate_receptive_field(layers):
receptive_field = 1
for layer in layers:
if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.MaxPool2d):
receptive_field = receptive_field + (layer.kernel_size[0] - 1) * layer.stride[0]
return receptive_field
# 创建卷积层和池化层
layers = [
nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
]
print("Receptive field size:", calculate_receptive_field(layers))
# 输出为:
#Receptive field size: 5通过以上代码,我们可以估算出在不同网络层组合下的感受野大小。
感受野在深度学习任务中的应用案例
- 图像分类:在图像分类任务中,较大的感受野帮助模型捕捉全局的物体信息,从而提高分类精度。例如,深度卷积网络能够在最后的全连接层"看到"整个图像,进而根据全局特征做出准确判断。
- 目标检测和分割:在目标检测和图像分割中,感受野的大小影响了模型的定位能力和分割精度。较大感受野使得网络可以捕捉到物体的整体轮廓,而小感受野可以关注物体的细节,使分割边界更准确。
参考文献
-
Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding convolutional networks. In European Conference on Computer Vision (pp. 818-833). Springer, Cham.
-
Luo, W., Li, Y., Urtasun, R., & Zemel, R. (2016). Understanding the effective receptive field in deep convolutional neural networks. arXiv preprint arXiv:1701.04128.
-
O'Shea, K., & Nash, R. (2015). An introduction to convolutional neural networks. arXiv preprint arXiv:1511.08458.
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
introduction to convolutional neural networks. arXiv preprint arXiv:1511.08458.
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
-
Mallat, S. (1999). A wavelet tour of signal processing. Academic Press.