银行信贷风控专题:Python、R 语言机器学习数据挖掘应用实例合集:xgboost、决策树、随机森林、贝叶斯等
原创 拓端研究室
在当今金融领域,风险管控至关重要。无论是汽车贷款违约预测、银行挖掘潜在贷款客户,还是信贷风控模型的构建,以及基于决策树的银行信贷风险预警,都是金融机构面临的关键挑战。
本银行信贷风控专题合集将通过代码和数据案例深入探讨这些金融场景中的问题与解决方案,通过对数据的深入分析、模型的构建与优化,为金融机构提供有效的风险管控策略,以促进金融市场的稳定与健康发展。
汽车贷款违约预测
作为违约预测类项目,本项目同样拥有数据不均衡的问题,即违约的数据相较于不违约的数据占比较小。此外,若不对数据进行深度理解、处理,模型的训练结果十分糟糕,F1分数仅有0.01。
解决方案
任务/目标
本项目以F1分数和准确率为评判标准,通过对数据的处理,机器学习模型的训练,尽可能提高违约预测的有效性。
数据****预处理
 查看数据的分布情况,对ID等无效特征进行剔除。
查看数据的分布情况,对ID等无效特征进行剔除。
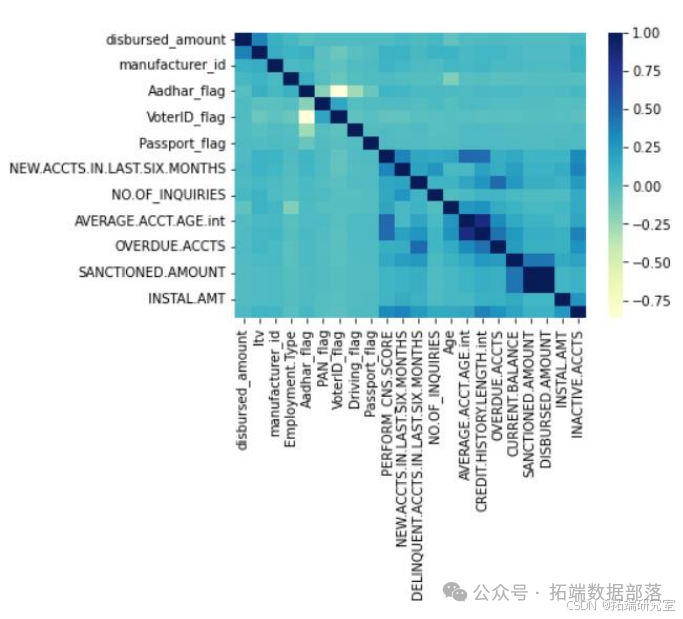
通过查看特征之间的相关性,去掉与其他特征相关性95%以上的特征,避免多重共线性。
对于形式为"X年X月"的特征,转换为月份数,以此将字符串数据转换为数值型数据。

对于文字类数据,通过对各个种类的理解用数字划分信用等级,数字越高代表借款人信用记录越好。
特征包含了主要账户和次要账户的各种信息,此处将两个账户的信息合并(例如:将主要账户余额、第二账户余额合并)。
由于很多特征对于大部分借款人来说是0,因此新增一个特征,记录每个借款人之前所有特征中数值为0的个数。
以上例举的只是部分特征。
构造
以上说明了如何抽取相关特征,我们大致有如下训练样本(只列举部分特征)。
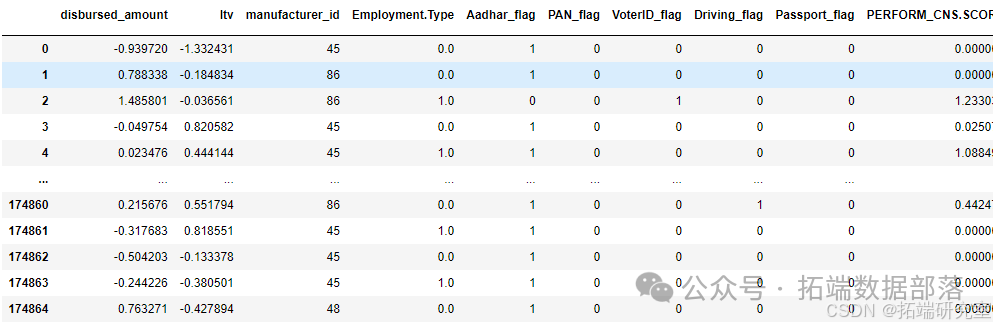
划分训练集和测试集
考虑到最终模型会预测将来的某时间段的销量,为了更真实的测试模型效果,切分训练集和验证集。具体做法如下:利用train_test_split()函数进行训练集、验证集划分,将30%的数据作为验证集,用于对机器学习模型调参。
建模
线性模型:利用AWS Sagemaker中的LinearLearner模型作为基准,通过对XGBoost模型的训练,调参以得到更好的预测效果。
X****GBoost:
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。
模型优化
优化方法:参数调参
结果

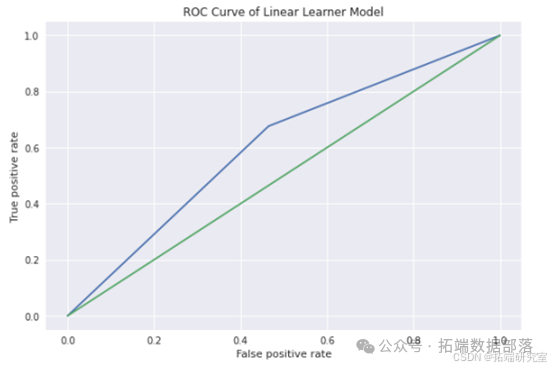
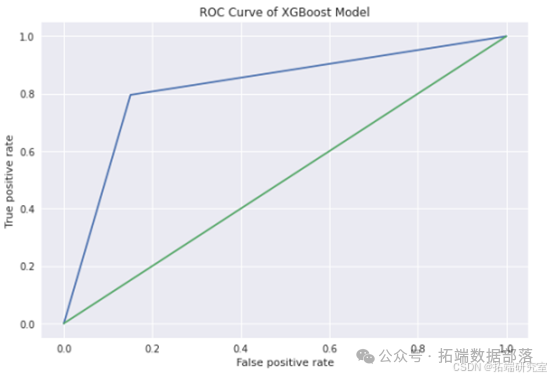
在此案例中,通过对数据的处理,即使最基本的线性模型也有0.6的F1分数,比最初的0.01有了大幅提高。此外,通过利用AWS Sagemaker的Hyperparameter Tuning相关函数,对XGBoost模进行调参、训练,最终F1结果达到了0.8以上,有了显著提升。对汽车贷款违约预测有效性有了大幅提高。
ning相关函数,对XGBoost模进行调参、训练,最终F1结果达到了0.8以上,有了显著提升。对汽车贷款违约预测有效性有了大幅提高。