飞猪SQL面试题---重点用户
在一些场景中我们经常听到这样的一些描述,例如20%的用户贡献了80%的销售额,或者是20%的人拥有着80%的财富,你知道这样的数据是怎么算出来的吗
数据如下,uid 是用户的id ,amount是用户的消费金额
|uid|amount|
+---+------+
| 1| 20|
| 2| 19|
| 3| 3000|
| 4| 200|
| 5| 300|
| 6| 2000|
| 7| 10|
| 8| 3|
| 9| 2|
| 10| 1|
| 11| 1|
| 12| 4000|
| 13| 5|
| 14| 5|
+---+------+现在我们需要
- 计算出贡献出90%的销售额的用户
- 贡献出90%的销售额用户的人数占比
这里的计算逻辑就是按照用户的销售额从大到小进行累加,找到超过90的临界点,那这些用户就是我贡献出90%的销售额的用户,是重点用户。
计算出当前销售额和累计销售额的占比
首先我们计算出当前销售额和累计销售额,我们直接使用sum 窗口函数即可,这里我们没有partition by ,因为我们就是计算全部,不需要分组
select
uid
,amount
,sum(amount)over(order by amount desc) as cur_amount
,sum(amount)over() as total_amount
from amount有了cur_amount和total_amount 计算占比就很简单了
select
uid
,amount
,round(sum(amount)over(order by amount desc) /sum(amount)over(),2) as rate
from amount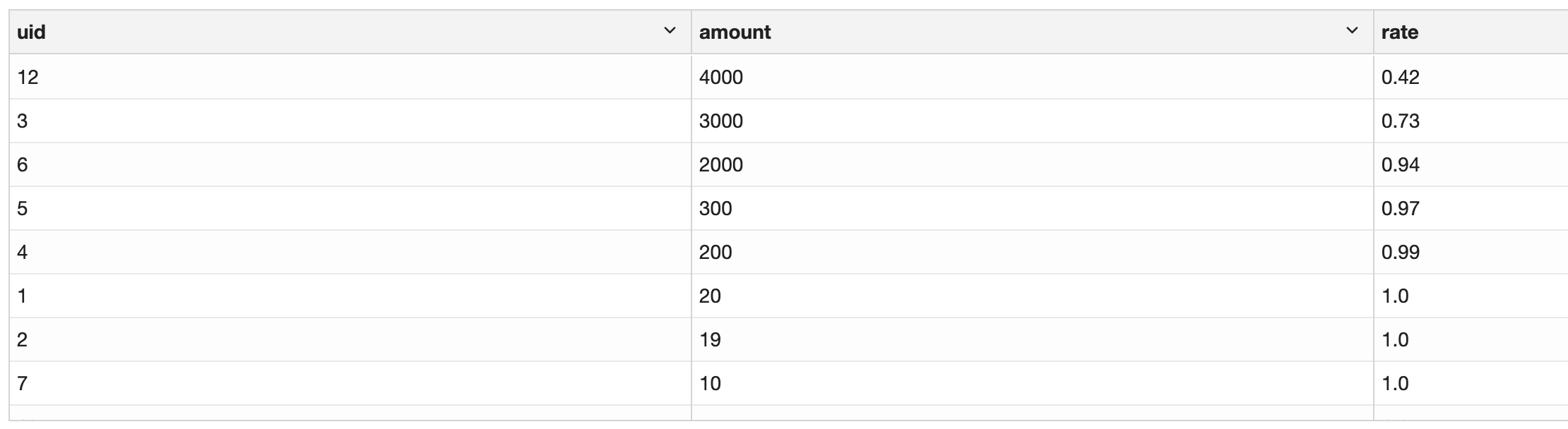
找到临界点
其实这个这个时候我们可以看到在第三个用户也就是用户id 为6的那一行,累计销售占比已经超过了90%,也就是94%,此时的用户id 是13、3、6,这个时候我们的问题是我们要怎么把三个用户提出来呢
一般这个时候我们有两种实现方式
- 排序,就像提取分组前几一样,我们通过序号小于等于多少
- 标志位,满足的都是true 不满足的都是false,或者满足的都是1不满足的都是0
我们这个场景很明显用排序不是那么方便,因为这里的百分比值没有准确等于90%的,跟排序不一样,所以我们用标志位,我们要的数据用true 表示,不要的用false 表示
这里我们判断true 的逻辑是
-
rate 小于0.9
-
当前rate 大于等于0.9,但是前面一个rate 小于0.9,那么此时当前记录包括之前的记录都是我们需要的,当前记录就是边界
select
uid
,amount
,rate
,if(rate<0.9 or (rate>0.9 and lag(rate,1,0)over(order by amount desc)<0.9),true,false) as flag
from(
select
uid
,amount
,round(sum(amount)over(order by amount desc) /sum(amount)over(),2) as rate
from amount
)tmp
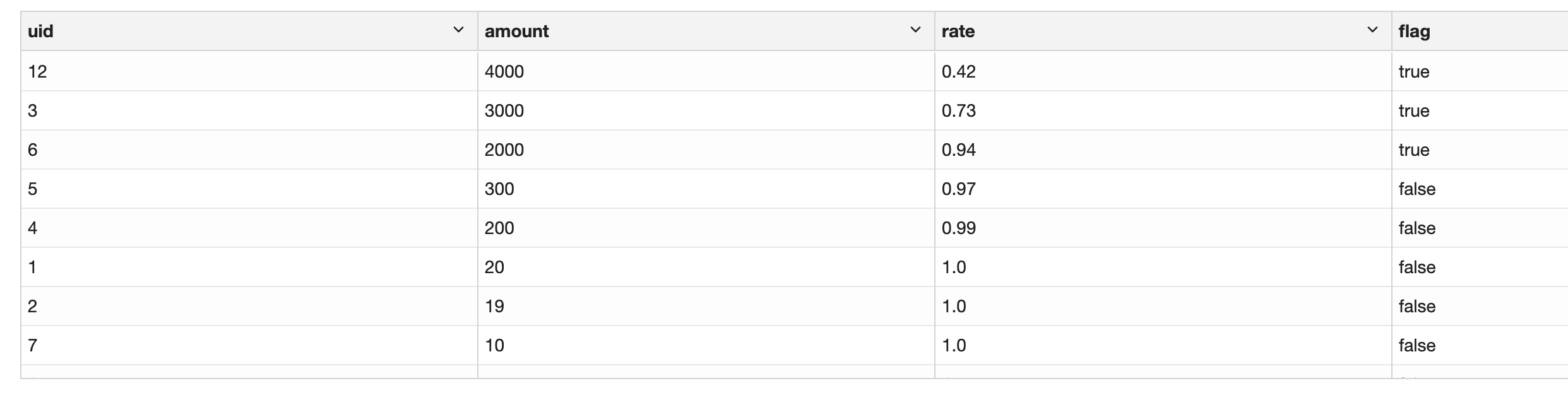
我们可以看到数据是正确的,最后汇总一下
select
flag,count(1)
from(
select
uid
,amount
,rate
,if(rate<0.9 or (rate>0.9 and lag(rate,1,0)over(order by amount desc)<0.9),true,false) as flag
from(
select
uid
,amount
,round(sum(amount)over(order by amount desc) /sum(amount)over(),2) as rate
from amount
)tmp
)
group by flag
grouping sets(flag,null)
总共14个人中,3个人的消费占了90%的总消费额