
本文深入探讨了检索增强生成(RAG)技术在AI工作流中的应用,特别是OpenAI的o1系列模型和Google的Gemini 1.5模型在长上下文RAG任务中的性能,分析了不同模型在长上下文RAG任务中的失败模式,为开发者构建RAG系统提供了宝贵参考。
(本文由OneFlow编译发布,转载请联系授权。原文:https://www.databricks.com/blog/long-context-rag-capabilities-openai-o1-and-google-gemini)
来源|Databricks
翻译|张雪聃、林心宇
OneFlow编译
题图由 SiliconCloud平台生成
检索增强生成(RAG)是Databricks的客户希望在自身数据上定制AI工作流的主要应用场景。大语言模型(LLM)发布的速度非常快,许多客户都想获得最新的指导,以构建最佳的RAG流水线。在之前的博客文章中(LLM的长上下文RAG性能,https://www.databricks.com/blog/long-context-rag-performance-llms),我们在13种流行的开源和商用LLM上进行了超过2000次的长上下文RAG实验,以揭示它们在各种领域特定数据集上的表现。发布这篇博客后,我们收到了许多请求,希望对更多顶尖模型进行进一步的基准测试。
九月,OpenAI发布了GPT o1,依靠额外的推理时计算来增强"推理"能力。我们很想看看这些新模型在我们内部基准测试中会有怎样的表现;增加推理时计算是否会带来显著提升?
我们设计了评估套件,对长上下文的RAG工作流进行压力测试。Google Gemini 1.5模型是唯一具备200万词元上下文长度的顶尖模型,我们对Gemini 1.5模型(5月发布)的表现感到兴奋。200万词元大致相当于一个包含数百篇文档的小型语料库;在这种情况下,开发者构建自定义AI系统时,原则上可以完全跳过检索和RAG,直接将整个语料库包含在LLM上下文窗口中。这些超长上下文模型真的能替代检索吗?
随后,我们对新的顶尖模型OpenAI o1-preview、o1-mini以及Google Gemini 1.5 Pro和Gemini 1.5 Flash进行了基准测试。在进行这些额外实验后,我们发现:
-
在我们长上下文RAG基准测试中,OpenAI o1模型相比Anthropic和Google模型有持续提升,支持上下文长度最高可达128k词元。
-
尽管性能不如顶尖的OpenAI和Anthropic模型,但Google Gemini 1.5模型在极端上下文长度(最高达200万词元)下展现了稳定的RAG性能。
-
不同模型在长上下文RAG任务中表现出不同的失败模式。
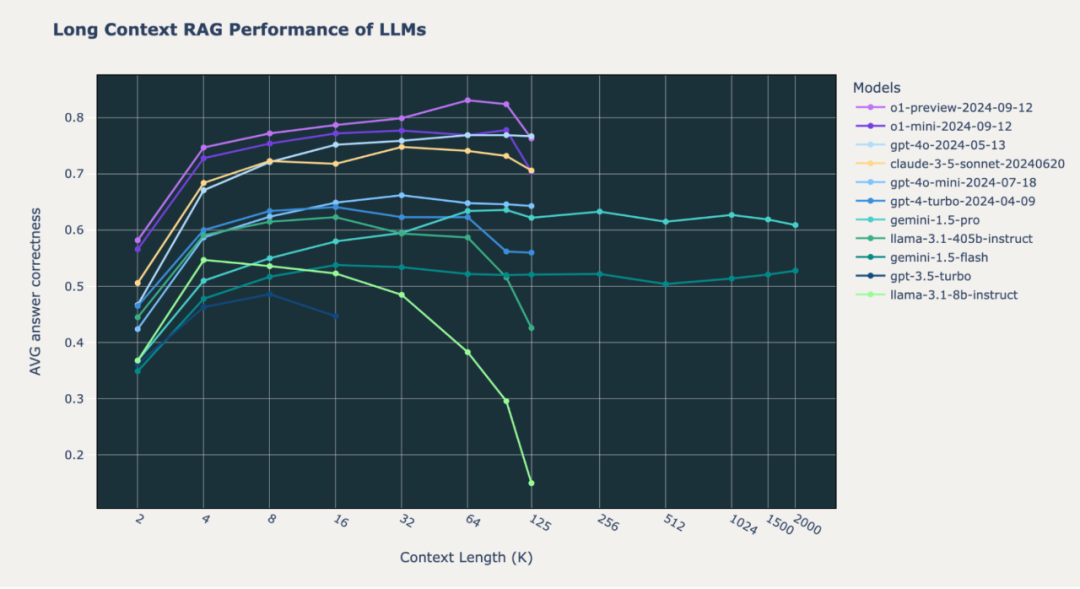
图1: 尖端模型在三个精选的RAG数据集(Databricks DocsQA、FinanceBench和Natural Questions)上的长上下文性能。上下文长度以千词元为单位,从2k到200万词元进行衡量。
1
前文回顾
我们设计了内部基准来测试尖端LLM的长上下文端到端RAG能力。基本设置如下:
- 从使用OpenAI的text-embedding-3-large嵌入的向量数据库中检索文档片段(chunk)。文档被分割为512词元的片段,步长为256词元。
- 通过在上下文窗口中包含更多检索文档来改变总词元数。我们将总词元数从2k增加到200万。
- 系统必须根据检索的文档正确回答问题。答案由经过校准的LLM(使用GPT-4o)进行评判。
我们的内部基准包括三个独立的精选数据集:Databricks DocsQA、FinanceBench和Natural Questions (NQ)。
在之前的博客文章(*https://www.databricks.com/blog/long-context-rag-performance-llms*)中,我们发现:
- 检索更多文档确实有益:为给定查询检索更多信息,能够提升将正确信息传递给LLM的可能性。具有长上下文长度的现代LLM可以利用这一点,从而改善整体RAG系统。
- 更长的上下文对RAG而言并不总是最优解:大多数模型的性能在某个上下文长度后会下降。值得注意的是,Llama-3.1-405b的性能在32k词元后开始下降,GPT-4-0125-preview在64k词元后开始下降,只有少数模型能够在所有数据集上维持一致的长上下文RAG性能。
- 模型在长上下文RAG任务中失败的方式都各不相同:我们深入分析了DBRX和Mixtral的长上下文性能,并识别出了各自独特的失败模式,例如由于版权问题拒绝或总是对上下文进行总结。许多行为表明,缺乏足够的长上下文后训练。
在这篇博客中,我们对OpenAI o1-preview、o1-mini和Google Gemini 1.5 Pro及Gemini 1.5 Flash进行了相同的分析。有关我们数据集、方法论和实验细节的完整描述,请参见(LLM的长上下文RAG性能,https://www.databricks.com/blog/long-context-rag-performance-llms)
2
OpenAI o1:长上下文RAG中的新SOTA模型
新的SOTA模型:OpenAI o1-preview和o1-mini模型在我们的三项长上下文RAG基准测试中超越了所有其他模型,o1-mini的结果与GPT-4o相近。GPT-4o-mini上的性能提升十分惊人,因为新发布的"mini"版本比上次发布的最强模型更优秀。
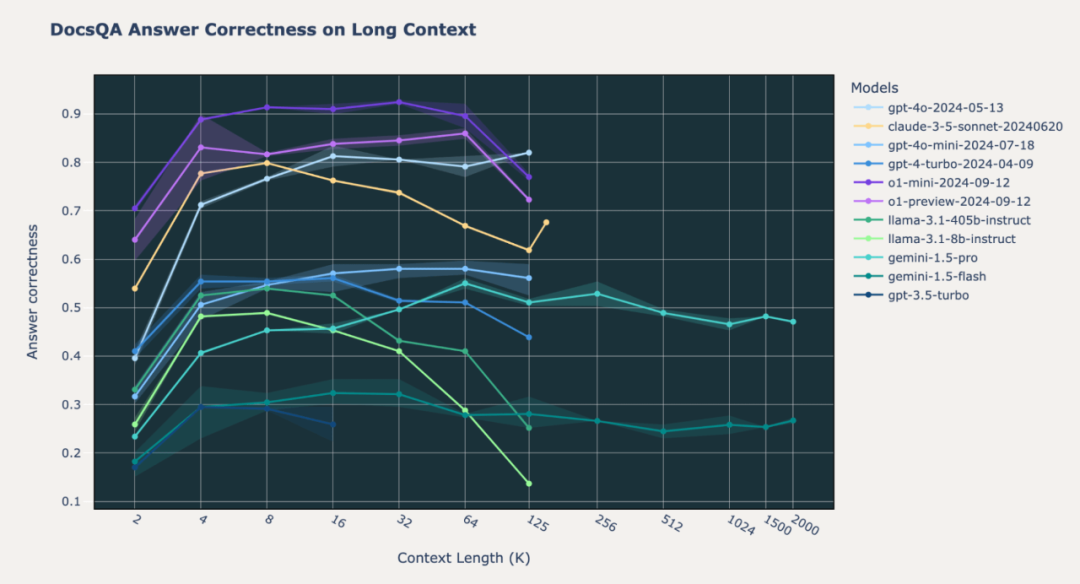
图2.1:在Databricks DocsQA内部* 数据集上,SOTA模型的长上下文RAG性能*
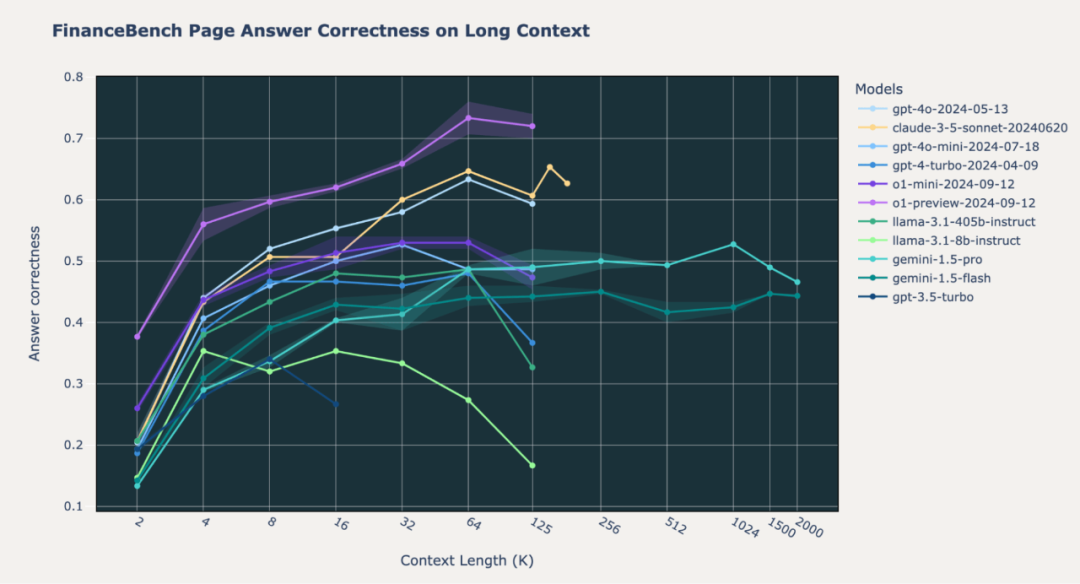
*图2.2:*在内部FinanceBench数据集上,SOTA模型的长上下文RAG性能
我们注意到,在基准测试中o1模型的行为存在差异。在我们的内部Databricks DocsQA和FinanceBench数据集上,o1-preview和o1-mini模型在所有上下文长度下的表现显著优于GPT-4o和Gemini模型。这种情况在Natural Questions (NQ)数据集上基本成立;然而,我们注意到o1-preview和o1-mini模型在短上下文长度(2k词元)上的性能不佳。我们将在后文探讨这一奇怪现象。
3
Gemini 1.5模型在最高200万词元下保持一致的RAG性能
尽管Google Gemini 1.5 Pro和Gemini 1.5 Flash模型在128000 tokens以下的整体答案正确性远低于o1和GPT-4o模型,但Gemini模型在超长上下文(最高可达200万词元)下保持了一致的性能。
在Databricks DocsQA和FinanceBench上,Gemini 1.5模型的表现不及OpenAI o1、GPT4o-mini和Anthropic Claude-3.5-Sonnet。然而,在NQ上,所有这些模型的表现相对较为优异,答案正确性值始终高于0.8。大多数情况下,相比其他模型,Gemini 1.5模型在其最大上下文长度结束时不会出现性能下降。
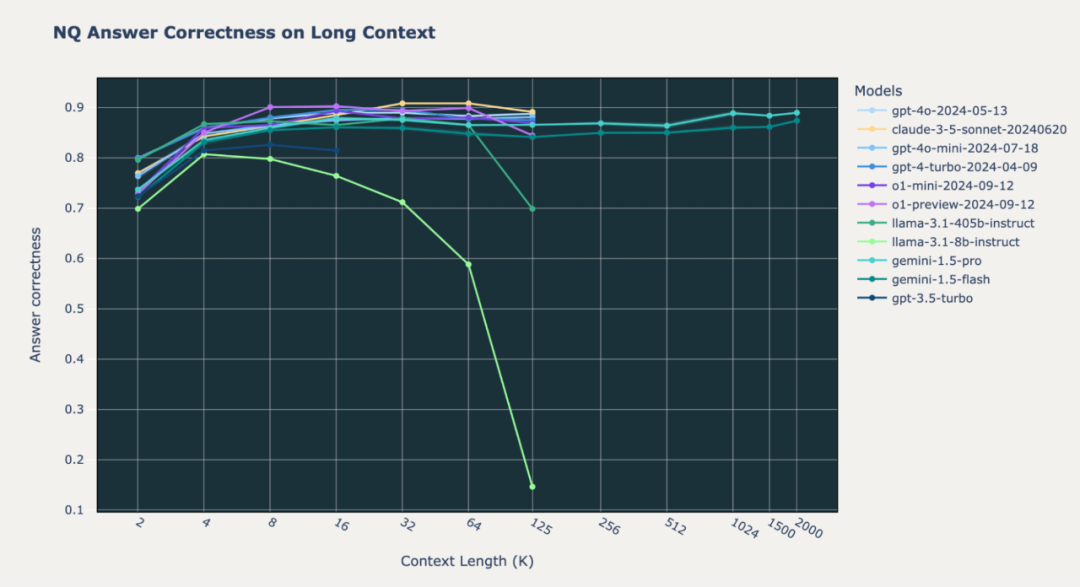
图2.1:在Natural Questions (NQ) 数据集上,SOTA模型的长上下文RAG性能
这些结果表明,对于小于200万词元的语料库,可以在RAG流水线中跳过检索步骤,而直接将整个数据集输入到Gemini模型中。尽管这样做可能会相当昂贵且性能较低,但可以为开发者提供更简化的开发体验,在构建LLM应用时以更高的成本换取开发的便捷性。
4
LLM在长上下文RAG中的不同失败模式
为评估生成模型在处理长上下文长度时的失败模式,我们对OpenAI的o1和Gemini 1.5 Pro进行了分析,使用了与我们之前博文相同的方法(https://www.databricks.com/blog/long-context-rag-performance-llms)。我们提取了各个模型在不同上下文长度下的回答,并手动检查了多个样本,基于观察结果定义了以下广泛的失误类别:
- 重复内容(repeated_content):当模型的回答完全由重复的(无意义的)单词或字符组成。
- 随机内容(random_content):当模型生成的回答完全随机,与上下文无关,或者没有逻辑性或语法合理性。
- 未遵循指令(fail_follow_inst):当模型未理解指令的意图或未遵循问题中指定的指令。例如,当指令要求基于上下文回答问题时,模型却尝试总结上下文。
- 空响应(empty_resp):生成的回答为空
- 错误答案(wrong_answer):当模型尝试遵循指令,但给出的回答错误。
- 其他(others): 失误不属于上述列出的任何类别。
我们还增加了两个新类别,因为这些失误在Gemini模型中尤为普遍:
- 拒绝回答(refusal):模型拒绝回答问题,表明答案无法在上下文中找到,或表明上下文与问题无关。
- 因API过滤导致的任务失败: 由于API的严格过滤规则,模型API直接阻止了该提示内容的生成。如果任务因API过滤失败,我们不会将其计入最终的答案正确率计算中。
我们为每个类别设计了对应的描述性提示,并使用GPT-4o对模型的所有失败例子进行了分类。此外需要注意,这些失败模式在其他数据集上可能并不具备代表性;在不同的生成设置和提示模板下,失败模式也可能会有所不同。
o1-preview和o1-mini的失败分析
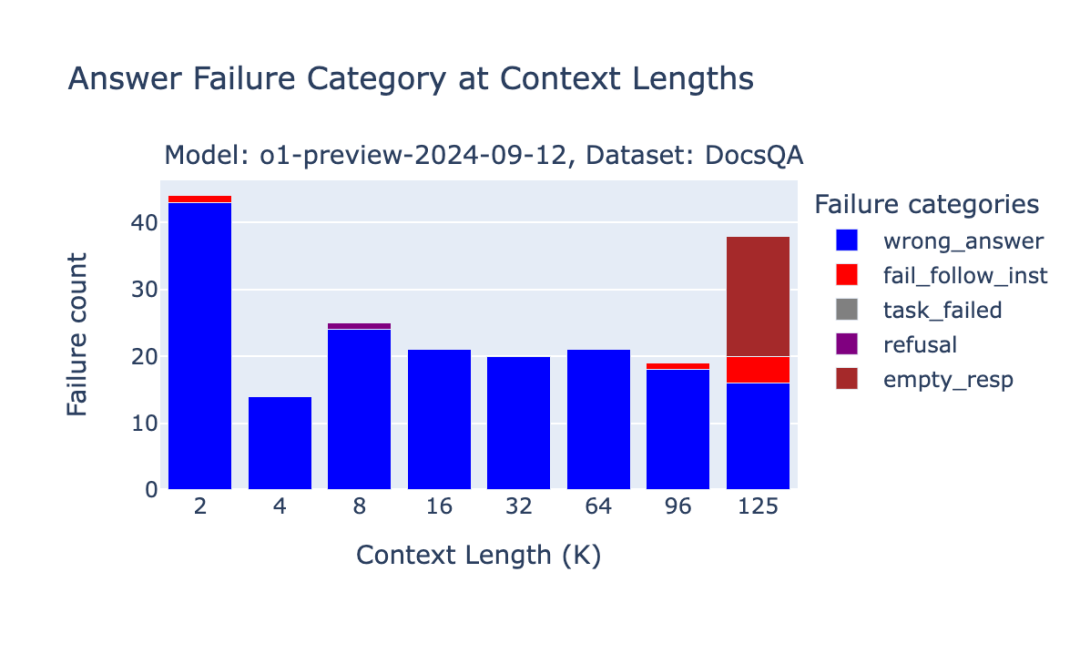
图3.1:OpenAI o1-preview在Databricks DocsQA基准测试中的失败分析
虽然OpenAI的o1-preview和o1-mini在我们的基准测试中排名靠前,但我们仍然注意到一些由于上下文长度导致的独特失败例子。由于o1模型中推理步骤的词元长度难以预测,当提示内容因中间的"推理"步骤而增长时,OpenAI并不会直接使请求失败,而是返回一个空字符串的响应。
o1模型在NQ上的行为变化
尽管在Databricks DocsQA和FinanceBench数据集上的表现有所提升,我们观察到o1-preview和o1-mini模型在NQ数据集的短篇幅上下文情境中的性能下降。在短篇幅上下文情境中,如果检索到的文档中没有相关信息,o1模型更可能简单地回答"信息不可用"(我们的提示内容中包含了一个指令:"如果没有相关段落,请使用你的知识回答问题")。
我们还注意到,在一些样本中,即便有oracle文档提供支持,o1模型依然未能提供正确答案。对于这样一个强大的模型来说,这样的性能回退令人意外。
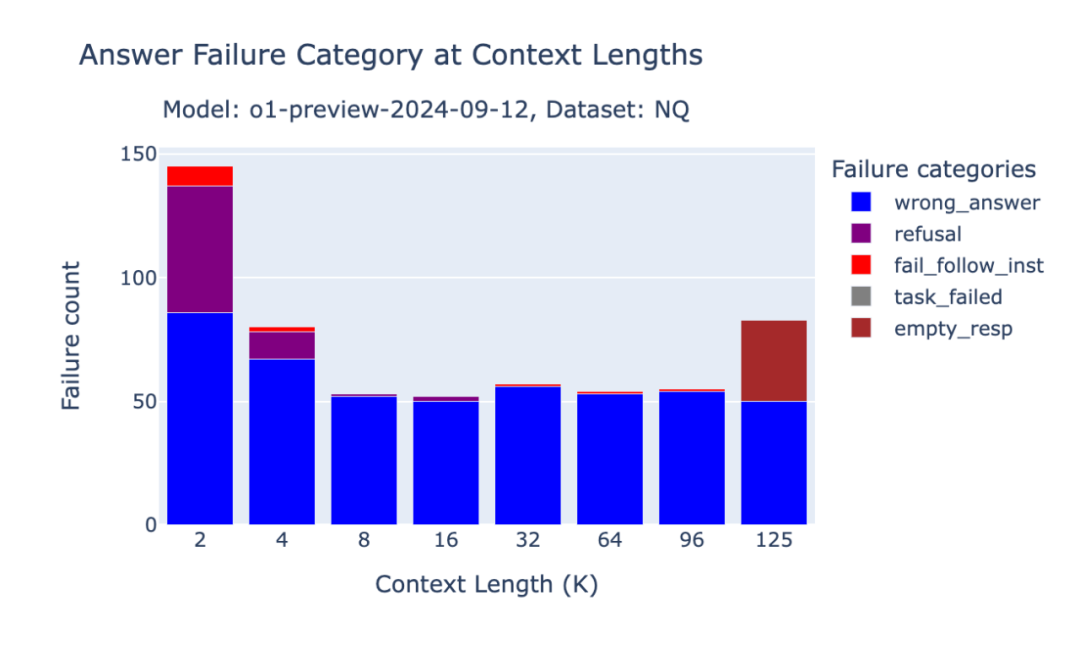
图3.2:OpenAI o1-preview在Natural Questions基准测试中的失败分析
在下面的示例中,在没有oracle文档的情况下,o1拒绝回答问题,而GPT-4o则基于其自身知识给出了答案:

在下一个示例中,即便检索到了oracle文档,o1-preview仍未能回答该问题:

Gemini 1.5 Pro和Flash的失败分析
下方的柱状图展示了Gemini 1.5 Pro和Gemini 1.5 Flash在FinanceBench、Databricks DocsQA和NQ数据集上的失败分布情况。
Gemini的生成API对提示内容的主题非常敏感。在NQ基准测试中,由于提示内容被过滤,任务失败的情况很多。这令人意外,因为NQ是一个标准的学术基准测试数据集,其他API模型均成功进行了评估。因此我们发现,Gemini的一部分性能下降仅仅是因为安全过滤!不过,需要注意的是,我们决定不将因API过滤导致的任务失败计入最终的准确率计算。
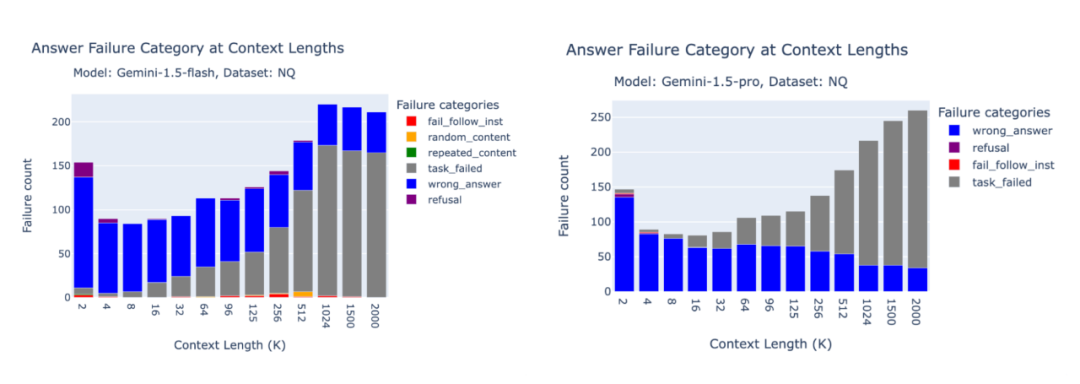
图3.3:Gemini 1.5 Pro和Flash在NQ基准测试中的失败分析。请注意,task_failed并不计入最终的准确率。
以下是来自Google Gemini API的BlockedPromptException错误示例:

在FinanceBench基准测试中,Gemini 1.5 Pro的很大一部分错误是由于"拒绝回答",即模型要么拒绝回答问题,要么提到无法在上下文中找到答案。这种情况在短篇幅上下文情境中更为明显,因为OpenAI的text-embedding-3-large检索器可能未能检索到正确的文档。特别是在2k上下文长度下,96.2%的"拒绝"情况发生在oracle文档缺失时。准确率在4k、8k和16k上下文长度下分别为89%、87%和77%。
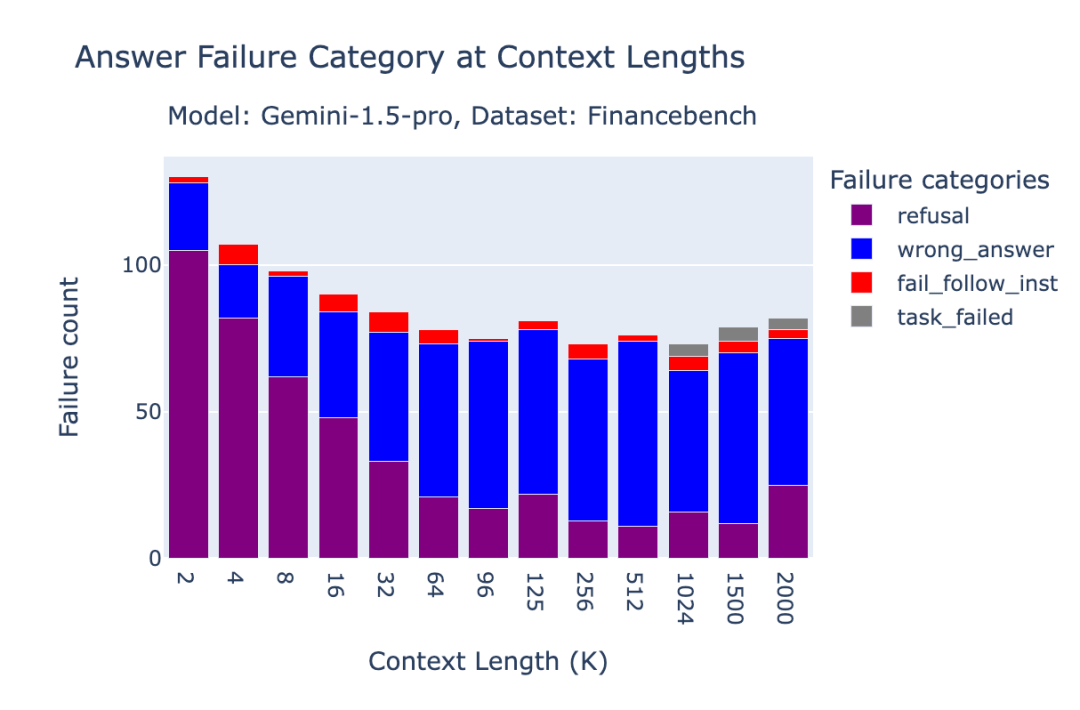
图3.4:Gemini 1.5 Pro在FinanceBench基准测试中的失败分析
在Databricks DocsQA数据集中,大部分错误都是由于回答错误导致的。
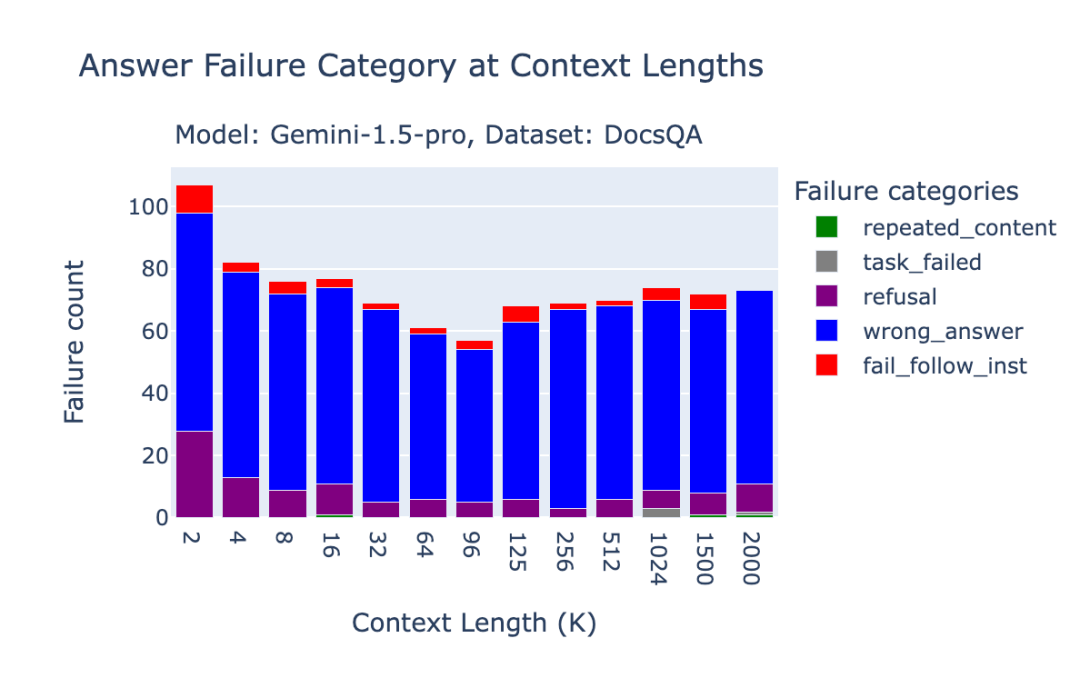
图3.5:Gemini 1.5 Pro在Databricks DocsQA基准测试中的失败分析
5
结论
我们很高兴看到OpenAI o1模型表现出色;如其他报道所述,o1模型似乎比GPT-4和GPT-4o有实质性提升。此外,我们还惊讶地发现Gemini 1.5模型在上下文长度达200万词元时依然保持一致的性能,尽管整体的准确率较低。我们希望我们的基准测试能够为构建RAG工作流的开发人员和企业提供参考。
强大的基准测试和评估工具对于开发复杂的AI系统至关重要。为此,Databricks Mosaic AI Research致力于分享评估研究(例如,校准Mosaic评估测试套件)以及产品,如Mosaic AI Agent Framework和Agent Evaluation,帮助开发者成功构建先进的AI产品。
6
附录
长上下文RAG性能表:
通过将这些RAG任务结合起来,我们得到了以下表格,展示了模型在上述4个数据集上的平均表现。该表与图1中的数据相同。
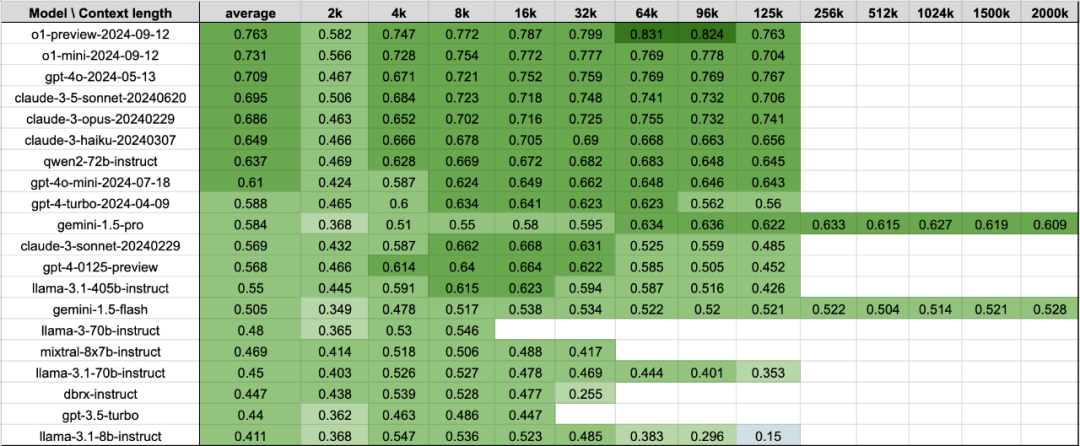
表1:每个上下文长度下3个RAG数据集的平均表现。数据与图1相同。
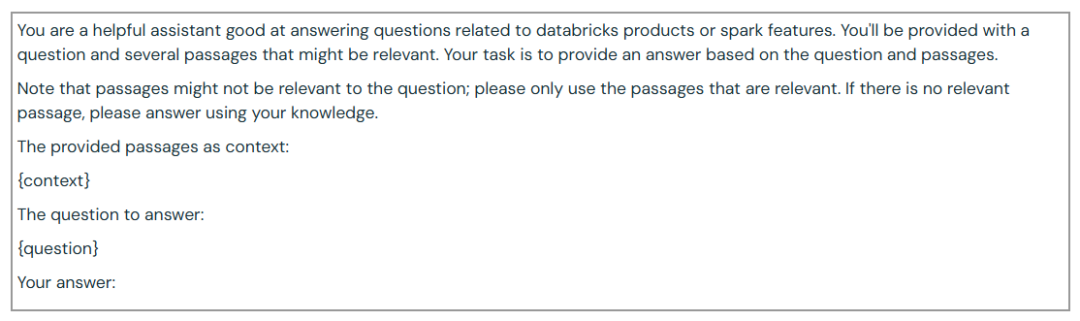
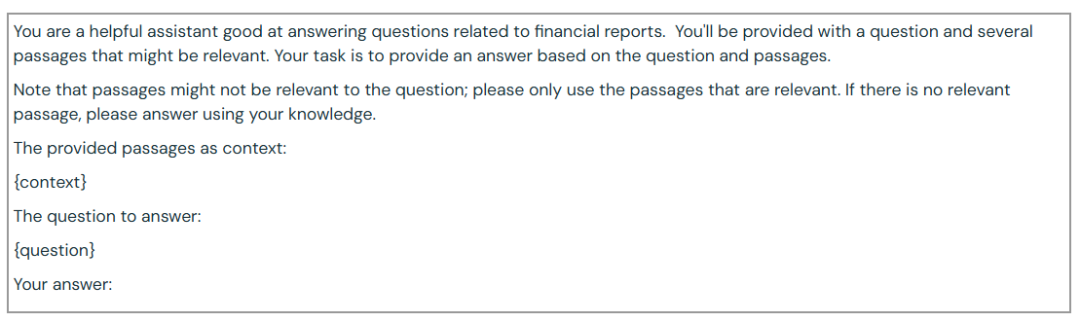
提示模板:
我们使用了以下提示模板(与我们之前的博文中的相同):
Databricks DocsQA:
FinanceBench:
NQ:

其他人都在看
让超级产品开发者实现"Token自由"
邀请好友体验SiliconCloud, 狂送2000万Token/人
邀请越多,Token奖励越多
siliconflow.cn/zh-cn/siliconcloud