在之前精读了这个多模态的OCR项目论文,理解了其基本的模型架构,论文精读地址:
【论文精读】GOT-OCR2.0源码论文------打破传统OCR流程的多模态视觉-语言大模型架构:预训练VitDet 视觉模型+ 阿里通义千问Qwen语言模型-CSDN博客
本文在阅读论文基础上,根据官方指南安装配置其项目源码环境的过程,并且记录实际安装中可能会出现的问题及如何解决。最后在安装好的环境中,测试官方训练的模型在挑选的一些图片中的OCR效果。
在测试过程中,其通用性表现在传统OCR可能需要多个模型分别进行文字、数字、公式等功能实现,OCR2.0一个模型就够了。更令人惊奇的是,OCR2.0不仅可以提取图像中已有的文本内容,甚至可以分析图表得到"思考"后的文本信息------详见测试章节(三.2.③章节)
目录
一、环境安装
Github项目源码地址给出的安装方式是先使用Git克隆项目,本文因为网络等问题暂且不使用这种方式,直接去下载源码zip包解压到自己的项目文件处。
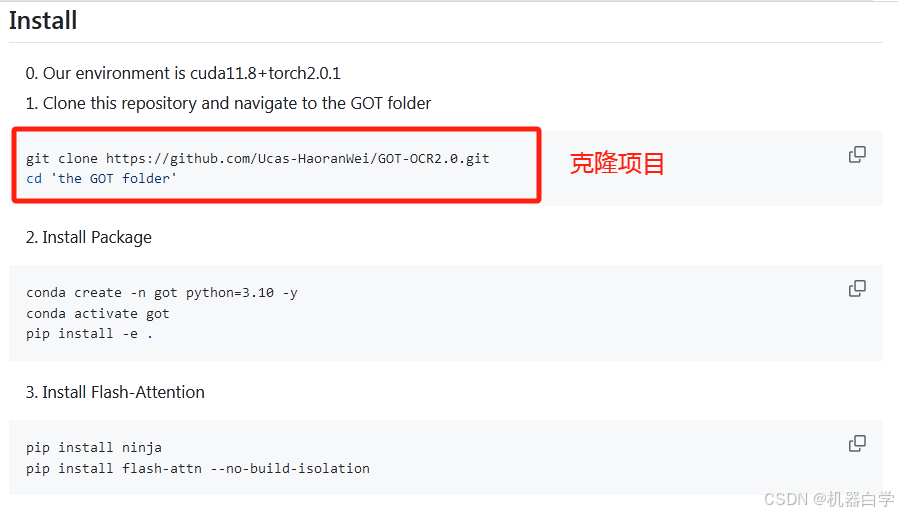
1.GOT-OCR源码下载
Github地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.0
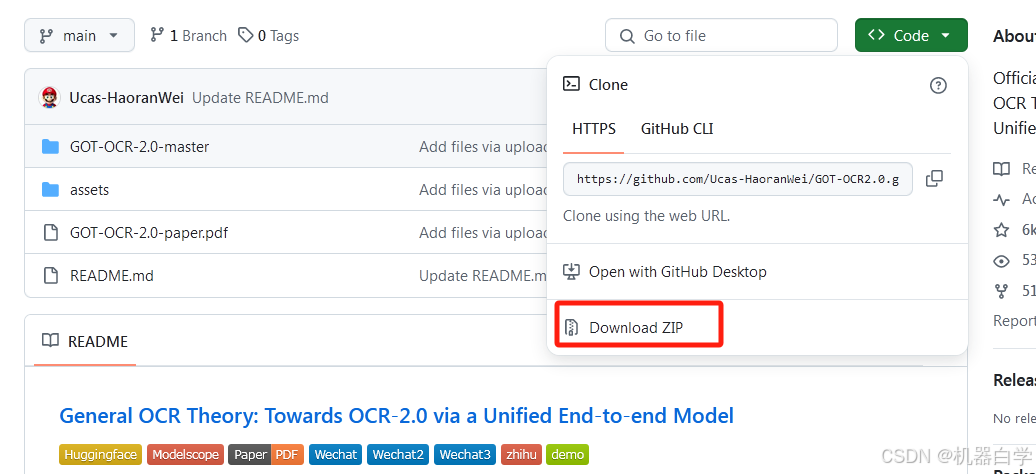
解压完成后,GOT-OCR-2.0-master下是主运行程序源码,可以使用Pychram创建下面进入。不使用Pycharm也要在命令行进入这个目录下进行安装。PDF文件是这个开源项目的论文。
python
# 进入主程序目录下进行安装环境操作
cd GOT-OCR2.0-main\GOT-OCR-2.0-master
2.虚拟环境与Torch安装
老规矩,首先创建虚拟环境和安装必要的 torch 环境。
根据安装指南中的记录,作者使用的是cuda11.8和torch2.0.1版本,我们也安装相同。
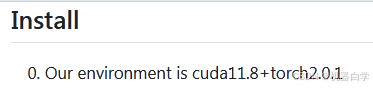
python
# 创建虚拟环境
conda create -n got python=3.10 -y
# 激活
conda activate got
# 安装对应torch
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
3.GOT依赖包安装
在之前下载好的源码处,进入GOT-OCR-2.0-master这个主运行程序目录,可以看到目录下有一个pyproject.toml 文件,按照官方指南使用pip安装命令,就会根据这个文件安装所需的依赖包,并在环境中创建一个GOT环境库。
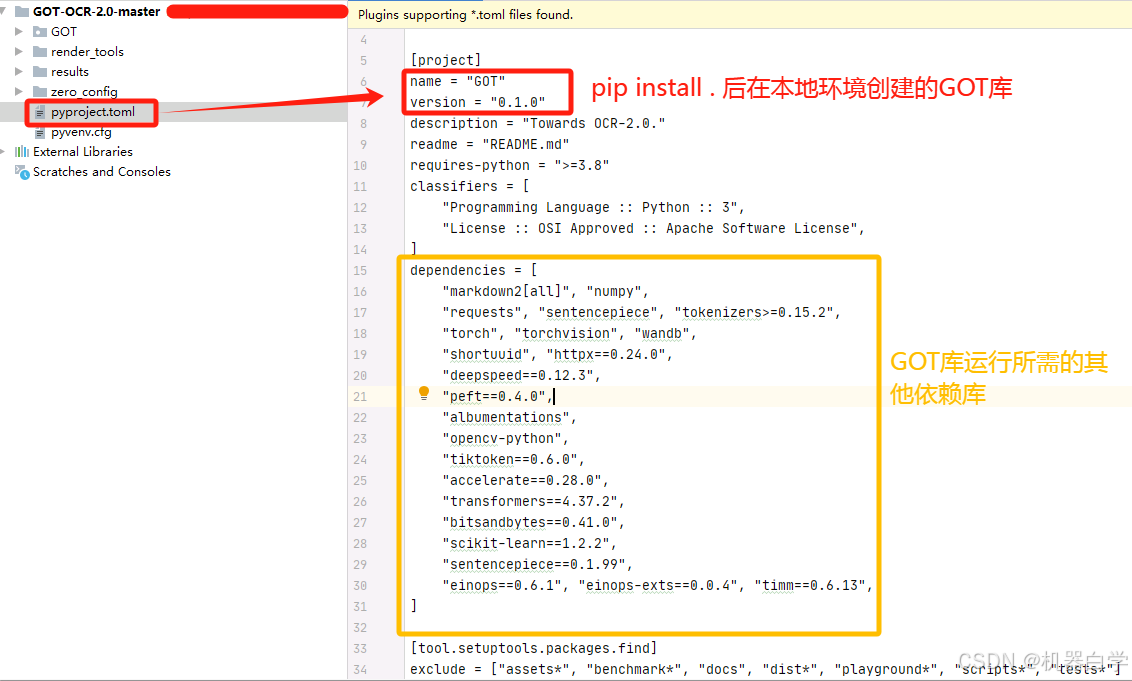
下面开始按照官方指南pip安装GOT库。
pip install . 安装方式是在当前目录下寻找setup.py 文件或 pyproject.toml文件进行安装,-e表示是编辑开发模式,目录处的代码变化也会影响安装的包环境。
这种安装方式需要确保cd到对应pyproject.toml文件目录,在下载的源码里,其目录在GOT-OCR-2.0-master下。
python
# 导航到pyproject.toml处
cd GOT-OCR-2.0-master
# 开发模式安装相关包
pip install -e .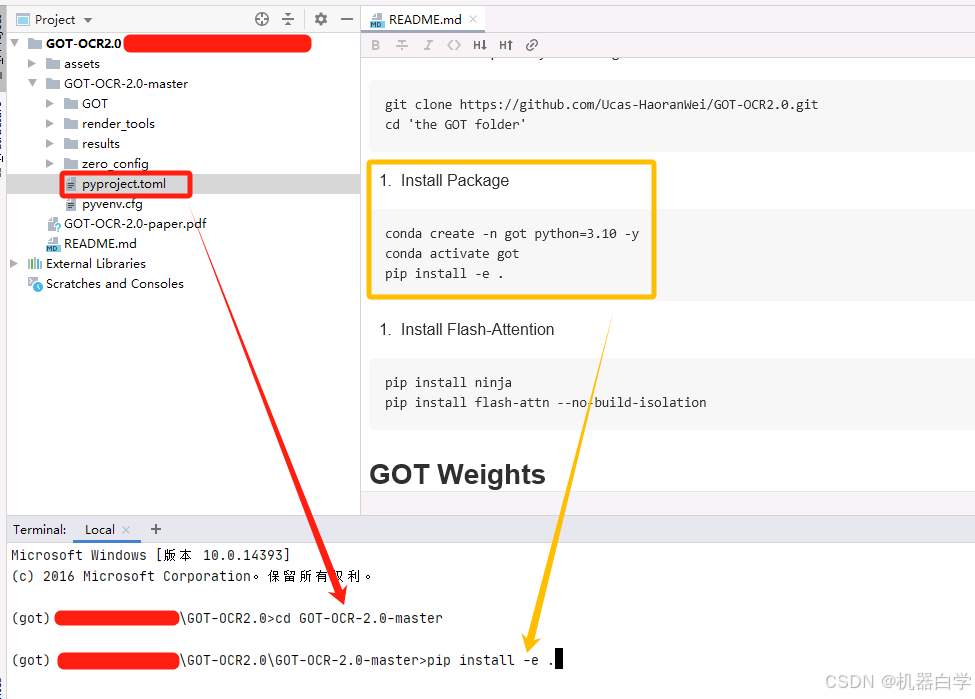
在安装GOT 依赖包中的 deepspeed==0.12.3 似乎会报错。
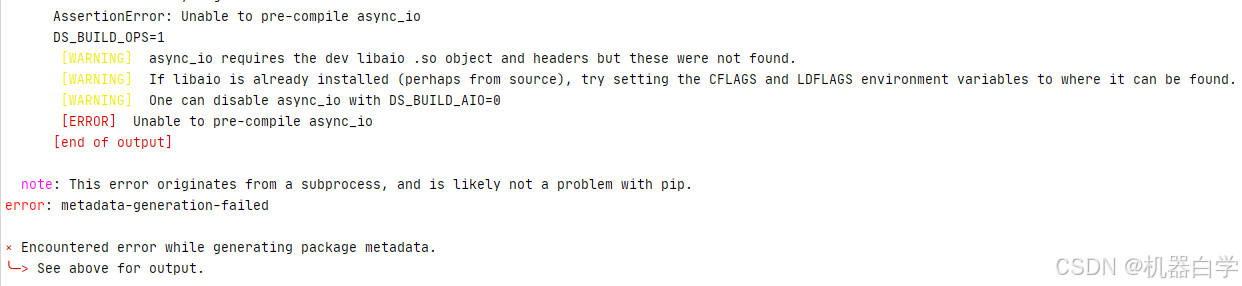
查询网上其他博文安装都比较复杂,实验了一下使用whl包可以成功安装。
deepspeed的whl地址 :https://github.com/melMass/DeepSpeed/releases/tag/v0.14.3
安装方法和过程如下。先去上述官方的Github项目地址下下载其发布的whl包到本地。(没有找到默认要求里的deepspeed==0.12.3版本,安装了其最新的版本0.14.3,后续使用没有报错)
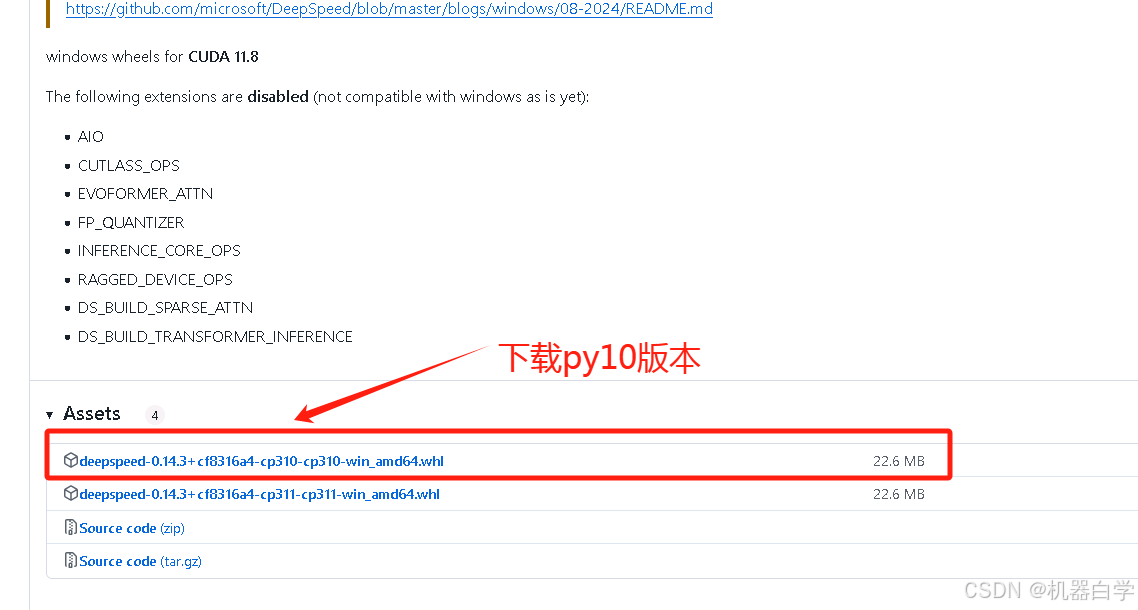
然后将安装包 .whl 放到环境的 Scripts 下,进入环境pip安装即可。
python
# 安装whl包
pip install deepspeed-0.14.3+cf8316a4-cp310-cp310-win_amd64.whl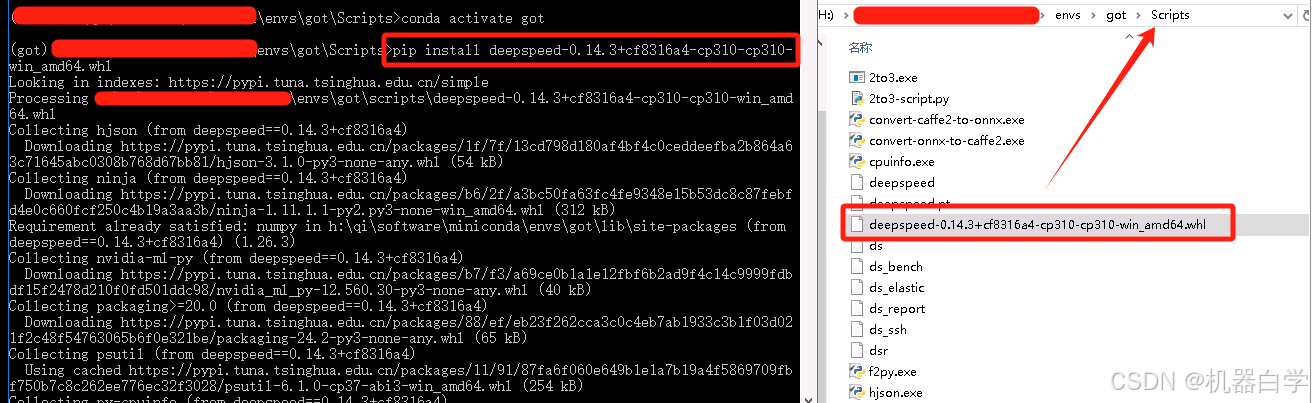
 (注意) 安装完后,还要修改pyproject.toml 文件中的安装deepspeed版本设置(默认版本的没有在官方下找到对应whl包),再返回进行pip install -e . 才能安装成功。
(注意) 安装完后,还要修改pyproject.toml 文件中的安装deepspeed版本设置(默认版本的没有在官方下找到对应whl包),再返回进行pip install -e . 才能安装成功。
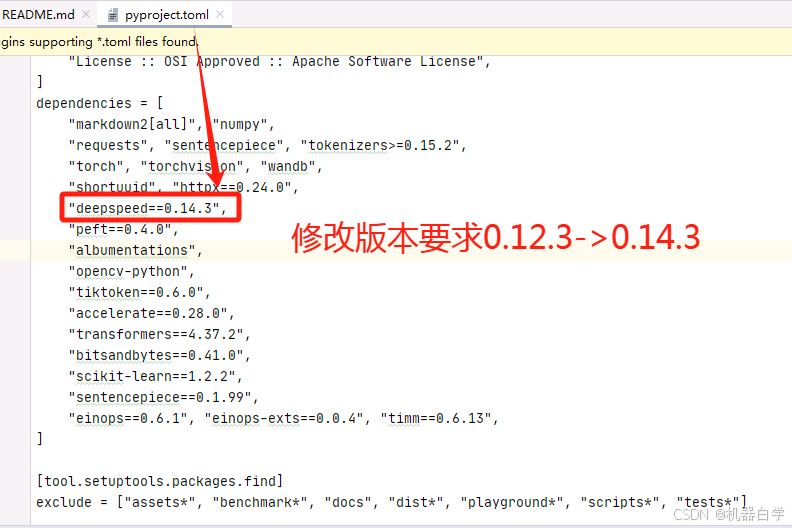
最后看到打印下面这个就可以开一半的香槟了!安装GOT库算是完成了。

可以pip list 打印看一下现在安装好的库都有哪些。

二、模型参数下载
官方指南给了三种模型参数下载方式。

但建议最好用huggingface的国内镜像源,下载快速便捷,
模型在镜像源地址如下:https://hf-mirror.com/stepfun-ai/GOT-OCR2_0
模型参数偏大------model.safetensors,约1.5G,需耐心下载。
等所有下载好了,在GOT 源码主程序目录GOT-OCR-2.0-master 下新建一个GOT_weights文件夹,用于存放下载内容,到时候指令使用模型的时候只需指定到这个新建地址即可。
至此,环境配置部分基本完成,可以开香槟庆祝一下了。下面安装官方指南给出的命令指令规则测试一下在实际图片上的OCR表现效果。
三、官方模型参数实验
下面来测试一下GOT-OCR2.0强大的 "通用型" OCR能力。
推理设备要求,至少需要 6G 以上显存的GPU设备,如果是使用cuda推理的话。
1.测试报错处理
实验中可能会出现一些运行报错,将报错和解决方案记录在下。
通过官方指令可以看到,实际运行的是源码主程序GOT-OCR-2.0-master 目录GOT/demo下的py文件。
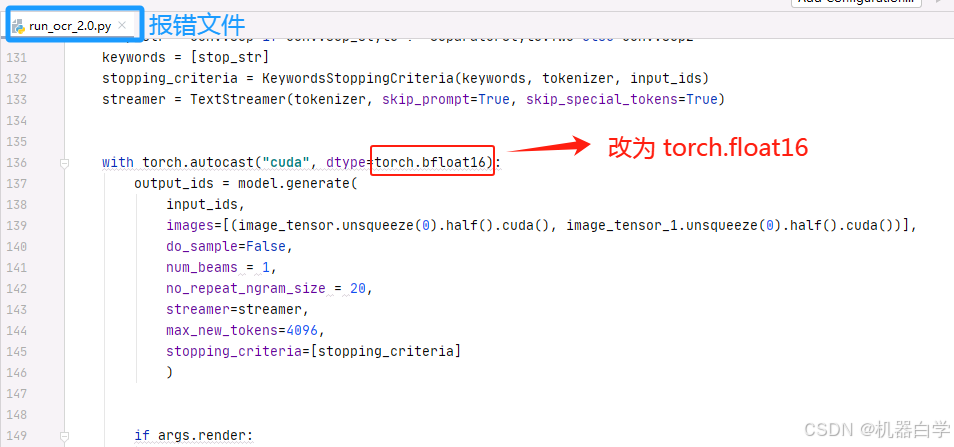
下面这个报错是因为cuda的软件版本和GPU的硬件不支持最新的 bfloat16 数据结构------(好像只有最新的H100、A100等高端性能服务级显卡在数据架构上支持这一格式)

这个只需修改对应报错地方的数据格式,改为 float16 即可,从报错信息可以看到在136行。
2.从测试数据内容出发
找了几种不同类型的文本内容进行测试,这些在传统OCR流程中可能对应不同的任务模式,需要单独构建模型。这部分是测试OCR2.0模型的"通用性"
本部分同用一个命令,即**--type ocr**,这个模式下仅识别文本内容并打印出ocr结果
python
python GOT/demo/run_ocr_2.0.py --model-name "model_path" --image-file "img_path" --type ocr①中英混搭文本
需要注意命令行中的地址可能需要使用绝对地址路径,比如--model-name 后的模型地址最好使用本地带在哪个盘的绝对地址路径。
python
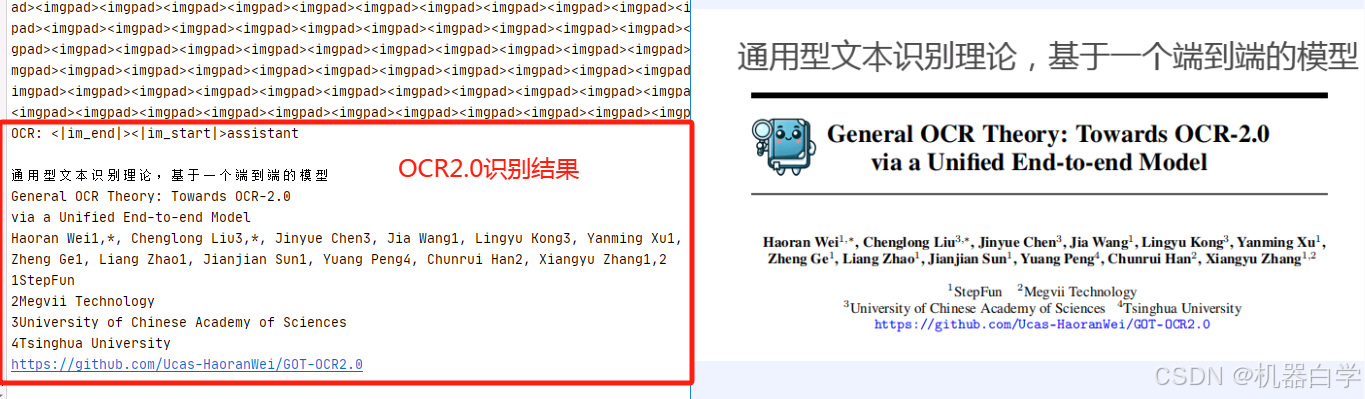
python GOT/demo/run_ocr_2.0.py --model-name \GOT-OCR2.0-main\GOT-OCR-2.0-master\GOT_weights\ --image-file \GOT-OCR2.0-main\GOT-OCR-2.0-master\test\jpg\test1.jpg --type ocr下面是识别结果打印(默认情况是只打印文本),可以看到是没什么问题,效果很好的。
而且不管是论文标准字体(英文部分),还是添加的中文注释,识别准确度都很高,也没有漏检,连人名上的小数字也识别在内(体现了视觉VitDet的局部识别能力)
②表格及公式
下面仍按上述模型识别方式,只是改变图片输入,可以看到对于图表格式数据,识别效果依然挺好,几乎都正确。下图没有展示完整识别结果,就单行对应基本准确,具体内容在后续format模式的可视化效果展示中可以清晰看到。
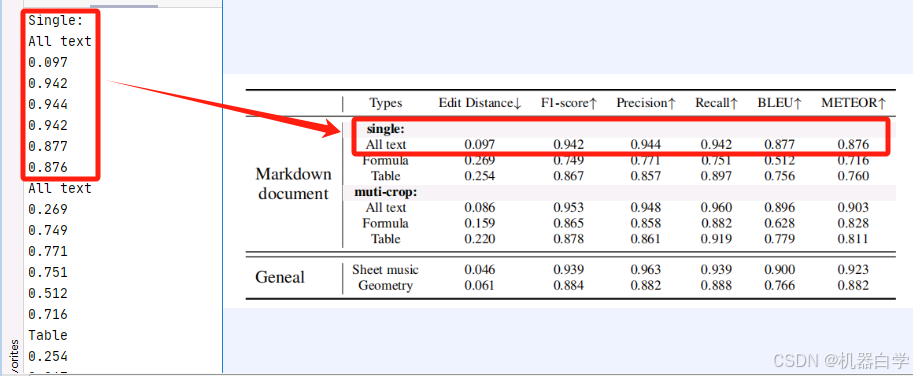
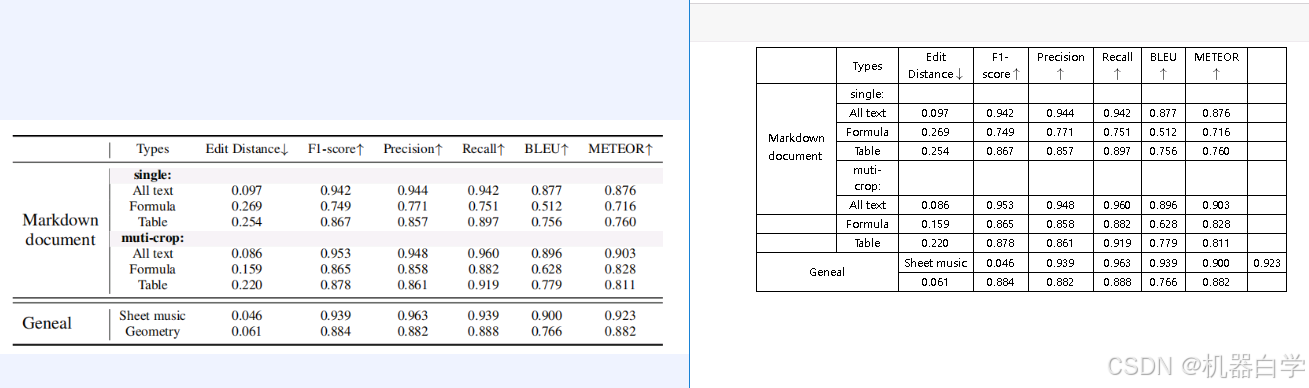
更令人振奋的是,其对于图表中的公式内容也可以提取识别出来,虽然部分其可能只是视为英文字符,但是一些特殊的数学符号(如)其也能识别出来,说明其具有一定的读取数学符号能力的。
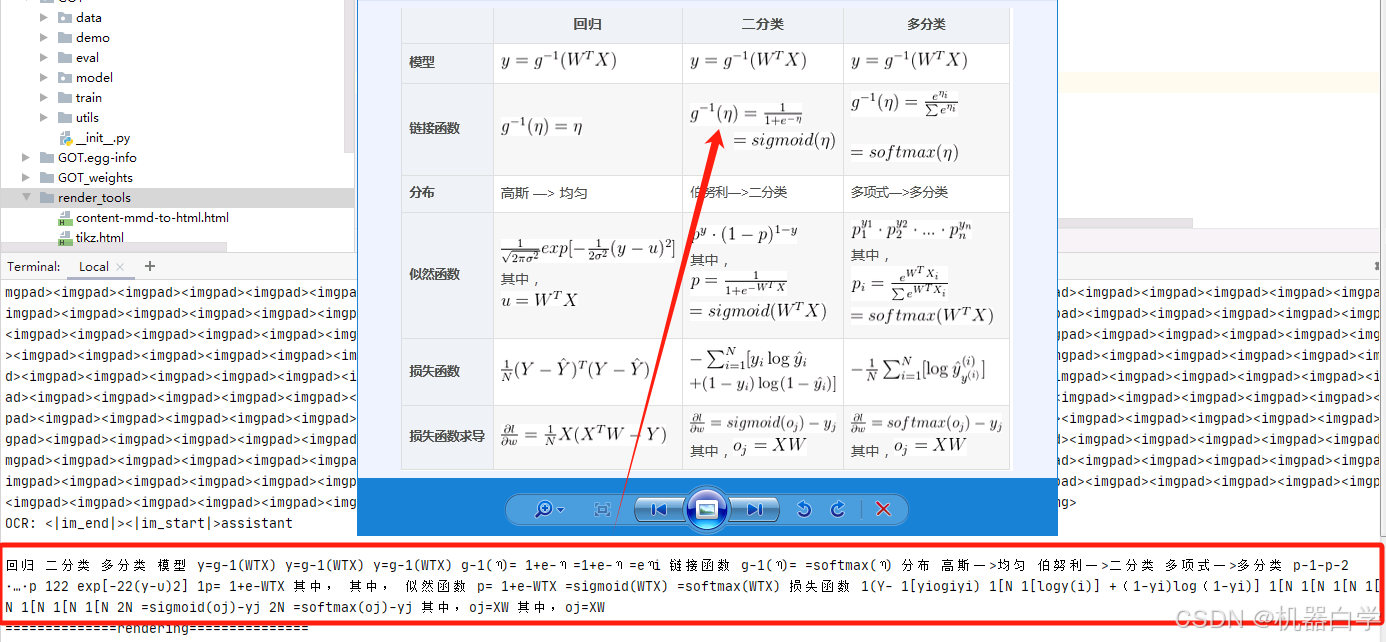
经过可视化渲染可以更加清晰看到起结果。左侧是图片,右侧则是可以复制粘贴的OCR文本数据。足以看到其强大功能。
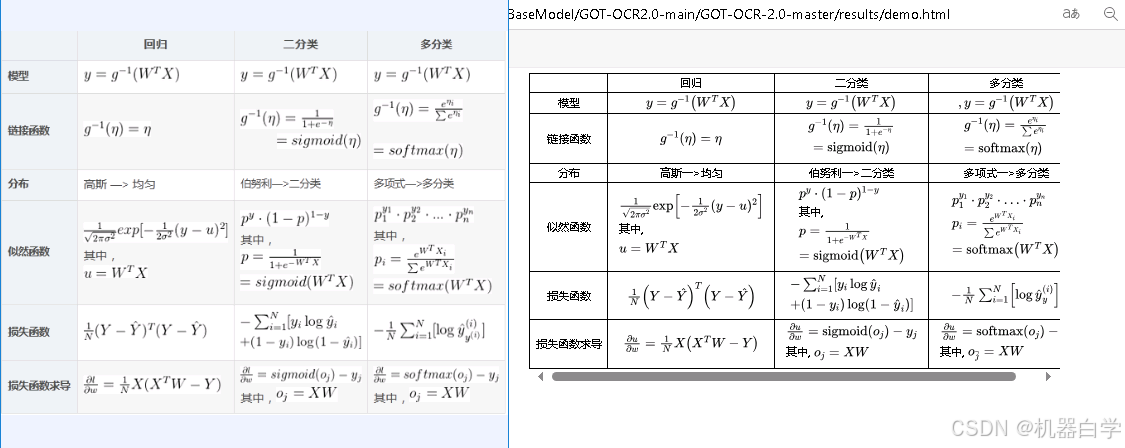
③化学符图表形状
本部分指令代码要参考之后章节,要使用--render保存渲染结果。直接展示结果。左侧是原图,右侧是OCR识别结果经过渲染后的html可视化结果。
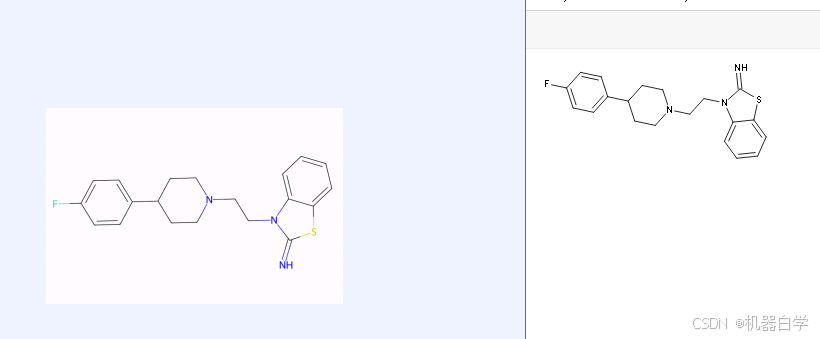
另外一个令人震惊的是其图表识别能力 ,其语言模型似乎继承了LVLMs的一定能力,可以理解图片的数轴和颜色?在本例图中,就红色柱状图对应Ann的Mon类中,图中并没有标注815数值,但模型仅通过读取图片查询数轴相对位置,就得到了一个精准近似结果,这是传统OCR不敢相信的。
④繁体中文
在测试中也发现,官方训练集可能缺乏对繁体中文的数据,繁体字的识别效果没有那么好,但是也能识别出部分常见字。
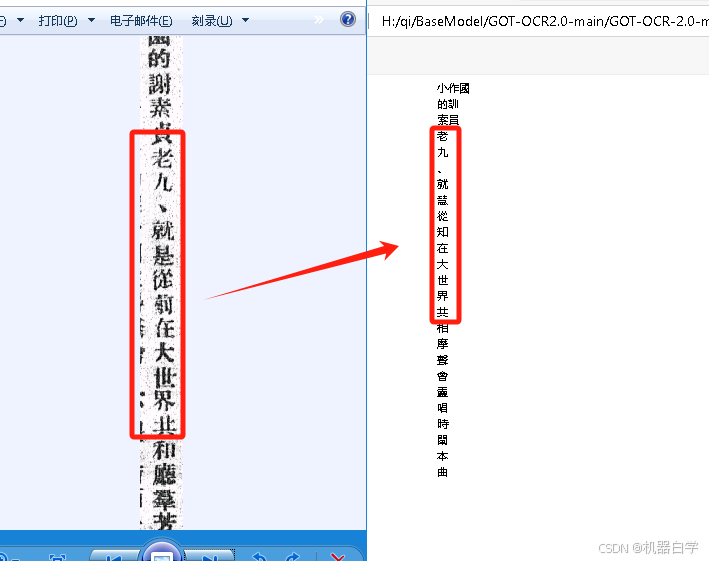
3.从识别模式出发
①Format可视化模式
在上部分使用了正常的ocr打印结果,这部分使用其format,并在最后加--render即可实现可视化,可视化结果保存在项目文件 result/demo.html 文件内,直接浏览器打开就可以看到最终渲染效果了。
指令命令如下,也是最好使用绝对地址。
python
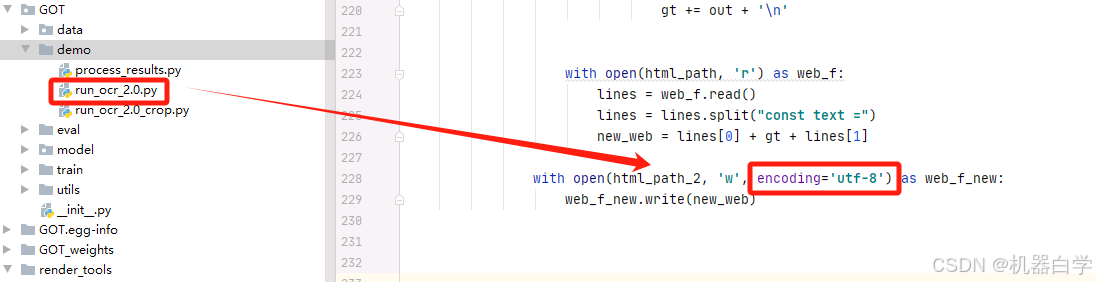
python GOT/demo/run_ocr_2.0.py --model-name "model_path" --image-file "img_path" --type format --render本部分模式可视化中,还有一些源码简单修改。为了防止在最后可视化的中文变成乱码结果,需要在其运行保存写入html文件处加上编码格式。在GOT/demo/run_ocr2.0.py 文件的228行处, 加一个encoding='utf-8' 即可。
效果如下。 可以看到对于表格数据来说还是不错的。

②兴趣区域识别模式
模型还支持兴趣区域识别ocr,原文指出这对于点读笔来说有使用价值,具体来说可以根据区域在原图中的位置框,或者用特殊颜色进行涂色的区域进行单独识别。
其指令代码如下,受精力限制,本部分的实验在之后有时间再进行。
python
# 根据区域坐标
python GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format/ocr --box [x1,y1,x2,y2]
# 根据区域颜色
python GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format/ocr --color red/green/blue③高分辨率切图识别模式
由于模型训练采用的1024*1024的图像,超过这个比例的高清图识别效率不高(测试图片均小于这个值),因此对于高清大尺寸图,作者采用切分识别然后整合的处理方法。
指令如下,注意如果也出现第一部分报错提醒,也要修改run_ocr_2.0_crop.py对应部分。
python
# 高清大图切分处理
python GOT/demo/run_ocr_2.0_crop.py --model-name /GOT_weights/ --image-file /an/image/file.png 结语
至此GOT-OCR2.0的环境安装和一些基本测试完结,在后续将构建起微调训练的数据集格式,并进行微调训练和从头训练的测试记录。敬请期待,谢谢。