文章目录
概述
在 2017 年 4 月发布 Unsupervised Sentiment Neuron 算法的文章《》中指出,"真正好的预测与理解有关",以及"仅仅被训练用于预测下一个字符之后,神经网络自动学会了分析情感" 。
尽管训练出的这个系统初始只是为了能够预测亚马逊评论文本中的下一个字符,而让人惊讶的是,该系统中还出现了意料之外的「情感神经元(sentiment neuron)」,其囊括了几乎所有的情感信号。
这篇文章在当时没有受到太多关注甚至被 ICLR 2018 拒稿,但分析认为,这个研究成果对 OpenAI 后续的研究产生了深远的影响,也为下一阶段 OpenAI all-in GPT 路线打下了基础。
- 本文所涉及的所有资源的获取方式:https://www.aspiringcode.com/content?id=100000000011\&uid=5ee8b38087fc4c27b83f4780542a7152
演示效果
下图表示情感神经元的逐字符值,消极值为红色、积极值为绿色。 请注意,像"最好的"或"可怕"这样强烈的指示性词语会引起颜色的特别大变化。

有趣的是,在完成句子和短语之后,系统仍会进行大量更新。 比如说"And about 99.8 percent of that got lost in the film"这个句子,即使"in the film"本身没有表达情感,系统还是在前面的"lost"之后、以及在句子结束后,将情感值向更消极的方向进行了更新。
核心逻辑
> 方法论
OpenAI首先在8200万亚马逊评论的语料库上用4,096个单位训练了multiplicative LSTM,以预测一小段文本中的下一个字。 训练在四个NVIDIA Pascal GPU上进行,花费了一个月,模型处理速度为每秒12,500个字符。
这4,096个单位(只是浮标的向量)可以被认为是表示模型读取的字符串的特征向量。 在训练mLSTM后,OpenAI通过采用这些单位的线性组合将模型转换为情感分类器,通过可用的监督数据学习组合的权重。

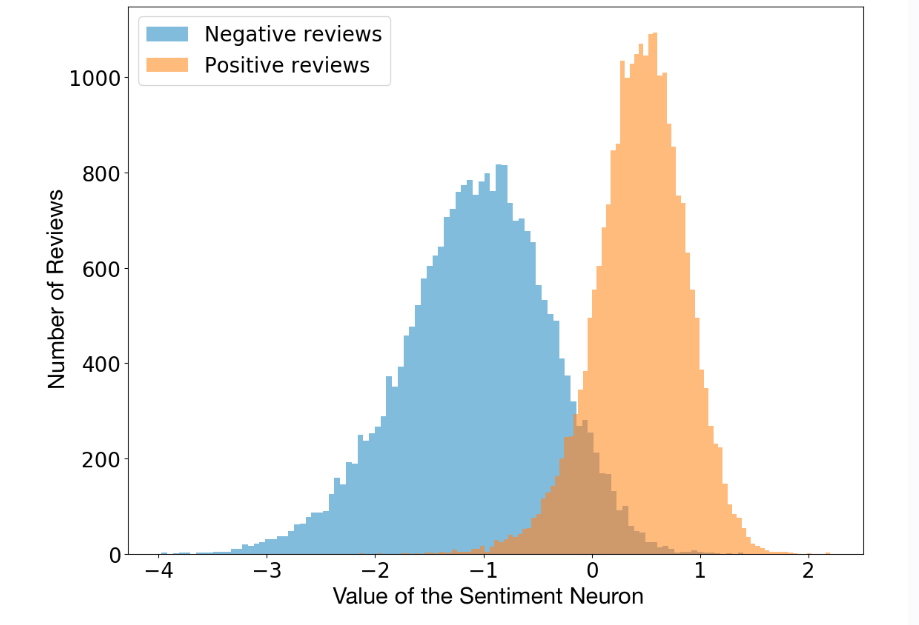
哇!确实有一个单一的特征权重很大。一定是情感神经元。事实上,我们甚至可以得到它在 4096 个神经元列表中的索引。如果你看一下结果,你会发现它的索引是2388。还有其他一些神经元的贡献相对较高。
> 情感神经元 OpenAI这项研究还有一个独特的"情感神经元",包含几乎所有的情感信号。
在用L1正则化训练线性模型的同时,研究人员注意到,它只用了很少的已学习单位。挖掘其原因的时候发现,实际上存在着一个对情感值有高度预测性的"情感神经元"。
> 无监督学习 目前,标签数据是机器学习的燃料。 收集数据很容易,但对数据进行可扩展的标注很难。只有在机器翻译,语音识别或自动驾驶这样的重要问题上,生成标签才能得到相应的回报。
开发无监督学习算法,学习数据集的良好表征,仅用少量标注数据解决问题,一直以来都是机器学习研究人员的梦想。
OpenAI的研究表明,在创建具有良好表征学习能力的系统时,简单地用大量数据训练一个大型的无监督下雨不预测模型,可能是一种很好的方法。
使用方式
1、输入文本,输出预测情绪
# start
from encoder import Model
import numpy as np
model = Model()
text = ['I do not like you!','I can not love you any more!','I couldn't figure out how to put this book down.']
text_features = model.transform(text)
sentiment_scores = text_features[:, 2388]
print("情绪值:", sentiment_scores)2、输入基础开头文本,加上情绪值,加上目标文字数,输出带情绪的一段话
from encoder import Model
mdl = Model()
base = "I couldn't figure out"
print("\'%s\'... --> (argmax sampling):" % base)
positive = mdl.generate_sequence(base, override={2388 : 1.0})
negative = mdl.generate_sequence(base, override={2388 : -1.5}, len_add = 100)这是当要求以"嗯"开头时生成的内容。
Hmm what a waste of film not to mention a Marilyn movie for nothing.嗯,那还不错!
有趣的部分是通过固定情感神经元的值来生成样本。以下是一些生成的示例。
情绪= 1.0 且起始短语= "This is" =>
This is a great album with a quality history of the group.情绪= -1.0 且起始短语="可能"=>
It might have been good but I found myself skipping pages to get to the end.情绪 = -1.0 =>
I can't believe I bought this book.很高兴生成的短语连贯、像人类一样并且也符合预期的情绪。
也就是说,有时生成的文本与情绪并不完全相符。
情绪 = -1.0且起始短语="很棒"=>
Great DVD with the original production leaving good video and audio quality.关于生成的有趣之处在于,它也可以被视为获得单个神经元直觉的一种方式。因此,我尝试通过固定其他重要神经元的值来生成文本。例如,将神经元 801 的值固定为 -1.0 生成此文本。
This is the greatest movie ever! Ever since my parents had watched it back in the 80s, I always watched it.它(神经元 801)与情绪似乎有一些相关性。
修复不同的值(甚至多个值在一起)并查看生成的文本是一个有趣的练习。
- 本文所涉及的所有资源的获取方式:https://www.aspiringcode.com/content?id=100000000011\&uid=5ee8b38087fc4c27b83f4780542a7152
部署方式
- dockerfile