一、介绍
VideoCrafter是一个功能强大的AI视频编辑和生成工具,它结合了深度学习和机器学习技术,为用户提供了便捷的视频制作和编辑体验。
系统:Ubuntu22.04系统,显卡:4090,显存:24G
二、基础环境
1.查看系统是否有Miniconda3的虚拟环境
conda -V如果输入命令没有显示Conda版本号,则需要安装。
安装教程可查看:

2.更新系统命令
输入下列命令将系统更新及系统缺失命令下载
apt-get update
apt-get upgrade
apt-get install -y vim wget unzip lsof net-tools openssh-server git git-lfs gcc cmake build-essential3.创建虚拟Python环境
-
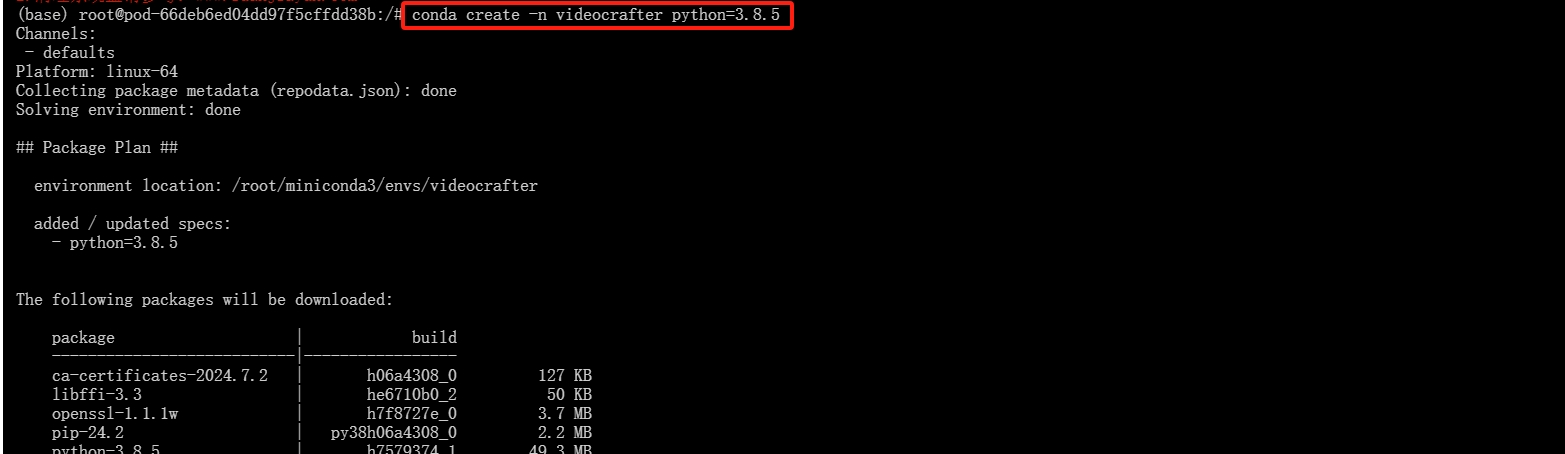
创建一个名为"videocrafter"的虚拟镜像,python版本为3.8.5
conda create -n videocrafter python=3.8.5
-
进入"videocrafter"虚拟环境
conda activate videocrafter

4.下载模型
输入下列命令对videocrafter模型进行下载
git clone https://gitclone.com/github.com/AILab-CVC/VideoCrafter.gitls
cd VideoCrafter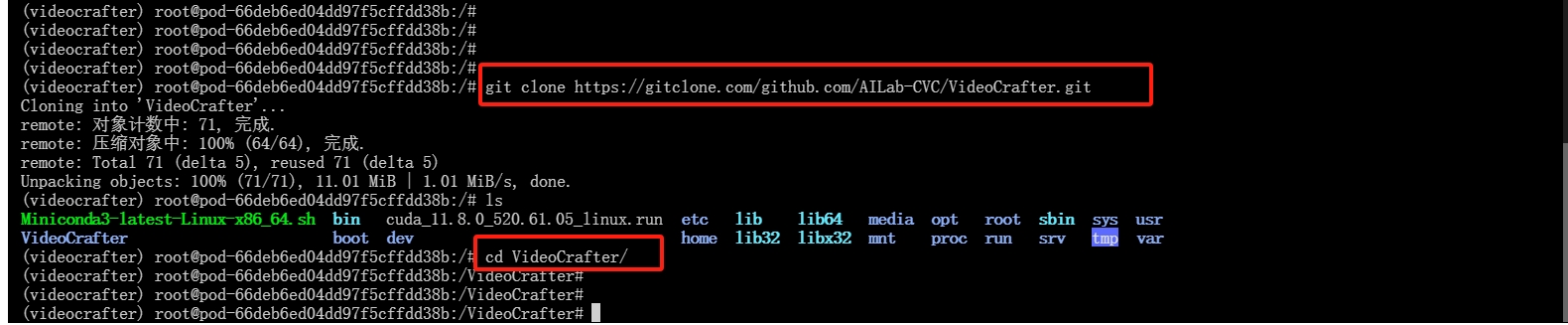
5.下载模型依赖包
输入下列命令:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple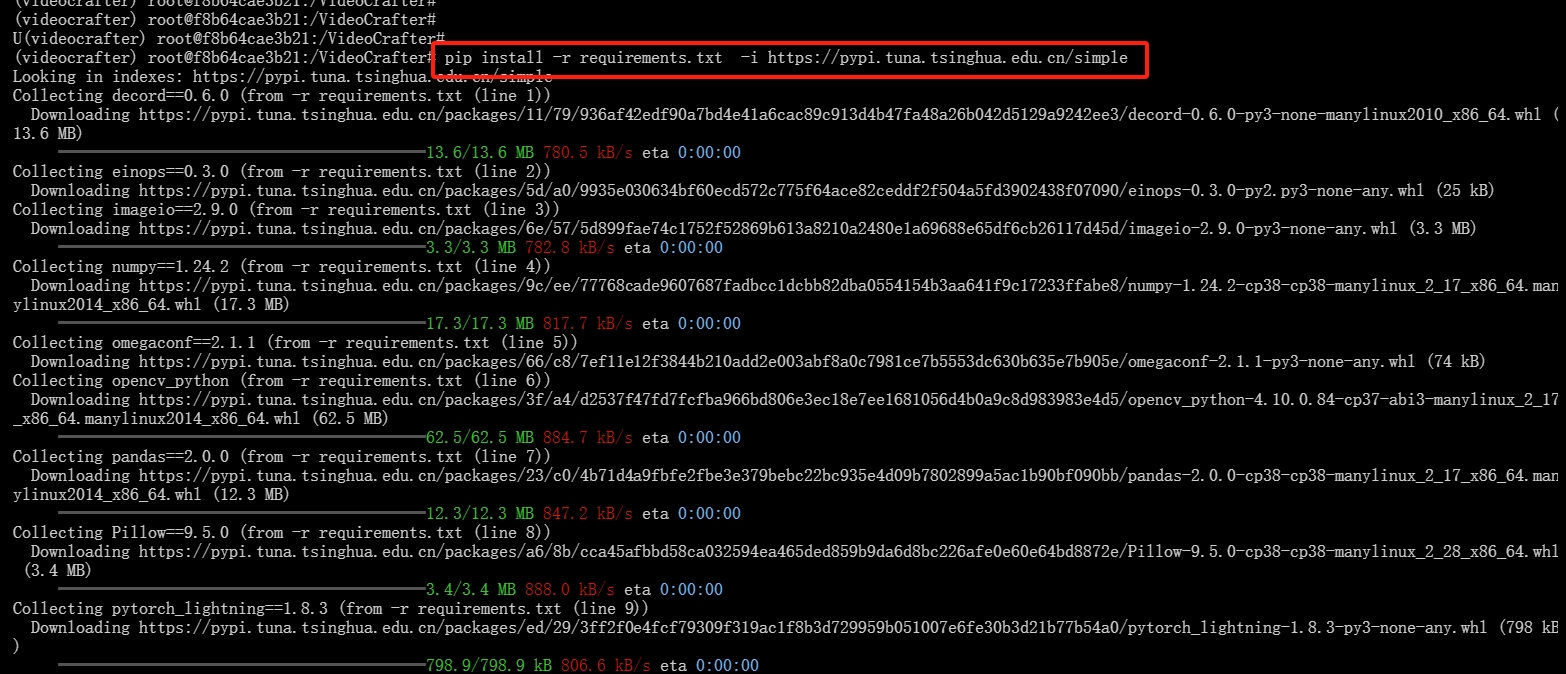
出现报错:
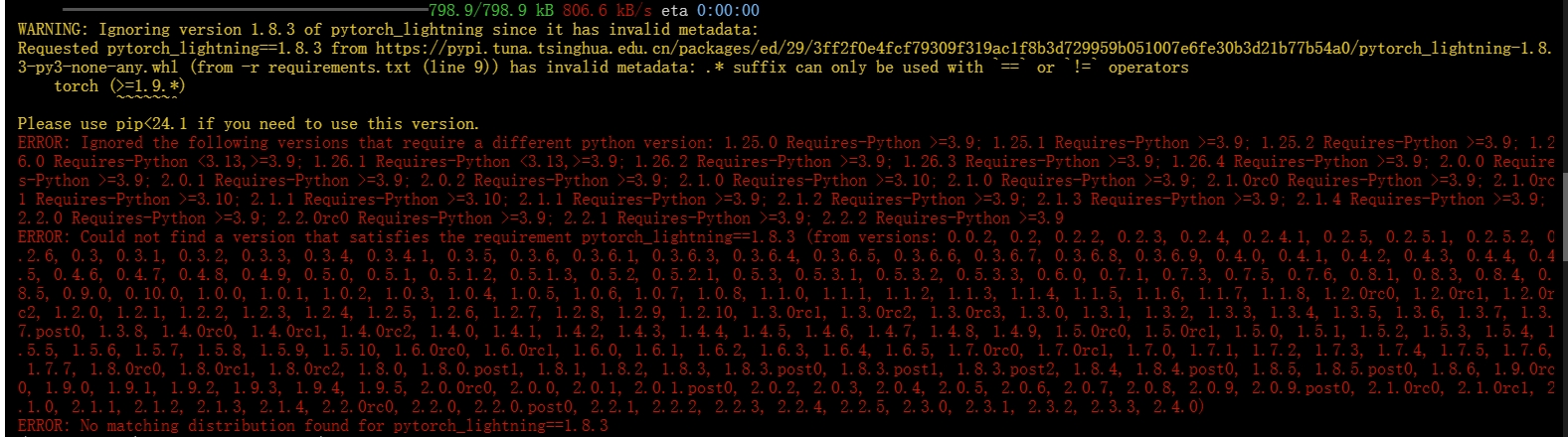
进入requirements.txt文档中将pytorch_lightning的版本号删除
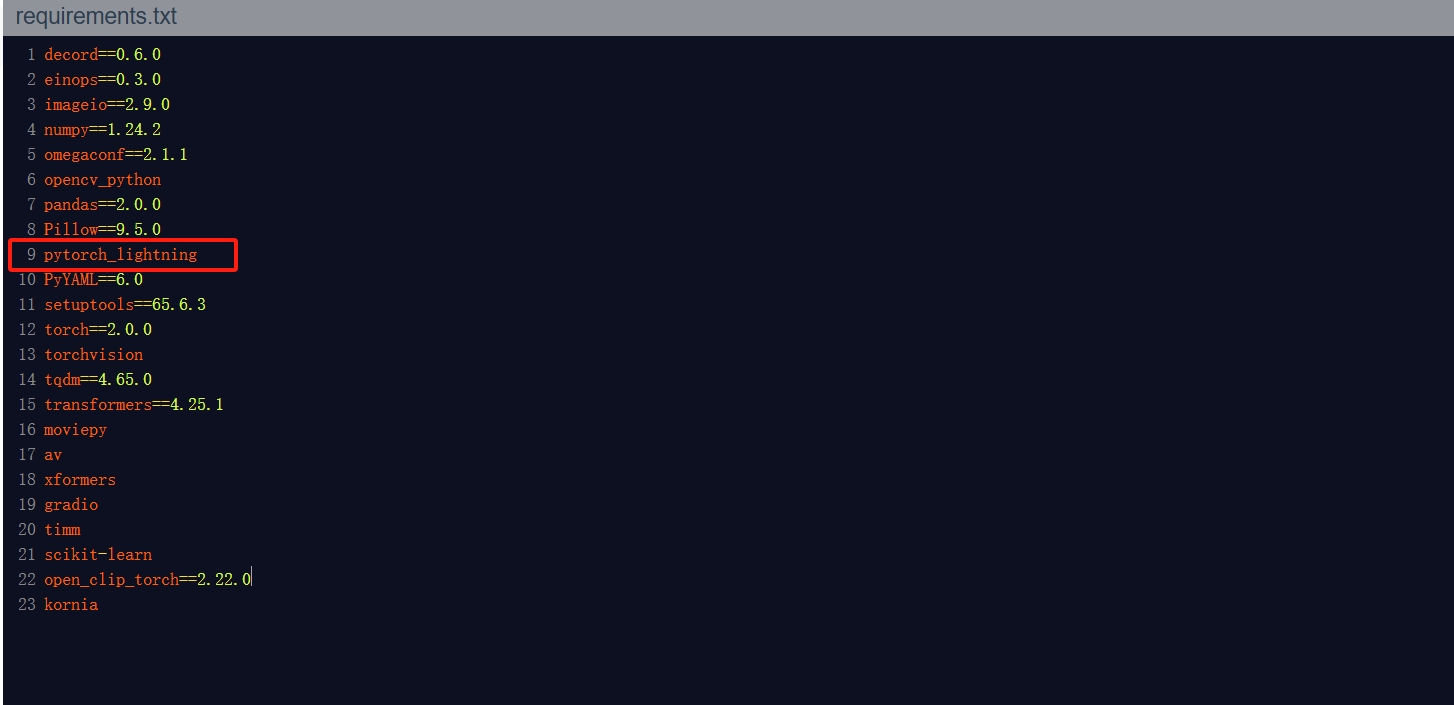
重新运行下载命令:
问题解决

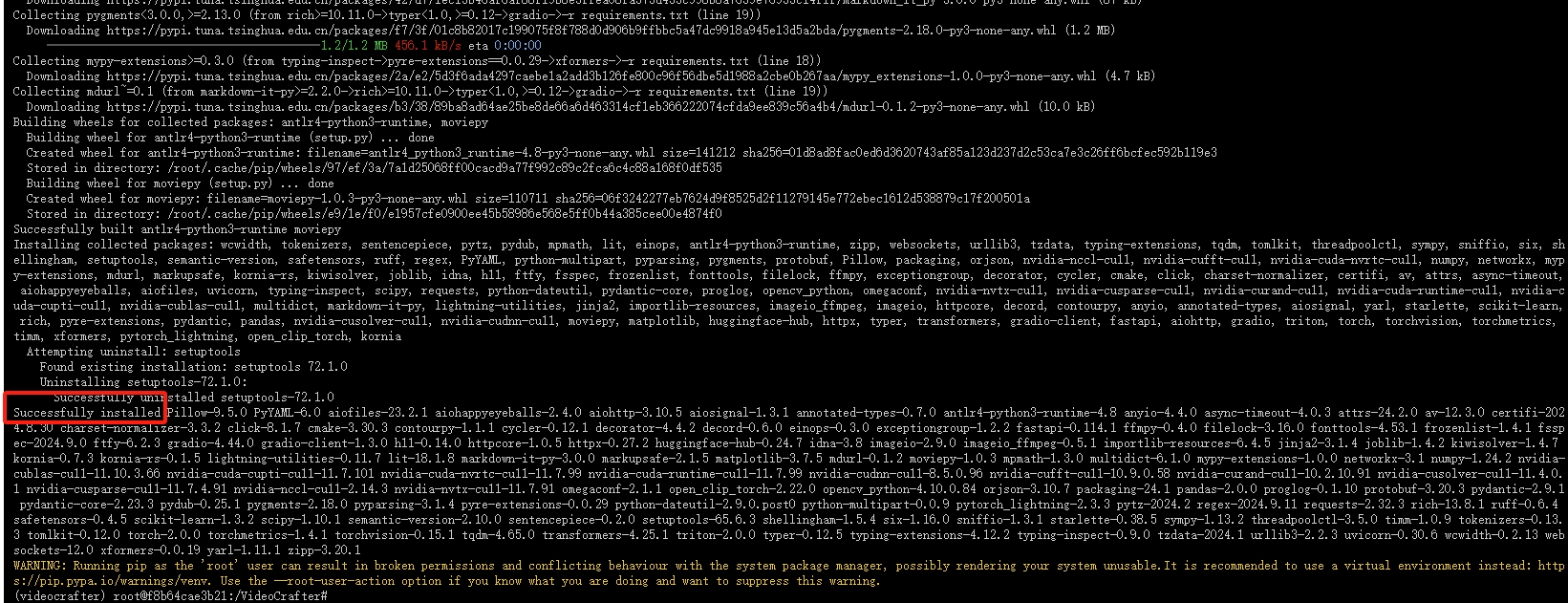
耐心等待直到"Successfully"出现:
6.添加模型文件
运行下列命令:
sh scripts/run_text2video.sh
按照错误提示安装checkpoints/base_1024_v1/model.ckpt
创建checkpoints文件夹
mkdir checkpoints
cd checkpoints
下载模型文件:
git lfs install
git clone https://hf-mirror.com/VideoCrafter/Text2Video-1024
三、web界面展示
输入下列命令启动界面:
python gradio_app.py
复制网址打开页面
