文章目录
- 前言
- [MapReduce 基本流程概述](#MapReduce 基本流程概述)
- [MapReduce 三个核心阶段详解](#MapReduce 三个核心阶段详解)
-
- [Map 阶段](#Map 阶段)
- [Shuffle 阶段](#Shuffle 阶段)
-
- 具体步骤
-
- 分区(Partition)
- 排序(Sort)
- [分组(Combine 和 Grouping)](#分组(Combine 和 Grouping))
- [Reduce 阶段](#Reduce 阶段)
- [MapReduce 应用场景](#MapReduce 应用场景)
- [MapReduce Java 实战](#MapReduce Java 实战)
- 个人简介
前言
- Hadoop 是一个开源的分布式计算框架,专为处理大规模数据而设计。它最初由 Apache 软件基金会开发,能够以经济高效的方式在分布式集群上存储和处理海量数据。Hadoop 的核心组件包括分布式存储(HDFS)和分布式计算(MapReduce),以及一套支持工具。
- 本文将重点探讨
分布式计算(MapReduce), Hadoop MapReduce 是一种分布式计算模型,旨在处理大规模数据集。它通过将任务分解为多个子任务并在分布式集群中并行执行,极大地提高了数据处理效率。本文将详细剖析 MapReduce 的三个核心阶段:Map 阶段、Shuffle 阶段 和 Reduce 阶段,帮助您深入理解其工作机制。
MapReduce 基本流程概述
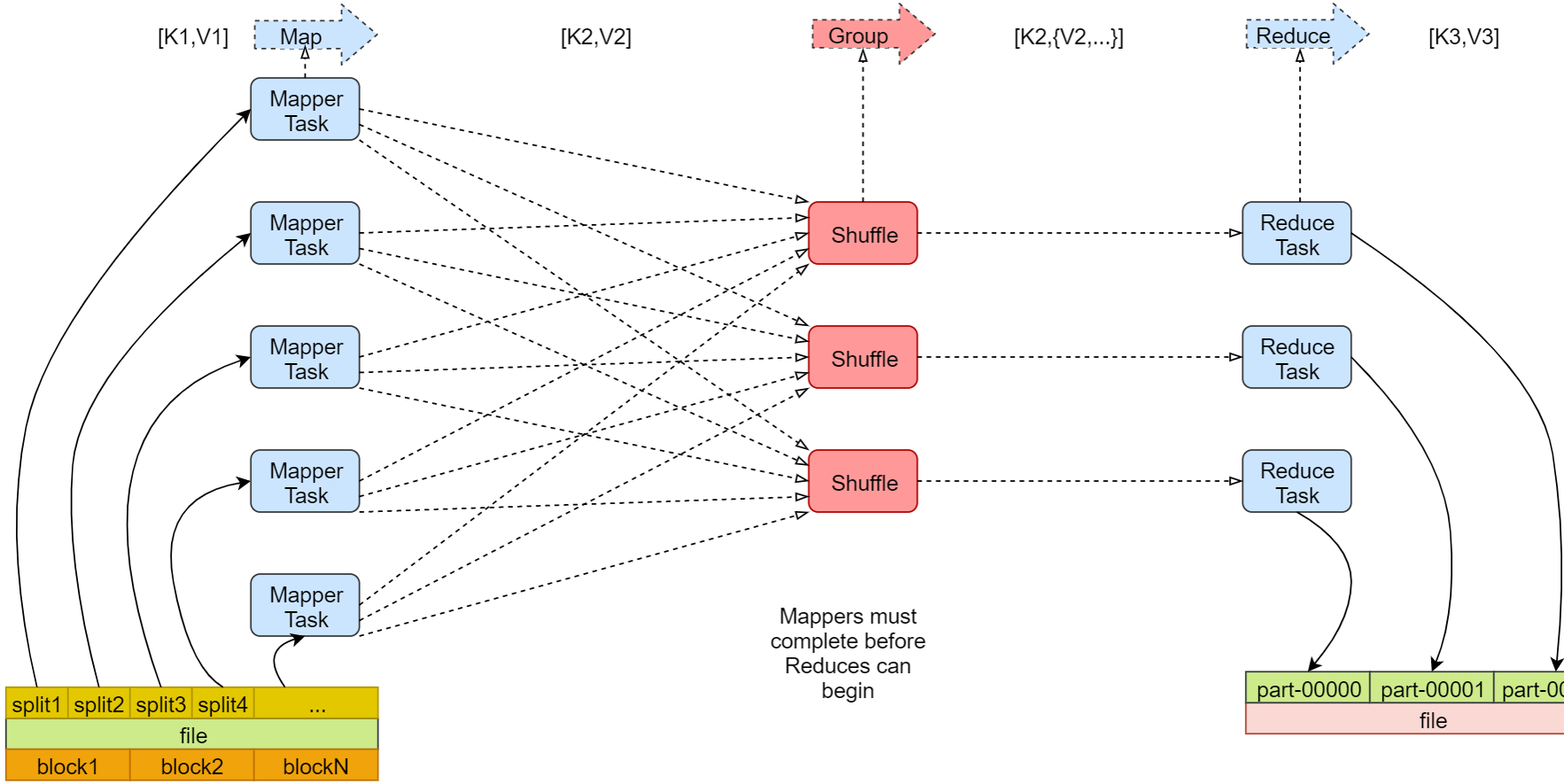
- 为了更好的理解
MapReduce计算模型,上面是我在网上找的一张流程图,可以清晰的看到整体流程可以大致分为三个阶段:Map、Shuffle、Reduce,但实际上在进入三个阶段前,还有一个数据分片阶段,因此我们可以将整体流程分为以下四个步骤:
txt
1、输入数据分片:将数据分割成多个逻辑块,每个块被一个 Mapper 处理。
2、Map 阶段:处理输入数据,将其转化为键值对 (key, value)。
3、Shuffle 阶段:对 Map 阶段的输出进行分区、排序和分组。
4、Reduce 阶段:对同一键的所有值进行聚合或计算,最终输出结果。MapReduce 三个核心阶段详解
Map 阶段
- 将输入数据转化为中间键值对 (key, value) 的形式。
工作原理
- 输入格式:Hadoop 的 InputFormat(默认是 TextInputFormat)将原始数据分割成逻辑记录,传递给 Mapper。
txt
1、每个逻辑块由一个 Mapper 处理,读取输入数据并生成中间结果。
2、用户需实现 map() 方法,定义如何将输入转化为中间 (key, value) 对。- 示例
txt
输入数据:
hello hadoop
hello world
输出数据
(hello, 1), (hadoop, 1), (hello, 1), (world, 1)Shuffle 阶段
- 将 Map 阶段的中间结果组织为 Reducer 可用的形式,包括分区、排序和分组。
- 是介于 Map 和 Reduce 之间的一个过程,可以分为 Map 端的 shuffle 和 Reduce 端的 Shuffle。
具体步骤
分区(Partition)
- 根据分区函数(默认是哈希函数 hash(key) % num_reducers)将中间键值对分配到不同的 Reducer。
相同键值对会被发送到同一个 Reducer。
排序(Sort)
- 对中间键值对按键进行全局排序。
- 排序可以在 Mapper 端局部排序,也可以在 Reducer 端进行全局合并排序。
分组(Combine 和 Grouping)
-
在 Reducer 端,具有相同键的所有值被合并为一个列表。
-
可选地使用 Combiner 函数在 Mapper 端预聚合中间结果,以减少网络传输量。
-
示例
txt
输入数据:
(hello, 1), (hadoop, 1), (hello, 1), (world, 1)
输出数据
Reducer 1: (hadoop, [1])
Reducer 2: (hello, [1, 1]), (world, [1])- 注意:
Shuffle 阶段可能成为性能瓶颈,因为涉及大量数据的网络传输和排序操作。
Reduce 阶段
- 对 Shuffle 阶段分组后的中间结果进行聚合或计算,输出最终结果。
工作原理
txt
1、输入:<key, list(values)>,即每个键和其对应的值列表。
2、用户需实现 reduce() 方法,定义如何对同一键的所有值进行处理。- 示例
txt
输入数据:
(hadoop, [1])
(hello, [1, 1])
(world, [1])
输出数据
(hadoop, 1)
(hello, 2)
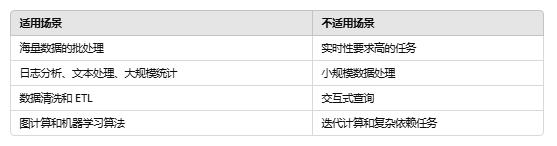
(world, 1)MapReduce 应用场景
- 数据分析:如日志处理、点击流分析。
- 文本处理:如全文索引、词频统计。
- 大规模计算:如矩阵乘法、图处理。
MapReduce Java 实战
Hadoop 环境搭建
- 本文主要演示
MapReduce:Map、Shuffle、Reduce三个流程,因此安装使用现成的 docker 镜像实现:
txt
docker pull sequenceiq/hadoop-docker:2.7.1
# 运行 Hadoop 单节点容器
docker run -it --name hadoop-master -p 8088:8088 -p 9870:9870 -p 9000:9000 sequenceiq/hadoop-docker:2.7.1- 安装成功后访问服务是否正常启动
txt
HDFS NameNode 界面:http://xxxxx:9870
YARN ResourceManager 界面:http://xxxx:8088代码实现
-
下面我们演示如何用 Java 实现一个基本的词频统计程序(WordCount),包含 Mapper、Reducer 和 Driver 的完整 Java 类。。
-
WordCountMapper.java
java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split("\\s+");
for (String str : words) {
word.set(str); // 设置当前单词
context.write(word, one); // 输出单词和计数值(1)
}
}
}- WordCountReducer.java
java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum); // 设置结果值
context.write(key, result); // 输出单词和总次数
}
}- WordCount.java (Driver 类)
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: WordCount <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Word Count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}打包提交服务器运行
- 上传统计文件到 HDFS
txt
wordcount.txt
hadoop hello hadoop
world
# 上传
hdfs dfs -mkdir -p /input/wordcount
hdfs dfs -put wordcount.txt /input/wordcount- 运行程序计算
txt
hadoop jar xxx/hadoop-wordcount-1.0-SNAPSHOT.jar com.example.WordCount- 查看运行结果

- 查看统计文件
txt
hadoop 1
hello 2
world 1个人简介
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
🚀 我对技术的热情是我不断学习和分享的动力。我的博客是一个关于Java生态系统、后端开发和最新技术趋势的地方。
🧠 作为一个 Java 后端技术爱好者,我不仅热衷于探索语言的新特性和技术的深度,还热衷于分享我的见解和最佳实践。我相信知识的分享和社区合作可以帮助我们共同成长。
💡 在我的博客上,你将找到关于Java核心概念、JVM 底层技术、常用框架如Spring和Mybatis 、MySQL等数据库管理、RabbitMQ、Rocketmq等消息中间件、性能优化等内容的深入文章。我也将分享一些编程技巧和解决问题的方法,以帮助你更好地掌握Java编程。
🌐 我鼓励互动和建立社区,因此请留下你的问题、建议或主题请求,让我知道你感兴趣的内容。此外,我将分享最新的互联网和技术资讯,以确保你与技术世界的最新发展保持联系。我期待与你一起在技术之路上前进,一起探讨技术世界的无限可能性。
📖 保持关注我的博客,让我们共同追求技术卓越。