1 参考文献
【官方指引】https://qwen.readthedocs.io/en/latest/
【ModelScope训练】https://modelscope.cn/docs/使用Tuners
【CUDA下载安装教程】https://blog.csdn.net/changyana/article/details/135876568
【安装cuDNN】https://developer.nvidia.com/rdp/cudnn-archive
【安装PyTorch】https://pytorch.org/
【安装Ollama】https://ollama.com/download
2 基础环境
2.1 安装CUDA
【查看显卡驱动】nvidia-smi
【验证CUDA安装】nvcc -V
首先查看NVIDIA显卡对应的CUDA版本号,然后根据此版本号下载对应版本的Toolkit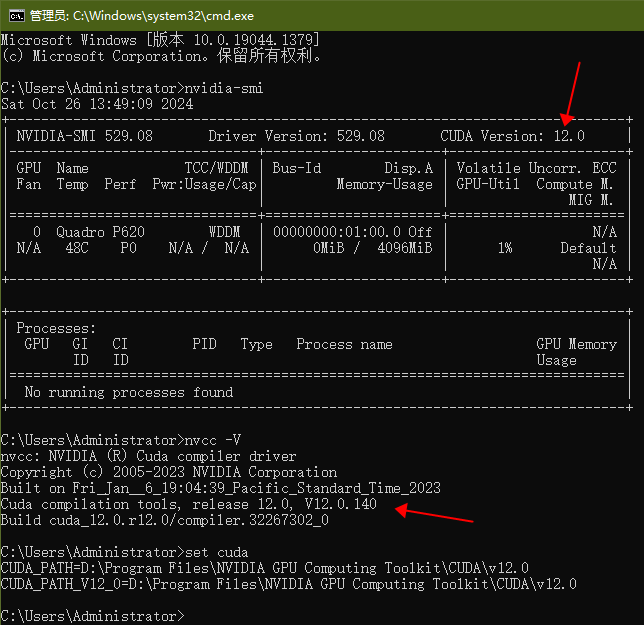
2.2 安装cuDNN
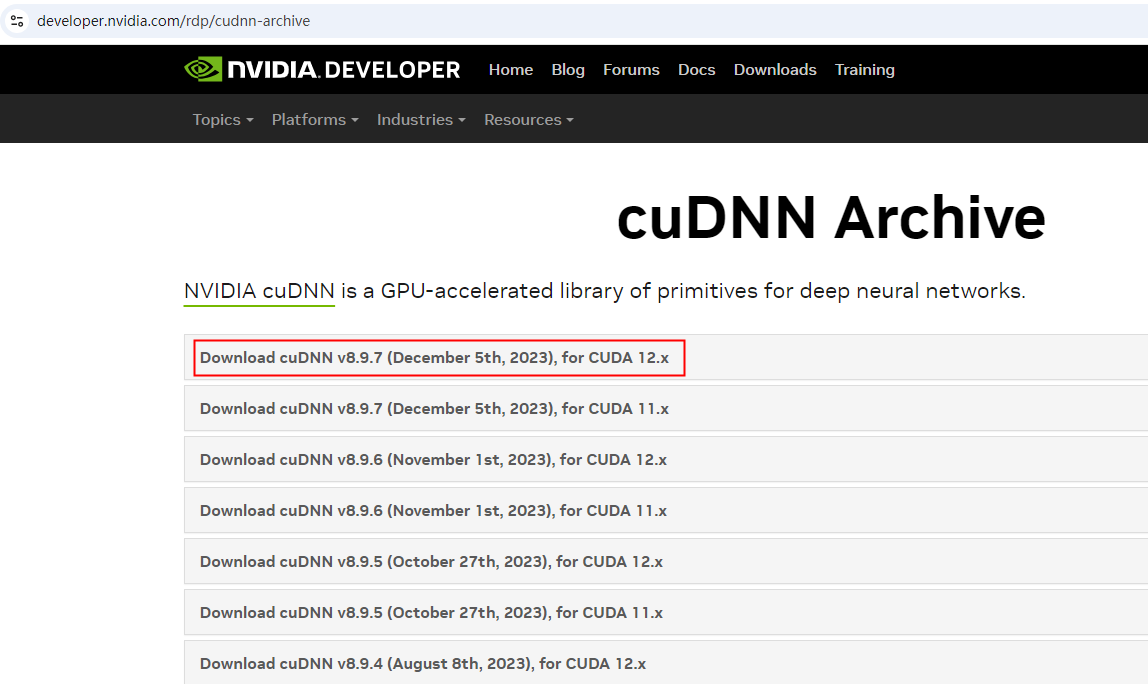
把下载的cudnn压缩包进行解压,在cudnn的文件夹下,把bin,include,lib文件夹下的内容对应拷贝到cuda相应的bin,include,lib下即可,最后安装完成。2.3 安装PyTorch
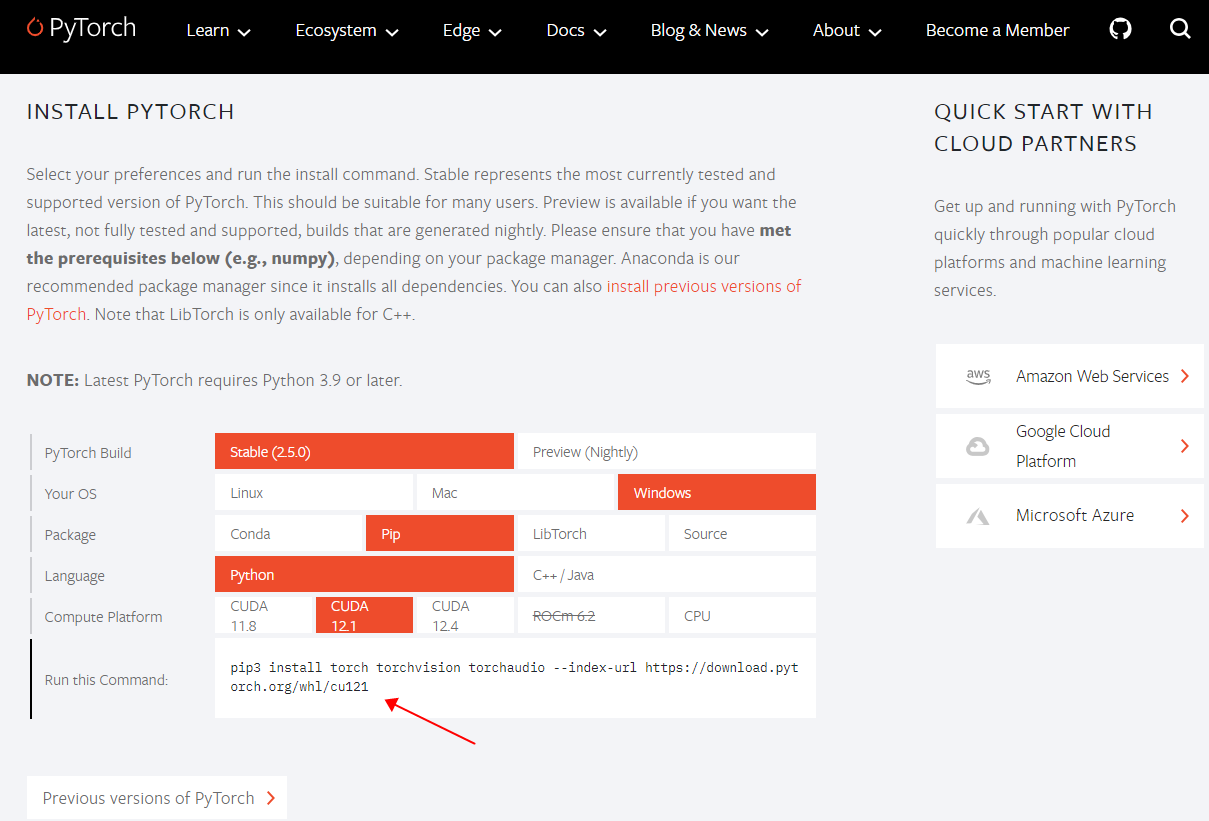
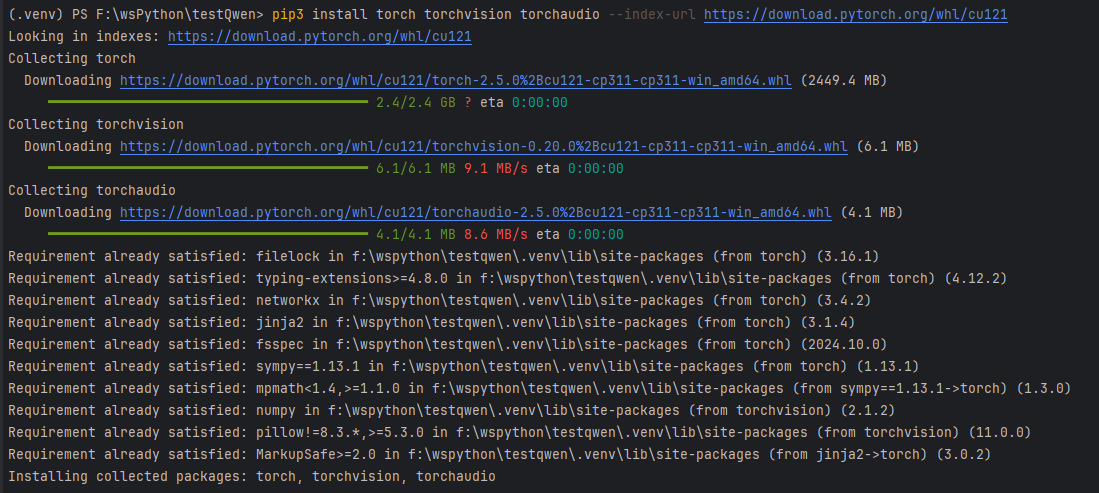
# 验证PyTorch是否与CUDA兼容
import torch
print(torch.\_\_version\_\_)
print(torch.cuda.is\_available())3 通过Ollama调用模型
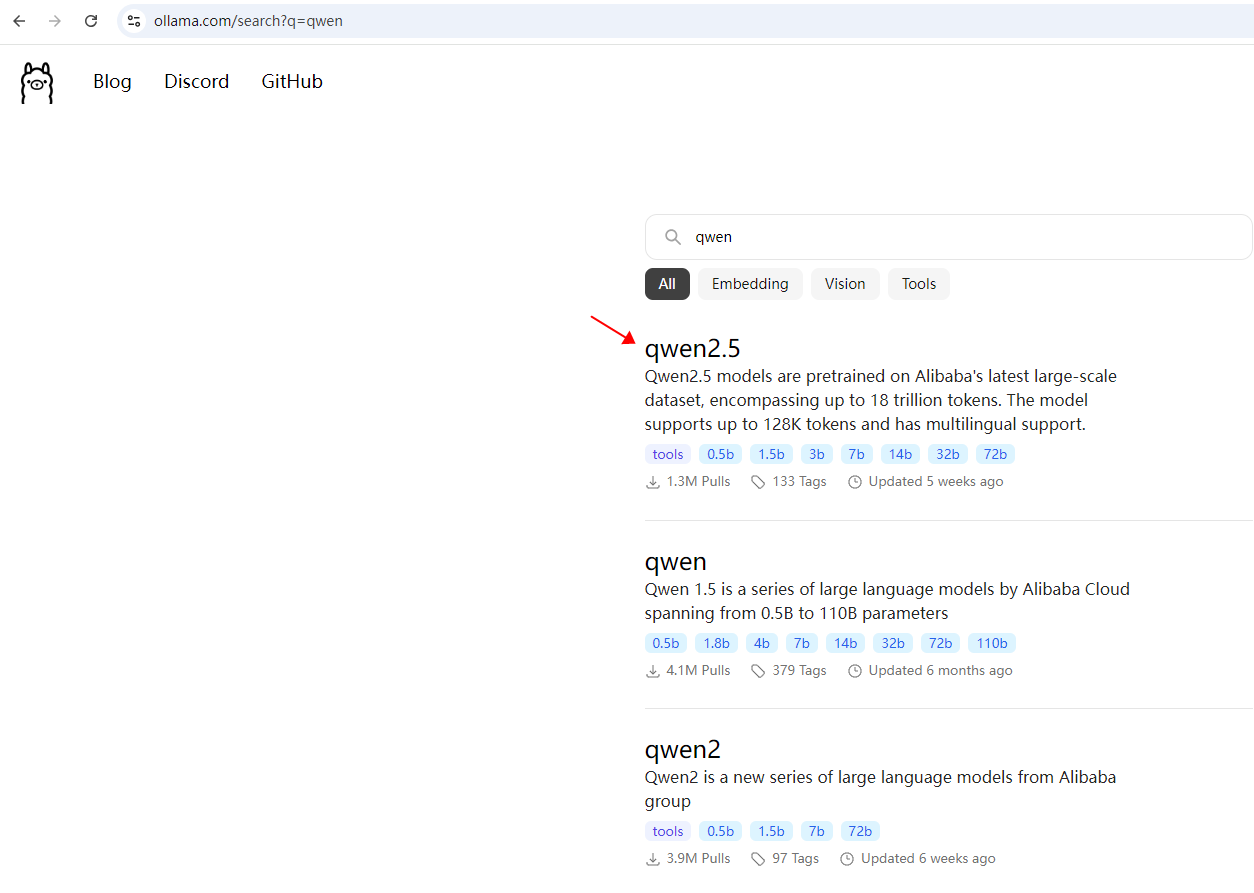
Ollama是一种比较简单方便的本地运行方案。通过Ollama官网直接安装,可搜索支持的大模型:https://ollama.com/search?q=qwen
4 Qwen官方指引
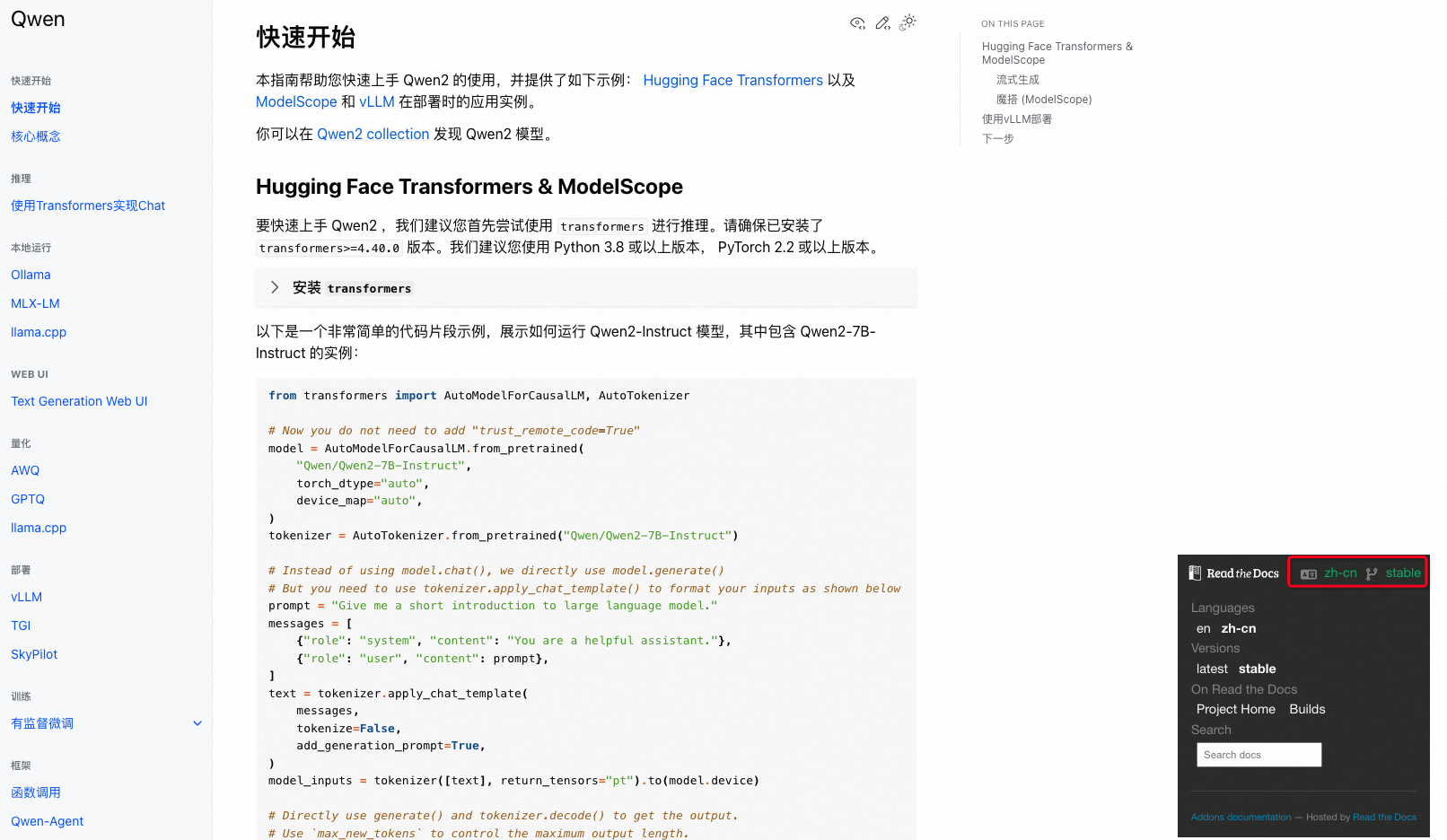
Qwen官方指南详细说明了支持的各种方案,比查看各种网络博客说明更清晰。
5 自定义训练
5.1 参考ModelScope指引
\# 自定义ModelScope模型缓存路径
export MODELSCOPE\_CACHE\=/Users/kuliuheng/workspace/aiWorkspace/Qwen

1 # A100 18G memory
2 from swift import Seq2SeqTrainer, Seq2SeqTrainingArguments 3 from modelscope import MsDataset, AutoTokenizer 4 from modelscope import AutoModelForCausalLM 5 from swift import Swift, LoraConfig 6 from swift.llm import get\_template, TemplateType 7 import torch 8
9 pretrained\_model = 'qwen/Qwen2.5-0.5B-Instruct'
10
11
12 def encode(example):
13 inst, inp, output = example\['instruction'\], example.get('input', None), example\['output'\]
14 if output is None:
15 return {}
16 if inp is None or len(inp) == 0:
17 q = inst
18 else:
19 q = f'{inst}\\n{inp}'
20 example, kwargs = template.encode({'query': q, 'response': output})
21 return example
22
23
24 if \_\_name\_\_ == '\_\_main\_\_':
25 # 拉起模型
26 model = AutoModelForCausalLM.from\_pretrained(pretrained\_model, torch\_dtype=torch.bfloat16, device\_map='auto', trust\_remote\_code=True)
27 lora\_config = LoraConfig(
28 r=8,
29 bias='none',
30 task\_type="CAUSAL\_LM",
31 target\_modules=\["q\_proj", "k\_proj", "v\_proj", "o\_proj"\],
32 lora\_alpha=32,
33 lora\_dropout=0.05)
34 model = Swift.prepare\_model(model, lora\_config)
35 tokenizer = AutoTokenizer.from\_pretrained(pretrained\_model, trust\_remote\_code=True)
36 dataset = MsDataset.load('AI-ModelScope/alpaca-gpt4-data-en', split='train')
37 template = get\_template(TemplateType.chatglm3, tokenizer, max\_length=1024)
38
39 dataset = dataset.map(encode).filter(lambda e: e.get('input\_ids'))
40 dataset = dataset.train\_test\_split(test\_size=0.001)
41
42 train\_dataset, val\_dataset = dataset\['train'\], dataset\['test'\]
43
44 train\_args = Seq2SeqTrainingArguments(
45 output\_dir='output',
46 learning\_rate=1e-4,
47 num\_train\_epochs=2,
48 eval\_steps=500,
49 save\_steps=500,
50 evaluation\_strategy='steps',
51 save\_strategy='steps',
52 dataloader\_num\_workers=4,
53 per\_device\_train\_batch\_size=1,
54 gradient\_accumulation\_steps=16,
55 logging\_steps=10,
56 )
57
58 trainer = Seq2SeqTrainer(
59 model=model,
60 args=train\_args,
61 data\_collator=template.data\_collator,
62 train\_dataset=train\_dataset,
63 eval\_dataset=val\_dataset,
64 tokenizer=tokenizer)
65
66 trainer.train()View Code
(1)官方示例代码中没有写 main 主函数入口,实际运行时发现会报错提示说:子线程在主线程尚未完成初始化之前就运行了。 所以这里就补齐了一个主函数入口
(2)官方代码中没有针对 'qwen/Qwen2.5-0.5B-Instruct' 模型代码,运行时target_modules会提示错误,需要指定模型中实际存在的模块名才行。这里有个技巧,通过打印模型信息可以看到实际的层级结构:
from modelscope import AutoModelForCausalLM
model\_name \= 'qwen/Qwen2.5-0.5B-Instruct'
model \= AutoModelForCausalLM.from\_pretrained(model\_name)
print(model)得到如下结果:


Qwen2ForCausalLM(
(model): Qwen2Model(
(embed\_tokens): Embedding(151936, 896)
(layers): ModuleList(
(0\-23): 24 x Qwen2DecoderLayer(
(self\_attn): Qwen2SdpaAttention(
(q\_proj): Linear(in\_features\=896, out\_features=896, bias=True)
(k\_proj): Linear(in\_features\=896, out\_features=128, bias=True)
(v\_proj): Linear(in\_features\=896, out\_features=128, bias=True)
(o\_proj): Linear(in\_features\=896, out\_features=896, bias=False)
(rotary\_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate\_proj): Linear(in\_features\=896, out\_features=4864, bias=False)
(up\_proj): Linear(in\_features\=896, out\_features=4864, bias=False)
(down\_proj): Linear(in\_features\=4864, out\_features=896, bias=False)
(act\_fn): SiLU()
)
(input\_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
(post\_attention\_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((896,), eps=1e-06)
(rotary\_emb): Qwen2RotaryEmbedding()
)
(lm\_head): Linear(in\_features\=896, out\_features=151936, bias=False)
)View Code
调整目标模块名之后,代码能够跑起来了,但Mac Apple M3笔记本上跑,的确是速度太慢了点:
\[INFO:swift\] Successfully registered \`/Users/kuliuheng/workspace/aiWorkspace/Qwen/testMS/.venv/lib/python3.10/site-packages/swift/llm/data/dataset\_info.json\`
\[INFO:swift\] No vLLM installed, if you are using vLLM, you will get \`ImportError: cannot import name 'get\_vllm\_engine' from 'swift.llm'\`
\[INFO:swift\] No LMDeploy installed, if you are using LMDeploy, you will get \`ImportError: cannot import name 'prepare\_lmdeploy\_engine\_template' from 'swift.llm'\`
Train: 0%| | 10/6492 \[03:27<42:38:59, 23.69s/it\]{'loss': 20.66802063, 'acc': 0.66078668, 'grad\_norm': 30.34488869, 'learning\_rate': 9.985e-05, 'memory(GiB)': 0, 'train\_speed(iter/s)': 0.048214, 'epoch': 0.0, 'global\_step/max\_steps': '10/6492', 'percentage': '0.15%', 'elapsed\_time': '3m 27s', 'remaining\_time': '1d 13h 21m 21s'}
Train: 0%| | 20/6492 \[23:05<477:25:15, 265.56s/it\]{'loss': 21.01838379, 'acc': 0.66624489, 'grad\_norm': 23.78275299, 'learning\_rate': 9.969e-05, 'memory(GiB)': 0, 'train\_speed(iter/s)': 0.014436, 'epoch': 0.01, 'global\_step/max\_steps': '20/6492', 'percentage': '0.31%', 'elapsed\_time': '23m 5s', 'remaining\_time': '5d 4h 31m 21s'}
Train: 0%| | 30/6492 \[29:48<66:31:55, 37.07s/it\]{'loss': 20.372052, 'acc': 0.67057648, 'grad\_norm': 38.68712616, 'learning\_rate': 9.954e-05, 'memory(GiB)': 0, 'train\_speed(iter/s)': 0.016769, 'epoch': 0.01, 'global\_step/max\_steps': '30/6492', 'percentage': '0.46%', 'elapsed\_time': '29m 48s', 'remaining\_time': '4d 11h 2m 20s'}
Train: 1%| | 40/6492 \[36:00<62:35:16, 34.92s/it\]{'loss': 20.92590179, 'acc': 0.66806035, 'grad\_norm': 38.17282486, 'learning\_rate': 9.938e-05, 'memory(GiB)': 0, 'train\_speed(iter/s)': 0.018514, 'epoch': 0.01, 'global\_step/max\_steps': '40/6492', 'percentage': '0.62%', 'elapsed\_time': '36m 0s', 'remaining\_time': '4d 0h 48m 3s'}
Train: 1%| | 50/6492 \[42:23<60:03:47, 33.57s/it\]{'loss': 19.25114594, 'acc': 0.68523092, 'grad\_norm': 37.24295807, 'learning\_rate': 9.923e-05, 'memory(GiB)': 0, 'train\_speed(iter/s)': 0.01966, 'epoch': 0.02, 'global\_step/max\_steps': '50/6492', 'percentage': '0.77%', 'elapsed\_time': '42m 23s', 'remaining\_time': '3d 19h 1m 0s'}
Train: 1%| | 60/6492 \[47:45<54:01:41, 30.24s/it\]{'loss': 19.54689178, 'acc': 0.69552717, 'grad\_norm': 27.87804794, 'learning\_rate': 9.908e-05, 'memory(GiB)': 0, 'train\_speed(iter/s)': 0.020941, 'epoch': 0.02, 'global\_step/max\_steps': '60/6492', 'percentage': '0.92%', 'elapsed\_time': '47m 45s', 'remaining\_time': '3d 13h 19m 3s'}
Train: 1%| | 65/6492 \[50:38<64:46:05, 36.28s/it\]