Flink支持多种安装模式。
local(本地)------本地模式
standalone------独立模式,Flink自带集群,开发测试环境使用
standaloneHA---独立集群高可用模式,Flink自带集群,开发测试环境使用
yarn------计算资源统一由Hadoop YARN管理,生产环境测试
下载链接:
https://archive.apache.org/dist/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.11.tgz
1、上传Flink安装包,解压,配置环境变量
[root@hadoop11 modules]# tar -zxf flink-1.13.6-bin-scala_2.11.tgz -C /opt/installs/
[root@hadoop11 installs]# mv flink-1.13.6/ flink
[root@hadoop11 installs]# vim /etc/profile
export FLINK_HOME=/opt/installs/flink
export PATH=$PATH:$FLINK_HOME/bin
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
记得source /etc/profile2、修改配置文件
① /opt/installs/flink/conf/flink-conf.yaml
jobmanager.rpc.address: bigdata01
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
#历史服务器 如果HDFS是高可用,则复制core-site.xml、hdfs-site.xml到flink的conf目录下 hadoop11:8020 -> hdfs-cluster
jobmanager.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/
historyserver.web.address: bigdata01
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/② /opt/installs/flink/conf/masters
bigdata01:8081③ /opt/installs/flink/conf/workers
bigdata01
bigdata02
bigdata033、上传jar包
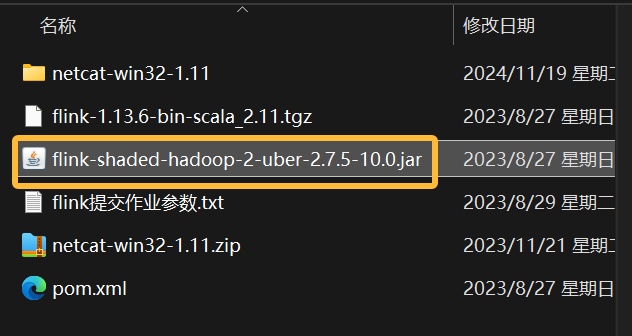
将资料下的flink-shaded-hadoop-2-uber-2.7.5-10.0.jar放到flink的lib目录下
4、分发
xsync.sh /opt/installs/flink
xsync.sh /etc/profile
如果你没有编写分发的脚本,可以使用scp命令进行远程拷贝。5、启动
#启动HDFS
start-dfs.sh
#启动集群
start-cluster.sh
#启动历史服务器
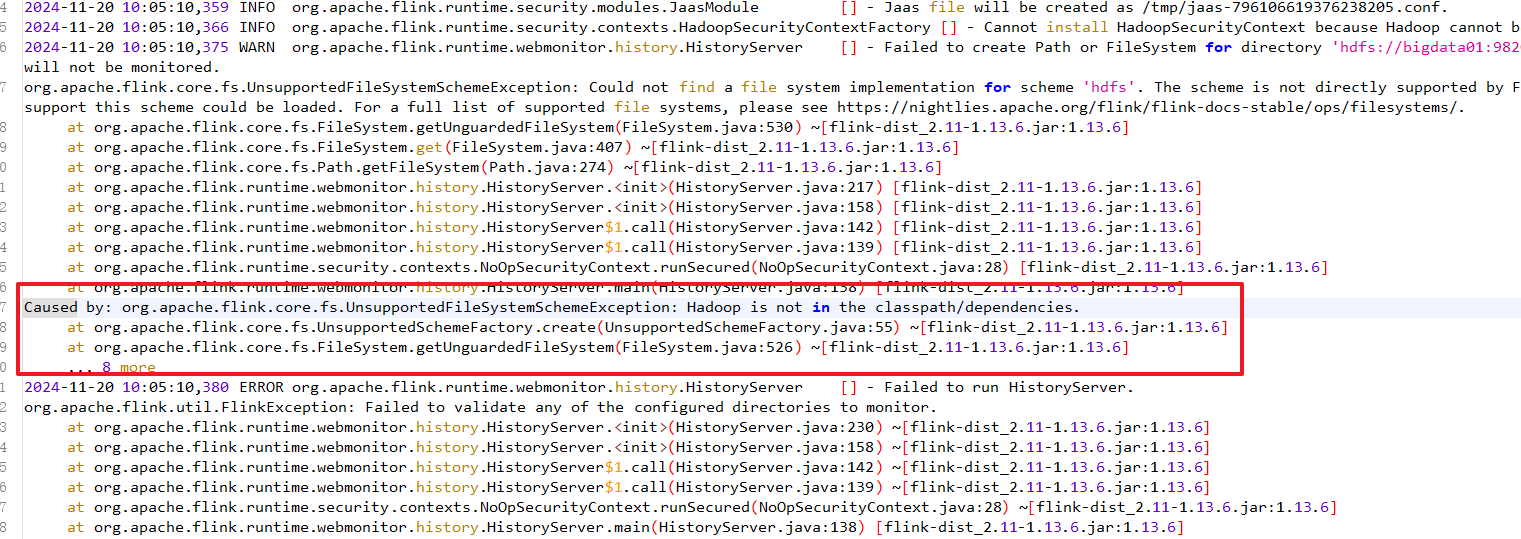
historyserver.sh start假如 historyserver 无法启动,也就没有办法访问 8082 服务,原因大概是你没有上传 关于 hadoop 的 jar 包到 lib 下:
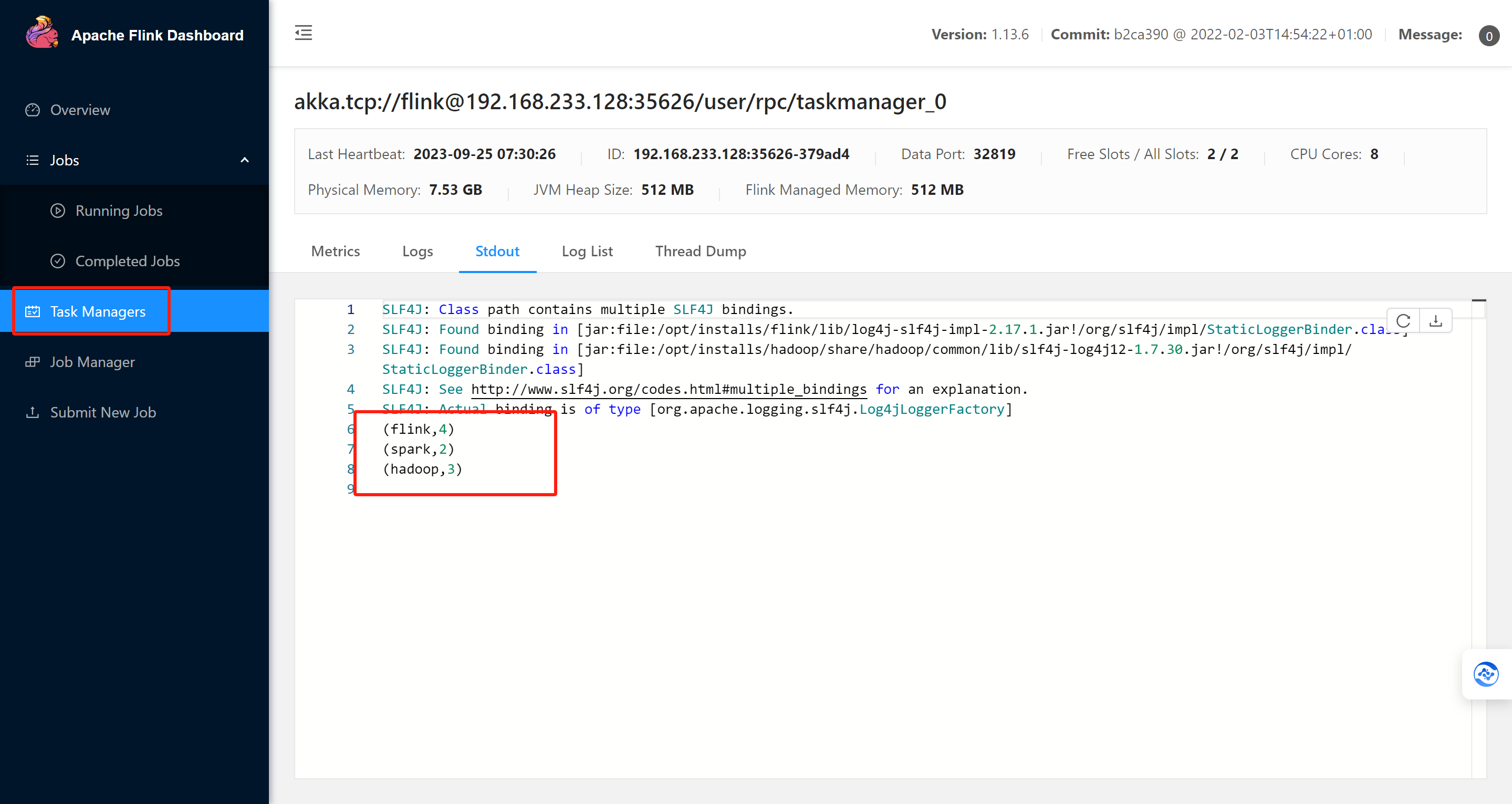
6、观察webUI
http://bigdata01:8081 -- Flink集群管理界面 当前有效,重启后里面跑的内容就消失了
能够访问8081是因为你的集群启动着呢
http://bigdata01:8082 -- Flink历史服务器管理界面,及时服务重启,运行过的服务都还在
能够访问8082是因为你的历史服务启动着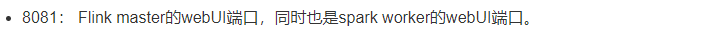
两者的区别:首先可以先把服务都停止
然后再重启,发现8081上已经完成的任务中是空的,而8082上的历史任务都还在,原因是8082读取了hdfs上的一些数据,而8081没有。
但是从web提供的功能来看,8081提供的功能还是比8082要丰富的多。
7、提交官方示例
flink run /opt/installs/flink/examples/batch/WordCount.jar
或者
flink run /opt/installs/flink/examples/batch/WordCount.jar --input 输入数据路径 --output 输出数据路径
flink run /opt/installs/flink/examples/batch/WordCount.jar --input /home/wc.txt --output /home/result运行以上案例时,会出现有时候运行成功,有时候运行失败的问题:
Caused by: java.io.FileNotFoundException: /home/wc.txt (没有那个文件或目录)
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at org.apache.flink.core.fs.local.LocalDataInputStream.<init>(LocalDataInputStream.java:50)
at org.apache.flink.core.fs.local.LocalFileSystem.open(LocalFileSystem.java:134)
at org.apache.flink.api.common.io.FileInputFormat$InputSplitOpenThread.run(FileInputFormat.java:1053)原因是:你的 taskManager 有三台,你的数据只在本地存放一份,所以需要将数据分发给 bigdata02 和 bigdata03
xsync.sh /home/wc.txt