概述
自大规模语言建模服务推出以来,由于其实用性强,已被许多公司和个人所使用。但与此同时,确保大规模语言模型的安全性已成为模型开发者和监管者面临的重要问题。近年来,研究人员和从业人员发现,迫切需要新的数据集来评估和提高大规模语言模型的安全性。已有许多研究报告。然而,由于安全性是多方面的,并取决于具体情况,因此并没有明确的定义。因此,由于这种复杂性,用于评估安全性的数据集多种多样,发展迅速。
例如,仅在 2024 年 1 月至 2 月间,就发布了许多数据集来评估各种风险。这些数据集包括社会经济偏差数据集(Gupta 等人,2024 年)、有害内容生成数据集(Bianchi 等人,2024 年)和与权力导向相关的长期风险评估数据集(Mazeika 等人,2024 年)。由于数据集种类繁多,研究人员和从业人员很难找到最适合自己的数据集。
本文首次对已发布的用于评估和提高大规模语言模型安全性的数据集进行了全面回顾,根据明确的选择标准,识别并收集了 2018 年 6 月至 2024 年 2 月间发布的 102 个数据集。然后从目的、创建方法、格式和规模、访问和许可等几个方面对这些数据集进行了审查。
对大规模语言建模安全最新发展的分析还表明,数据集的创建速度很快,主要是由学术机构和非营利组织推动的。分析还证实,专业安全评估和合成数据的使用越来越多,英语是数据集的主要语言。
此外,还通过发布模型和对流行的大规模语言模型进行基准测试,审查了在实践中如何使用公开可用的数据集。结果表明,目前的评估方法具有很强的专有性,而且只利用了一小部分可用数据集。
审查方法
本文的评论仅限于开放数据集,重点是大规模语言模型的安全评估和改进。本文只涉及文本数据集,不包括图像、语音或多模态模型数据集。
对数据格式没有限制,但由于与大型语言模型的交互通常以文本聊天的形式进行,因此包含开放式问题和说明的数据集以及多选题和自动完成式文本片段也包括在内。不设置语言限制。此外,只有在 GitHub 和 Hugging Face 上公开的数据集才能访问。对数据许可证的类型没有限制。
最后,所有数据集必须与大规模语言模型的安全性相关。安全的定义范围很广,包括与大规模语言模型的代表性、政治和社会人口偏见、有害指令和建议、危险行为、社会、道德和伦理价值以及对抗性使用有关的数据集。它不包括与大规模语言模型能力、错误信息生成或真实性测量相关的一般数据集。本次审查的截止日期为 2024 年 3 月 1 日。在此日期之后发布的数据集不包括在内。
本文还采用了社区驱动的迭代方法来探索数据集。2024 年 1 月发布了包含初始数据集列表的 SafetyPrompts.com 第一版,并在 Twitter 和 Reddit 上进行推广,以征求反馈和其他建议。最终收集到 77 个数据集,随后又通过滚雪球的方式收集到 35 个数据集。最终,102 个在 2018 年 6 月至 2024 年 2 月期间发布的开放数据集被纳入审查范围。
论文指出,采用这种方法有两个原因:首先,大规模语言模型的安全性是一个快速发展的领域,来自广泛利益相关者的反馈非常重要;通过在 SafetyPrompts.com 上共享审查的中期结果,可以获得许多意见。其次,它表示这样做是为了确保不会遗漏传统关键词搜索无法捕捉到的相关数据集。例如,"语言模型"、"安全 "和 "数据集 "等关键词可以在谷歌学术等网站上产生许多结果,但可能会遗漏重要的数据集。
它还记录了 102 个数据集中每个数据集的 23 条结构化信息。这涵盖了整个数据集开发流程,包括每个数据集是如何创建的、它的外观如何、如何使用、如何访问以及在哪里发布。下表是一份代码手册,描述了本次审查的电子表格结构和内容。复制该电子表格和分析的代码可在 github.com/paulrottger/safetyprompts-paper 上获取。
审查结果
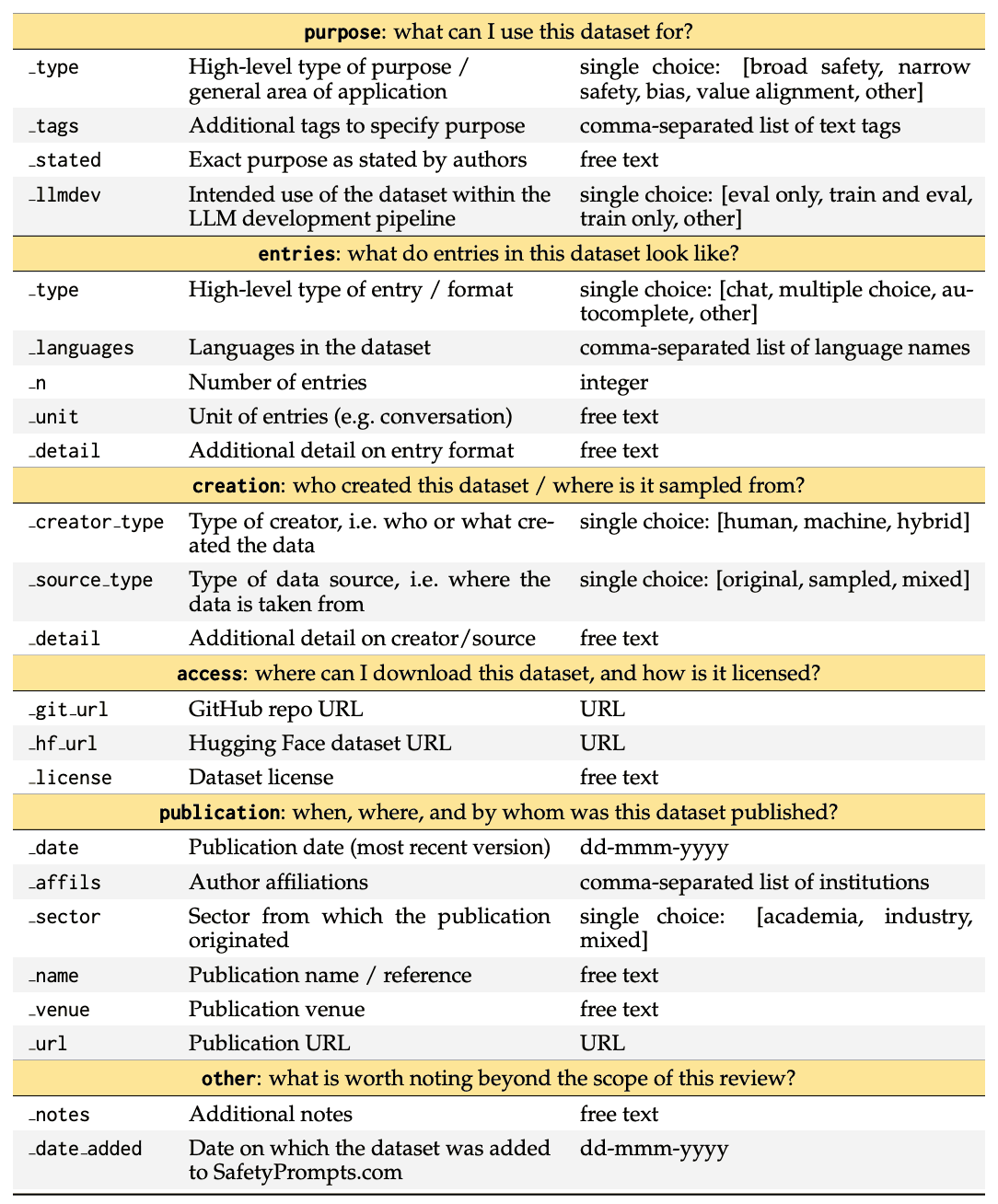
对大规模语言模型安全性的研究建立在对语言模型风险和偏差的长期研究基础之上。首批数据集于 2018 年发布,旨在评估性别偏见。这些数据集旨在用于核心参照解析系统,但也适用于当前的大规模语言模型。这些数据集建立在之前关于词嵌入偏差的研究基础之上,表明人们对语言模型负面社会影响的担忧并不新鲜。
同样,Dinan 等人(2019 年)和 Rashkin 等人(2019 年)等人也在当前的生成式大规模语言建模范式之前引入了数据集,以评估和改进对话代理的安全性。然而,当时人们对安全性的兴趣相对较小,本文所回顾的 102 个数据集中只有 9 个(8.9%)是在 2020 年之前发表的。
2021 年至 2022 年,有关大规模语言模型安全性的研究经历了一个适度增长期。在这两年中,分别发布了 15 和 16 个开放数据集。这与研究人员对生成式语言建模的兴趣日益浓厚相吻合,尤其是在 GPT-3 (Brown 等人,2020 年)发布之后。
最后,论文证实,有关大规模语言模型安全性的研究目前正在经历前所未有的增长。在本次综述收录的 102 个数据集中,有 47 个(46.1%)是在 2023 年发布的。这与ChatGPT(2022 年 11 月)发布后公众对大规模语言模型日益增长的兴趣以及对大规模语言模型安全性的担忧是一致的。数据集。
本文还将数据集的目的分为五大类。首先,广泛安全(n=33)是指涵盖大规模语言模型安全性多个方面的数据集。这包括结构化评估数据集,如 SafetyKit(Dinan 等人,2022 年)和 SimpleSafetyTests(Vidgen 等人,2023 年),以及 BAD(Xu 等人,2021 年)和 AnthropicRedTeam(Ganguli 等人,2022 年)等数据集。.,2022 年)等数据集,以及广泛的红外数据集,如
其次,狭义安全(n=18)是指在大规模语言模型中只关注安全特定方面的数据集。例如,SafeText(Levy 等人,2022 年)侧重于一般的物理安全,而 SycophancyEval(Sharma 等人,2024 年)侧重于跟随行为。
价值完整性(n=17)是指大规模语言模型中有关伦理、道德或社会行为的数据集。它包括评估对道德规范理解的数据集,如 Scruples(Lourie 等人,2021 年)和 ETHICS(Hendrycks 等人,2020 年a),以及民意调查,如 GlobalOpinionQA(Durmus 等人,2023 年)。包括
偏差(n=26)是指评估大规模语言模型中社会人口偏差的数据集。例如,BOLD(Dhamala 等人,2021 年)评估文本完成中的偏差,DiscrimEval(Tamkin 等人,2023 年)评估特定 LLM 决策中的偏差。
其他(n=8)包括用于开发大型语言模型聊天监控系统(如 FairPrism(Fleisig 等人,2023 年)和 ToxicChat(Lin 等人,2023 年))的数据集,以及来自公开提示黑客竞赛的数据集。包括专业提示语集(如 Gandalf (LakeraAI, 2023a)、Mosscap (LakeraAI, 2023b) 和 HackAPrompt (Schulhoff et al., 2023))。
下图(转载于下)显示,最初的安全数据集主要涉及评估偏见:2018 年至 2021 年间发布的 24 个数据集中,有 13 个(54.2%)是为识别和分析语言模型中的社会人口偏见而创建的。其中 12 个数据集评估了性别偏见,包括与其他偏见类别(如种族和性取向)一起评估的数据集。
广泛的安全性是 2022 年行业贡献的一个重要主题。例如,Anthropic 发布了两个广泛的红队数据集(Ganguli 等人,2022 年;Bai 等人,2022 年a),Meta 发布了一个关于正向差异尺度语言模型交互的数据集(Ung 等人,2022 年)和一个关于一般安全评估的数据集(Dinan 等人,2022 年)。数据集(Dinan 等人,2022 年)。最近,广泛的安全评估已转向结构性更强的评估,如DecodingTrust(Wang等人,2024年)和HarmBench(Mazeika等人,2024年)等基准。
本文的审查结果表明,安全评估呈现出更加专业化的趋势。狭义的安全评估直到 2022 年才出现,但现在已成为新数据集的主体:仅在 2024 年的前两个月,在纳入审查的 15 个数据集中,就有 6 个(40.0%)与规则合规性(Mu 等人,2024 年)、隐私推理能力(Mireshghallah 等人,2024 年)和大规模语言模型安全性的某些方面有关。能力(Mireshghallah 等人,2024 年)以及大规模语言模型安全性的某些方面。
最后,很明显,大多数数据集仅用于模型评估。在本综述收录的 102 个数据集中,有 80 个(78.4%)明确是为基准测试和评估而创建的,而不是用于模型训练。相比之下,只有 4 个数据集(3.9%)包含用户与专门为模型训练而创建的大规模语言模型之间积极互动的实例。
它还回顾了数据集的格式和大小。研究发现,大规模语言模型的安全数据集格式随着大规模语言模型的总体发展趋势而发生了变化。早期的数据集,尤其是为偏差评估而创建的数据集,通常使用自动完成格式(n=8)。在这种格式中,模型的任务是填写屏蔽词或完成句子片段。这些格式最适合早期的大规模语言模型(如 BERT 和 GPT-2),而聊天式提示和对话(n=58)以及可提示选择题(n=14)则更适合当前的大规模语言模型。
综述中包含的 102 个数据集在规模上差别很大,但不同数据集的特点(如数据集的目的或创建方式)并没有明显的对应模式。最小的数据集是 Bianchi 等人(2024 年)的 ControversialInstructions,其中包含 40 个作者生成的提示,指示大规模语言模型生成仇恨言论。最大的数据集是 Schulhoff 等人(2023 年)的 HackAPrompt,其中包含 601,757 条人类编写的提示语,是提示语黑客竞赛的一部分。
此外,审查还从创建方式的角度对数据集进行了研究。在所审查的 102 个数据集中,有 17 个(16.7%)使用了人工编写的短语和提示模板,这些模板被组合起来创建了大型评估数据集。例如,HolisticBias(Smith 等人,2022 年)使用了 26 个句子模板(如 "我是属性 1和属性 2"。),并结合约 600 个不同的描述性词语,创建了 459 758 个测试用例。这种模板方法在偏差评估中特别流行,26 个偏差评估数据集中有 13 个使用了这种方法。模板最近还被用于大规模语言模型的一般安全性评估(Wang 等人,2024 年)和隐私推断(Mireshghallah 等人,2024 年)。
最近发布的越来越多的数据集是完全合成的。早期的安全数据集收集的是人写的提示语,但第一个包含完全由模型生成的提示语的数据集是在 2023 年发布的。由提示语、句子和多选题组成。例如,Shaikh 等人(2023 年)使用 GPT-3.5 生成了 200 个有害问题,并研究了排序链(CoT)问题解答的安全性。
此外,最近的一些数据集不是使用静态模板进行数据准备,而是使用大规模语言模型进行灵活扩增。例如,Bhatt 等人(2023 年)使用 Llama-70b-chat (Touvron et al.Wang 等人(2024 年)采用类似方法建立了一个大型 DecodingTrust 基准。
也有用于模型评估的小型手写提示数据集。在审查的 102 个数据集中,有 11 个(10.8%)是由作者自己编写的,包括几百条提示,用于评估特定的模型行为(如遵守规则(Mu 等人,2024 年)或夸大安全性(Rottger 等人,2023 年))。
还对数据集的语言进行了审查。大多数安全数据集仅使用英语。在审查的 102 个数据集中,88 个(86.3%)仅使用英语;6 个数据集(5.9%)仅使用中文(如 Zhou 等人,2022 年;Xu 等人,2023 年;Zhao 等人,2023 年);1 个数据集(Nevéol等人,2022 年)测量了法语模型中的社会偏见。其他 7 个数据集(10.8%)涵盖英语和一种或多种其他语言;Pikuliak 等人(2023 年)涵盖 10 种语言,所审查的 102 个数据集共涵盖 19 种不同语言。
审查还关注了数据访问和许可方面:在102 个数据集中,只有 8 个(7.8%)没有在 GitHub 上共享,而 GitHub 是最受欢迎的数据共享平台。这 8 个数据集可在 Hugging Face 上获得;35 个数据集(34.3%)可在 GitHub 和 Hugging Face 上获得;尽管 Hugging Face 越来越受欢迎,但在 Hugging Face 上获得数据集的比例更高。报告称,尽管Hugging Face越来越受欢迎,但在Hugging Face上可用的数据集比例较高的趋势并不明显。
此外,在共享数据时,所使用的许可证通常是许可性的。最常见的许可证是麻省理工学院许可证,102 个数据集中有 40 个(39.2%)使用该许可证;14 个(13.7%)使用阿帕奇 2.0 许可证,该许可证提供额外的专利保护;27 个(26.5%)使用知识共享 BY 4.0 许可证,该许可证要求提供适当的出处并注明对数据集所做的任何更改;5 个数据集(4.5%)使用知识共享 BY 4.0 许可证。27(26.5%)个数据集使用了知识共享 BY 4.0 许可,该许可要求提供适当的信用并注明对数据集所做的任何改动;5 个数据集(4.9%)使用了 CC BY-NC 许可,该许可禁止商业使用;2 个数据集(4.9%)使用了 CC BY-NC 许可,该许可禁止商业使用。只有一个数据集(2.0%)使用限制性更强的自定义许可证;截至 2024 年 3 月 25 日,有 19 个数据集(18.6%)未指定许可证。
报告还指出,数据集的创建和出版主要由学术机构和非营利组织主导。在所审查的 102 个数据集中,有 51 个(50.0%)是由完全隶属于学术或非营利组织的作者发表的;27 个(26.5%)是由行业和学术团队发表的;24 个(23.5%)是由非营利组织发表的。出版。另外,数据集的创建显然集中在少数研究中心。
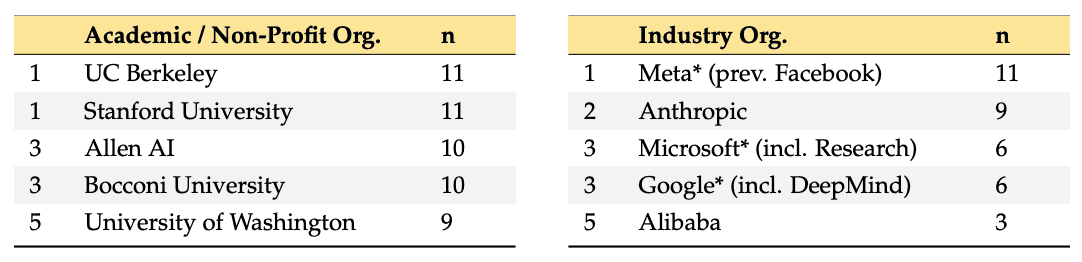
它表明,通过使用模板和合成数据,已经创建了多样化的评估数据集。它还提供了关于语言多样性、数据访问和许可的重要见解。
在发布模型时使用安全数据集
本节介绍了安全数据集实际使用情况的调查结果。特别是,它根据公开的模型发布文档,调查了在现代大规模语言模型发布之前,哪些安全数据集被用于评估这些模型。它还调查了流行的大规模语言模型基准中包含的安全数据集,并确定了大规模语言模型安全评估的规范和一般使用现状。
本文收录了截至 2024 年 3 月 12 日在LMSYS Chatbot Arena Leaderboard上列出的性能最高的前 50 个大规模语言模型。LMSYS Leaderboard 是一个用于评估大规模语言模型的众包平台,它基于 400 多万对人类偏好投票来计算和排列模型的 ELO 分数。LMSYS Leaderboard 在大规模语言建模社区非常受欢迎,涵盖了业界和学术界最新发布的模型。
前 50 个条目对应 31 个独特的模型发布。在这 31 个模型中,有 11 个(35.5%)是只能通过 API 访问的专有模型。这些模型分别由 OpenAI (GPT)、Google (Gemini)、Anthropic (Claude)、Perplexity (pplx) 和 Mistral (Next、Medium 和 Large) 发布。其他 20 个模型(64.5%)是可通过 Hugging Face 访问的开放模型。在排行榜上,专有模型普遍优于开放模型,Qwen1.5-72b-chat 是排名最高的开放模型,排在第 10 位。31个模型中有26个(83.9%)是由工业研究中心发布的,其余的由学术或非营利组织发布。所有 31 个模型都是在 2023 年或 2024 年发布的。
审查发现,大多数现代大规模语言模型在发布前都进行了安全评估,但这些评估的范围和性质各不相同:31 个模型中有 24 个(77.4%)在其发布出版物中报告了安全评估;21 个(67.7%)报告了至少一个数据集的安全评估,并报告了评估结果。数据集,并报告了结果。例如,Guanaco(Dettmers 等人,2024 年)只在一个安全数据集(Nangia 等人的 CrowS-Pairs,2020 年)中进行了评估。相比之下,Llama2(Touvron 等人,2023b)在五个不同的安全性数据集中进行了评估;31 个模型中有七个没有报告任何安全性评估。这些模型包括来自学术界和工业界的五个开放模型,如 Starling(Zhu 等人,2023 年)和 WizardLM(Xu 等人,2024 年),以及专有的 Mistral Medium 和 Next 模型。
研究还发现,专有数据在模型释放的安全评估中发挥着重要作用。在报告安全评估结果的 24 个模型释放中,有 13 个(54.2%)使用了非公开的专有数据来评估模型的安全性。其中三个版本(Gemini(Anil等人,2023年)、Qwen(Bai等人,2022年b)和Mistral-7B(Jiang等人,2023年))仅报告了来自专有数据集的结果。
此外,在模型发布评估中使用的安全数据集的多样性也非常有限:在 31 个模型发布中,总共只使用了 12 个开放的 LLM 安全数据集,其中 7 个只使用了一次。其中,TruthfulQA(Lin 等人,2022 年)在 24 个报告安全评估结果的模型发布中被用于 16 个(66.7%)。所有其他数据集最多在 5 个模型发布出版物中使用。
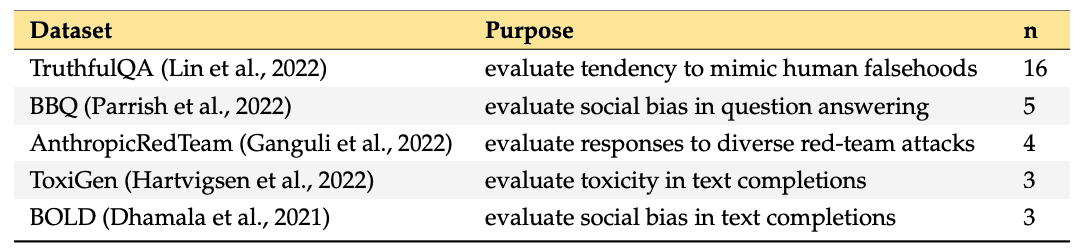
由此可见,安全数据集在模型释放中发挥着重要作用,是安全评估的基础。然而,这些数据集的使用是有限的,预计将使用更多样化的数据集。
主要基准中使用的安全数据集
对以下五个广泛使用的通用基准进行了研究
- 斯坦福大学的 HELM Classic(Liang 等人,2023 年)。
- HELM 结构(Zhang 等人,2024 年)。
- Hugging Face's Open LLM Leaderboard (Beeching et al., 2023)。
- Eleuther 人工智能的评估系统(Gao 等人,2021 年)、
- BIG-Bench(Srivastava 等人,2023 年)。
此外,还研究了两个基准,TrustLLM(Sun 等人,2024 年)和 LLM 安全排行榜,这两个基准主要关注大规模语言模型的安全性。
审查发现,各基准评估大规模语言模型安全性的方式存在显著差异:七个基准共使用了 20 个安全数据集,其中 14 个数据集仅用于一个基准。例如,TrustLLM(Sun 等人,2024 年)使用了 8 个安全数据集,其中 6 个未在任何其他基准中使用;在多个基准中使用的安全数据集包括 TruthfulQA(Lin 等人,2022 年)、TrustLLM(Sun 等人,2023 年)、TrustLLM(Sun 等人,2024 年)和 TruthfulQA(Lin 等人,2022 年)。在五个基准中使用,而 RealToxicityPrompts(Gehman 等人,2020 年)和 ETHICS(Hendrycks 等人,2020a)在三个基准中使用。
总结
本文的综述显示,人们对大规模语言模型安全性的兴趣与日俱增,推动了大规模语言模型安全性数据集的多样化,2023 年发布的数据集数量超过以往任何时候,预计今年这一趋势仍将持续。.而现有数据集的用途和格式多种多样,随着时间的推移,会逐渐适应大规模语言模型用户和开发者的用途。
但另一方面,我们也发现了一些挑战。目前最突出的挑战之一是缺乏英语以外语言的数据集。我们发现,目前的安全数据集绝大多数是英文的。这可能反映了多年来自然语言处理的研究趋势。数据集的语言偏差反映了数据集发布者的语言偏差。如果非美国机构率先用自己的语言创建数据集,这种偏差就会得到改善。
对大规模语言模型安全数据集实际使用情况的分析还表明,在安全评估标准化方面还有改进的余地。安全评估是模型开发者和用户的一个重要优先事项,这一点从模型版本的发布和将安全评估纳入流行的大规模语言模型基准中可以得到证明。然而,迄今为止所使用的安全评估方法显然都是高度专有的,大多数模型发布出版物和基准都使用了不同的数据集。更加标准化和公开的评估将使模型比较更有意义,并为促进安全大规模语言模型的开发提供激励。
标准化的挑战在于确定哪些评估构成适当的标准。本文回顾的数据集也表明,不同的数据集有不同的用途,很难简单地用同一标准进行比较。首先,我们希望此次回顾有助于认识到目前可用的大型语言建模数据集的多样性,从而为今后的数据集开发提供参考。
注:
源码地址:https://github.com/paul-rottger/safetyprompts-paper.git