【大语言模型】ACL2024论文-16 基于地图制图的罗马尼亚自然语言推理语料库的新型课程学习方法
目录
文章目录
- [【大语言模型】ACL2024论文-16 基于地图制图的罗马尼亚自然语言推理语料库的新型课程学习方法](#【大语言模型】ACL2024论文-16 基于地图制图的罗马尼亚自然语言推理语料库的新型课程学习方法)
基于地图制图的罗马尼亚自然语言推理语料库的新型课程学习方法

摘要:
本文的主要贡献是介绍了第一个公开的罗马尼亚语自然语言推理(NLI)语料库RoNLI,它包含58K训练句子对和6K验证及测试句子对。这些句子对通过远程监督获取和手动标注得到正确的标签。文章还提出了一种基于数据制图的新型课程学习策略,通过该策略改进了最佳模型。数据集和复现基线的代码已在GitHub上公开。
研究背景:
自然语言推理(NLI)任务是识别句子对中的蕴含关系,是自然语言理解(NLU)的关键任务之一。尽管NLI任务在构建对话代理、改进文本分类、机器翻译等自然语言处理(NLP)任务中非常重要,但针对低资源语言的NLI研究相对较少。罗马尼亚语作为一种低资源语言,缺乏公开的NLI语料库,这限制了在该语言上研究和开发NLI模型的可能性。

问题与挑战:
罗马尼亚语NLI任务面临的主要挑战包括:1)缺乏公开的NLI语料库;2)由于资源稀缺,难以训练有效的NLI模型;3)模型容易受到自动标注过程中的噪声影响。
如何解决:
本文通过以下方式解决上述挑战:1)创建了首个罗马尼亚语NLI语料库RoNLI;2)提出了一种基于数据制图的新型课程学习策略,以改善模型训练;3)通过手动标注验证和测试集,确保数据质量。
核心创新点:
- 创建了首个罗马尼亚语NLI语料库RoNLI,为研究罗马尼亚语NLI提供了基础资源。
- 提出了一种基于数据制图的新型课程学习策略,通过分析模型的训练动态来指导训练过程,从而提高模型性能。
算法模型:
- 基于远程学习的多种机器学习模型,包括基于词嵌入的浅层模型和基于Transformer的神经网络。
- Ro-BERT:针对罗马尼亚语的BERT变体,用于NLI任务。
- 基于数据制图的新课程学习策略,通过数据特性(如置信度和变异性)来指导模型训练。
实验效果:
- Ro-BERT在基线模型中表现最佳,但在整体F1分数上未能超过80%。
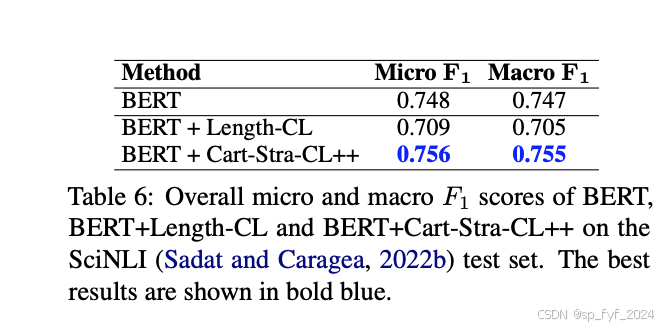
- 通过数据制图和课程学习策略,Ro-BERT + Cart-Stra-CL++模型在微F1和宏F1分数上分别达到了75%和59%,显示出统计学上的显著改进。
- 在SciNLI数据集上,Ro-BERT + Cart-Stra-CL++模型也取得了最佳性能,证明了其泛化能力。


相关工作:
本文提到了多个英语和其他语言的NLI数据集,如SNLI、MNLI、XNLI等,并讨论了它们的优缺点。此外,还提到了其他低资源语言NLI数据集的研究,如Creole、Indonesian和Turkish。
后续优化方向:
- 扩大RoNLI语料库的规模,以支持更复杂的NLI模型训练。
- 探索更多的课程学习策略,以进一步提高模型性能。
- 研究罗马尼亚语特有的语法和语义现象,以改进模型对罗马尼亚语的理解。
- 将RoNLI和新型课程学习策略应用于其他低资源语言,以促进这些语言NLI研究的发展。
后记
如果您对我的博客内容感兴趣,欢迎三连击 (***点赞、收藏和关注 ***)和留下您的评论,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。