详细介绍Stable Diffusion核心网络结构------CLIP,作用,架构等。

目录
[Stable Diffusion核心网络结构](#Stable Diffusion核心网络结构)
[CLIP Text Encoder模型](#CLIP Text Encoder模型)
Stable Diffusion核心网络结构
摘录来源:https://zhuanlan.zhihu.com/p/632809634
目录
[Stable Diffusion核心网络结构](#Stable Diffusion核心网络结构)
[CLIP Text Encoder模型](#CLIP Text Encoder模型)
SD模型整体架构初识
Stable Diffusion模型整体上是一个End-to-End模型 ,主要由VAE (变分自编码器,Variational Auto-Encoder),U-Net 以及CLIP Text Encoder三个核心组件构成。
本文主要介绍CLIP Text Encoder,VAE和U-Net请参考:
在FP16精度下Stable Diffusion模型大小2G(FP32:4G),其中U-Net大小1.6G,VAE模型大小160M以及CLIP Text Encoder模型大小235M(约123M参数)。其中U-Net结构包含约860M参数,FP32精度下大小为3.4G左右。
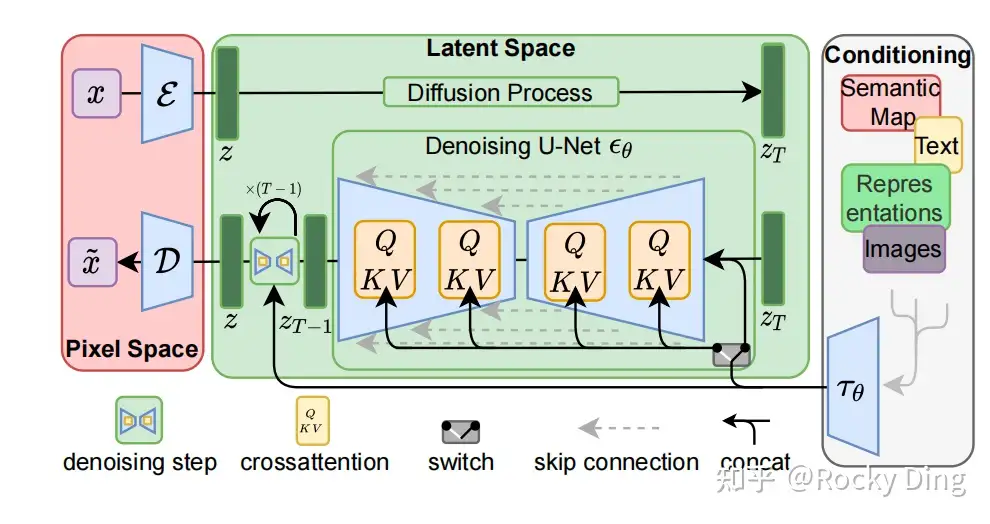 Stable Diffusion整体架构图
Stable Diffusion整体架构图
CLIP Text Encoder模型
作为文生图模型,Stable Diffusion中的文本编码模块直接决定了语义信息的优良程度,从而影响到最后图片生成的质量和与文本的一致性。
在这里,多模态领域的神器------CLIP(Contrastive Language-Image Pre-training) ,跨过了周期,从传统深度学习时代进入AIGC时代,成为了SD系列模型中文本和图像之间的**"桥梁"** 。并且从某种程度上讲,正是因为CLIP模型的前置出现,加速推动了AI绘画领域的繁荣。
那么,什么是CLIP呢?CLIP有哪些优良的性质呢?为什么是CLIP呢?
首先,CLIP模型是一个基于对比学习的多模态模型,主要包含Text Encoder和Image Encoder两个模型 。其中Text Encoder用来提取文本的特征,可以使用NLP中常用的text transformer模型作为Text Encoder;而Image Encoder主要用来提取图像的特征,可以使用CNN/Vision transformer模型(ResNet和ViT等)作为Image Encoder。与此同时,他直接使用4亿个图片与标签文本对数据集进行训练,来学习图片与本文内容的对应关系。
与U-Net的Encoder和Decoder一样,CLIP的Text Encoder和Image Encoder也能非常灵活的切换,庞大图片与标签文本数据的预训练赋予了CLIP强大的zero-shot分类能力。
灵活的结构,简洁的思想,让CLIP不仅仅是个模型,也给我们一个很好的借鉴,往往伟大的产品都是大道至简的。更重要的是,CLIP把自然语言领域的抽象概念带到了计算机视觉领域。
 CLIP模型训练使用的图片-文本对数据
CLIP模型训练使用的图片-文本对数据
CLIP在训练时,从训练集中随机取出一张图片和标签文本 ,接着CLIP模型的任务主要是通过Text Encoder和Image Encoder分别将标签文本和图片 提取embedding向量 ,然后用********余弦相似度(cosine similarity) 来比较两个embedding向量的相似性,以判断随机抽取的标签文本和图片是否匹配,并进行梯度反向传播,不断进行优化训练。
 CLIP模型训练示意图
CLIP模型训练示意图
上面讲了Batch为1时的情况,当我们把训练的Batch提高到 N 时,其实整体的训练流程是不变的。只是现在CLIP模型需要将N个标签文本和N个图片的两两组合预测出N^2个可能的文本-图片对的****余弦相似性******** ,即下图所示的矩阵。这里共有N个正样本,即真正匹配的文本和图片(矩阵中的对角线元素),而剩余的N**^** 2−N个文本-图片对为负样本,这时CLIP模型的训练目标就是最大化N个正样本的余弦相似性,同时最小化N^2−N个负样本的余弦相似性。
 Batch为N时的CLIP训练示意图
Batch为N时的CLIP训练示意图
完成CLIP的训练后,输入配对的图片和标签文本,则Text Encoder和Image Encoder可以输出相似的embedding向量 ,计算余弦相似度就可以得到接近1 的结果。同时对于不匹配的图片和标签文本,输出的embedding向量计算余弦相似度则会接近0。
就这样,CLIP成为了计算机视觉和自然语言处理****自然语言处理****这两大AI方向的"桥梁",从此AI领域的多模态应用有了经典的基石模型。
上面我们讲到CLIP模型主要包含Text Encoder和Image Encoder两个部分 ,在Stable Diffusion中主要使用了Text Encoder部分。CLIP Text Encoder模型将输入的文本Prompt进行编码,转换成Text Embeddings(文本的语义信息) ,通过U-Net 网络的CrossAttention模块【CrossAttention的K,V来自Text Embeddings,Q来自图像的 latent 特征】嵌入Stable Diffusion中作为Condition条件,对生成图像的内容进行一定程度上的控制与引导 ,目前SD模型使用的是CLIP ViT-L/14CLIP ViT-L/14中的Text Encoder模型。
CLIP ViT-L/14 中的Text Encoder是只包含Transformer结构的模型,一共由12个CLIPEncoderLayer 模块组成,模型参数大小是123M,具体CLIP Text Encoder模型结构如下图所示。其中特征维度为768,token数量是77,所以输出的Text Embeddings的维度为77x768。
CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)下图是Rocky梳理的Stable Diffusion CLIP Text Encoder的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习Stable Diffusion CLIP Text Encoder部分,相信大家脑海中的思路也会更加清晰:
 Stable Diffusion CLIP Text Encoder完整结构图
Stable Diffusion CLIP Text Encoder完整结构图
一般来说,我们提取CLIP Text Encoder模型最后一层特征作为CrossAttention模块的输入,但是开源社区的不断实践为我们总结了如下经验:当我们生成二次元内容时, 可以选择提取CLIP Text Encoder模型倒数第二层特征; 当我们生成写实场景内容时, 可以选择提取CLIP Text Encoder模型最后一层的特征。这让Rocky想起了SRGAN以及感知损失,其也是提取了VGG网络的中间层特征才达到了最好的效果,AI领域的"传承"与共性,往往在这些不经意间,让人感到人工智能的魅力与美妙。
由于CLIP训练时所采用的最大Token数是77,所以在SD模型进行前向推理时,当输入Prompt的Token数量超过77时,将通过Clip操作拉回77x768,而如果Token数不足77则会使用padding操作得到77x768。如果说全卷积网络的设计让图像输入尺寸不再受限,那么CLIP的这个设置就让输入的文本长度不再受限(可以是空文本)。无论是非常长的文本,还是空文本,最后都将得到一样维度的特征矩阵。
同时在SD模型的训练中,一般来说CLIP的整体性能是足够支撑我们的下游细分任务的,所以CLIP Text Encoder模型参数是冻结的,我们不需要对其重新训练。
【如果我们想要一个新的embeeding词对应新特征向量,可以进行Textual Inversion 或 embedding fine-tuning微调】
注意:
Textual Inversion 或 embedding fine-tuning 微调的部分并不是 Stable Diffusion 模型中的 CLIP Text Encoder ,而是训练新的词汇嵌入(embedding) ,这些嵌入会被用在 CLIP Text Encoder 的输入层,但CLIP Text Encoder 本身的参数是冻结的,并不会在这个过程中被调整。
在AIGC时代,我们使用语言文字表达的创意与想法,可以轻松让Stable Diffusion生成出一幅幅精美绝伦、创意十足、飞速破圈的图片。而这些背后,都有CLIP的功劳,CLIP不仅仅连接了文本和图像,也连接了AI行业与千万个需要生成图片和视频的行业,AI绘画的ToC普惠如此之强,Rocky认为CLIP就是那个"隐形冠军"。
微调文本映射
Textual Inversion 和 embedding fine-tuning
原始CLIP、BLIP
参考:万字长文解读深度学习------多模态模型CLIP、BLIP、ViLT-CSDN博客