AIGC专栏17------EasyAnimate V5版本详解 应用MMDIT结构,拓展模型规模到12B 支持不同控制输入的控制模型
- 学习前言
- 相关地址汇总
- 测试效果
-
- [Image to Video](#Image to Video)
- [Text to Video](#Text to Video)
- EasyAnimate详解
- 项目使用
学习前言
前段时间开源了CogVideoX-Fun,学习了很多CogVideoX的代码与思想理念,发现EasyAnimate之前的版本存在非常多不合理的地方,比如说embedding的添加方式、模型规模等。在这个基础上我们开发了EasyAnimateV5,提升了EasyAnimate系列的模型生成能力。
另外,筛选了一大批不同控制条件的视频,训练了带有不同控制能力的EasyAnimateV5模型。

相关地址汇总
源码下载地址
https://github.com/aigc-apps/EasyAnimate
HF测试链接
https://huggingface.co/spaces/alibaba-pai/EasyAnimate
感谢大家的关注。
测试效果
Image to Video











Text to Video









EasyAnimate详解
技术储备
Diffusion Transformer (DiT)
DiT基于扩散模型,所以不免包含不断去噪的过程,如果是图生图的话,还有不断加噪的过程,此时离不开DDPM那张老图,如下:
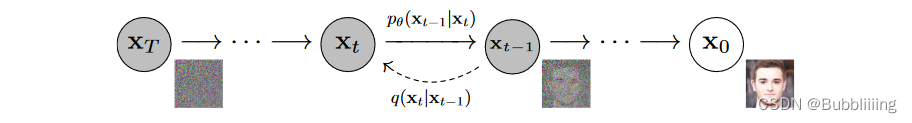
DiT相比于DDPM,使用了更快的采样器,也使用了更大的分辨率,与Stable Diffusion一样使用了隐空间的扩散,但可能更偏研究性质一些,没有使用非常大的数据集进行预训练,只使用了imagenet进行预训练。
与Stable Diffusion不同的是,DiT的网络结构完全由Transformer组成,没有Unet中大量的上下采样,结构更为简单清晰。
Stable Diffusion 3
在2024年3月,Stability AI发布了Stable Diffusion 3,Stable Diffusion 3一个模型系列,参数量从 800M 到 8B 不等。相比于过去的Stable Diffusion,Stable Diffusion 3的生图质量更高,且更符合人类偏好。
Stable Diffusion 3做了多改进,比如文本信息注入的方式,DiT模型在最初引入文本时,通常使用Cross Attention的方法结合文本信息,如Pixart-α、hunyuan DiT等。Stable Diffusion 3通过Self-Attention引入文本信息。相比于Cross Attention,使用Self-Attention引入文本信息不仅节省了Cross Attention的参数量,还节省了Cross Attention的计算量。
Stable Diffusion 3还引入了RMS-Norm。,在每一个attention运算之前,对Q和K进行了RMS-Norm归一化,用于增强模型训练的稳定性。
同时使用了更大的VQGAN,VQGAN压缩得到的特征维度从原来的4维提升到16维等。

CogVideoX

2024年8月,智谱开源视频生成模型CogVideoX,先是2B模型,而后是5B模型,近期还开源了V1.5的模型,几个视频生成模型能力都非常强悍,极大的提高了视频开源模型的水准。
CogVideoX主要具有以下特点:
- 自主研发了一套高效的三维变分自编码器结构(3D VAE)。降低了视频扩散生成模型的训练成本和难度。结合 3D RoPE 位置编码模块,该技术提升了在时间维度上对帧间关系的捕捉能力,从而建立了视频中的长期依赖关系。
- 拓展视频模型规模到5B,提升了模型的理解能力,使得模型能够处理超长且复杂的 prompt 指令。
- 模型与Stable Diffusion 3一致,将文本、时间、空间融合在一起,通过 Full Attention 机制优化模态间的交互效果。
算法细节
EasyAnimateV5特点
在EasyAnimateV5版本中,我们在大约10m SAM图片数据+26m 图片视频混合的预训练数据上进行了从0开始训练。与之前类似的是,EasyAnimateV5依然支持图片与视频预测与中文英文双语预测,同时支持文生视频、图生视频和视频生视频。
参考CogVideoX,我们缩短了视频的总帧数并减少了视频的FPS以加快训练速度,最大支持FPS为8,总长度为49的视频生成。我们支持像素值从512x512x49、768x768x49、1024x1024x49与不同纵横比的视频生成。
对比EasyAnimateV4,EasyAnimateV5还突出了以下特点:
- 应用MMDIT结构,拓展模型规模到12B。
- 支持不同控制输入的控制模型。
- 参考图片添加Noise。
- 更多数据和更好的多阶段训练。
应用MMDIT结构,拓展模型规模到12B
参考Stable Diffusion 3和CogVideoX,在我们的模型中,我们将文本和视频嵌入连接起来以实现Self-Attention,从而更好地对齐视觉和语义信息。然而,这两种模态的特征空间之间存在显著差异,这可能导致它们的数值存在较大差异,这并不利于二者进行对齐。
为了解决这个问题,还是参考Stable Diffusion 3,我们采用MMDiT架构作为我们的基础模型,我们为每种模态实现了不同的to_k、to_q、to_v和前馈网络(FFN),并在一个Self-Attention中实现信息交互,以增强它们的对齐。
另外,为了提高模型的理解能力,我们将模型进行了放大,参考Flux,我们模型的总参数量扩展到了12B。
添加控制信号的EasyAnimateV5
在原本Inpaint模型的基础上,我们使用控制信号替代了原本的mask信号,将控制信号使用VAE编码后作为Guidance与latent一起进入patch流程。该方案已经在CogVideoX-FUN的实践中证实有效。
我们在26m的预训练数据中进行了筛选,选择出大约443k高质量视频,同时使用不同的处理方式包含OpenPose、Scribble、Canny、Anime、MLSD、Hed和Depth进行控制条件的提取,作为condition控制信号进行训练。
在进行训练时,我们根据不同Token长度,对视频进行缩放后进行训练。整个训练过程分为两个阶段,每个阶段的13312(对应512x512x49的视频),53248(对应1024x1024x49的视频)。
以EasyAnimateV5-Control为例子,其中:
- 13312阶段,Batch size为128,训练步数为5k
- 53248阶段,Batch size为96,训练步数为2k。
工作原理图如下:

参考图片添加Noise
在CogVideoX-FUN的实践中我们已经发现,在视频生成中,在视频中添加噪声对视频的生成结果有非常大的影响。参考CogVideoX和SVD,在非0的参考图向上添加Noise以破环原图,追求更大的运动幅度。
我们在模型中为参考图片添加了Noise。与CogVideoX一致,在进入VAE前,我们在均值为-3.0、标准差为0.5的正态分布中采样生成噪声幅度,并对其取指数,以确保噪声的幅度在合理范围内。
函数生成与输入视频相同形状的随机噪声,并根据已计算的噪声幅度进行缩放。噪声仅添加到有效值(不需要生成的像素帧上)上,随后与原图像叠加以得到加噪后的图像。
另外,提示词对生成结果影响较大,请尽量描写动作以增加动态性。如果不知道怎么写正向提示词,可以使用smooth motion or in the wind来增加动态性。并且尽量避免在负向提示词中出现motion等表示动态的词汇。
Pipeline结构如下:

基于Token长度的模型训练
EasyAnimateV5的训练分为多个阶段,除了图片Adapt VAE的阶段外,其它阶段均为视频训练,分别对应了不同的Token长度。
图片VAE的对齐
我们使用了10M的SAM进行模型从0开始的文本图片对齐的训练,总共训练约120K步。
在训练完成后,模型已经有能力根据提示词去生成对应的图片,并且图片中的目标基本符合提示词描述。
视频训练
视频训练则根据不同Token长度,对视频进行缩放后进行训练。
视频训练分为多个阶段,每个阶段的Token长度分别是3328(对应256x256x49的视频),13312(对应512x512x49的视频),53248(对应1024x1024x49的视频)。
其中:
- 3328阶段
- 使用了全部的数据(大约26.6M)训练文生视频模型,Batch size为1536,训练步数为66.5k。
- 13312阶段
- 使用了720P以上的视频训练(大约17.9M)训练文生视频模型,Batch size为768,训练步数为30k
- 使用了最高质量的视频训练(大约0.5M)训练图生视频模型 ,Batch size为384,训练步数为5k
- 53248阶段
- 使用了最高质量的视频训练(大约0.5M)训练图生视频模型,Batch size为196,训练步数为5k。
训练时我们采用高低分辨率结合训练,因此模型支持从512到1280任意分辨率的视频生成,以13312 token长度为例:
- 在512x512分辨率下,视频帧数为49;
- 在768x768分辨率下,视频帧数为21;
- 在1024x1024分辨率下,视频帧数为9;
这些分辨率与对应长度混合训练,模型可以完成不同大小分辨率的视频生成。
项目使用
项目启动
推荐在docker中使用EasyAnimateV5:
sh
# pull image
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# enter image
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# clone code
git clone https://github.com/aigc-apps/EasyAnimate.git
# enter EasyAnimate's dir
cd EasyAnimate
# download weights
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
# Please use the hugginface link or modelscope link to download the EasyAnimateV5 model.
# I2V models
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP
# T2V models
# https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh
# https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh到这里已经可以打开gradio网站了。
文生视频
首先进入gradio网站。选择对应的预训练模型,如"models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512"。然后在下方填写提示词。
然后调整视频高宽和生成帧数,最后进行生成;


图生视频

图生视频与文生视频有两个不同点:
- 1、需要指定参考图;
- 2、指定与参考图类似的高宽;
CogVideoX-Fun的ui已经提供了自适应的按钮Resize to the Start Image,打开后可以自动根据输入的首图调整高宽。

视频生视频
视频生视频与文生视频有两个不同点:
- 1、需要指定参考视频;
- 2、指定与参考视频类似的高宽;
CogVideoX-Fun的ui已经提供了自适应的按钮Resize to the Start Image,打开后可以自动根据输入的视频调整高宽。

控制生视频
首先调整model type到Control,然后选择模型。
可修改prompt如下:
python
A person wearing a knee-length white sleeveless dress and white high-heeled sandals performs a dance in a well-lit room with wooden flooring. The room's background features a closed door, a shelf displaying clear glass bottles of alcoholic beverages, and a partially visible dark-colored sofa. 
然后修改为根据参考视频自动resize。

最后上传控制视频,进行生成。
