注意版本依赖【本实验版本如下】
Hadoop 3.1.1
spark 2.3.2
scala 2.111.依赖环境
1.1 java
安装java并配置环境变量【如果未安装搜索其他教程】
环境验证如下:
C:\Users\wangning>java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)1.2 hadoop安装
下载地址:https://hadoop.apache.org/releases.html
本案例下载:hadoop-3.1.1.tar.gz
或者直接访问:
https://hadoop.apache.org/release/3.1.1.html1.2.1 hadoop安装

环境变量新增:HADOOP_HOME 值,本地安装目录(根据实际更改)D:\apps\hadoop-3.3.6
path增加%HADOOP_HOME%\bin 和 %HADOOP_HOME%\sbin
验证hadoop是否安装好:
C:\Users\wangning>hadoop version
Hadoop 3.1.1
Source code repository https://github.com/apache/hadoop -r 2b9a8c1d3a2caf1e733d57f346af3ff0d5ba529c
Compiled by leftnoteasy on 2018-08-02T04:26Z
Compiled with protoc 2.5.0
From source with checksum f76ac55e5b5ff0382a9f7df36a3ca5a0
This command was run using /D:/apps/hadoop-3.1.1/share/hadoop/common/hadoop-common-3.1.1.jar1.2.2 修改hadoop配置文件
修改hadoop的配置文件,这些配置文件决定了hadoop是否能正常启动
配置文件的位置:在%HADOOP_HOME%\etc\hadoop\
core-site.xml, -- 是全局配置
hdfs-site.xml, --hdfs的局部配置。
mapred-site.xml -- mapred的局部配置。
a:在coresite.xml下的配置:
添加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>b: hdfs文件都可以建立在本地监听的这个服务下
在hdfs-site.xml下的配置:
添加
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/apps/hadoop-3.1.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/apps/hadoop-3.1.1/data/datanode</value>
</property>
</configuration>在Hadoop3.1.1的安装目录下新建data文件夹,再data下,新建namenode和datanode 文件夹,

yarn-site.xml下的配置:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml文件下的配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>1.2.3 配置文件下载
下载的hadoop安装包默认是在linux环境下运行的,如果需要在windows中启动,需要额外增加两个步骤
a、下载对应版本的bin文件包,替换本机hadoop安装目录下的bin包
https://github.com/cdarlint/winutilsb、将对应版本bin包中的hadoop.dll这个文件放在本机的C:\Windows\System32下

step4: 启动hadoop
进入sbin目录中,用 管理员模式启动cmd:
先初始化NameNode:hdfs namenode -format

再运行start-dfs.cmd,
再运行start-yarn.cmd
运行完上述命令,会出现2*2个窗口,如果没有报错继续,如果报错根据错误定位原因。
在cmd中输入jps,如果返回如下几个进程,就说明启动成功了

1.2.4 访问验证
http://localhost:8088 ------查看应用管理界面ResourceManager

http://localhost:9870 ------NameNode界面

1.3 Spark安装
spark下载路径:[根据自己的版本进行下载]
https://archive.apache.org/dist/spark/spark-2.3.2/
下载对应的预编译文件:[spark-2.3.2-bin-hadoop2.7.tgz]
下载后解压到路径,配置环境变量:
SPARK_HOME 变量值:Spark 的解压目录,例如 C:\Spark
编辑 Path,添加:%SPARK_HOME%\bin
验证 Spark:[cmd下执行:spark-shell]
C:\Users\wangning>spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://DESKTOP-8B1BDRS.mshome.net:4040
Spark context available as 'sc' (master = local[*], app id = local-1737362793261).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_261)
Type in expressions to have them evaluated.
Type :help for more informationui页面验证:http://localhost:4040
1.4 Scala安装
下载scala
https://www.scala-lang.org/download/2.11.0.html
下载后执行安装,比如安装目录为:D:\apps\scala-2.11.0

配置环境变量:
SCALA_HOME
配置完执行验证
C:\Users\wangning>scala -version
Scala code runner version 2.11.0 -- Copyright 2002-2013, LAMP/EPFL
C:\Users\wangning>scala
Welcome to Scala version 2.11.0 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_261).
Type in expressions to have them evaluated.
Type :help for more information.
scala> print("hello scala")
hello scala
scala>2. 创建scala项目
增加scala插件

2.1 项目初始化
对应的pom.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.3.2</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
</project>2.2 coding
Scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object WordCount_local {
def main(args: Array[String]) {
// if (args.length < 1) {
// System.err.println("Usage: <file>")
// System.exit(1)
// }
val conf = new SparkConf().setMaster("local").setAppName("HuiTest") //本地调试需要
// val conf = new SparkConf() //online
val sc = new SparkContext(conf)
// val line = sc.textFile(args(0)) //online
// val line = sc.textFile("hdfs://localhost:9000/user/words.txt") //本地调试
val line = sc.textFile("file:///D:/file/words.txt")
line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)
sc.stop()
}
}2.3 打包
- File->Project Structure



注意接下来删除除了jar包和compile output之外的所有jar,否则执行阶段会报错
执行相关操作:
C:\Windows\system32>hdfs dfs -ls hdfs://localhost:9000/
C:\Windows\system32>hdfs dfs -mkdir hdfs://localhost:9000/user/
C:\Windows\system32>hdfs dfs -ls hdfs://localhost:9000/
Found 1 items
drwxr-xr-x - wangning supergroup 0 2025-01-22 18:09 hdfs://localhost:9000/user
C:\Windows\system32>hdfs dfs -put D:/file/words.txt hdfs://localhost:9000/user/words.txt
put: `/file/words.txt': No such file or directory
C:\Windows\system32>hdfs dfs -put file:///D:/file/words.txt hdfs://localhost:9000/user/words.txt
C:\Windows\system32>
C:\Windows\system32>hdfs dfs -cat hdfs://localhost:9000/user/words.txt
hello
hello spark
hello redis
hello flink
hello doris
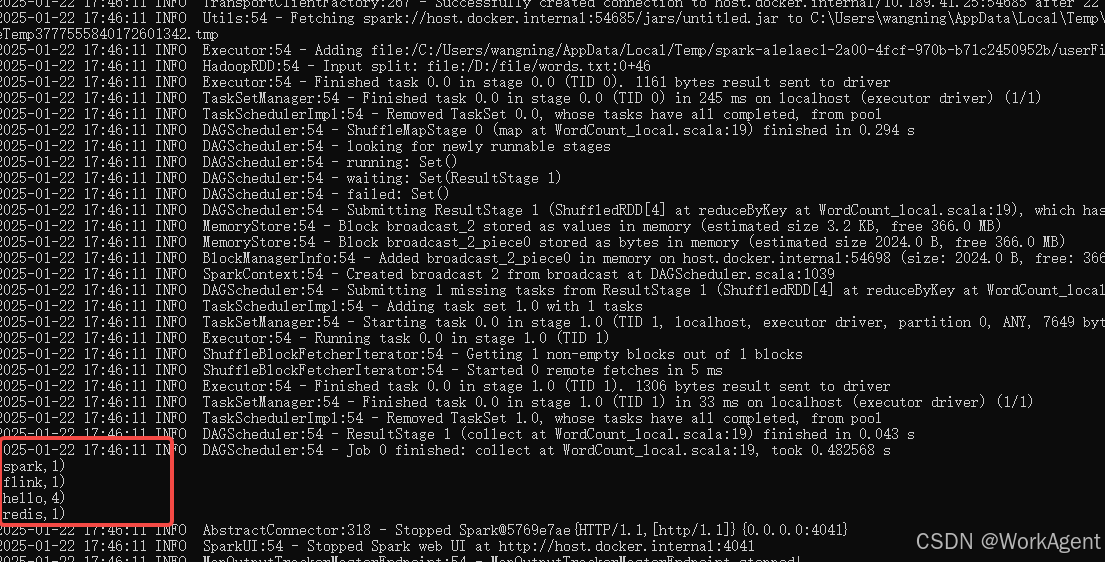
C:\Windows\system32>2.4 执行验证
cmd下执行:
Scala
# 查看编译是否成功
jar tf D:\code\testcode\t6\out\artifacts\untitled_jar\untitled.jar | findstr "WordCount_local"
# 运行代码
spark-submit --master local --name huihui --class WordCount_local D:\code\testcode\t6\out\artifacts\untitled_jar\untitled.jar查看运行结果如下: