遗传算法与深度学习实战(35)------使用遗传算法优化生成对抗网络
0. 前言
我们已经构建了用于编码深度卷积生成对抗网络 (Deep Convolutional Generative Adversarial Networks, DCGAN)的遗传编码器,优化封装的 DCGAN 类只需要定义用于演化的遗传算法参数,添加进化搜索能够对 GAN 网络进行自我优化。
1. 模型构建
(1) 导入执行遗传算法所需的库和工具:
python
from tensorflow.keras.datasets import mnist as data
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Activation, Flatten, Reshape, Dropout, ZeroPadding2D
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, UpSampling2D, Convolution2D
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras.initializers import RandomNormal
import tensorflow as tf
import tensorflow.keras.backend as K
import numpy as np
import matplotlib.pyplot as plt
from livelossplot import PlotLosses
from tqdm import tqdm_notebook
from IPython import display
from IPython.display import clear_output
import random
from tqdm.notebook import tqdm as tqdm
plt.gray()
from deap import algorithms
from deap import base
from deap import benchmarks
from deap import creator
from deap import tools
def extract(images, labels, class_):
labels = np.squeeze(labels)
idx = labels == class_
imgs = images[idx]
print(imgs.shape)
return imgs
(train_images, train_labels), (test_images, test_labels) = data.load_data()
# split dataset
#train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype("float32") / 255.0
print(train_images.shape)
train_images = extract(train_images, train_labels, 5)
plt.imshow(train_images[0])
# Rescale -1 to 1
train_images = (train_images.astype(np.float32) - 127.5) / 127.5
if len(train_images.shape)<4:
train_images = np.expand_dims(train_images, axis=3)
print(train_images.shape)
latent_dim = 100
channels = train_images.shape[3]
image_shape = (train_images.shape[1], train_images.shape[2], channels)
print(image_shape)
def clamp(num, min_value, max_value):
return max(min(num, max_value), min_value)
def linespace(v, minv, maxv):
range = maxv - minv
return v * range + minv
def linespace_int(v, minv, maxv):
range = maxv - minv
return clamp(int(v * range + minv), minv, maxv)
def reverse_space(x, minv, maxv):
range = maxv - minv
if range==0: return 0
return (x - minv) / range
FILTERS = 0
MIN_FILTERS = 16
MAX_FILTERS = 128
ALPHA = 1
MIN_ALPHA = .05
MAX_ALPHA = .5
CRITICS = 2
MIN_CRITICS = 1
MAX_CRITICS = 10
CLIP = 3
MIN_CLIP = .005
MAX_CLIP = .1
LR = 4
MIN_LR = .00000001
MAX_LR = .0001
FILTERS = 0
MIN_FILTERS = 16
MAX_FILTERS = 128
ALPHA = 1
MIN_ALPHA = .05
MAX_ALPHA = .5
CRITICS = 2
MIN_CRITICS = 1
MAX_CRITICS = 10
CLIP = 3
MIN_CLIP = .005
MAX_CLIP = .1
LR = 4
MIN_LR = .00000001
MAX_LR = .0001(2) 构建 DCGAN 模型。在 DCGAN 类的 __init__ 函数中,基因序列定义了模型中使用的每个超参数。首先,确保 image_shape 可被四整除并且可以适合于模型的卷积架构。接下来,每个超参数值都通过将浮点数映射到相应的空间生成。同时,在零值附近初始化权重,以更好地对齐权重与裁剪函数。最后,创建优化器,并构建模型:
python
class DCGAN:
def __init__(self, i):
'''
=== GLOBAL ===
image_shape=(32, 32, 1),
z_size=(1, 1, latent_dim),
=== ENCODED ===
n_filters=128,
alpha=0.2,
disc_iters=5
clip_lower=-0.01,
clip_upper=0.01,
lr=5e-5,
'''
assert image_shape[0] % 4 == 0, "Image shape must be divisible by 4."
self.image_shape = image_shape
self.z_size = (1, 1, latent_dim)
self.n_filters = linespace_int(i[FILTERS], MIN_FILTERS, MAX_FILTERS)
self.alpha = linespace_int(i[ALPHA], MIN_ALPHA, MAX_ALPHA)
self.lr = linespace(i[LR], MIN_LR, MAX_LR)
self.clip_lower = -linespace(i[CLIP], MIN_CLIP, MAX_CLIP)
self.clip_upper = linespace(i[CLIP], MIN_CLIP, MAX_CLIP)
self.critic_iters = linespace_int(i[CRITICS], MAX_CRITICS, MIN_CRITICS)
self.weight_init = RandomNormal(mean=0., stddev=0.02)
self.optimizer = tf.keras.optimizers.legacy.RMSprop(self.lr)
self.critic = self.build_critic()
self.g = self.build_generator()
self.gan = self.build_gan()
def build_critic(self):
model = Sequential(name="Critic")
model.add(Conv2D(self.n_filters//4, kernel_size=3, strides=2, input_shape=self.image_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(self.n_filters//2, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(self.n_filters, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(self.n_filters*2, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1))
img = Input(shape=self.image_shape)
validity = model(img)
model = Model(img, validity)
model.compile(loss=self.wasserstein_loss,
optimizer=self.optimizer,
metrics=['accuracy'])
return model
def build_generator(self):
model = Sequential(name="Generator")
cs = self.image_shape[1] // 4
model.add(Dense(self.n_filters * cs * cs, activation="relu", input_dim=latent_dim))
model.add(Reshape((cs, cs, self.n_filters)))
model.add(UpSampling2D())
model.add(Conv2D(self.n_filters, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(self.n_filters//2, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
noise = Input(shape=(latent_dim,))
img = model(noise)
return Model(noise, img)
def build_gan(self):
z = Input(shape=(latent_dim,))
img = self.g(z)
# For the combined model we will only train the generator
self.critic.trainable = False
# The discriminator takes generated images as input and determines validity
valid = self.critic(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
gan = Model(z, valid)
gan.compile(loss=self.wasserstein_loss, optimizer=self.optimizer)
return gan
def train(self, train_images, epochs=10, batch_size=128, verbose=0):
#track minium/maximum losses
min_g_loss = 1000
min_fake_loss = 1000
min_real_loss = 1000
max_g_loss = -1000
max_fake_loss = -1000
max_real_loss = -1000
# Adversarial ground truths
valid = -np.ones((batch_size, 1))
fake = np.ones((batch_size, 1))
batches = int(train_images.shape[0] / batch_size)
history = []
if verbose:
groups = { "Critic" : {"Real", "Fake"}, "Generator":{"Gen"}}
plotlosses = PlotLosses(groups=groups)
for e in range(epochs):
for i in tqdm(range(batches)):
for _ in range(self.critic_iters):
# ---------------------
# Train critic
# ---------------------
# Select a random half of images
idx = np.random.randint(0, train_images.shape[0], batch_size)
imgs = train_images[idx]
# Sample noise and generate a batch of new images
noise = np.random.normal(0, 1, (batch_size, latent_dim))
gen_imgs = self.g.predict(noise)
# Train the critic (real classified as ones and generated as zeros)
c_loss_real = self.critic.train_on_batch(imgs, valid)
c_loss_fake = self.critic.train_on_batch(gen_imgs, fake)
c_loss = 0.5 * np.add(c_loss_real, c_loss_fake)
#clip discriminator/critic weights
for l in self.critic.layers:
weights = l.get_weights()
weights = [np.clip(w, self.clip_lower, self.clip_upper) for w in weights]
l.set_weights(weights)
# ---------------------
# Train Generator
# ---------------------
# Train the generator (wants discriminator to mistake images as real)
g_loss = self.gan.train_on_batch(noise, valid)
min_g_loss = min(min_g_loss, g_loss)
min_fake_loss = min(min_fake_loss, c_loss[1])
min_real_loss = min(min_real_loss, c_loss[0])
max_g_loss = max(max_g_loss, g_loss)
max_fake_loss = max(max_fake_loss, c_loss[1])
max_real_loss = max(max_real_loss, c_loss[0])
loss = dict(
Real = reverse_space(c_loss[0],min_real_loss, max_real_loss),
Fake = reverse_space(c_loss[1],min_fake_loss, max_fake_loss),
Gen = reverse_space(g_loss, min_g_loss, max_g_loss) )
history.append(loss)
if verbose:
plotlosses.update(loss)
plotlosses.send()
self.plot_generated()
print(min_g_loss, max_g_loss, min_fake_loss, max_fake_loss, min_real_loss, max_real_loss)
return history
def wasserstein_loss(self, y_true, y_pred):
return K.mean(y_true * y_pred)
def plot_generated(self, n_ex=10, dim=(1, 10), figsize=(12, 2)):
noise = np.random.normal(0, 1, size=(n_ex, latent_dim))
generated_images = self.g.predict(noise)
generated_images = generated_images.reshape(n_ex, image_shape[0], image_shape[1])
plt.figure(figsize=figsize)
for i in range(generated_images.shape[0]):
plt.subplot(dim[0], dim[1], i+1)
plt.imshow((1-generated_images[i])*255, interpolation='nearest', cmap='gray_r')
plt.axis('off')
plt.tight_layout()
plt.show()
individual = np.random.random((10))
dcgan = DCGAN(individual)
dcgan.g.summary()
dcgan.critic.summary()
dcgan.gan.summary()
individual = np.random.random((5))
individual[FILTERS] = reverse_space(128, MIN_FILTERS, MAX_FILTERS)
individual[ALPHA] = reverse_space(.2, MIN_ALPHA, MAX_ALPHA)
individual[CLIP] = reverse_space(.01, MIN_CLIP, MAX_CLIP)
individual[CRITICS] = reverse_space(5, MIN_CRITICS, MAX_CRITICS)
individual[LR] = reverse_space(.00005, MIN_LR, MAX_LR)
print(individual)
dcgan = DCGAN(individual)
history = dcgan.train(train_images, verbose=1)
def loss(history, loss):
h = [i[loss] for i in history]
max_loss = max(h)
idx = h.index(max_loss)
return np.mean(h[idx:])
loss(history, "Real")2. 进化生成对抗网络
(1) 创建用于执行架构优化的遗传算法 (Genetic Algorithms, GA) 求解器,将适应度函数注册为 FunctionMin(),我们的目标是最小化适应度值:
python
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", list, fitness=creator.FitnessMin)
MIN_VALUE = 0.
MAX_VALUE = 1.
NDIM = 5
def uniform(low, up, size=None):
try:
return [random.uniform(a, b) for a, b in zip(low, up)]
except TypeError:
return [random.uniform(a, b) for a, b in zip([low] * size, [up] * size)]
toolbox = base.Toolbox()
toolbox.register("attr_float", uniform, MIN_VALUE, MAX_VALUE, NDIM)
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.attr_float)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutGaussian, mu=0.0, sigma=1, indpb=.1)
toolbox.register("select", tools.selTournament, tournsize=3)(2) 使用评估函数评估模型的适应度。首先,将个体转换为字符串,以便用作训练字典中的索引。将值四舍五入到小数点后一位,因此,起始值 [.2345868] 变成了 [.2],这简化了字典中的条目数量,这样做是为了将训练从无限的探索空间简化为有限的空间。确切地说,通过将值四舍五入到一位小数,在基因序列长度为 5 的情况下,可以确定有 10 × 10 × 10 × 10 × 10 = 100,000 种可能的模型要测试。这样做的真正好处在于,它允许进化更大的种群,而不必重新评估相似的个体,评估每个模型需要相当长的时间:
python
trained = {}
generation = 0
def evaluate(individual):
# absolute and clip values
ind = str([round(i, 1) for i in individual])
if ind in trained:
return trained[ind],
print(f"Generarion {generation} individual {ind}")
dcgan = DCGAN(individual)
history = dcgan.train(train_images, verbose=0)
min_loss_real = 1/loss(history, "Real")
min_loss_gen = 1/loss(history, "Gen")
min_loss_fake = loss(history, "Fake")
total = (min_loss_real + min_loss_gen + min_loss_fake)/3
print(f"Min Fitness {min_loss_real}/{min_loss_gen}:{total}")
trained[ind] = total
return total,
toolbox.register("evaluate", evaluate) (3) 优化 DCGAN 不仅仅是比较准确率的问题。我们需要考虑模型的三个损失,包括真实损失、伪造损失和生成损失。需要以不同的方式对这些损失进行优化,以将其最小化。提取每个损失,对真实损失和生成损失求倒后作为适应度的一部分,最终适应度是这两个值与伪造损失的平均值:
python
MU = 100 #@param {type:"slider", min:1, max:100, step:1}
NGEN = 5 #@param {type:"slider", min:1, max:10, step:1}
RGEN = 1 #@param {type:"slider", min:1, max:5, step:1}
CXPB = .6
MUTPB = .3
pop = toolbox.population(n=MU)
hof = tools.HallOfFame(1)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", np.mean)
stats.register("std", np.std)
stats.register("min", np.min)
stats.register("max", np.max)
best = None
groups = { "fitness" : {"min", "max"}}
plotlosses = PlotLosses(groups=groups)
for g in range(NGEN):
generation = g
pop, logbook = algorithms.eaSimple(pop, toolbox,
cxpb=CXPB, mutpb=MUTPB, ngen=RGEN, stats=stats, halloffame=hof, verbose=False)
best = hof[0]
print(f"Gen ({(g+1)*RGEN})")
for l in logbook:
plotlosses.update({'min': l["min"], 'max': l["max"]})
plotlosses.send() # draw, update logs, etc
dcgan = DCGAN(best)
dcgan.train(train_images, verbose=1)代码输出 DCGAN 进化出的最佳解决方案,进化优化需要较长时间运行,但最终会生成最佳 GAN:
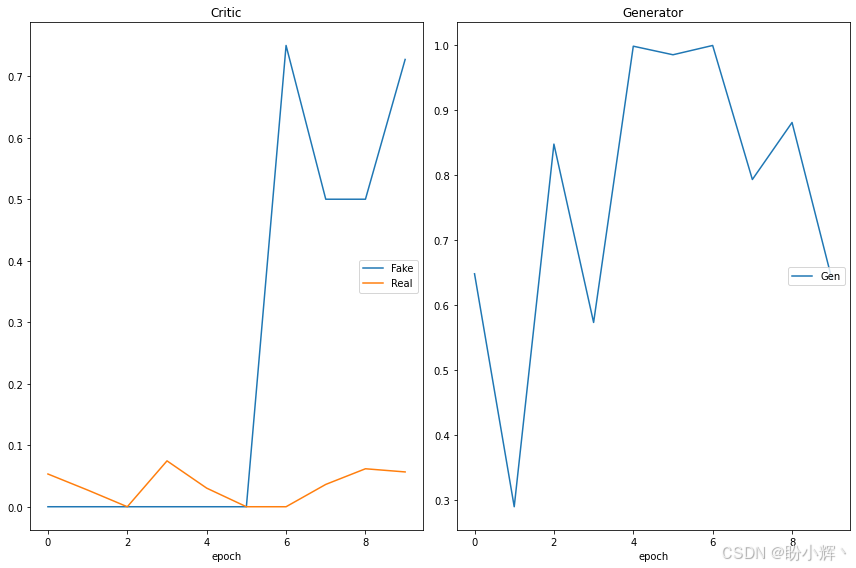
小结
进化对抗生成网络 (EvoGAN) 是一种结合了进化算法和对抗生成网络的模型。在本节中,我们通过优化封装的 DCGAN 类优化对抗生成网络模型。
系列链接
遗传算法与深度学习实战(1)------进化深度学习
遗传算法与深度学习实战(2)------生命模拟及其应用
遗传算法与深度学习实战(3)------生命模拟与进化论
遗传算法与深度学习实战(4)------遗传算法(Genetic Algorithm)详解与实现
遗传算法与深度学习实战(5)------遗传算法中常用遗传算子
遗传算法与深度学习实战(6)------遗传算法框架DEAP
遗传算法与深度学习实战(7)------DEAP框架初体验
遗传算法与深度学习实战(8)------使用遗传算法解决N皇后问题
遗传算法与深度学习实战(9)------使用遗传算法解决旅行商问题
遗传算法与深度学习实战(10)------使用遗传算法重建图像
遗传算法与深度学习实战(11)------遗传编程详解与实现
遗传算法与深度学习实战(12)------粒子群优化详解与实现
遗传算法与深度学习实战(13)------协同进化详解与实现
遗传算法与深度学习实战(14)------进化策略详解与实现
遗传算法与深度学习实战(15)------差分进化详解与实现
遗传算法与深度学习实战(16)------神经网络超参数优化
遗传算法与深度学习实战(17)------使用随机搜索自动超参数优化
遗传算法与深度学习实战(18)------使用网格搜索自动超参数优化
遗传算法与深度学习实战(19)------使用粒子群优化自动超参数优化
遗传算法与深度学习实战(20)------使用进化策略自动超参数优化
遗传算法与深度学习实战(21)------使用差分搜索自动超参数优化
遗传算法与深度学习实战(22)------使用Numpy构建神经网络
遗传算法与深度学习实战(23)------利用遗传算法优化深度学习模型
遗传算法与深度学习实战(24)------在Keras中应用神经进化优化
遗传算法与深度学习实战(25)------使用Keras构建卷积神经网络
遗传算法与深度学习实战(26)------编码卷积神经网络架构
遗传算法与深度学习实战(27)------进化卷积神经网络
遗传算法与深度学习实战(28)------卷积自编码器详解与实现
遗传算法与深度学习实战(29)------编码卷积自编码器架构
遗传算法与深度学习实战(30)------使用遗传算法优化自编码器模型
遗传算法与深度学习实战(31)------变分自编码器详解与实现
遗传算法与深度学习实战(32)------生成对抗网络详解与实现
遗传算法与深度学习实战(33)------WGAN详解与实现
遗传算法与深度学习实战(34)------编码WGAN