使用iOS个人声音与SoVITS训练个人AI语音(10分钟快速上手)

序言:最近在抖音上频繁看到曼波唱歌的视频和各种AI语音的搞笑短片,加上年后新购置的M2硬盘终于提供了足够的存储空间,让我有机会深入研究AI语音训练。24年年初我就想进行AI语音训练,但苦于语音素材难以获取,这次有了iOS收集素材就方便多了。在公司闲暇时,我摆弄着自己的iPhone 12,偶然发现了"个人声音"这一新功能,它允许用户在手机上训练一个基础的AI模型。我意识到可以将自己录制的150条语音导出,并通过查阅资料了解到可以利用SoVITS进行语音模型训练。因此,我撰写这篇教程,旨在记录并指导大家如何使用iOS手机收集语音素材,并利用SoVITS训练出属于自己的AI语音。
一、介绍
iOS 17引入的"个人声音"功能:允许用户通过录制一系列短语生成自定义语音,适用于语音助手、朗读文本等场景,特别适合有语言障碍的用户。该功能需在iOS 17及以上版本使用,注重隐私保护,所有数据处理均在设备本地完成。
GPT-SoVITS :由花儿不哭开发,是一款低成本AI音色克隆软件,目前支持TTS(文字转语音)功能,未来将支持变声功能。请注意,GPT-SoVITS的正确缩写是GSV,不要与So-VITS-SVC混淆。
PyCharm:JetBrains开发的Python IDE,提供代码编辑、调试等功能,支持跨平台使用,有免费社区版和付费专业版
二、训练准备
2.1 语音素材准备/导出
- 打开设置 -> 辅助功能 -> 个人声音。
- 如果没有个人声音,选择新建并按照系统指引录制素材。
- 录制完成后,点击导出录音,将压缩包复制到电脑。
2.2 下载GPT-SoVITS
点击此处,选择合适的方式进行下载。
三、开始训练
3.1 离线批量ASR
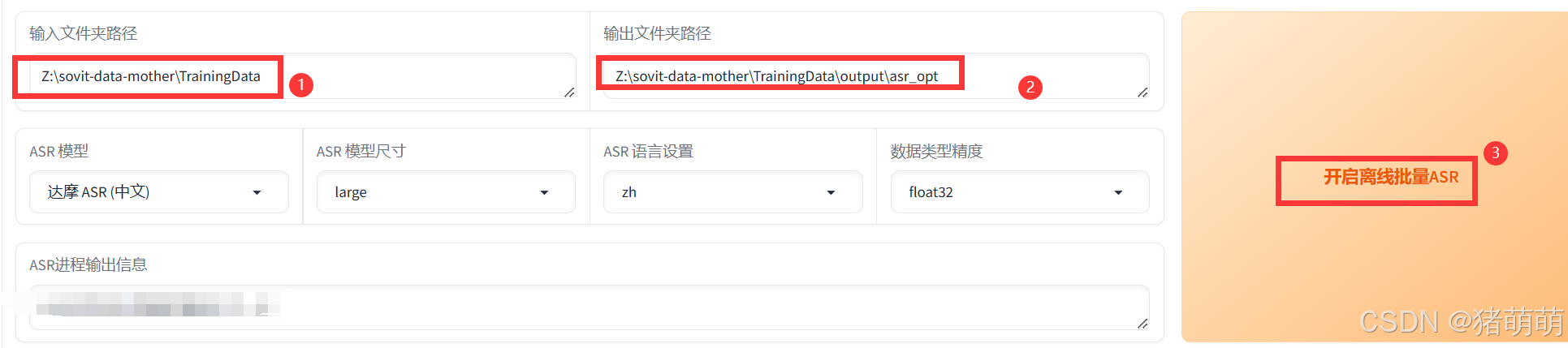
- 将导出的语音包解压到电脑(如
Z:\sovit-data-mother\TrainingData)。 - 运行
GPT-SoVITS-v2-240821中的go-webui.bat启动SoVITS。 - 在Web页面中找到"离线批量ASR"模块,输入语音包路径(如
Z:\sovit-data-mother\TrainingData)和输出路径(如Z:\sovit-data-mother\TrainingData\out\asr_opt)。 - 点击"开始离线批量ASR",等待任务完成。
当出现"ASR任务完成,查看终端进行下一步"时,ASR步骤结束。
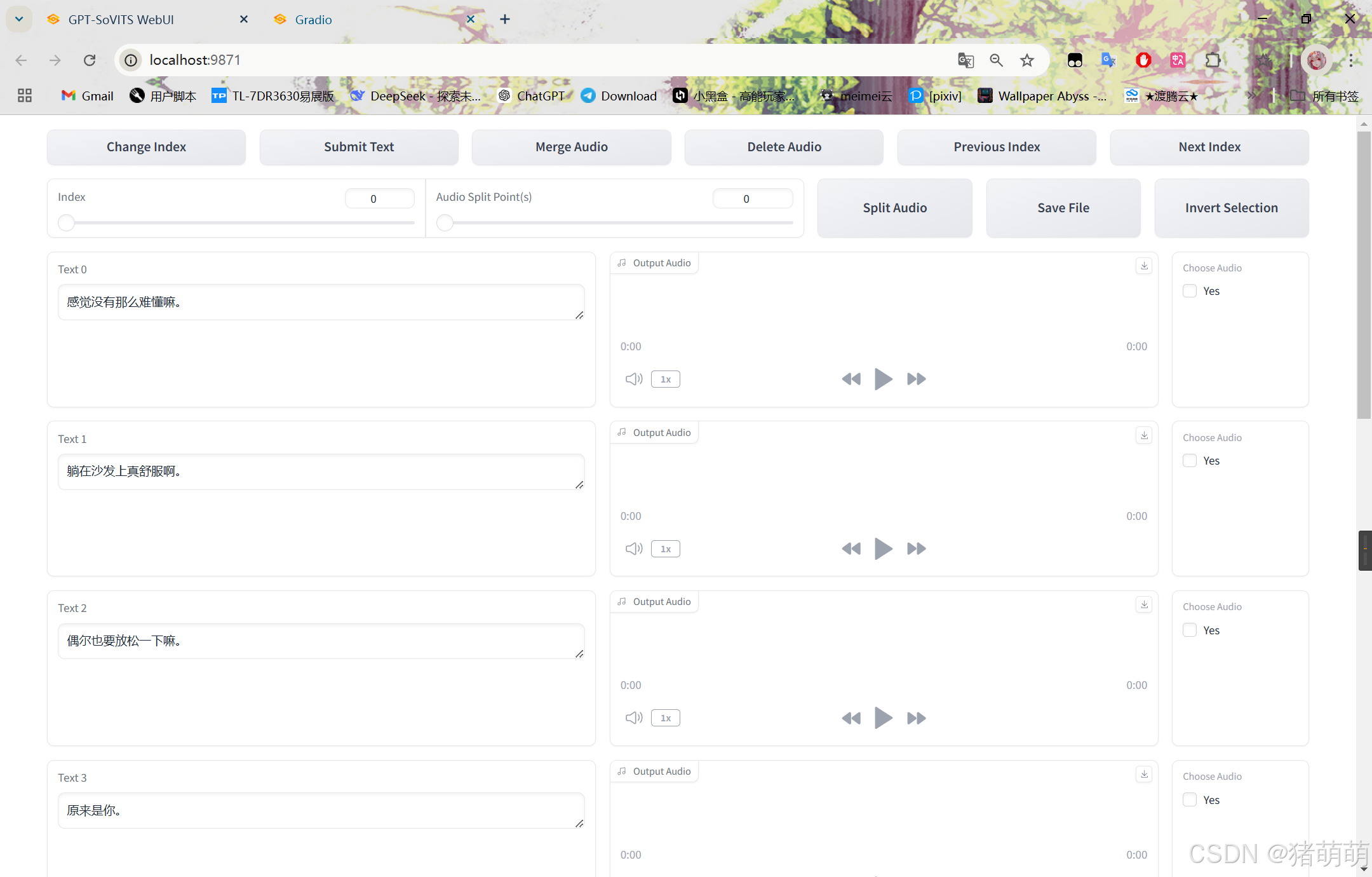
3.2 打标WebUI模块
我们视野转到打标WebUI模块

有两种方式处理打标(文字修正/打标)
3.2.1 通过开启打标WebUI对照metadata_data.json手动调整(不推荐)
点击开启打标WebUI,以记事本方式打开metadata_data.json。
注意!打开以后,每一行展开后的格式都为下边所示,找到每一行的关键词words 和utterance_name
json
{
"transcription":"S ... ~",
"sentence_idx":0,
"locale":"cmn-CN",
"sentence_estimated_duration":2.75,
phone_sequence:"S ...5",
"words":"时间不早了,今天先到这里吧。",
"utterance_name":"EExpG_4",
"script_title":"exclamations",
"paragraph_idx":4
}视野转到打标webUI,左边的text文本框中的文本内容有部分错误,按照metadata_data.json进行调整。
3.2.2 通过Pycharm执行python脚本批量处理打标。(推荐)
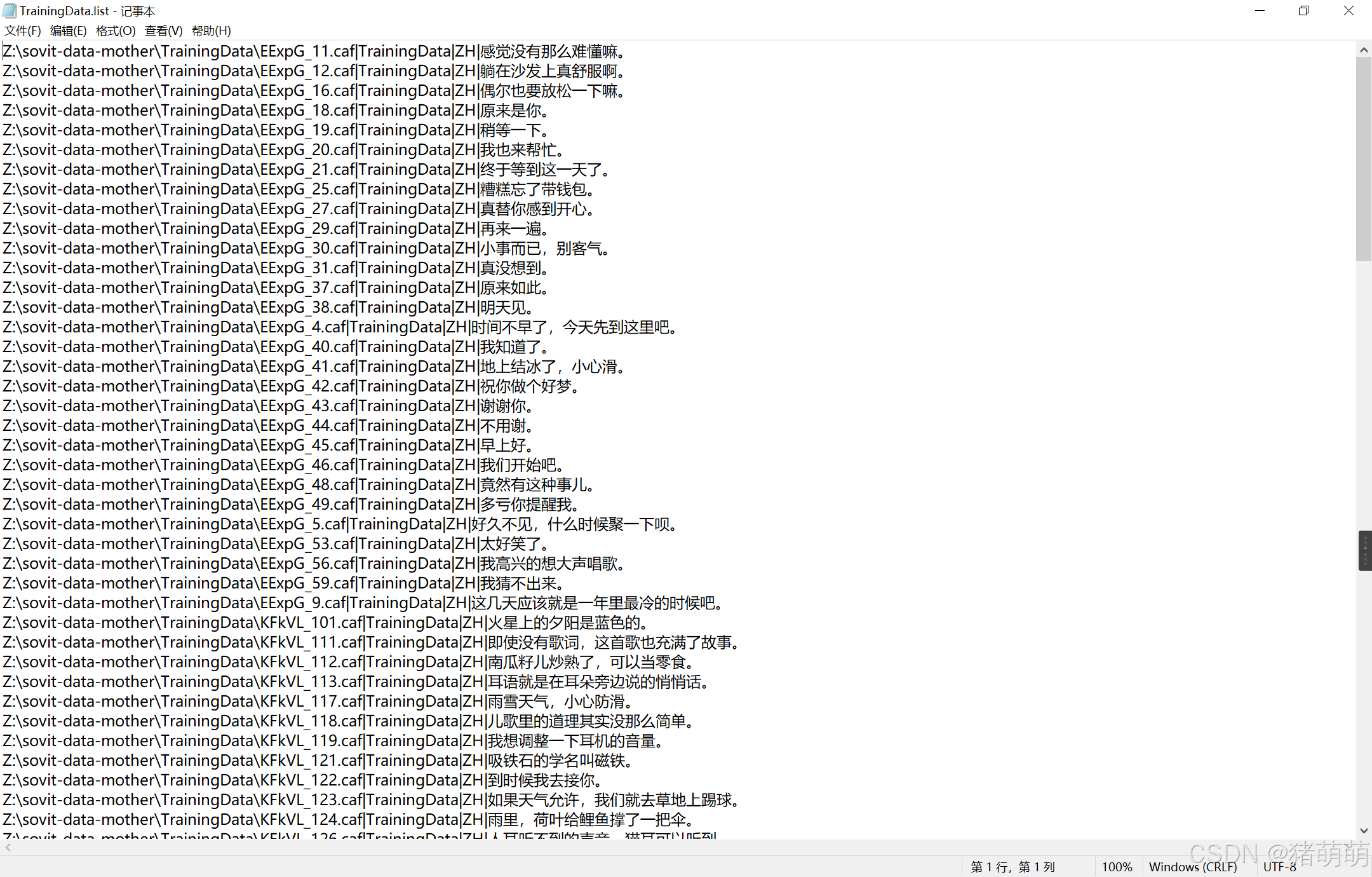
视野转到主页面中的打标webUI模块,注意下边的.list标注文件的路径

找到并打开TrainingData.list文件,以记事本方式打开,如下如图
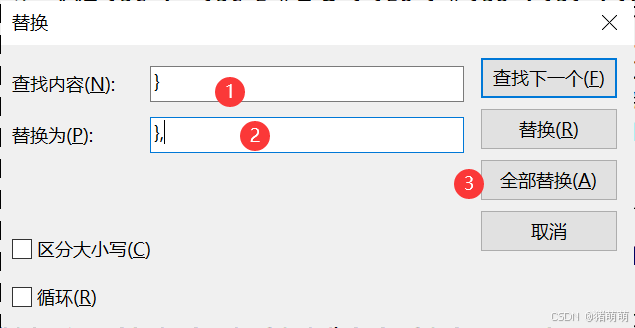
以记事本形式打开metadata_data.json ,在文件头键入' *** ',文件尾键入' *** ',使得***\[\]***将文件内容包裹住,如下图所示


然后点击替换,查找内容:' } ',替换为' }, ',点击全部替换。
打开Pycharm,新建py脚本文件,将下列代码复制粘贴,并执行:
python
import json
if __name__ == "__main__":
# 读取 JSON 文件,下边的路径填你自己的路径
with open('Z:\sovit-data-mother\TrainingData\metadata_data.json', 'r', encoding='utf-8') as file:
data = json.load(file)
# 遍历并提取 utterance_name 和 words
for item in data:
utterance_name = item.get('utterance_name')
words = item.get('words')
#下边的输出内容参考你自己的路径
if utterance_name and words:
print('Z:\sovit-data-mother\TrainingData\{}.caf|TrainingData|ZH|{}'.format(utterance_name,words))观察pycharm控制台输出如下:
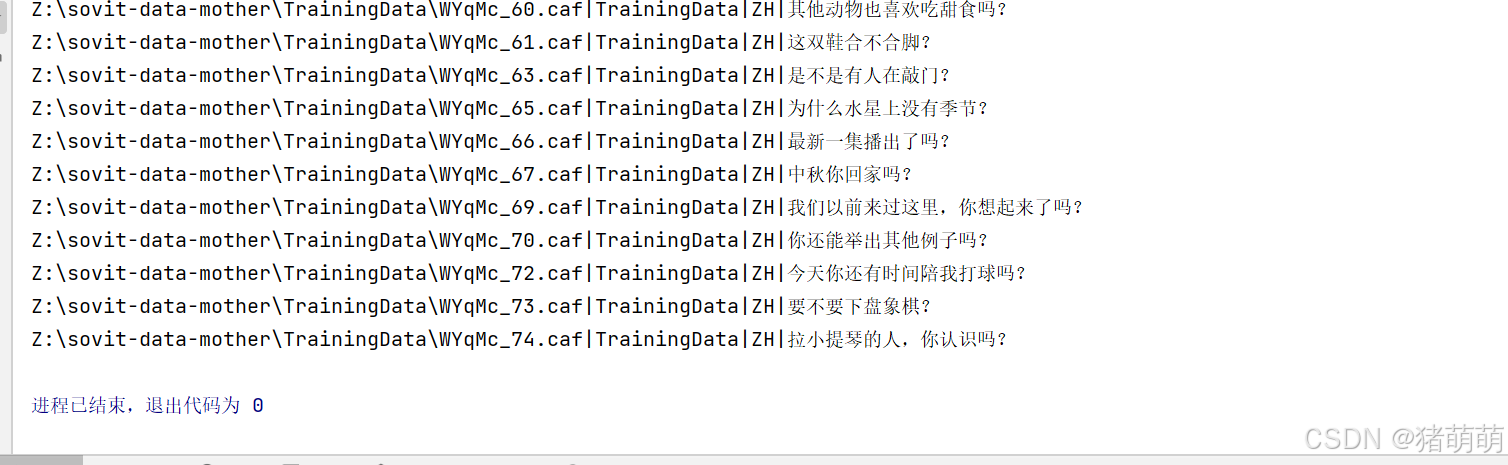
将内容复制到TrainingData.list,文件中进行覆盖保存。
4.1 进行1A-训练集格式化
视野回到首页,点击1-GPT-SoVITS-TTS,并输入你想要训练的模型名称。
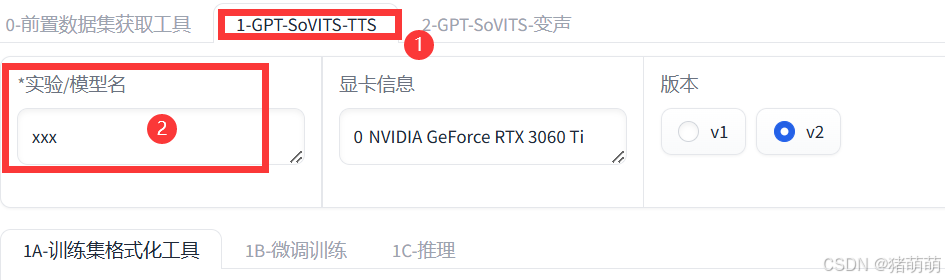
注意,文本标注文件以及训练集音频文件目录应该自动填充为你自己的相应链接,请查看对比。

直接点击一键三联!

观察到一键三连结束,即格式化结束。

4.2 进行1B-微调训练
点击切换到1B-微调训练。

按顺序点击SoVITS训练以及GPT训练,注意:一个训练完才能点下一个,除非你有多块显卡。
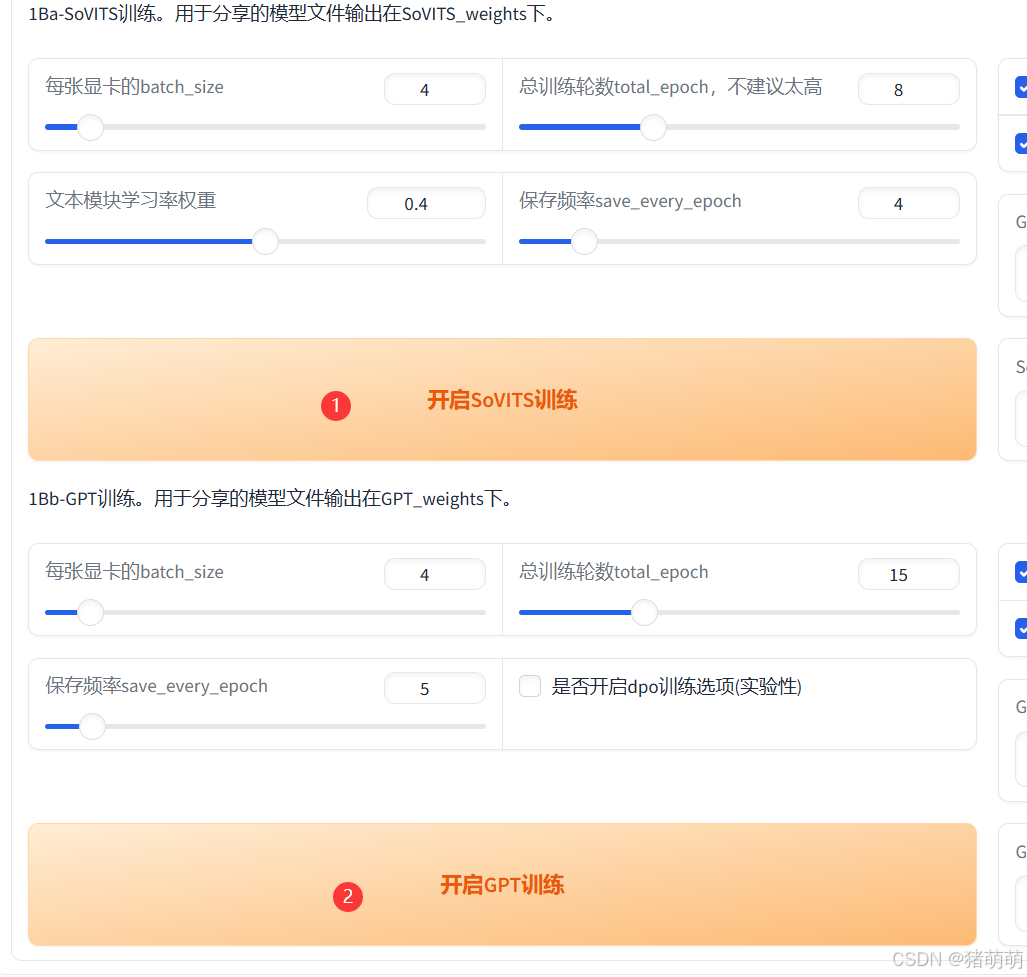
两个训练结束后,代表着你的模型训练完毕。
4.3 进行1C-推理(AI文字转语音)
接下来就是开始利用模型进行文字转语音操作,点击1C-推理,然后刷新模型,GPT模型列表和SoVITS模型列表选择你刚刚训练的模型。
勾选启用并行推理版本,点击开启TTS推理WebuUI。
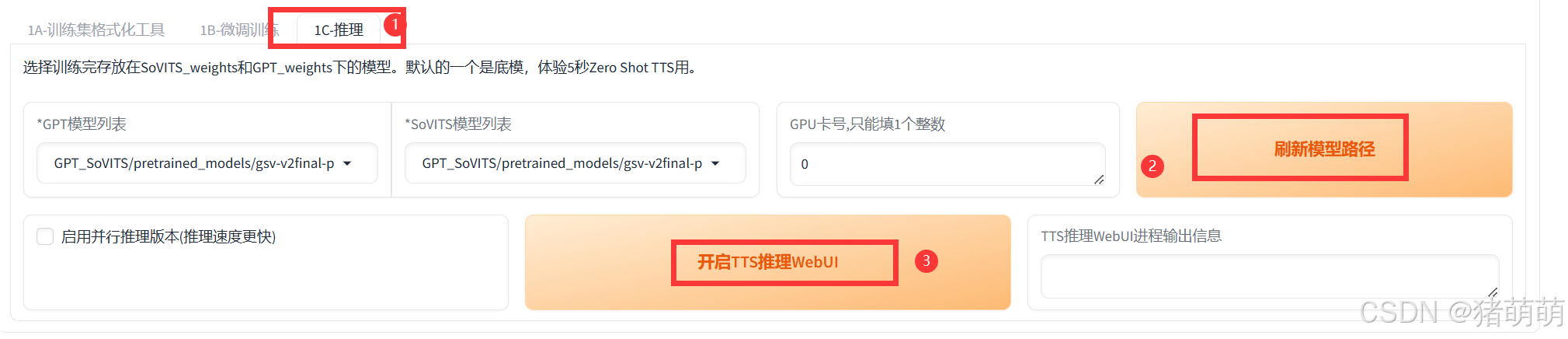
打开后的TTS推理WebUI,如下图所示:
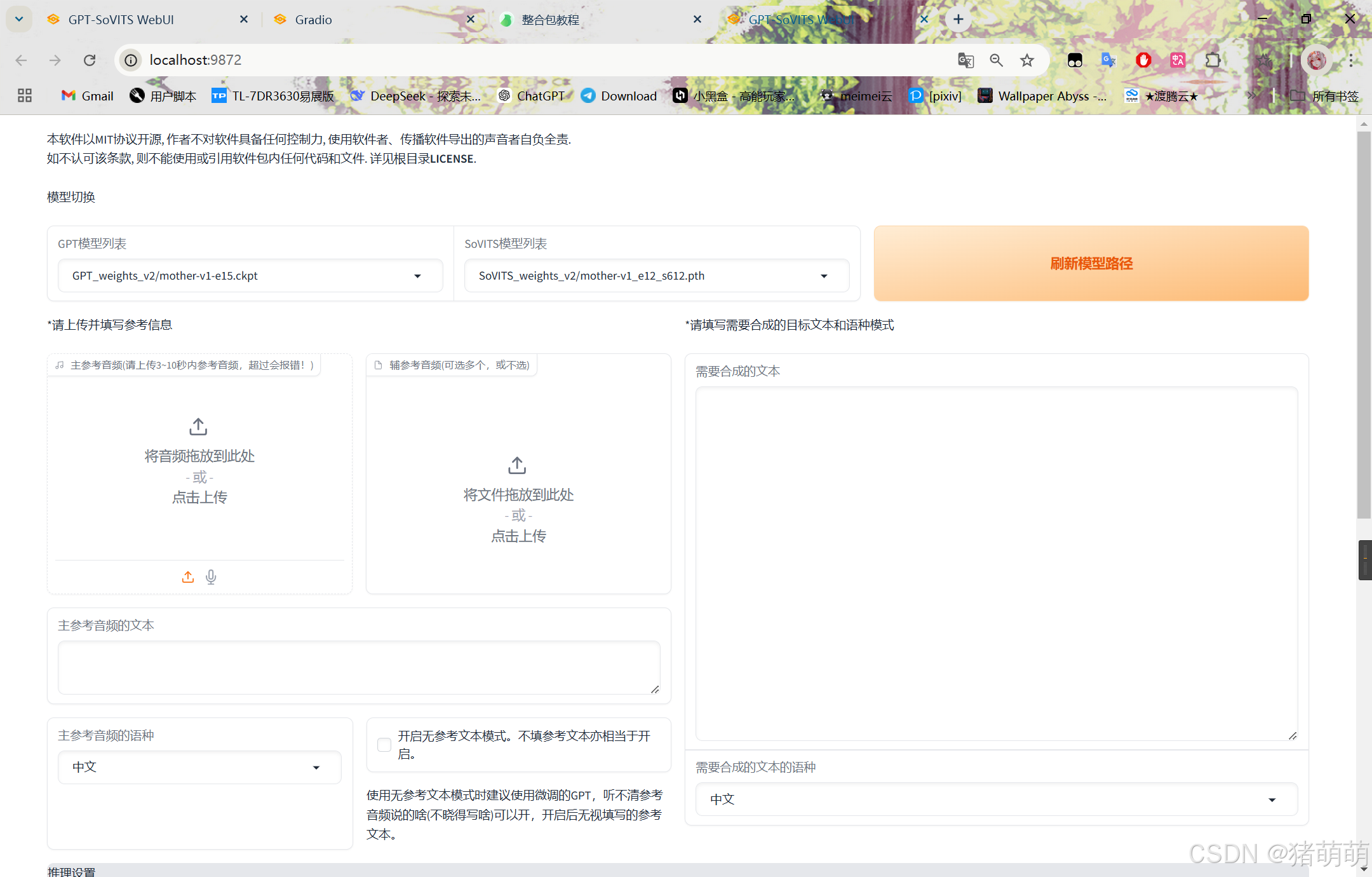
主参考音频主要控制语气,最好使用你自己素材包里的原语音素材,主参考音频的文本也是为了方便合成。
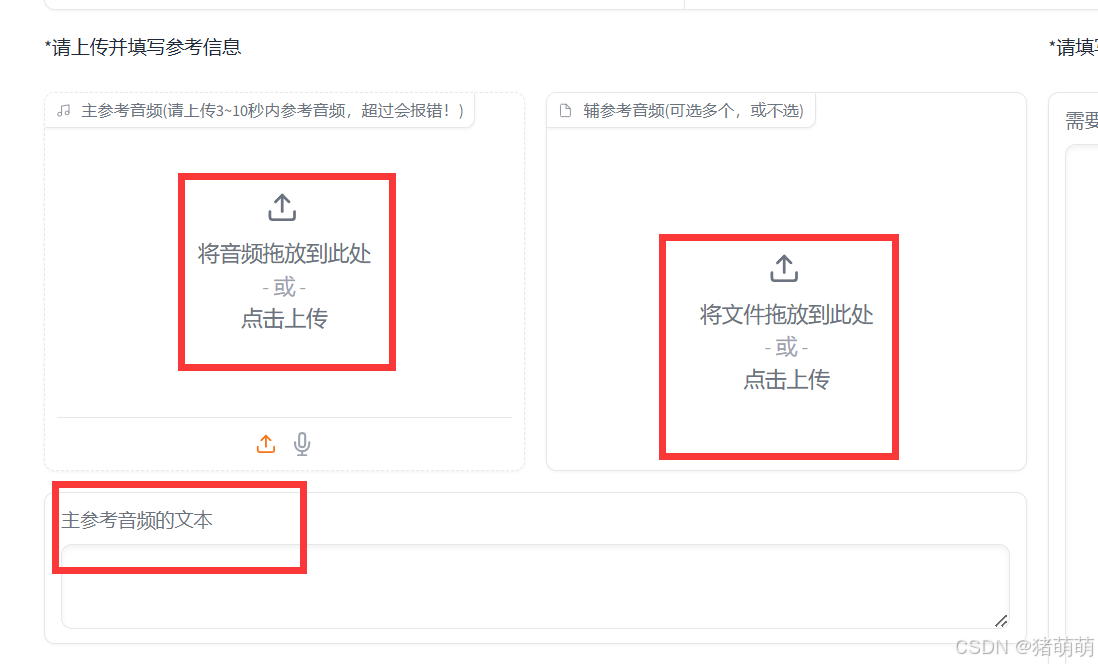
注意:主餐靠音频文本可填可不填,偏长的文字建议切分后再使用。
在右侧输出需要合成的文本后,点击下边的合成语音,即可试听。
本文不提供训练参数说明,请移步整合包教程,进行学习。😋