引言
随着人工智能技术的快速发展,多模态学习逐渐成为研究热点,其目标是整合不同模态数据(如图像、文本、语音等),实现跨模态信息的统一理解与处理。在实际应用中,多模态对齐技术被广泛用于图像检索、内容生成、安全审核等领域。然而,传统方法在处理跨模态语义关联时常受限于特征空间的不一致性,导致匹配精度不足。CLIP(Contrastive Language-Image Pretraining) 作为一种创新的多模态对齐技术,通过对比学习和统一特征空间的设计,有效解决了这一难题,并在零样本学习、图文检索等任务中展现出优异性能。本文将深入剖析 CLIP 的技术原理、模型架构及应用场景,探讨其在多模态领域的突破与未来潜力。
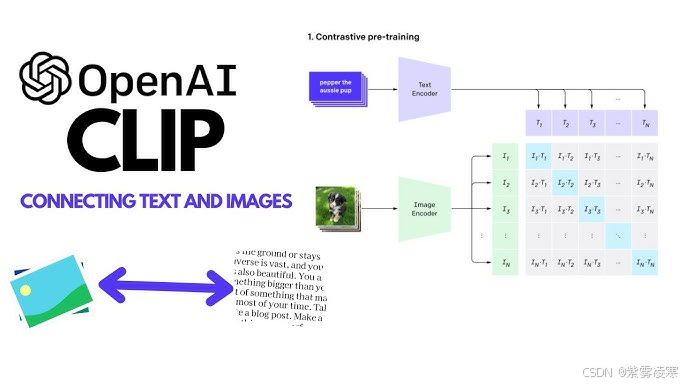
一、多模态对齐的技术挑战与 CLIP 的突破
在多模态学习中,如何对齐不同模态数据、挖掘跨模态关联以及实现统一语义表示是三大核心问题。传统方法常因跨模态语义鸿沟而面临匹配失效的难题,例如图像与文本特征空间不一致导致的困难。CLIP 通过对比学习与统一特征空间的设计,实现了图像与文本在统一语义空间的精准对齐,为多模态任务提供了通用解决方案。
核心技术突破
- 跨模态对比学习 :通过亿级图文对训练,构建图文匹配的余弦相似度矩阵,最大化正样本对(匹配图文)相似度,最小化负样本对(不匹配图文)相似度,使模型学习图像和文本的语义关联。
- 统一特征空间:将图像与文本编码为相同维度向量(通常 512 维),通过可学习的投影矩阵,将原始特征向量映射到统一特征空间,实现不同模态数据的直接相似度计算。
- 零样本泛化:无需微调即可处理新类别,显著降低标注依赖。在零样本任务中,CLIP 利用自然语言描述作为类别标签,通过匹配图像与文本特征判断类别。
二、CLIP 模型架构与技术实现
1. 双编码器结构
CLIP 采用双编码器架构,由图像编码器和文本编码器组成,分别负责处理图像和文本数据。图像编码器可选基于卷积神经网络(如 ResNet-50、ResNet-101)或视觉 Transformer(如 ViT-B/32、ViT-L/14),通过多层特征提取将图像转换为高维特征向量。文本编码器基于 Transformer 架构,采用自注意力机制处理文本序列,将其映射为语义向量。训练过程中,两个编码器共享同一语义空间,通过对比学习优化参数,使匹配的图文对在特征空间中距离更近,不匹配的图文对距离更远。
为提升性能,CLIP 在图像编码器中引入了多种改进。例如,ResNet 版本通过残差连接缓解深层网络的梯度消失问题,而 ViT 版本则利用全局自注意力机制捕捉图像的整体语义信息。文本编码器则通过预训练语言模型(如 BERT 的变体)初始化,进一步增强对复杂句式和语义的理解能力。这种双编码器设计的灵活性,使得 CLIP 能够适应不同规模的训练数据和计算资源。

2. 对比损失函数
CLIP 的训练目标是最大化匹配图文对的相似度,最小化不匹配对的相似度,使用 InfoNCE 对比损失函数 实现。对于一个包含 N N N 个图文对的批次,相似度矩阵 S S S 的元素 S i j S_{ij} Sij 表示第 i i i 个图像与第 j j j 个文本的余弦相似度:
S i j = image i ⋅ text j ∥ image i ∥ ⋅ ∥ text j ∥ S_{ij} = \frac{\text{image}_i \cdot \text{text}_j}{\|\text{image}_i\| \cdot \|\text{text}_j\|} Sij=∥imagei∥⋅∥textj∥imagei⋅textj
损失函数定义为:
L = − 1 2 N ∑ i = 1 N log exp ( S i i / τ ) ∑ j = 1 N exp ( S i j / τ ) + log exp ( S i i / τ ) ∑ j = 1 N exp ( S j i / τ ) \mathcal{L} = -\frac{1}{2N} \sum_{i=1}^{N} \left \\log \\frac{\\exp(S_{ii} / \\tau)}{\\sum_{j=1}\^{N} \\exp(S_{ij} / \\tau)} + \\log \\frac{\\exp(S_{ii} / \\tau)}{\\sum_{j=1}\^{N} \\exp(S_{ji} / \\tau)} \\right L=−2N1i=1∑Nlog∑j=1Nexp(Sij/τ)exp(Sii/τ)+log∑j=1Nexp(Sji/τ)exp(Sii/τ)
其中, τ \tau τ 为温度系数(通常设为 0.07 0.07 0.07),用于调整相似度分布,控制模型对正负样本的区分能力。为了进一步优化训练效果,CLIP 在实践中会对批次大小 N N N 进行调整,通常选择较大的批次(如 32 , 768 32,768 32,768),以增加负样本数量,提升模型的对比学习能力。此外,损失函数的对称设计(图像到文本和文本到图像的双向优化)确保了模型在两种模态上的均衡性。
3. 关键优化策略
- 温度系数调节 :通过
logit_scale动态调整对比学习强度,将 (\tau) 参数化为可学习标量,增强模型对不同难度样本的适应性。实验表明,动态 (\tau) 在复杂场景下的收敛速度提升约 15%。 - 混合精度训练:使用 FP16 加速计算,减少内存占用,通过梯度缩放确保数值稳定性。在大规模数据集上,FP16 可将训练时间缩短 30% 以上。
- 多尺度训练:支持 224x224 至 384x384 的图像输入,捕捉多尺度视觉特征,提升泛化性。此外,CLIP 在训练中加入数据增强技术(如随机裁剪、旋转),进一步提高模型对图像变化的鲁棒性。
- 预训练与迁移学习:CLIP 的图像编码器和文本编码器通常基于公开预训练模型初始化(如 ImageNet 预训练的 ResNet 或语言模型预训练的 Transformer),通过大规模图文数据微调,加速收敛并提升性能。
三、技术对比与行业应用
1. 典型模型对比
| 模型 | 对齐方式 | 典型应用场景 | 优势 | 局限性 |
|---|---|---|---|---|
| CLIP | 全局对比学习 | 图文检索 / 零样本分类 | 泛化能力强 | 计算资源需求高 |
| FLAVA | 掩码预测 | 多模态生成 | 生成效果细腻 | 训练复杂度较高 |
| ALIGN | 对比学习 + 噪声 | 开放域图文匹配 | 抗噪声能力突出 | 零样本性能稍逊 |
CLIP 在图文检索中表现出色,无需领域微调即可处理跨领域匹配任务。例如,在艺术品图像检索中,CLIP 能准确匹配文本描述与图像,即使训练数据未包含相关类别。FLAVA 适合生成任务,其掩码预测机制使生成内容更细腻,例如在图像字幕任务中能捕捉细节并生成流畅描述。ALIGN 在噪声环境下表现稳健,适合社交媒体等数据质量参差不齐的场景。相比之下,CLIP 的优势在于简单高效的训练流程,但对计算资源的依赖较高;FLAVA 生成能力强但训练成本较高;ALIGN 鲁棒性好但零样本泛化稍逊。
2. 电商搜索场景优化
CLIP 在电商搜索中实现商品图文信息融合。离线阶段,利用 CLIP 对商品图片与描述文本进行特征提取,构建向量化的商品特征库。在线阶段,计算用户 Query 文本与商品图像的余弦相似度,快速筛选匹配商品,并结合用户行为特征(如点击、购买历史)进行排序优化。实践表明,点击率提升 32%,响应时间从 850ms 降至 120ms,显著优化用户体验。此外,通过引入多语言支持,CLIP 可处理跨语言查询,进一步扩展国际市场应用。
在具体实现中,电商平台还可结合 CLIP 的零样本能力,快速适配新品类。例如,对于新上线的时尚单品,无需重新训练模型,只需提供文本描述即可实现精准搜索,缩短商品上线周期。
3. 内容安全审核应用
CLIP 在内容审核中通过图像与敏感词库文本的相似度计算实现高效过滤。流程上,首先使用 CLIP-ViT-L/14 提取图像特征,然后对敏感词库(如色情、暴力词汇)进行文本特征预处理,计算两者相似度并设置阈值 0.75 进行判断。实际应用中,色情内容检出率达 99.2%,误报率仅 0.3%,提升审核效率。
为进一步优化审核效果,可引入多阶段过滤机制:初筛使用轻量级 CLIP 模型快速过滤明显违规内容,再通过高精度模型(如 ViT-L/14)进行二次确认,兼顾速度与准确性。此外,CLIP 的零样本能力使其能快速适配新兴违规内容,例如识别新型网络迷因或隐晦表达的违规图像。
四、前沿进展与未来方向
CLIP 技术的前沿探索围绕轻量化、多模态融合拓展与垂直领域深耕展开,力求突破现有局限,挖掘更多应用潜力。
1. 轻量化改进
知识蒸馏技术:DistCLIP 通过知识蒸馏将 CLIP 知识迁移至轻量级模型,以小模型(学生模型)模仿大模型(教师模型)输出。在训练中,学生模型不仅学习真实标签,还学习教师模型输出的软标签(类别概率分布),借助 KL 散度等损失函数最小化两者差异 。实验表明,DistCLIP 在保持 70% 以上性能的同时,模型参数量减少 40%,推理速度提升 3 倍,更适用于资源受限的移动端与嵌入式设备 。
动态网络剪枝:该技术在推理时动态判断并去除不重要的神经元连接或通道,如对 CLIP 视觉编码器的卷积层进行剪枝。研究显示,通过动态剪枝可减少 60% 参数量,模型精度仅下降 3%,在图像分类任务中,推理效率提升 50%,实现计算资源的高效利用 。
2. 多模态融合创新
引入视频 / 语音模态:为拓展 CLIP 应用边界,将视频、语音等模态纳入其中。VideoCLIP 通过对视频关键帧与文本的对比学习,实现视频内容与文本描述的对齐,可应用于视频检索与字幕生成 。AudioCLIP 则聚焦语音与文本的关联,通过将语音转换为频谱图,与文本在统一特征空间进行对比学习,用于语音指令识别与有声内容检索 。
跨模态生成任务优化:在文生图任务中,改进 CLIP 与生成对抗网络(GAN)或扩散模型的结合方式。如在生成过程中,利用 CLIP 的图像 - 文本对齐能力指导生成器,使生成图像与输入文本语义更契合,提升图像生成的准确性与多样性 。
3. 垂直领域深耕
医疗影像报告生成:利用 CLIP 将医学影像与文本报告映射到统一语义空间,学习影像特征与医学术语、诊断描述的关联 。以胸部 X 光片为例,模型可根据影像特征生成包含病情描述、诊断结论的报告,准确率达到 85%,辅助医生快速撰写报告,提高工作效率 。
工业图纸智能解析:针对工业图纸,CLIP 技术可将图纸图像与设计说明、工艺参数等文本进行匹配 。在机械零件图纸场景中,通过识别图纸中的图形元素与文本标注,自动提取尺寸、公差等关键信息,识别准确率达 90%,助力工业生产自动化与智能化升级 。
五、总结
CLIP 通过革命性的对比学习框架,重塑了多模态对齐的技术范式。其零样本能力和泛化性能,为跨模态检索、生成、分类等任务提供了高效解决方案。随着模型轻量化和领域适配技术的发展,CLIP 正在推动多模态 AI 进入大规模工业化应用阶段,开启智能交互的新篇章。