Hive 是一个基于 Hadoop 的数据仓库工具,可以将结构化数据映射为一张数据库表,并提供 SQL 查询功能(称为 HiveQL)。它适合用于大数据场景下的数据分析和查询。
Hive 定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户直接查询Hadoop中的数据,同时,这个语言也允许熟悉MapReduce的开发者开发自定义的mapreduce任务来处理内建的SQL函数无法完成的复杂的分析任务。
Hive中包含的有SQL解析引擎,它会将SQL语句转译成M/R Job,然后在Hadoop中执行。
Hive可以通过sql查询Hadoop中的数据,并且sql底层也会转化成mapreduce任务,所以hive是基于hadoop的。
hive的系统架构如下
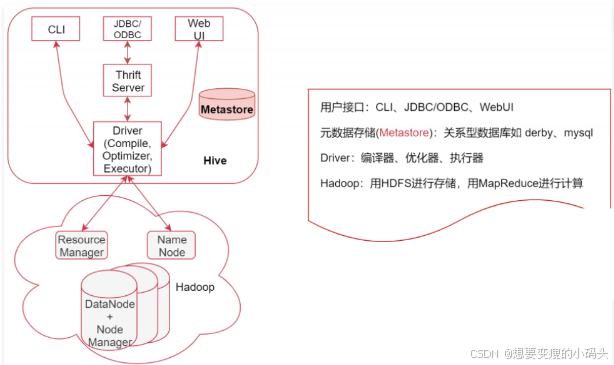
元数据存储(Metastore) ,注意:这里的存储是名词,Metastore表示是一个存储系统
Hive中的元数据包括表的相关信息,Hive会将这些元数据存储在Metastore中,目前Metastore只支持 mysql、derby。
Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在的hdfs目录等。Metastore默认使用内嵌的derby数据库。
Derby数据库的缺点:在同一个目录下一次只能打开一个会话,使用derby存储方式时,Hive会在当前目录生成一个derby.log文件和一个metastore_db目录,metastore_db里面会存储具体的元数据信息,没有办法使用之前的元数据信息了。
推荐使用MySQL作为外置存储引擎,可以支持多用户同时访问以及元数据共享。
Driver :包含:编译器、优化器、执行器
编译器、优化器、执行器可以完成 Hive的 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划最终存储在 HDFS 中,并在随后由 MapReduce 调用执行
Hadoop:Hive会使用 HDFS 进行存储,利用 MapReduce 进行计算。Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(特例 select * from table 不会生成 MapRedcue 任务,如果在SQL语句后面再增加where过滤条件就会生成MapReduce任务了。)
系统流程
用户通过接口传递Hive SQL,然后经过Driver对SQL进行分析、编译,生成查询计划,查询计划会存储在HDFS中,然后再通过MapReduce进行计算出结果,这就是整个大的流程。
在这个过程中,Hive是既不存储数据,也不计算数据,这些活都给了Hadoop来干,Hive底层最核心的东西其实就是Driver这一块,就是将SQL语句解析为最终的查询计划。
数据库 VS 数据仓库
数据库:传统的关系型数据库主要应用在基本的事务处理,例如银行交易之类的场景数据库支持增删改查这些常见的操作。
他是OLTP(On-Line Transaction Processing):操作型处理,称为联机事务处理,也可以称为面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性等问题,侧重于事务
数据仓库:主要做一些复杂的分析操作,侧重决策支持,相对数据库而言,数据仓库分析的数据规模要大得多。但是数据仓库只支持查询操作,不支持修改和删除。
他是OLAP(On-Line Analytical Processing):分析型处理,称为联机分析处理,一般针对某些主题历史数据进行分析,支持管理决策。侧重于分析
1. Hive 的核心概念
1.1 数据仓库
- Hive 是一个数据仓库工具,用于存储、管理和查询大规模数据。
- 它支持将结构化数据(如 CSV、JSON)映射为表,并提供类 SQL 的查询功能。
1.2 HiveQL
- HiveQL 是 Hive 的查询语言,语法类似于 SQL。
- 支持常见的 SQL 操作,如
SELECT、JOIN、GROUP BY等。
1.3 元数据存储
- Hive 使用元数据存储(Metastore)来管理表的结构信息(如表名、列名、数据类型等)。
- 元数据通常存储在关系型数据库(如 MySQL、PostgreSQL)中。
1.4 数据存储
- Hive 的数据存储在 HDFS(Hadoop 分布式文件系统)中。
- 支持多种文件格式,如文本文件、ORC、Parquet 等。
- 默认存在/user/hive/warehouse,在 hive-site.xml 中有一个参数 hive.metastore.warehouse.dir

这个下面有个默认数据库,default; 在元数据dbs表也可以看到
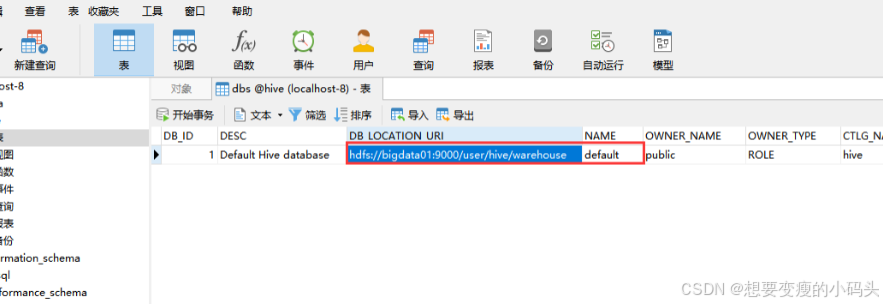
如果你不希望创建的数据库在这个目录下面,想要手工指定,那也是可以的,在创建数据库的时候通过location来指定hdfs目录的位置

2. Hive 的安装与配置
2.1 前置条件
- 已安装 Hadoop。
- 已安装 Java(推荐 JDK 1.8 或更高版本)。
- 已安装关系型数据库(如 MySQL)用于存储元数据。
2.2 下载 Hive
从 Apache Hive 官网下载 Hive:
选择适合的版本(如 apache-hive-3.1.2-bin.tar.gz)。
2.3 解压并配置
-
解压 Hive:
bashtar -zxvf apache-hive-3.1.2-bin.tar.gz -
配置环境变量:
编辑~/.bashrc或~/.zshrc文件,添加以下内容:bashexport HIVE_HOME=/path/to/hive export PATH=$PATH:$HIVE_HOME/bin然后执行:
bashsource ~/.bashrc -
配置 Hive:
-
复制配置文件模板:
bashcd $HIVE_HOME/conf cp hive-default.xml.template hive-site.xml -
修改
hive-site.xml,配置元数据存储(以 MySQL 为例):xml<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost/metastore?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>yourpassword</value> </property> -
将 MySQL 的 JDBC 驱动(如
mysql-connector-java-x.x.x.jar)复制到$HIVE_HOME/lib目录下。
-
2.4 初始化元数据
运行以下命令初始化元数据:
bash
schematool -initSchema -dbType mysql2.5 启动 Hive
运行以下命令启动 Hive CLI:
bash
hive3. Hive 的基本操作
3.0 命令行
一共有两种方式:第一个是使用bin目录下的hive命令,这个是从hive一开始就支持的使用方式
第二个是beeline命令,它是通过HiveServer2服务连接hive,它是一个轻量级的客户端工具,所以后来官方开始推荐使用这个。

hiveserver2默认会监听本机的10000端口,所以命令是 bin/beeline -u jdbc:hive2://localhost:10000
这样其实是以匿名用户的身份操作的,可能在操作一些文件的时候没有权限,所以可以启动的时候以root的身份启动:bin/beeline -u jdbc:hive2://localhost:10000 -n root
3.1 创建数据库
sql
CREATE DATABASE mydb;
USE mydb;3.2 创建表
sql
CREATE TABLE employee (
id INT,
name STRING,
salary FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;3.3 加载数据
将本地文件加载到 Hive 表中:
sql
LOAD DATA LOCAL INPATH '/path/to/employee.csv' INTO TABLE employee;3.4 查询数据
sql
SELECT * FROM employee;
SELECT name, salary FROM employee WHERE salary > 5000;3.5 删除表
sql
DROP TABLE employee;4. Hive 的高级功能
4.1 分区表
分区表可以提高查询效率,特别适合大规模数据。额外有一个分区字段:日期,国籍等,hive的表数据来源于hdfs,根据特性划分为:外部表和内部表,外部表删除不会影响到HDFS数据,内部表删除则会将HSFS的数据一并删除。分区表也分为:外部分区表和内部分区表
创建分区表:
sql
CREATE TABLE employee_partitioned (
id INT,
name STRING,
salary FLOAT
)
PARTITIONED BY (department STRING)
STORED AS TEXTFILE;加载数据到分区:
sql
LOAD DATA LOCAL INPATH '/path/to/hr_employee.csv' INTO TABLE employee_partitioned PARTITION (department='HR');
LOAD DATA LOCAL INPATH '/path/to/it_employee.csv' INTO TABLE employee_partitioned PARTITION (department='IT');查询分区数据:
sql
SELECT * FROM employee_partitioned WHERE department='HR';4.2 分桶表
分桶表可以将数据分散到多个文件中,一来避免数据倾斜,适合用于 JOIN 操作。
创建分桶表:
sql
CREATE TABLE employee_bucketed (
id INT,
name STRING,
salary FLOAT
)
CLUSTERED BY (id) INTO 4 BUCKETS
STORED AS TEXTFILE;加载数据到分桶表:
sql
INSERT INTO TABLE employee_bucketed SELECT * FROM employee;4.3 视图
视图的数据不存在HDFS中,视为一张虚拟的表。
创建视图:
sql
create view v1 as select t3_new.id,t3_new.stu_name from t3_nOKid stu_name4.4 复杂数据类型
Hive 支持复杂数据类型,如数组、Map 和结构体。
示例:
sql
CREATE TABLE employee_complex (
id INT,
name STRING,
skills ARRAY<STRING>,
details MAP<STRING, STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '|'
MAP KEYS TERMINATED BY ':'
STORED AS TEXTFILE;4.5 函数
视图的数据不存在HDFS中,视为一张虚拟的表。
topN:
一个典型的应用场景,分组排序取TopN操作,主要需要使用到ROW_NUMBER() 和 OVER()函数row_number和over函数通常搭配在一起使用。
row_number会对数据编号,编号从1开始。
over可以理解为把数据划分到一个窗口内,里面可以加上partition by,表示按照字段对数据进行分组,还可以加上order by 表示对每个分组内的数据按照某个字段进行排序。
row_number() 可以替换为 rank() 或者 dense_rank()。
其中: rank() 表示上下两条记录的score相等时,记录的行号是一样的,但下一个score值的行号递增N(N是重复的次数),比如:有两条并列第一,下一个是第三,没有第二
sql
-- 所有的学生的成绩按照 科目分组,倒序排列,编号
select *, row_number() over (partition by sub order by score desc) as num from student_score
-- 所有的科目前三名
select * from (
select *, row_number() over (partition by sub order by score desc) as num from student_score
) s where s.num<=3
-- 所有的学生的成绩按照 科目分组,倒序排列,编号(含并列)
-- row_number() over() 是正常排序
-- rank() over() 是跳跃排序,有两个第一名时接下来就是第三名(在各个分组内)
-- dense_rank() over() 是连续排序,有两个第一名时仍然跟着第二名(在各个分组内)
select *, rank() over (partition by sub order by score desc) as num from student_score
select *, dense_rank() over (partition by sub order by score desc) as num from student_score 行转列:
行转列就是把多行数据转为一列数据
针对行转列这种需求主要需要使用到 CONCAT_WS()、COLLECT_SET() 、COLLECT_LIST() 函数
CONCAT_WS() 函数可以实现根据指定的分隔符拼接多个字段的值,最终转化为一个带有分隔符的字符串它可以接收多个参数,第一个参数是分隔符,后面的参数可以是字符串或者字符串数组,最终就是使用分隔符把后面的所有字符串拼接到一块.
COLLECT_LIST()函数可以返回一个list集合,集合中的元素会重复,一般和group by 结合在一起使用
COLLECT_SET()函数可以返回一个set集合,集合汇中的元素不重复,一般和group by 结合在一起使用
行转列:
行转列就是把多行数据转为一列数据
针对行转列这种需求主要需要使用到 SPLIT()、EXPLODE()和LATERAL VIEW 函数
split函数,接受一个字串符和切割规则,就类似于java中的split函数,使用切割规则对字符串中的数据进行切割,最终返回一个array数组.
explode函数可以接受array或者map
-
explode(ARRAY) :表示把数组中的每个元素转成一行
-
explode(MAP) :表示把map中每个key-value对,转成一行,key为一列,value为一列
Lateral view 通常和split, explode等函数一起使用。
split可以对表中的某一列进行切割,返回一个数组类型的字段,explode可以对这个数组中的每一个元素转为一行,lateral view可以对这份数据产生一个支持别名的虚拟表
排序:
行转列就是把多行数据转为一列数据
ORDER BY
Hive中的order by跟传统的sql语言中的order by作用是一样的,会对查询的结果做一次全局排序,使用这个语句的时候生成的reduce任务只有一个。
SORT BY
Hive中指定了sort by,如果有多个reduce,那么在每个reducer端都会做排序,也就是说保证了局部有序(每个reducer出来的数据是有序的,但是不能保证所有的数据是全局有序的,除非只有一个reducer)
DISTRIBUTE BY
ditribute by:只会根据指定的key对数据进行分区,但是不会排序。一般情况下可以和sort by 结合使用,先对数据分区,再进行排序两者结合使用的时候distribute by必须要写在sort by之前.
CLUSTER BY
cluster by的功能就是distribute by和sort by的简写形式。也就是 cluster by id 等于 distribute by id sort by id。ps: 注意被cluster by指定的列只能是升序,不能指定asc和desc
Hive 的分组和去重函数
GROUP BY :对数据按照指定字段进行分组
DISTINCT:对数据中指定字段的重复值进行去重
5. Hive 的适用场景
- 数据仓库:适合构建企业级数据仓库。
- 数据分析:适合用于大规模数据的分析和查询。
- ETL 工具:适合用于数据抽取、转换和加载(ETL)任务。
总结
Hive 是一个强大的数据仓库工具,适合用于大数据场景下的数据分析和查询。