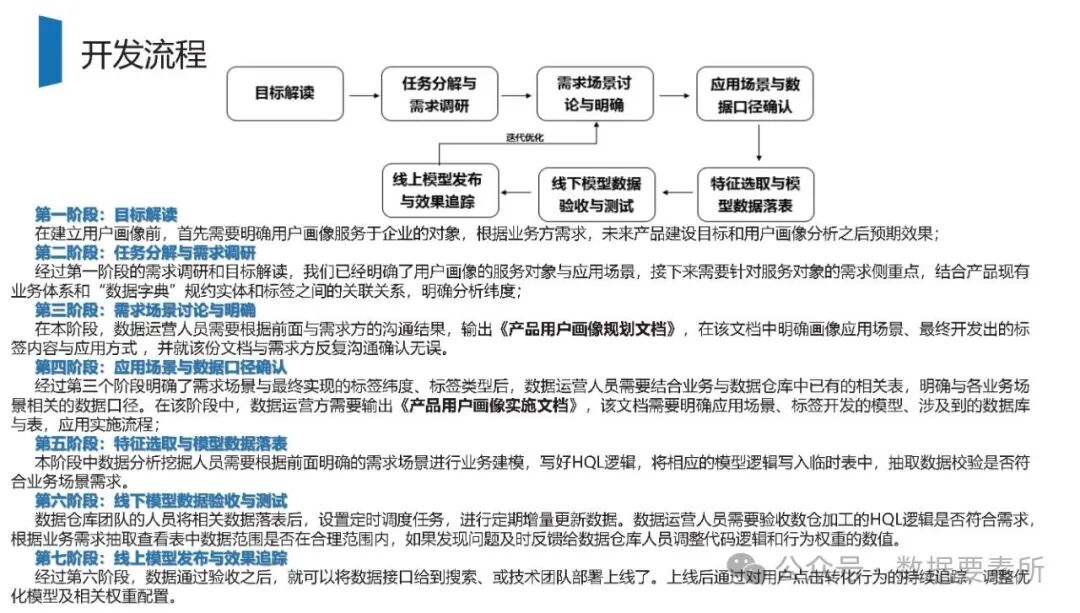
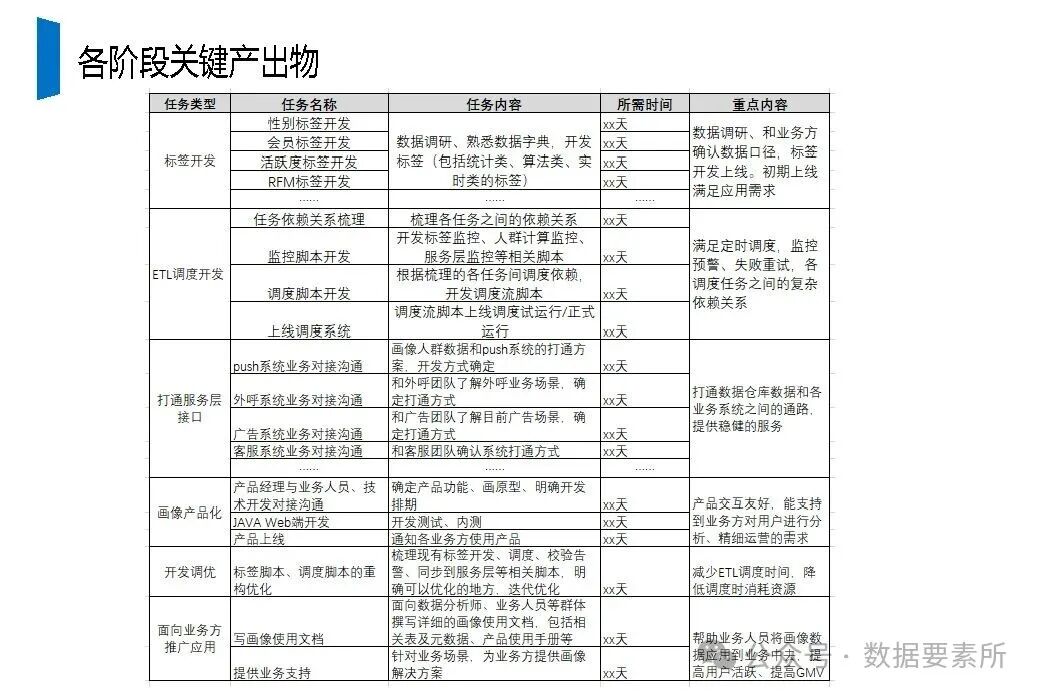
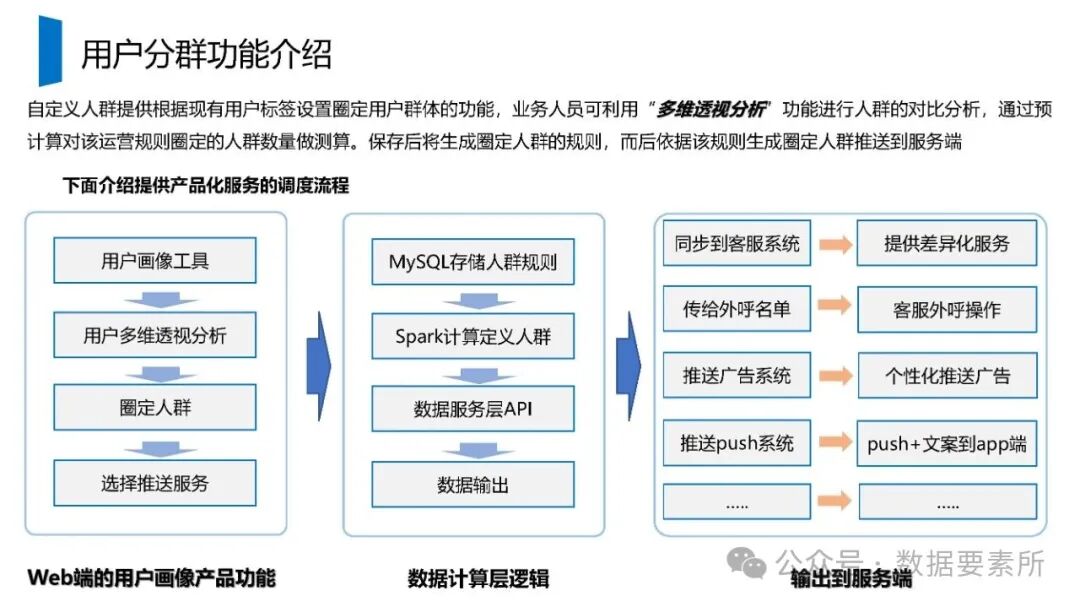
构建用户画像系统是一个涵盖数据架构、工程实现和业务应用的完整体系。其开发流程包含七个关键阶段:从目标解读、任务分解与需求调研,到需求场景明确、数据口径确认,再到特征选取与模型落表、线下验收测试,最终完成线上发布与效果追踪。
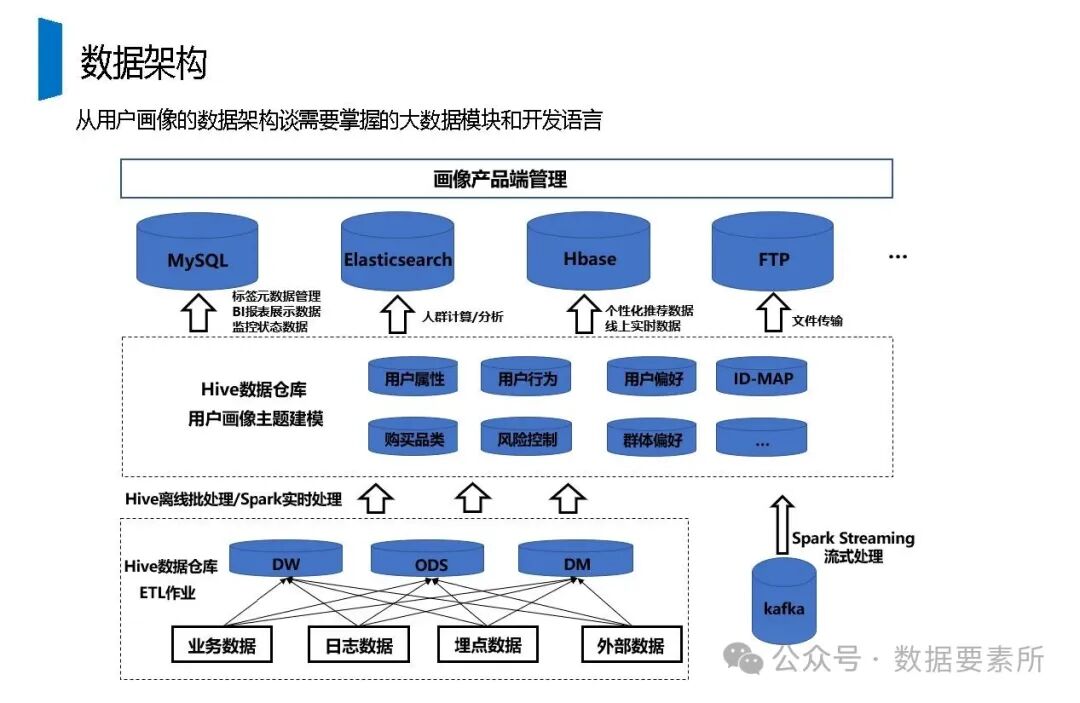
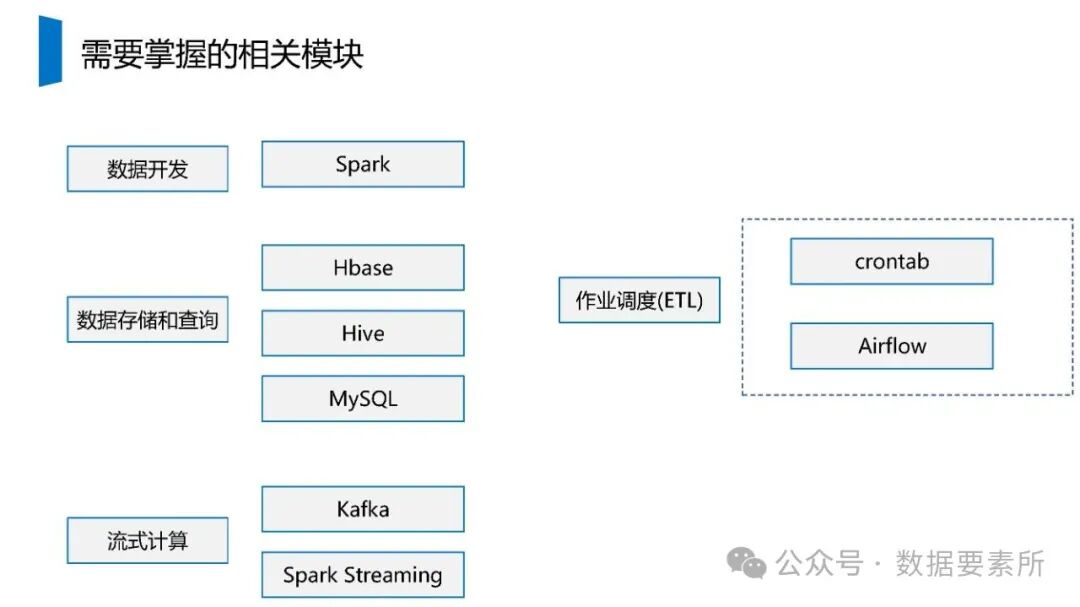
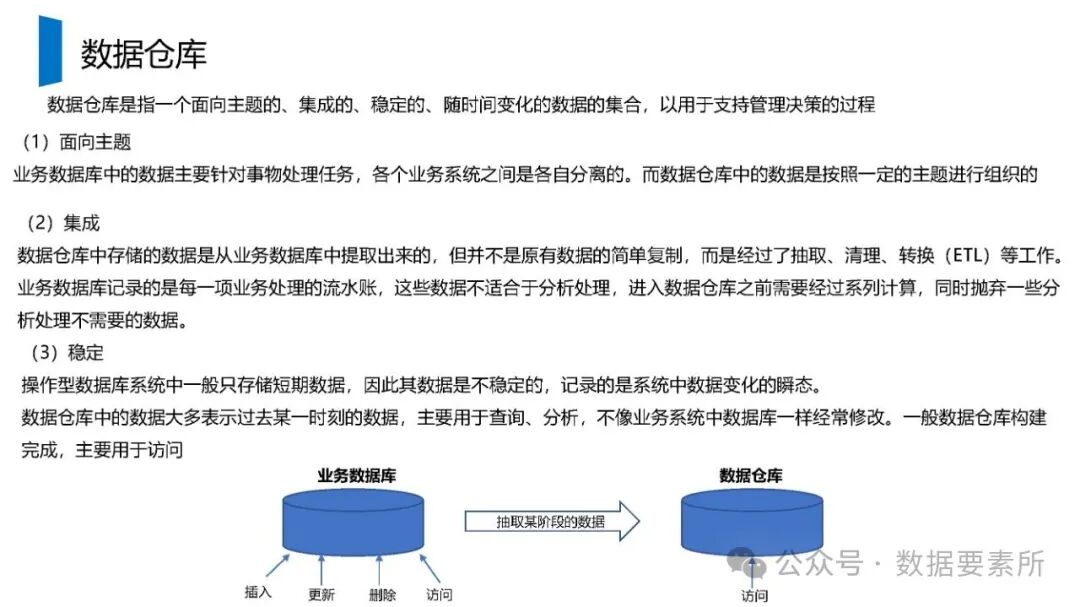
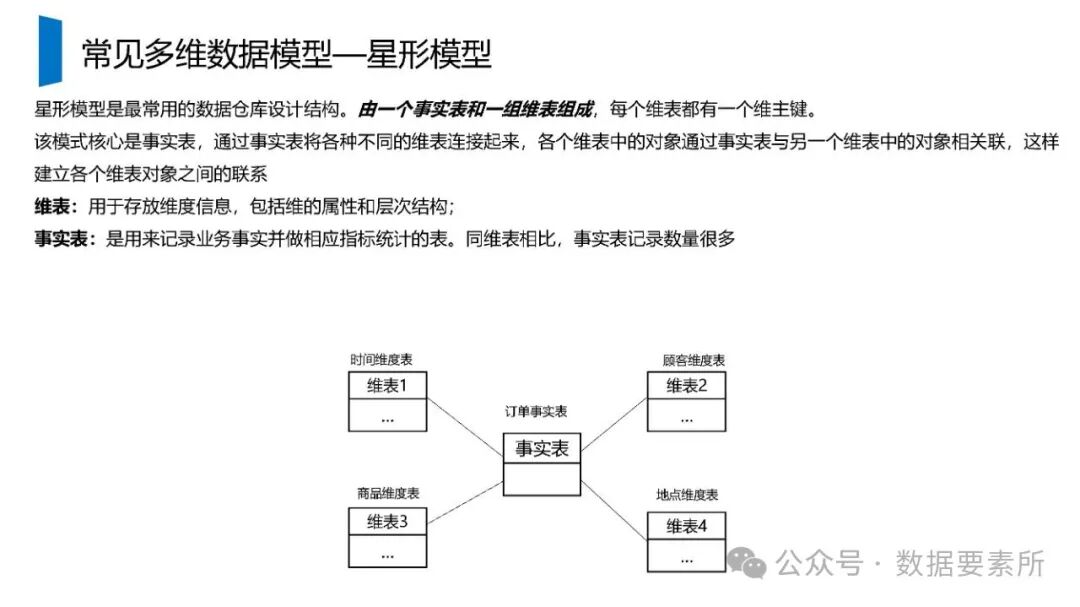
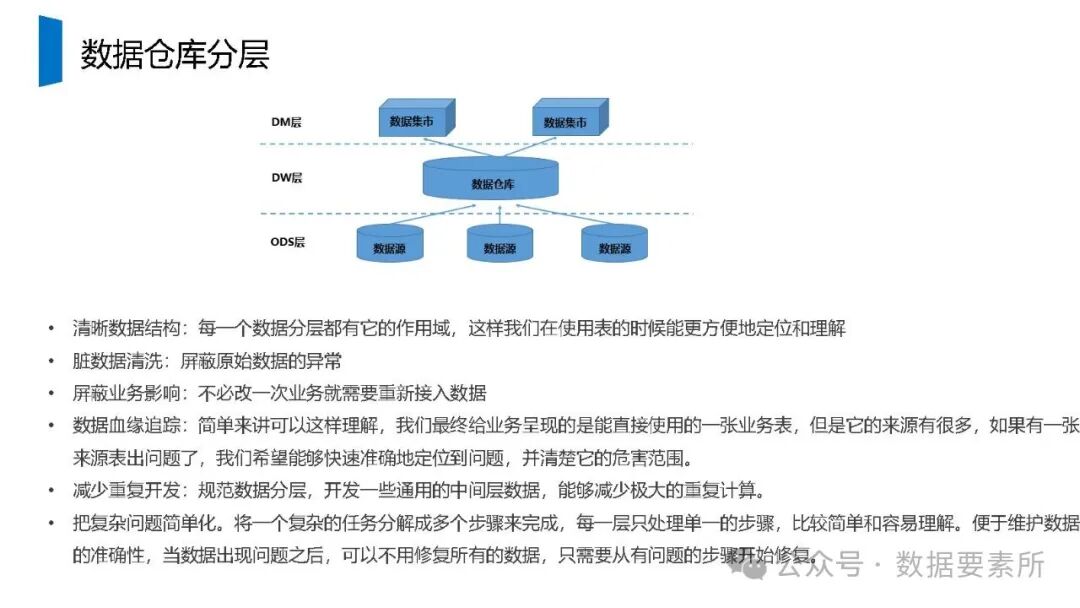
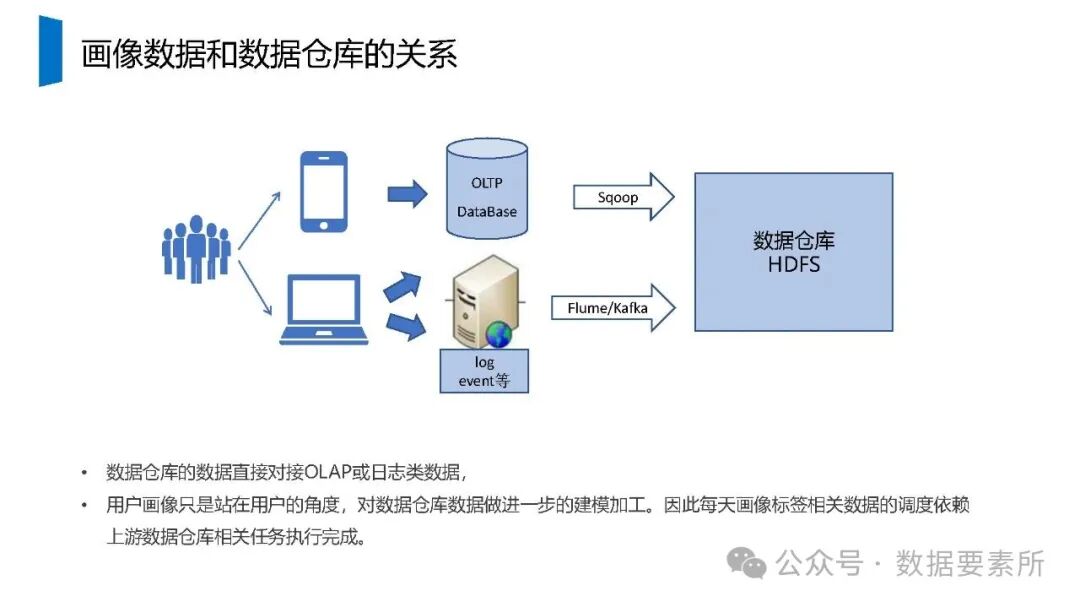
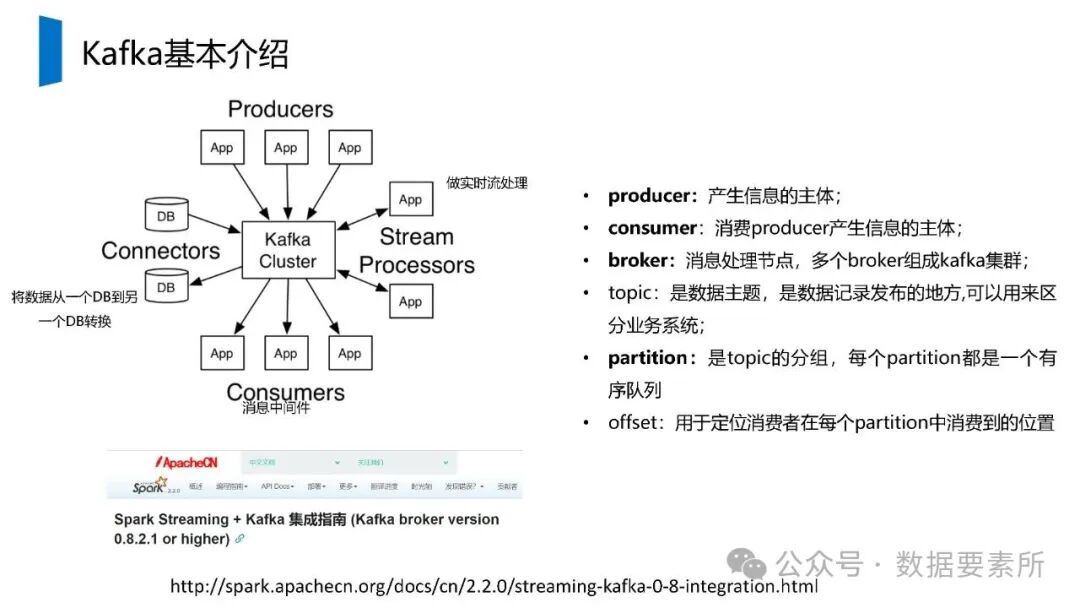
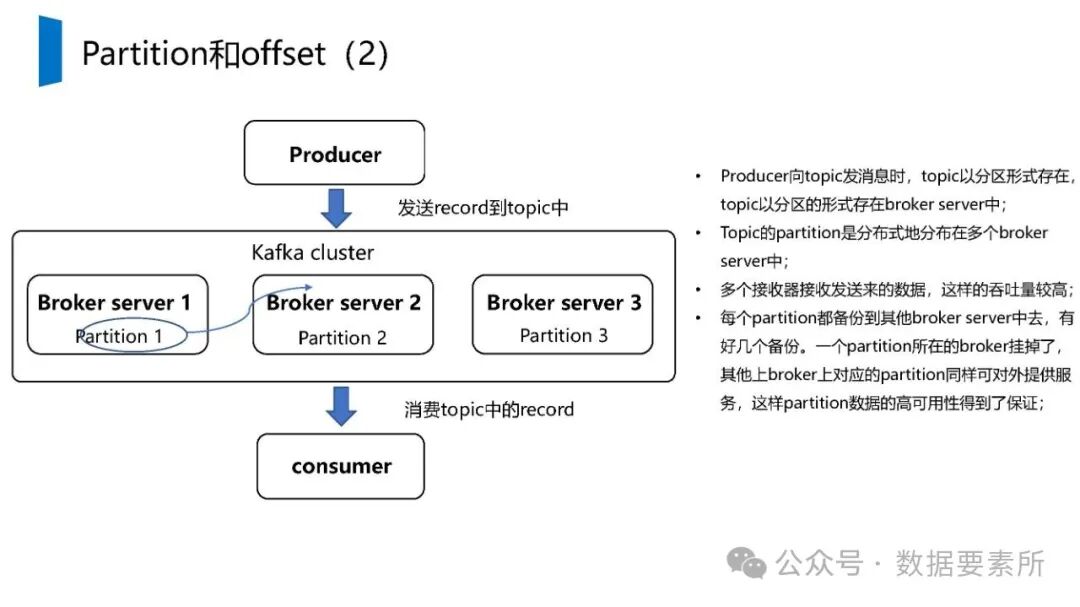
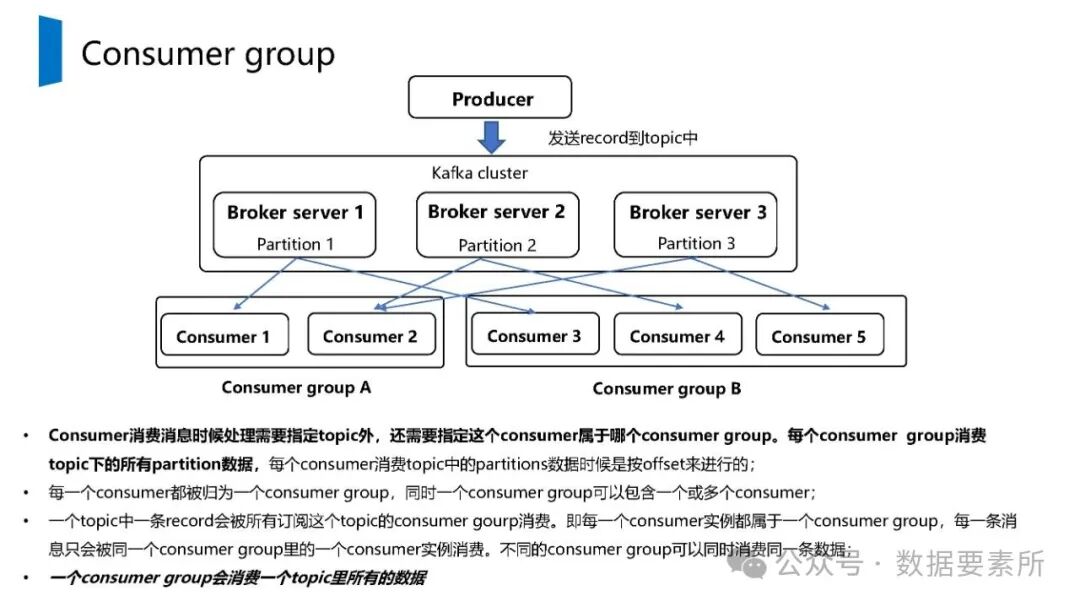
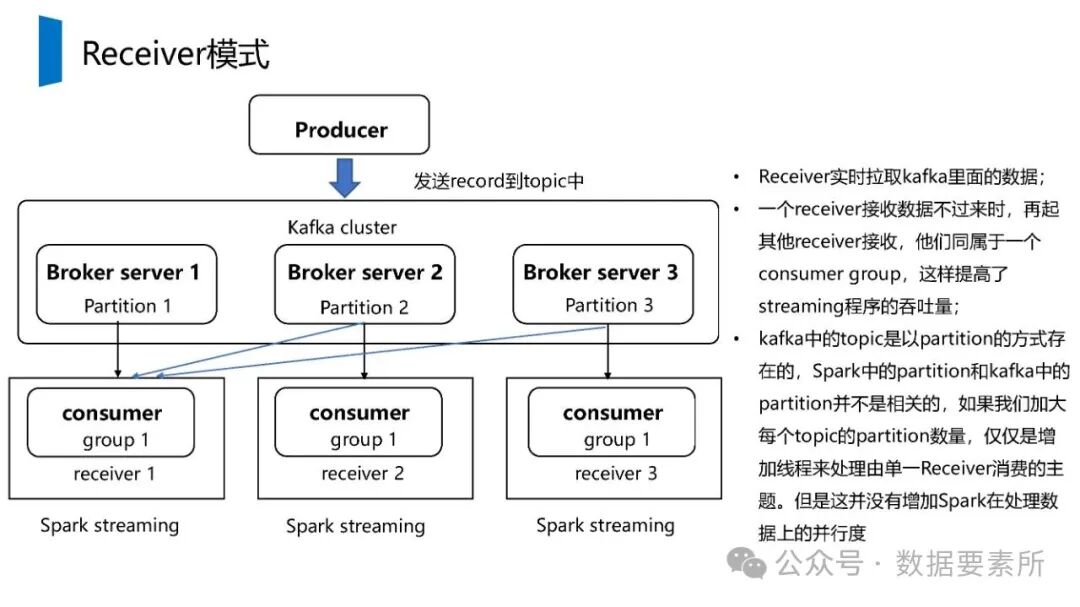
在数据架构方面,系统依赖于大数据技术栈如Kafka实现实时数据流处理,HBase用于分布式列式存储,Spark进行批量与流式计算,并借助Hive和MySQL支持数据存储与查询。数据仓库分层设计(如ODS、DWD、DWS、ADS)保障了数据结构的清晰性和血缘可追踪性。
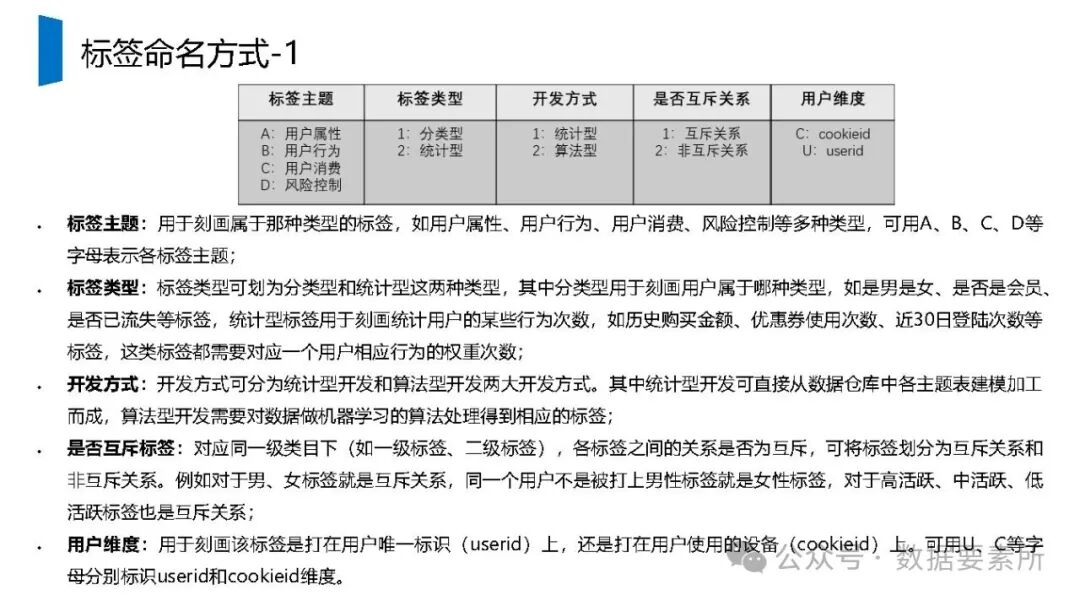
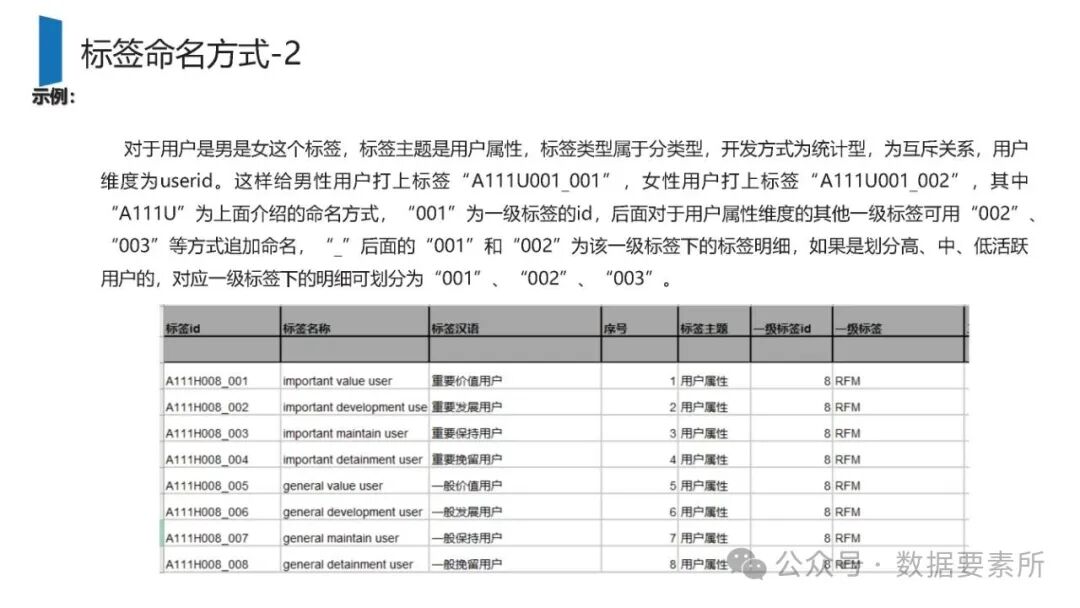
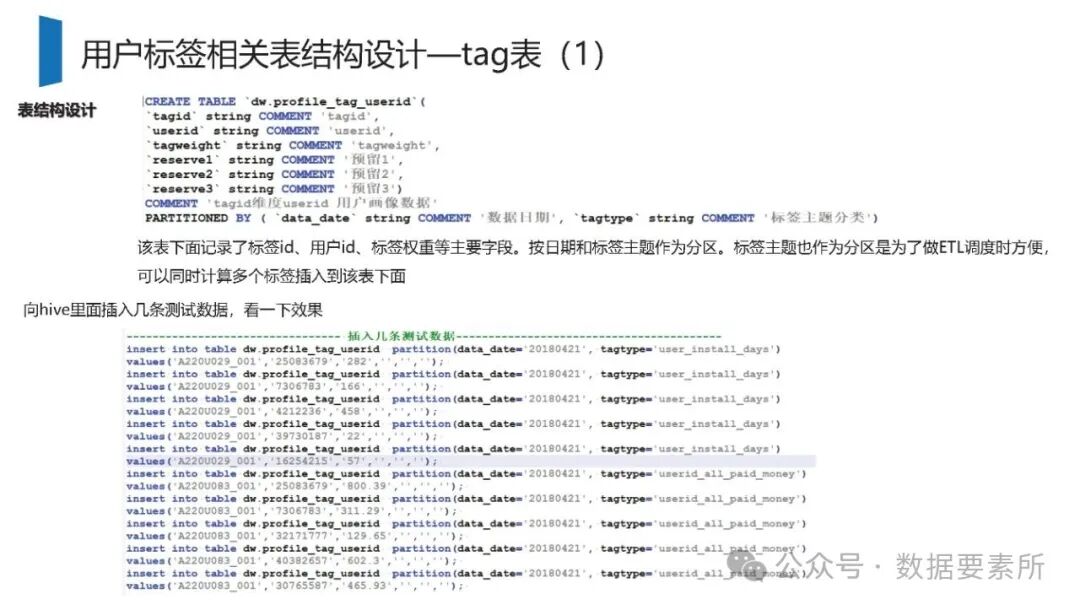
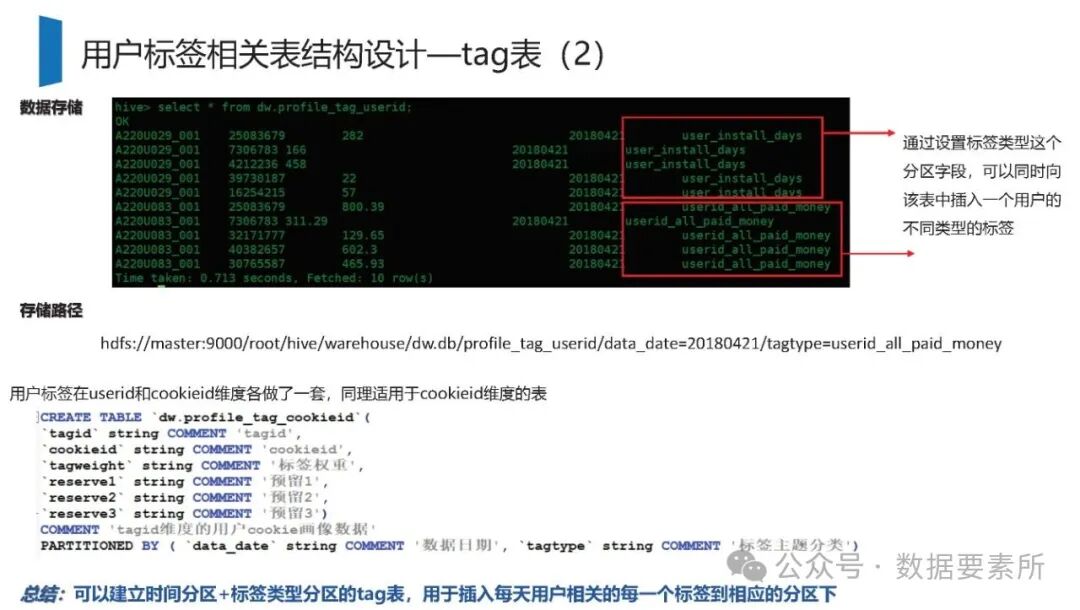
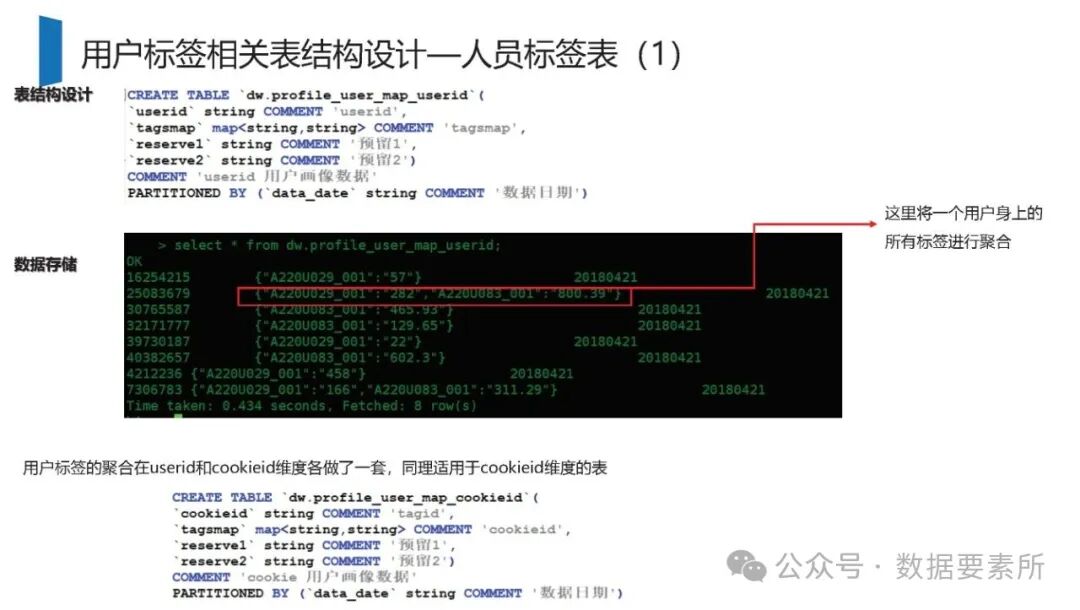
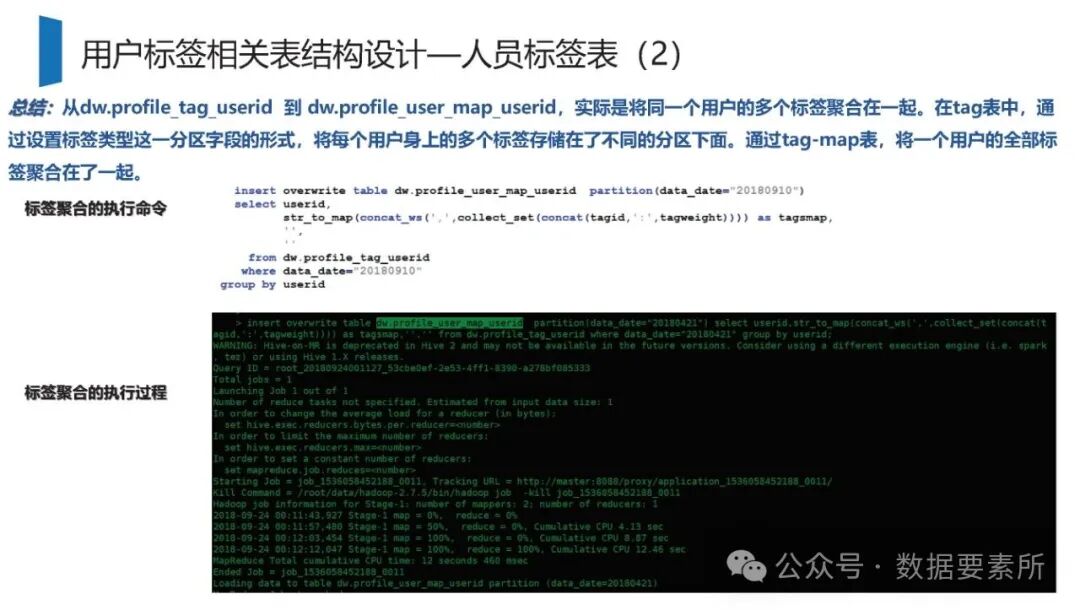
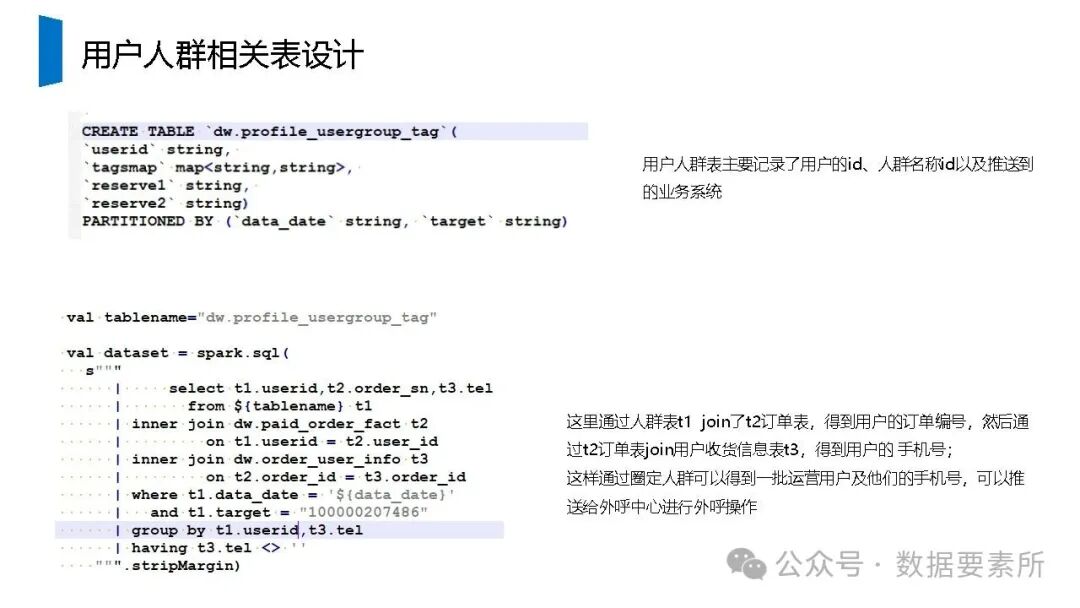
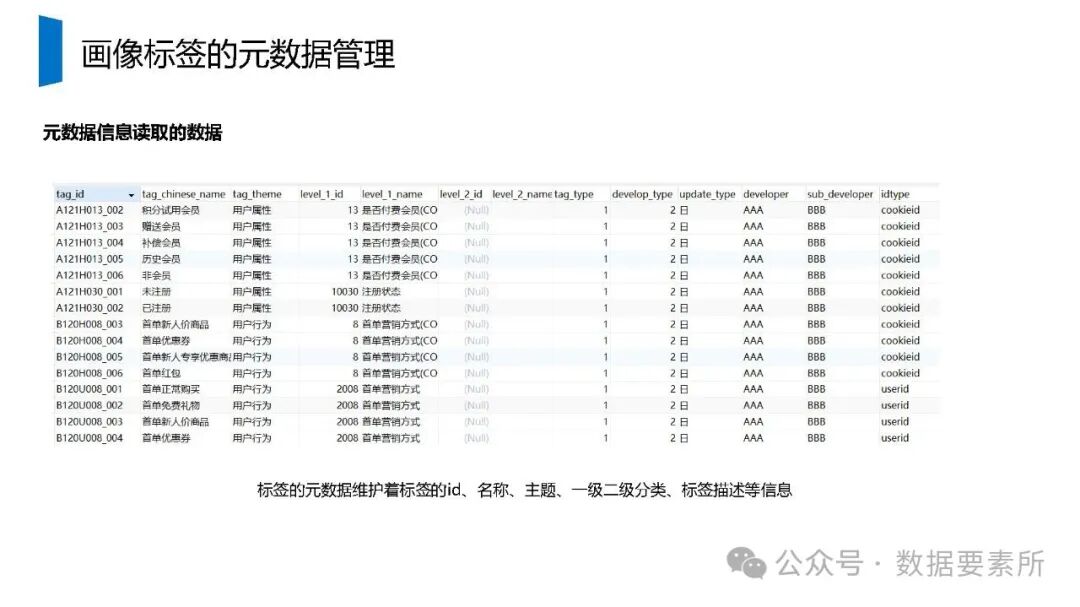
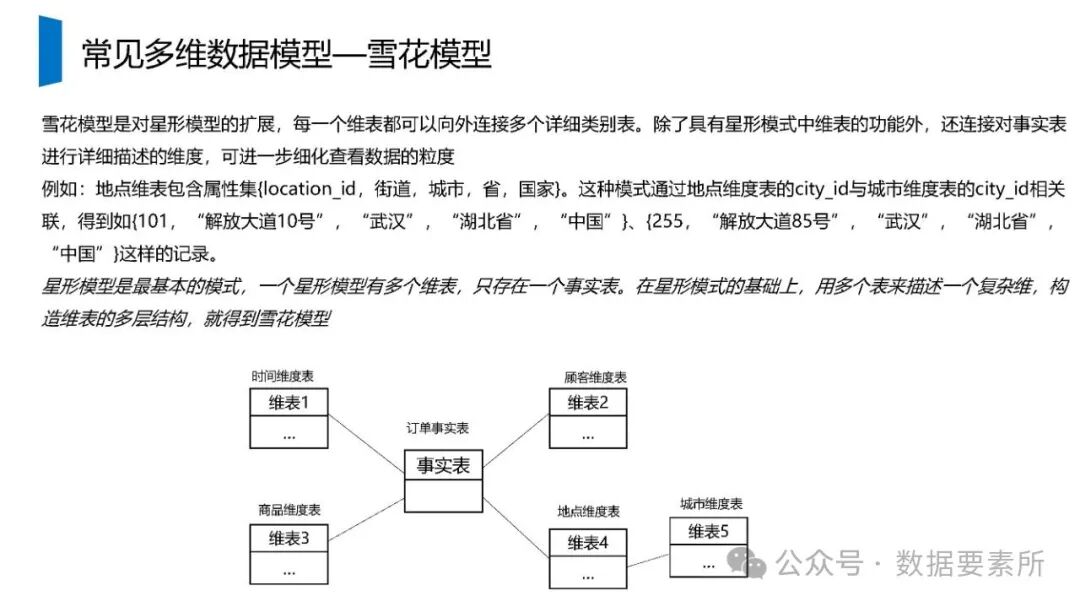
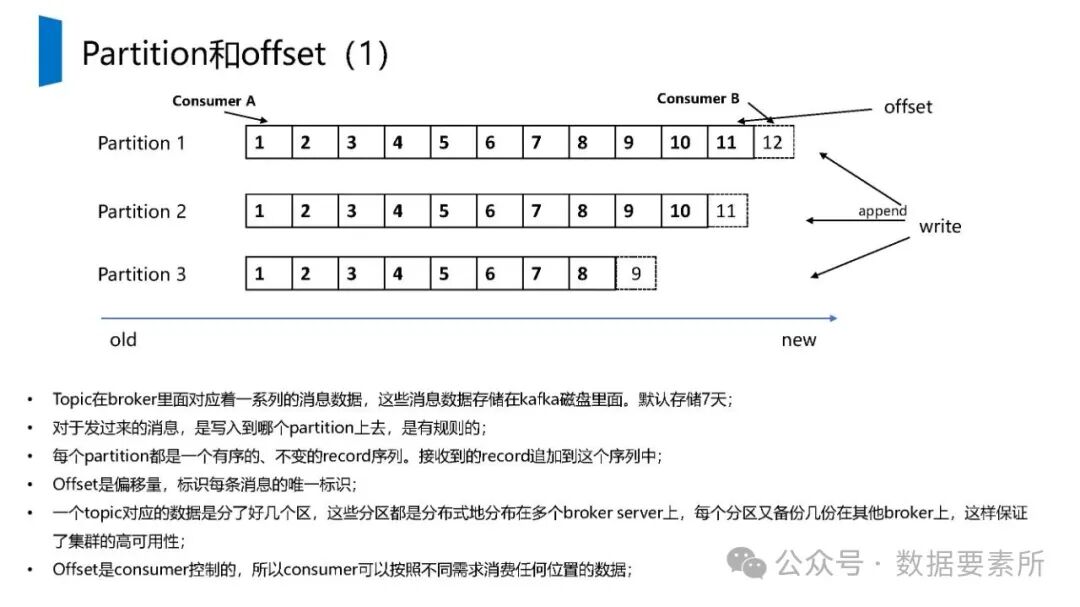
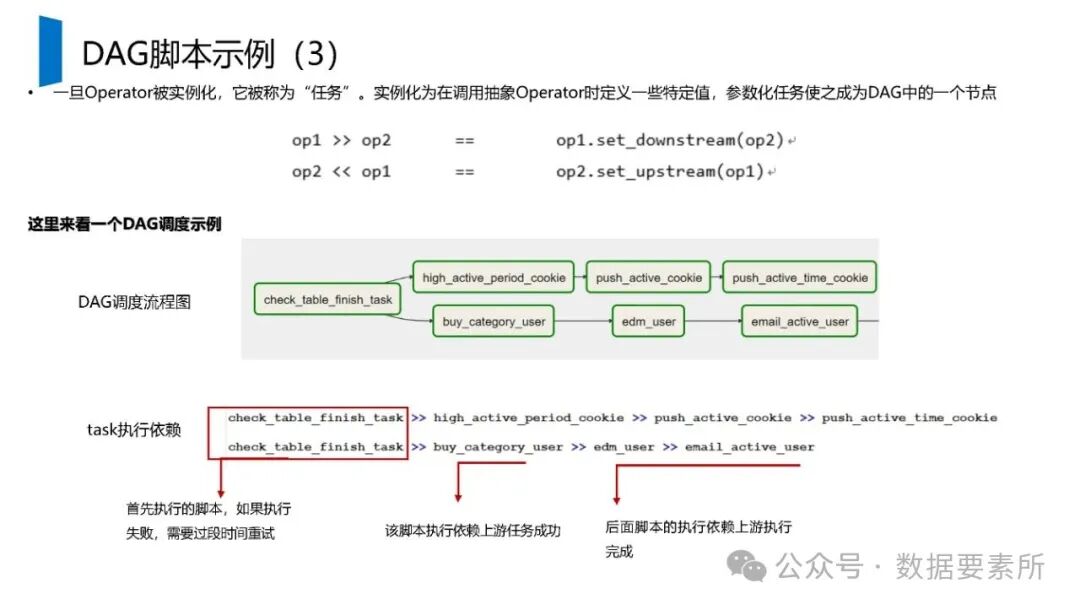
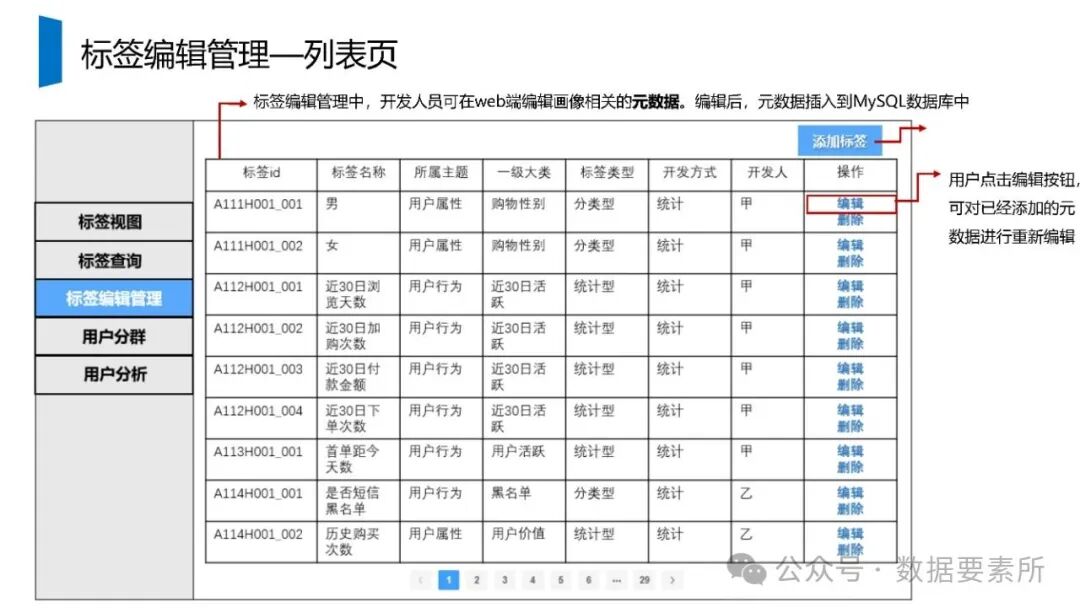
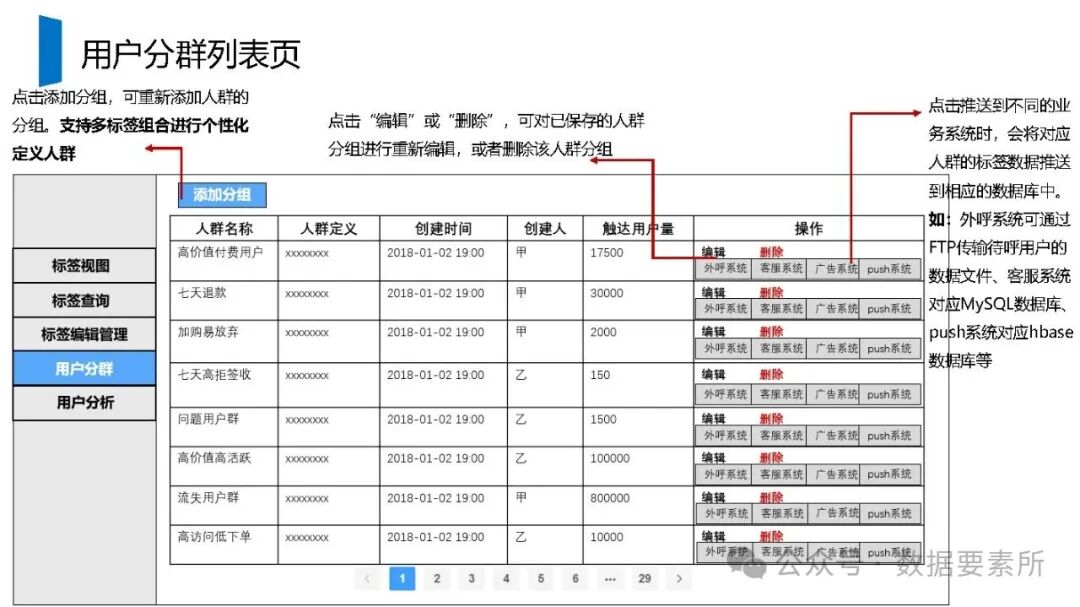
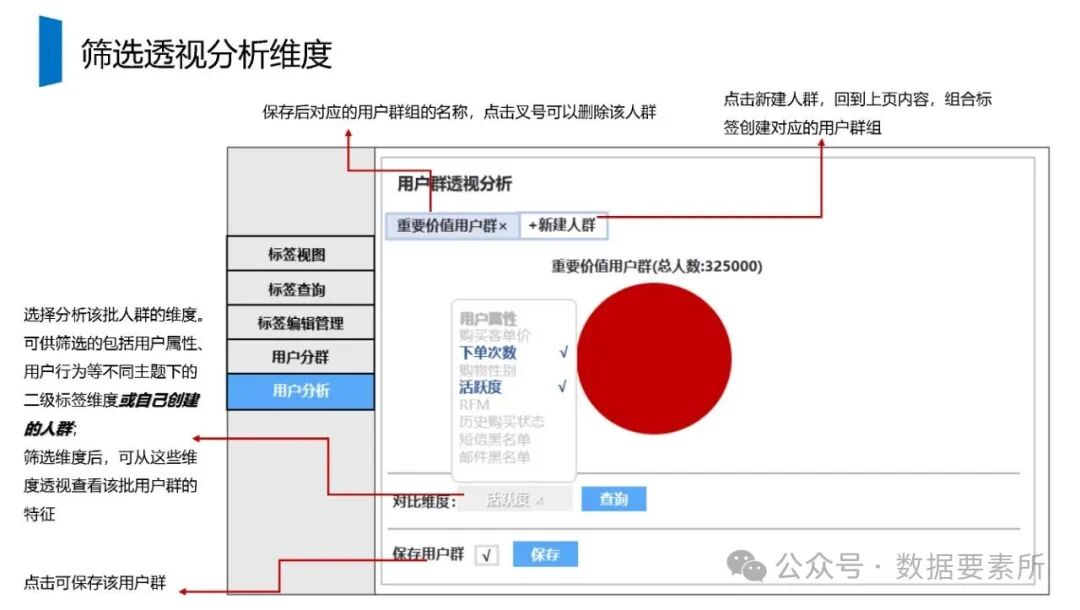
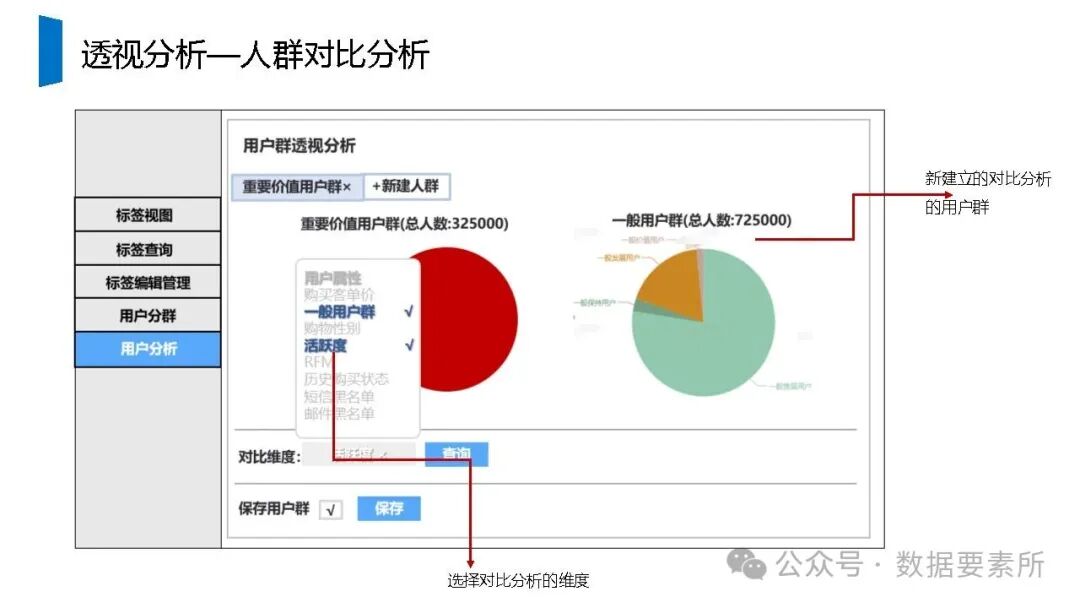
标签体系是用户画像的核心原子单元,可分为统计类、规则类和机器学习挖掘类标签。标签命名需遵循特定规则,涵盖主题、类型、开发方式、互斥属性和用户维度。表结构设计包括按日期和标签主题分区的标签表、用户标签聚合表以及用户分群表,便于数据的高效管理和查询。
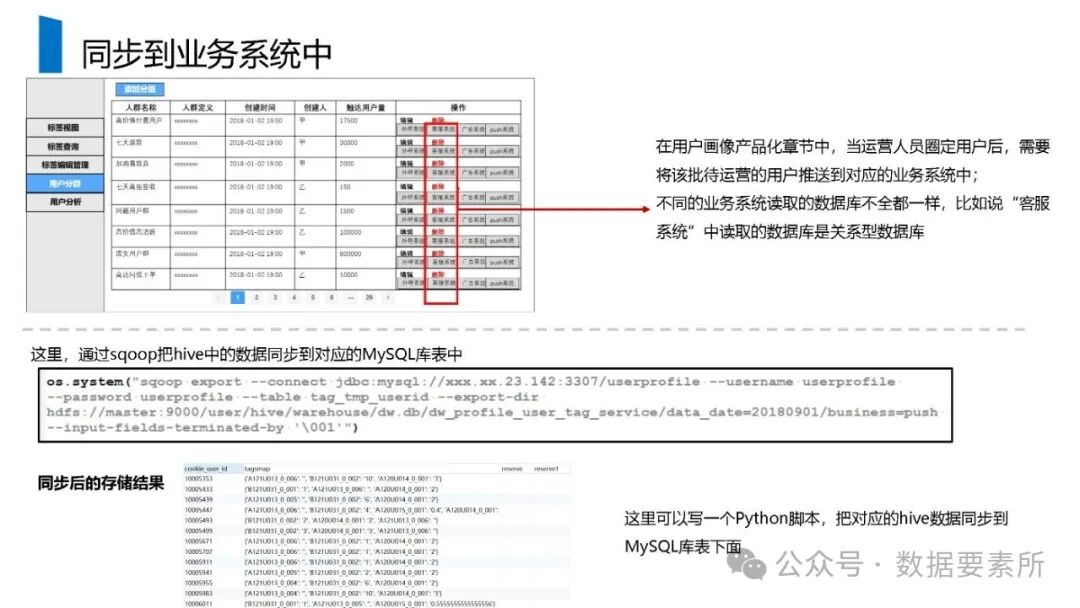
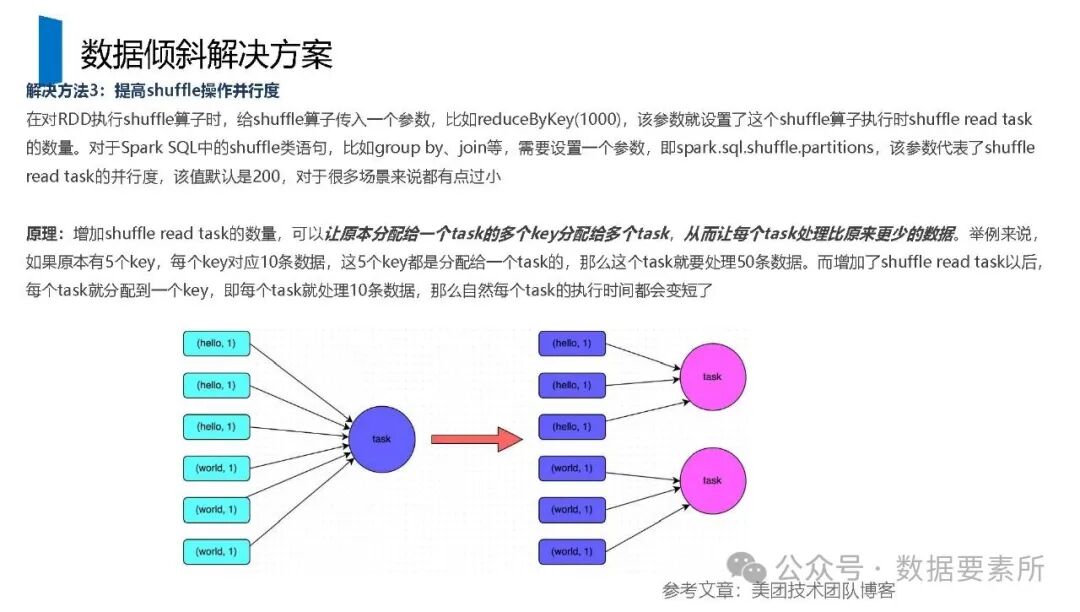
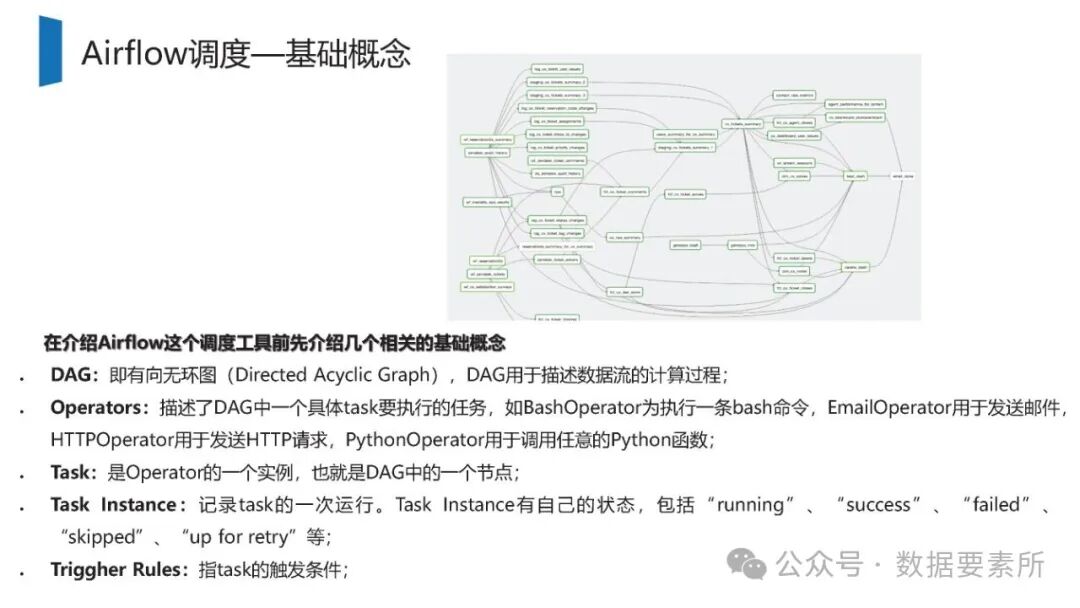
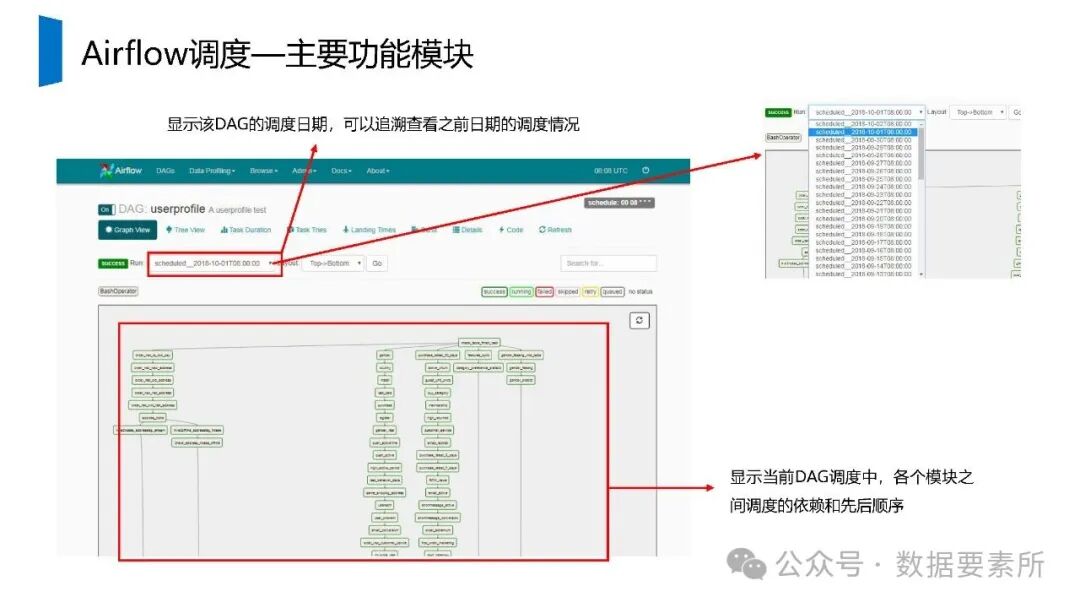
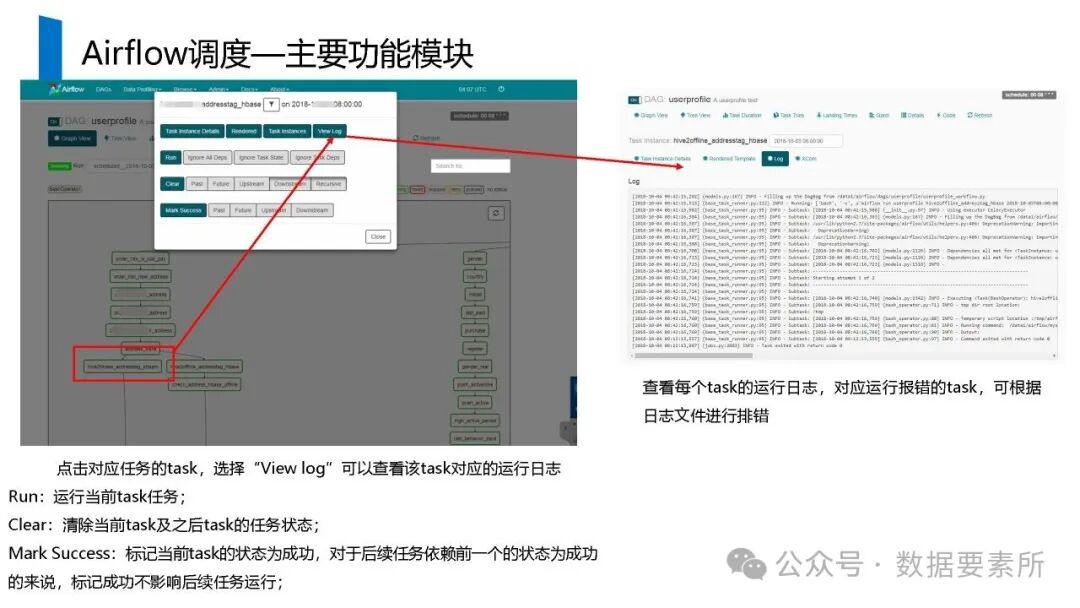
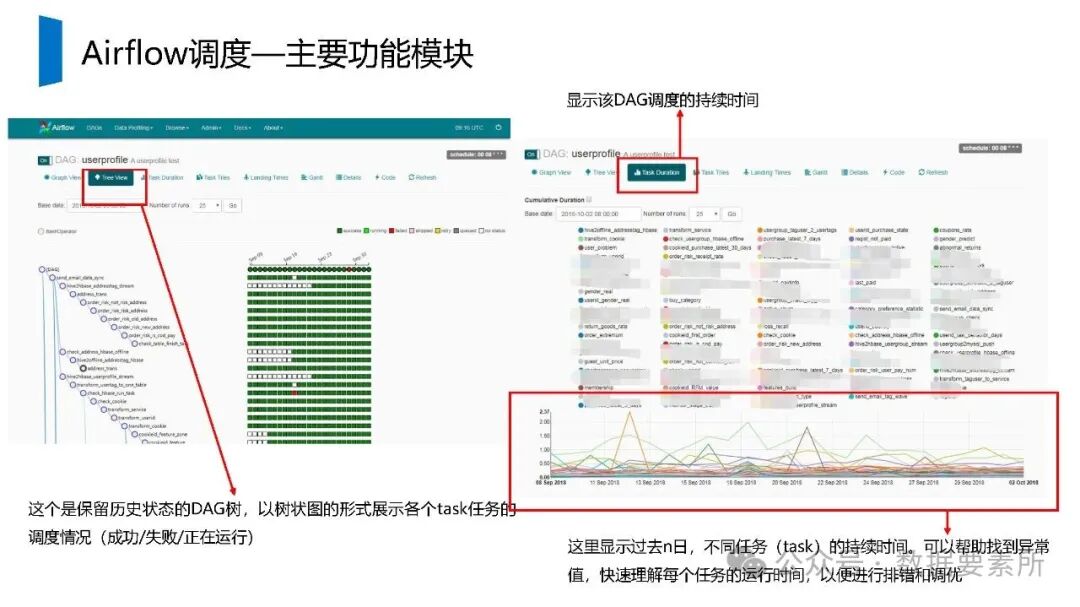
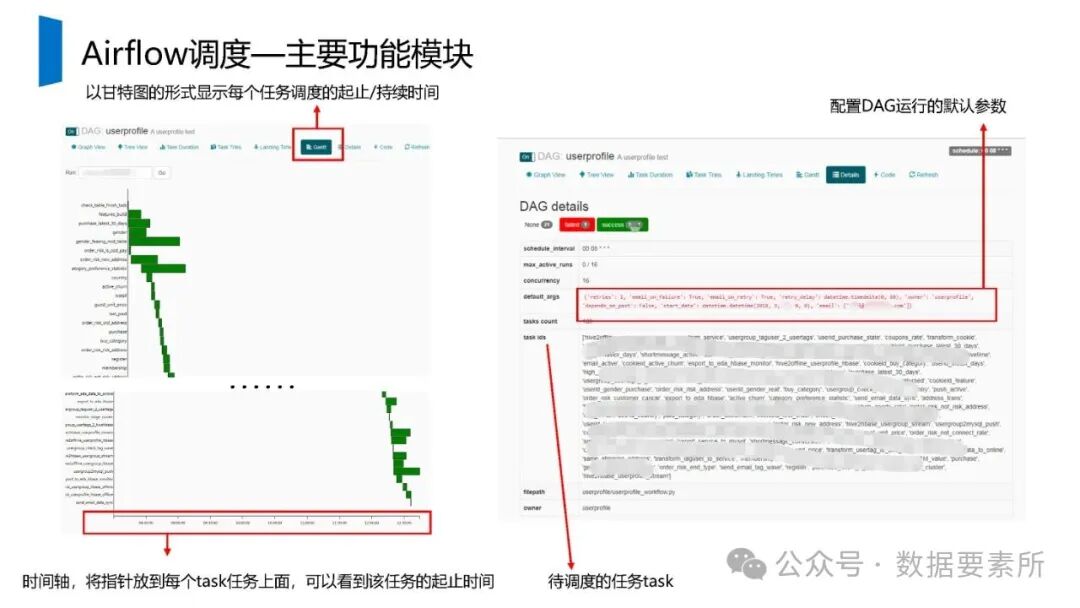
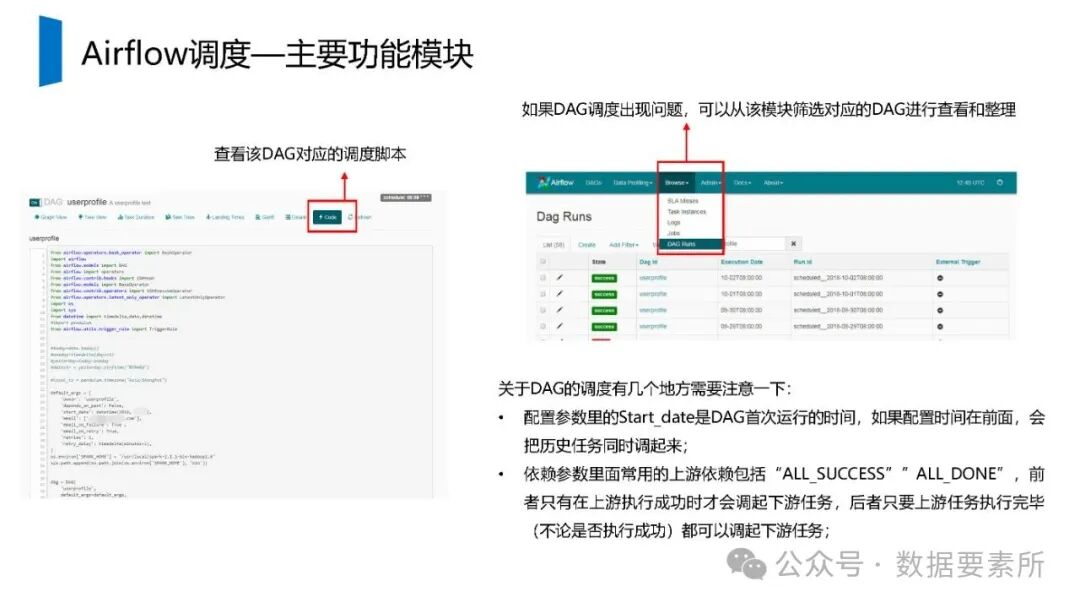
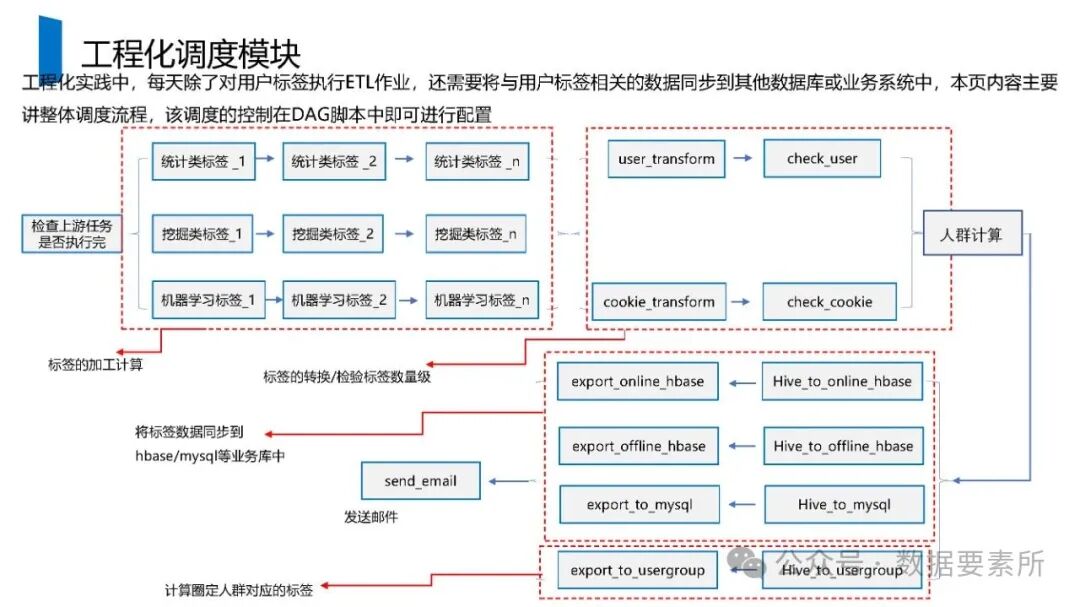
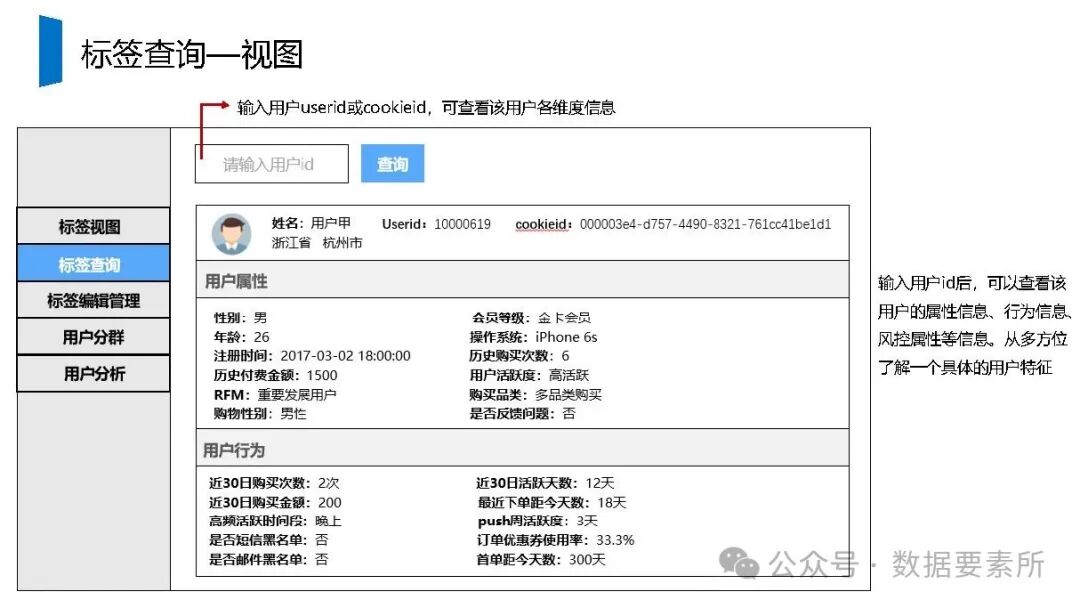
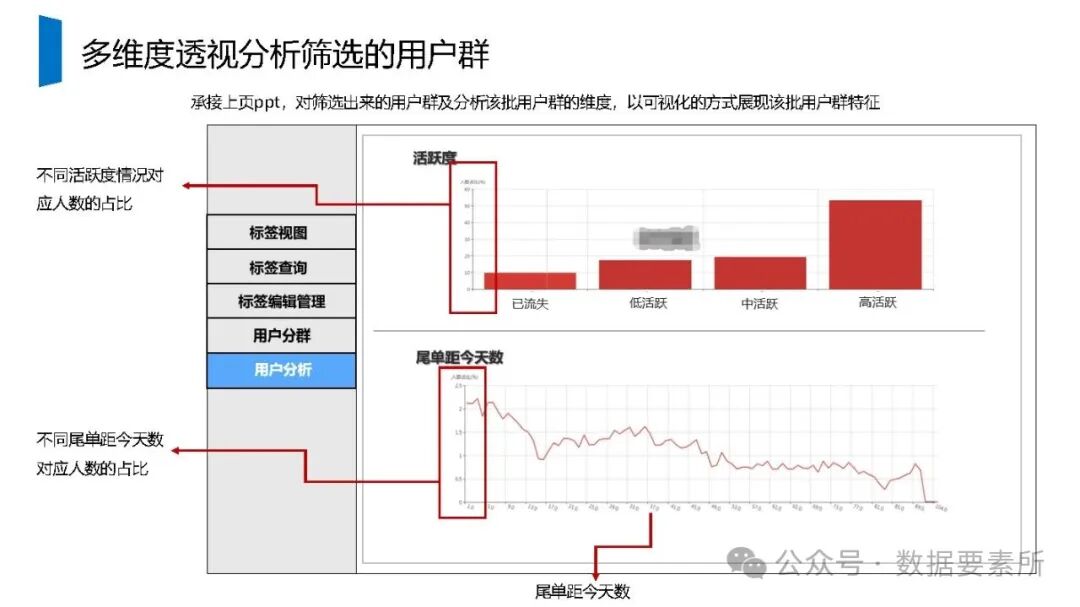
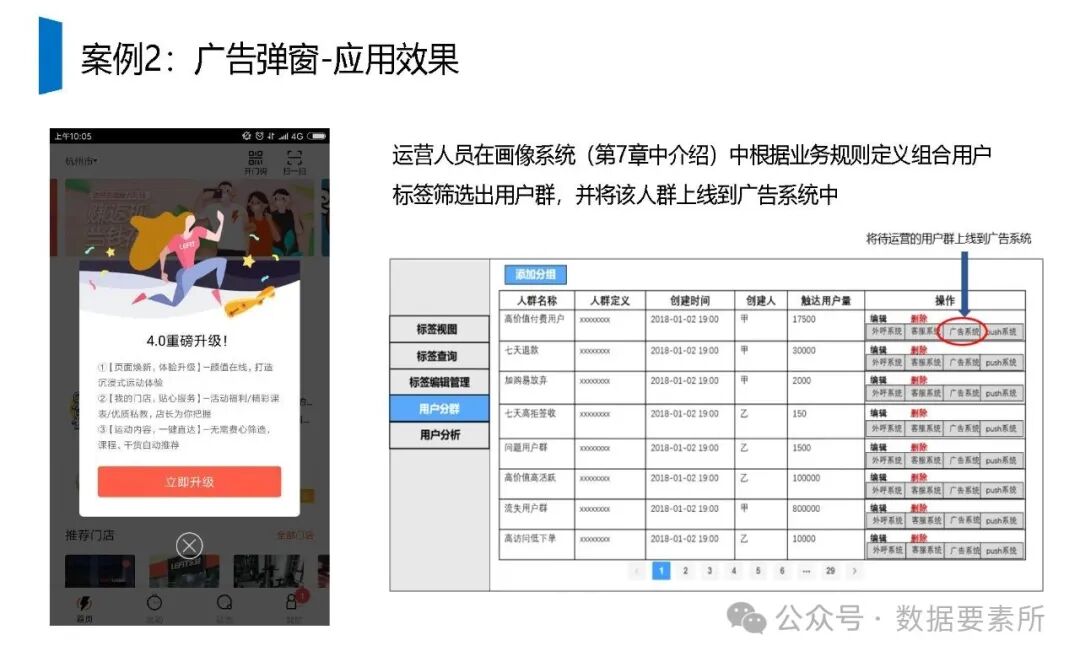
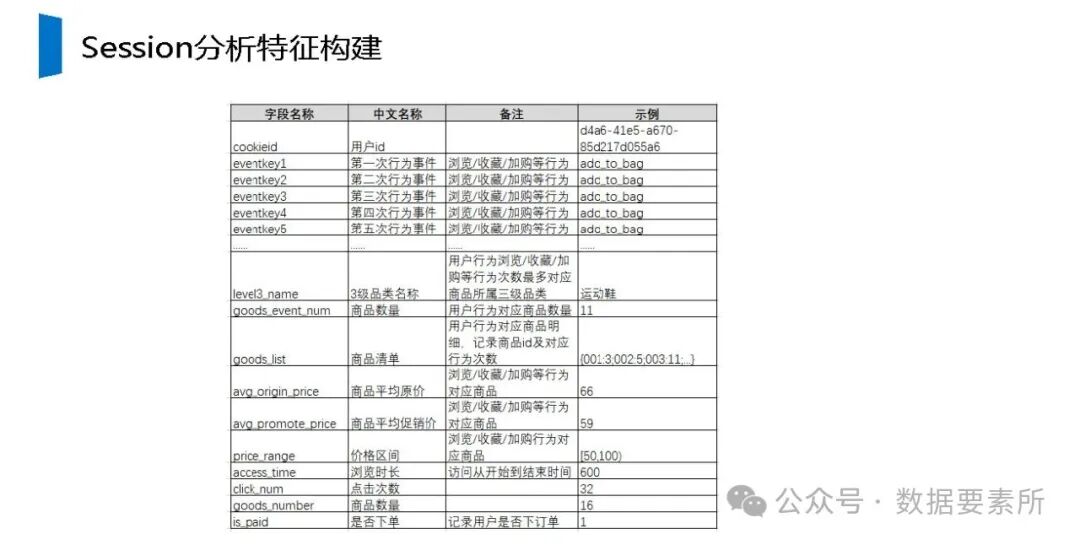
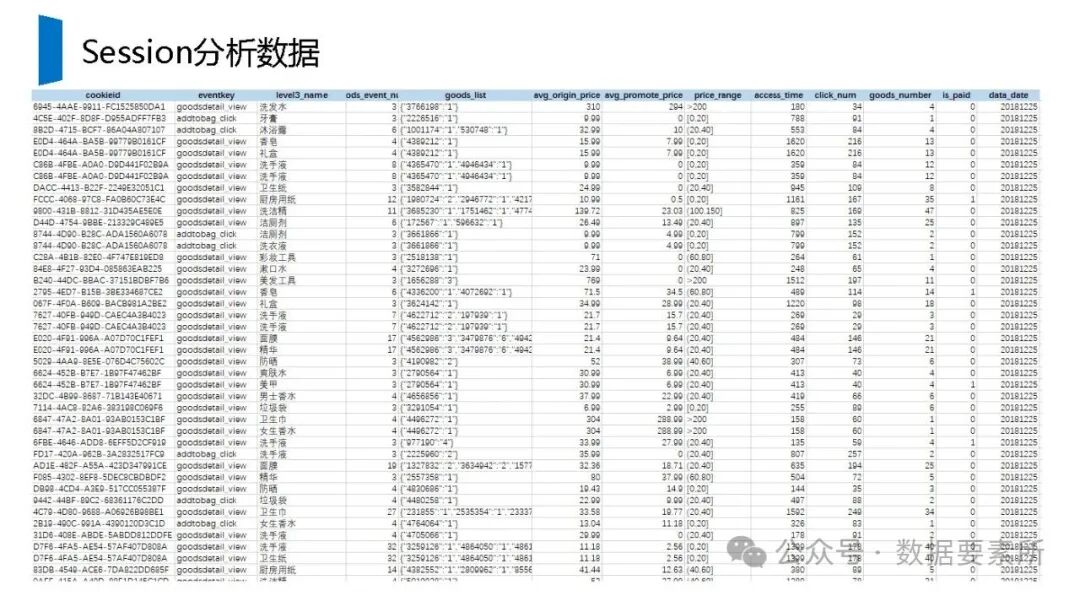
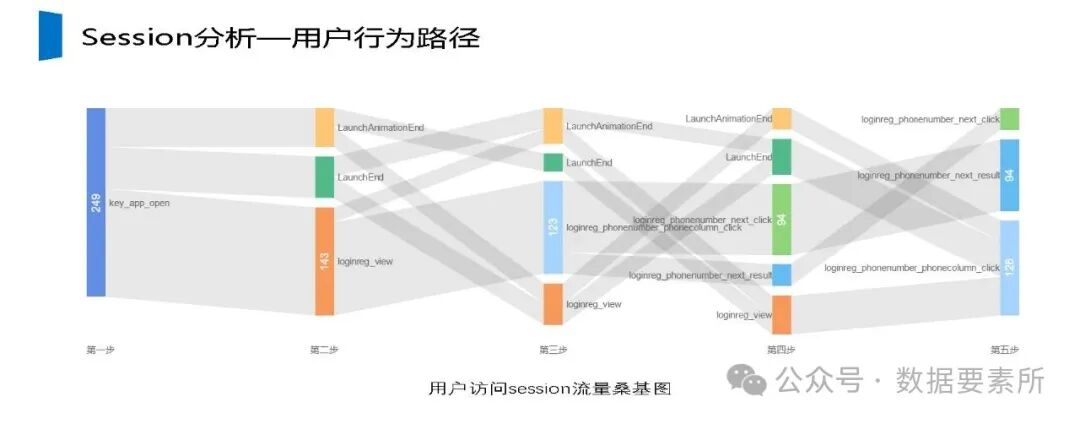
工程上,需通过ETL调度(如Airflow)定期更新数据,监控数据质量,并将结果同步至HBase、Elasticsearch等查询引擎或业务系统。画像系统最终服务于精准营销、A/B测试、Session分析和效果评估等业务场景,通过数据驱动实现用户洞察和业务增长。
关注"数据要素所 ",回复"资料",获取电子版材料的方式~