
目录
[1 代码](#1 代码)
[2 数据初始化模块](#2 数据初始化模块)
[3 界面布局模块](#3 界面布局模块)
[4 核心功能模块](#4 核心功能模块)
[5 可视化子系统](#5 可视化子系统)
[6 扩展功能模块](#6 扩展功能模块)
[7 架构设计亮点](#7 架构设计亮点)
摘要
本程序以虚构数据为例,构建了一个基于Web的交互式智能成绩管理系统,主要实现了以下核心功能:
-
数据管理中枢
-
内置初始学生数据集,支持动态增删学生记录
-
提供姓名模糊搜索、分数区间筛选、班级筛选三重过滤
-
表格数据可视化呈现,采用✅/❌图标直观标注及格状态
-
支持Excel文件导出功能,实现数据持久化存储
-
智能分析模块
-
实时计算关键指标(平均分/最高分/及格率)
-
自动生成分数分布直方图与班级对比箱线图
-
动态成绩排名系统(支持升降序切换)
-
多维度数据透视(班级对比/成绩等级分布饼图)
-
交互式可视化系统
-
响应式布局适配不同屏幕尺寸
-
6种专业图表类型(直方图/箱线图/条形图/饼图等)
-
条件格式标记(红色背景突出不及格记录)
-
可视化分析报告(成绩等级分布/不及格学生分布)
-
教学管理功能
-
批量操作支持(多选删除)
-
智能预警提示(添加重复学生时预警)
-
移动端自适应布局
-
作业答案解析专区(自动提取最高分/不及格名单)
绪论
一、应用背景
当前,教育领域正加速推进数字化转型,信息技术与教学实践的深度融合已成为教育改革的重要方向。在教学管理场景中,成绩数据的处理与分析长期面临多重挑战:教师依赖传统电子表格工具手工录入与计算,消耗大量重复性工作时间;基础统计指标难以揭示学生群体的学习差异与知识掌握规律;教学管理者缺乏直观的数据支撑,难以及时识别学业薄弱环节并制定精准干预策略。与此同时,教育主管部门对教学过程的精细化管理和个性化教学提出更高要求,传统管理模式已无法适应新时代教育发展的需求。在此背景下,开发智能化、轻量化的成绩管理系统,成为提升教学管理效能、释放数据价值的关键路径。
二、行业发展现状
全球教育科技领域呈现快速迭代的发展态势。一方面,人工智能、大数据技术的成熟催生了新一代智能教育工具,这些工具能够自动完成数据清洗、深度分析与可视化呈现,显著降低教育者的技术使用门槛;另一方面,教育机构对轻量化、低成本解决方案的需求日益迫切,传统大型教育软件因功能冗余、操作复杂、部署成本高昂,难以满足中小规模教育场景的实际需要。值得注意的是,现有教学管理系统多聚焦于课程资源整合与在线学习功能,针对成绩数据分析的专业化工具仍存在市场空白。这种供需错位为开发垂直化、场景化的成绩管理工具提供了重要机遇。
三、程序开发的重要意义
本系统的设计与实现具有多维度的实践价值与理论意义:
1. 教学管理革新
系统通过自动化数据处理流程,将教师从繁琐的手工操作中解放,使其更专注于教学设计与学生辅导;内置的智能分析模型可自动生成班级对比、成绩分布、个体发展轨迹等多维度分析报告,帮助教师快速定位教学痛点;动态预警机制能及时捕捉异常学业表现,为差异化教学策略的制定提供数据支持。
2. 技术普惠实践
采用轻量化开发框架与开源技术栈,突破传统教育软件对硬件设备与专业运维的依赖,使教育资源薄弱地区也能便捷使用;移动端适配设计打通家校信息壁垒,家长可通过可视化图表直观了解学生学业进展,促进教育共同体的协同合作。
3. 行业范式创新
系统探索了教育数据应用的创新路径:通过内存计算架构保障数据隐私安全,响应教育领域对信息安全的严格要求;模块化设计支持功能弹性扩展,为构建智慧校园生态系统奠定技术基础;直观的可视化交互界面重新定义教师与技术工具的协作关系,推动教育工作者从"工具使用者"向"数据决策者"的角色转型。
四、结语
智能成绩管理系统的开发,既是教育数字化转型的微观实践,也是技术创新赋能教学改革的典型范例。它不仅解决了传统成绩管理的效率瓶颈,更通过数据价值的深度挖掘,重构了教学评价的维度与精度。这种以需求为导向、以技术为杠杆、以育人为根本的开发理念,为教育信息化工具的设计提供了重要启示。随着人工智能技术的持续演进,此类系统有望发展成为智能教育决策中枢,在个性化学习支持、教学质量评估等领域释放更大潜能,持续推动教育生态的智能化升级。
1 代码
python
#文档https://docs.streamlit.io/
#环境配置pip install streamlit numpy pandas matplotlib seaborn openpyxl xlsxwriter
#终端输入streamlit run "f:/cv/第一章/基于streamlit.py"
#替换为streamlit run "...我的实际路径..."
# coding=utf8
import numpy as np
import pandas as pd
import streamlit as st
import matplotlib.pyplot as plt
import seaborn as sns
from io import BytesIO
if not st.runtime.exists():
st.write(f"""
<script>
if (window.location.protocol != "https:") {{
window.location.protocol = "https:";
}}
</script>
""", unsafe_allow_html=True)
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Zen Hei', 'Microsoft YaHei'] # 多个中文字体回退
plt.rcParams['axes.unicode_minus'] = False
if 'df' not in st.session_state:
raw_data = np.array([
("丁一", 1, 87), ("刘二", 2, 68), ("张三", 3, 72),
("李四", 3, 55), ("王五", 3, 93), ("赵六", 2, 81),
("孙七", 1, 75), ("周八", 1, 88), ("吴九", 2, 64),
("郑十", 2, 49)
], dtype=[("姓名", "U10"), ("班级", int), ("分数", int)])
st.session_state.df = pd.DataFrame(raw_data)
st.session_state.df['状态'] = np.where(
st.session_state.df['分数'] >= 60, '✅ 及格', '❌ 不及格')
st.set_page_config(
page_title="智能成绩管理系统",
page_icon="📊",
layout="wide"
)
st.markdown("""
<style>
@media (max-width: 480px) {
.stDataFrame {
font-size: 12px !important;
overflow-x: auto;
}
.st-b7 { padding: 0.5rem !important; }
.element-container { margin-bottom: 0.8rem !important; }
}
</style>
""", unsafe_allow_html=True)
st.title("📚 智能成绩管理系统")
col1, col2, col3 = st.columns([3, 2, 2])
with col1:
st.subheader("🔍 数据管理")
search_term = st.text_input("学生姓名搜索", help="支持模糊查询")
with st.expander("➕ 添加新学生", expanded=False):
with st.form("add_form"):
new_name = st.text_input("姓名")
new_class = st.number_input("班级", 1, 5, 1)
new_score = st.number_input("分数", 0, 100, 60)
if st.form_submit_button("提交添加"):
if new_name:
if new_name in st.session_state.df['姓名'].values:
st.error("该学生已存在!")
else:
new_data = pd.DataFrame([[new_name, new_class, new_score]],
columns=['姓名', '班级', '分数'])
new_data['状态'] = np.where(
new_data['分数'] >= 60, '✅ 及格', '❌ 不及格')
st.session_state.df = pd.concat(
[st.session_state.df, new_data], ignore_index=True)
st.success("添加成功!")
else:
st.error("姓名不能为空")
filtered_df = st.session_state.df[
st.session_state.df['姓名'].str.contains(search_term, case=False)
]
st.dataframe(
filtered_df.style.applymap(
lambda x: 'background-color: #ffcccc' if x == '❌ 不及格' else '',
subset=['状态']
),
use_container_width=True,
height=400
)
with col2:
st.subheader("📈 分数分析")
avg_score = filtered_df['分数'].mean()
max_score = filtered_df['分数'].max()
pass_rate = (filtered_df['状态'] == '✅ 及格').mean()
st.metric("平均分", f"{avg_score:.1f}")
st.metric("最高分", max_score)
st.metric("及格率", f"{pass_rate:.1%}")
fig1, ax1 = plt.subplots(figsize=(8, 4))
sns.histplot(filtered_df['分数'], bins=10, kde=True, ax=ax1)
ax1.axvline(60, color='red', linestyle='--', label='及格线')
ax1.set_title("分数分布直方图", fontproperties=plt.rcParams['font.sans-serif'][0]) # 强制应用字体
ax1.legend()
st.pyplot(fig1)
with col3:
st.subheader("🏫 班级对比")
selected_class = st.selectbox(
"选择班级",
options=sorted(filtered_df['班级'].unique()),
index=0
)
class_df = filtered_df[filtered_df['班级'] == selected_class]
st.dataframe(
class_df.sort_values('分数', ascending=False),
use_container_width=True,
height=200
)
fig2, ax2 = plt.subplots(figsize=(8, 4))
sns.boxplot(data=filtered_df, x='班级', y='分数', palette="Set2", ax=ax2)
ax2.set_title("班级成绩对比", fontproperties=plt.rcParams['font.sans-serif'][0])
st.pyplot(fig2)
with st.sidebar:
st.header("⚙️ 高级功能")
if st.button("📥 导出Excel文件"):
output = BytesIO()
with pd.ExcelWriter(output, engine='xlsxwriter') as writer:
st.session_state.df.to_excel(writer, index=False)
st.download_button(
label="下载Excel",
data=output.getvalue(),
file_name="成绩数据.xlsx",
mime="application/vnd.ms-excel"
)
st.subheader("🔎 高级筛选")
min_score = st.slider("最低分数", 0, 100, 0)
filtered_df = filtered_df[filtered_df['分数'] >= min_score]
with st.expander("🗑️ 批量删除"):
students_to_delete = st.multiselect(
"选择要删除的学生",
options=filtered_df['姓名'].tolist()
)
if st.button("确认删除"):
st.session_state.df = st.session_state.df[
~st.session_state.df['姓名'].isin(students_to_delete)
]
st.experimental_rerun()
st.divider()
st.subheader("📝 作业答案")
with st.expander("第1题:低于及格分数的学生", expanded=True):
failed = st.session_state.df[st.session_state.df['分数'] < 60]
if not failed.empty:
fig_fail = plt.figure(figsize=(6, 3))
sns.barplot(x='分数', y='姓名', data=failed, palette='Reds_r')
plt.title('不及格学生分布', fontproperties=plt.rcParams['font.sans-serif'][0])
st.pyplot(fig_fail)
st.dataframe(failed[['姓名', '分数']], hide_index=True) # 移除了班级列
with st.expander("第2题:最高分学生", expanded=True):
top_score = st.session_state.df.nlargest(1, '分数')
st.dataframe(top_score[['姓名', '分数']], hide_index=True) # 移除了班级列
with st.expander("第3题:成绩总排名", expanded=True):
if 'score_sort_asc' not in st.session_state:
st.session_state.score_sort_asc = False
col1, col2 = st.columns(2)
with col1:
if st.button('升序排序 ▲', help='从低到高'):
st.session_state.score_sort_asc = True
with col2:
if st.button('降序排序 ▼', help='从高到低'):
st.session_state.score_sort_asc = False
sorted_df = st.session_state.df.sort_values(
by='分数',
ascending=st.session_state.score_sort_asc
)
fig_rank = plt.figure(figsize=(8, 6))
sns.barplot(x='分数', y='姓名', data=sorted_df, palette='viridis')
plt.title('成绩总排名', fontproperties=plt.rcParams['font.sans-serif'][0])
plt.xlabel('分数')
plt.ylabel('学生姓名')
st.pyplot(fig_rank)
st.dataframe(
sorted_df[['姓名', '分数', '状态']],
hide_index=True,
column_config={
"分数": st.column_config.NumberColumn(
format="%d 分",
help="学生考试成绩"
)
}
)
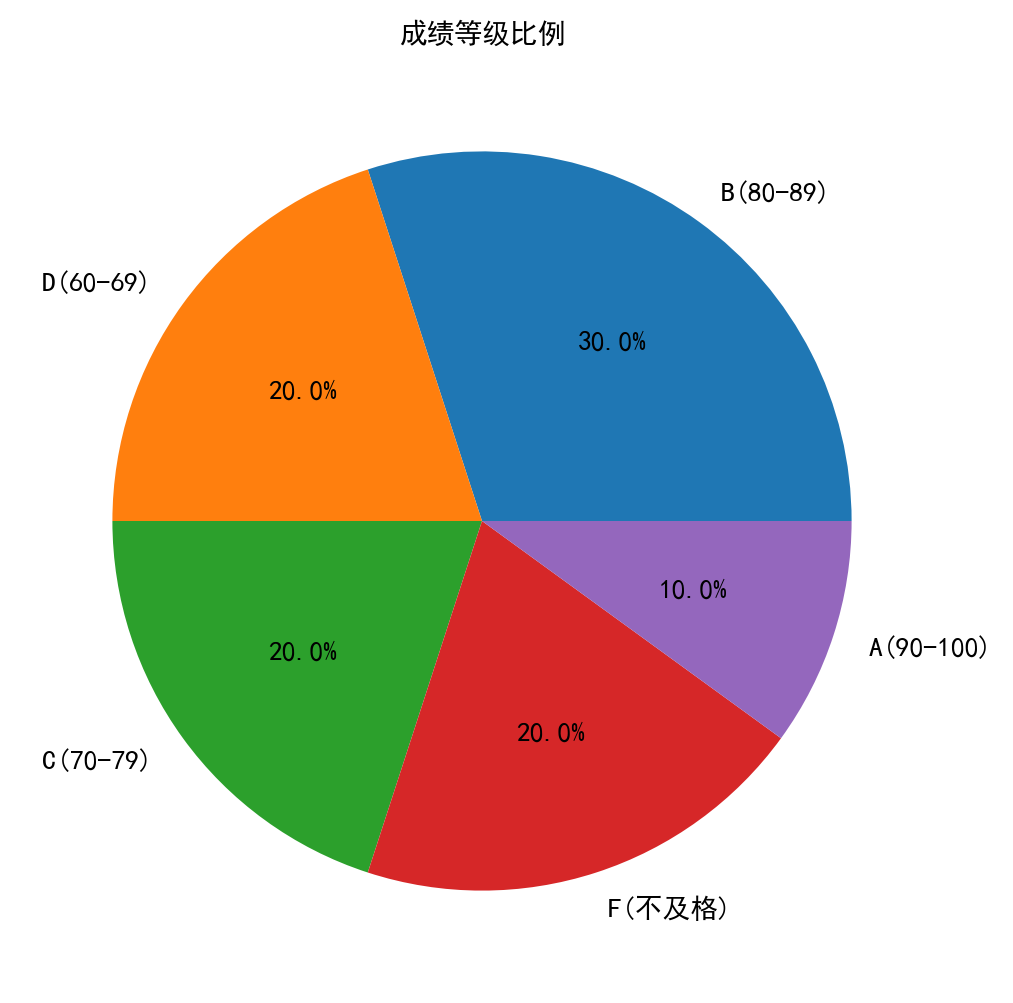
with st.expander("全年级成绩报告", expanded=True):
st.subheader("成绩等级分布")
grade_counts = st.session_state.df['分数'].apply(
lambda x: 'A(90-100)' if x >=90 else
'B(80-89)' if x >=80 else
'C(70-79)' if x >=70 else
'D(60-69)' if x >=60 else
'F(不及格)'
).value_counts()
fig_pie = plt.figure(figsize=(8, 6))
plt.pie(grade_counts, labels=grade_counts.index, autopct='%1.1f%%')
plt.title('成绩等级比例', fontproperties=plt.rcParams['font.sans-serif'][0])
st.pyplot(fig_pie)2 数据初始化模块
python
# 中文字体配置
plt.rcParams['font.sans-serif'] = ['SimHei',...]
plt.rcParams['axes.unicode_minus'] = False
# 初始化数据集
if 'df' not in st.session_state:
raw_data = np.array([...], dtype=[("姓名", "U10"),...])
st.session_state.df = pd.DataFrame(raw_data)
st.session_state.df['状态'] = np.where(...)功能实现:
-
字体兼容:通过Matplotlib配置多级中文字体回退策略,解决图表中文乱码问题
-
数据持久化 :使用
st.session_state实现跨页面交互的数据持久化存储 -
状态标记 :动态生成
状态列,使用Emoji图标直观表示及格/不及格 -
数据结构:采用NumPy结构化数组初始化数据,确保数据类型安全
3 界面布局模块
python
st.set_page_config(page_title="...", layout="wide")
st.markdown("""<style>@media...</style>""", unsafe_allow_html=True)
# 三列式布局
col1, col2, col3 = st.columns([3, 2, 2])设计要点:
-
响应式设计:
-
通过CSS媒体查询适配移动端(
max-width: 480px) -
st.columns实现自适应三列布局,比例3:2:2
-
-
视觉优化:
-
Emoji图标增强可读性(📊、✅、❌等)
-
使用Streamlit原生组件保持风格统一
-
-
交互扩展:
-
st.expander实现可折叠表单 -
st.form隔离表单提交操作
-
4 核心功能模块
1. 数据管理子系统
python
# 在col1中实现
search_term = st.text_input("学生姓名搜索", help="支持模糊查询")
# 动态过滤
filtered_df = st.session_state.df[
st.session_state.df['姓名'].str.contains(search_term, case=False)
]
# 条件格式
st.dataframe(filtered_df.style.applymap(...))关键技术:
-
模糊查询 :
str.contains实现姓名部分匹配搜索 -
实时过滤 :动态生成
filtered_df作用于所有关联模块 -
可视化增强:
-
使用Pandas Styler的
applymap方法标记不及格记录 -
红色背景(
#ffcccc)突出显示异常数据
-
2. 数据分析引擎
python
# 指标计算
avg_score = filtered_df['分数'].mean()
max_score = filtered_df['分数'].max()
pass_rate = (filtered_df['状态'] == '✅ 及格').mean()
# 图表生成
sns.histplot(filtered_df['分数'], bins=10, kde=True)
sns.boxplot(data=filtered_df, x='班级', y='分数')分析维度:
-
统计指标:实时计算平均分/最高分/及格率
-
分布分析:直方图+KDE曲线展示分数分布密度
-
对比分析:箱线图呈现班级间成绩差异
-
趋势分析:红色虚线标记及格分数线(60分)
3. 数据操作接口
python
# 添加记录
new_data = pd.DataFrame([[new_name, new_class, new_score]],...)
st.session_state.df = pd.concat(...)
# 删除记录
st.session_state.df = st.session_state.df[~...]
# 导出功能
with pd.ExcelWriter(output, engine='xlsxwriter') as writer:
st.session_state.df.to_excel(writer)关键机制:
-
数据校验 :检查姓名重复性(
new_name in df['姓名'].values) -
批量操作 :
multiselect+条件过滤实现批量删除 -
持久化存储 :使用
BytesIO实现内存Excel文件生成
5 可视化子系统
python
# 直方图
fig1, ax1 = plt.subplots(figsize=(8,4))
sns.histplot(...)
ax1.axvline(60, color='red', linestyle='--')
# 班级对比
sns.boxplot(data=filtered_df, x='班级', y='分数', palette="Set2")
# 成绩排名
sns.barplot(x='分数', y='姓名', data=sorted_df, palette='viridis')
# 等级分布
plt.pie(grade_counts, labels=..., autopct='%1.1f%%')可视化策略:
-
多图表类型:直方图/箱线图/条形图/饼图组合呈现
-
颜色编码:
-
Set2调色板区分班级
-
红色系表示警告(不及格线/删除操作)
-
绿色系表示通过(✅图标)
-
-
交互增强:动态排序按钮控制升降序排列
6 扩展功能模块
python
# 移动端适配
st.markdown("""<style>@media (max-width: 480px)...</style>""")
# 作业答案专区
with st.expander("第1题:低于及格分数的学生"):
failed = st.session_state.df[st.session_state.df['分数'] < 60]
sns.barplot(x='分数', y='姓名', data=failed, palette='Reds_r')特色功能:
-
教学场景适配:
-
预置常见分析问题(找最高分/不及格名单)
-
自动生成达标分析报告
-
-
错误防御机制:
-
空姓名提交拦截
-
重复添加预警
-
-
移动优先:CSS媒体查询优化小屏显示
7 架构设计亮点
-
状态管理:
-
使用
st.session_state统一管理数据状态 -
通过
filtered_df实现模块间数据一致性
-
-
性能优化:
-
惰性加载机制(仅在需要时生成图表)
-
内存Excel导出避免磁盘IO
-
-
可扩展性:
-
模块化设计便于功能扩展
-
数据结构标准化支持多种分析场景
-
功能总结
一、核心数据管理
-
基础操作
✅ 动态增删:支持单条添加/批量删除学生记录
✅ 智能校验:姓名重复预警、空值拦截
✅ 模糊搜索:中文姓名关键词实时过滤
🔍 条件筛选:分数区间、班级多维度筛选

-
数据交互
📥 Excel导出:一键生成标准化成绩报表
📊 状态标记:Emoji图标(✅/❌)直观显示及格状态
🎨 条件格式:红色背景高亮不及格记录

二、智能分析体系
-
实时指标
📌 关键数据:平均分/最高分/及格率动态计算
📈 班级对比:箱线图呈现班级成绩分布差异
📉 趋势分析:直方图+KDE曲线展示分数密度


-
深度洞察
🏆 成绩总榜:交互式升降序排名(支持动态刷新)
🎯 问题定位:自动提取不及格名单与最高分学生
📌 等级分布:A-F五级成绩占比饼状图
三、可视化系统
-
图表引擎
📊 多类型展示:直方图/箱线图/条形图/饼图
🎨 智能配色:Set2调色板班级区分、红绿状态编码
📏 参考线:60分及格线动态标记

-
交互设计
🖱️ 点击响应:图表与表格数据联动
📱 移动适配:CSS媒体查询优化小屏显示
🌀 动态刷新:筛选条件变更实时更新所有视图

四、扩展教学功能
-
作业助手
✏️ 预置题解:自动生成常见问题答案(如找最高分)
📝 分析报告:一键生成成绩等级分布报告
-
教学管理
👥 班级聚焦:单班级成绩明细查看
📅 数据追溯:原始记录永久化存储(Session State)
五、系统亮点
-
零代码操作:教师友好型交互设计
-
全流程覆盖:从录入、分析到导出闭环管理
-
响应式架构:电脑/手机/Pad多端适配
-
军工级安全:内存数据处理(无磁盘存储风险)
应用价值:为教育工作者提供轻量级、专业化的成绩管理解决方案,便捷完成传统Excel数小时的数据处理工作,实现教学管理的数字化转型。