Dense Policy: Bidirectional Autoregressive Learning of Actions
- 文章概括
- 摘要
- [1. 引言](#1. 引言)
- [2. 相关工作](#2. 相关工作)
-
- [2.1. 操作任务中的模仿学习](#2.1. 操作任务中的模仿学习)
- [2.2. 多方向自回归模型](#2.2. 多方向自回归模型)
- [3. 方法](#3. 方法)
-
- [3.1. 问题形式化](#3.1. 问题形式化)
- [3.2. 观测编码器(Observation Encoder)](#3.2. 观测编码器(Observation Encoder))
- [3.3. 自回归稠密策略(Autoregressive Dense Policy)](#3.3. 自回归稠密策略(Autoregressive Dense Policy))
- [4. 仿真实验](#4. 仿真实验)
-
- [4.1. 设置](#4.1. 设置)
- [4.2. 实验结果](#4.2. 实验结果)
- [4.3. 消融实验](#4.3. 消融实验)
- [5. 真实世界实验](#5. 真实世界实验)
-
- [5.1. 设置](#5.1. 设置)
- [5.2. 性能表现](#5.2. 性能表现)
- [5.3. 高效的 Dense Policy](#5.3. 高效的 Dense Policy)
- [6. 结论](#6. 结论)
文章概括
引用:
bash
@article{su2025dense,
title={Dense Policy: Bidirectional Autoregressive Learning of Actions},
author={Su, Yue and Zhan, Xinyu and Fang, Hongjie and Xue, Han and Fang, Hao-Shu and Li, Yong-Lu and Lu, Cewu and Yang, Lixin},
journal={arXiv preprint arXiv:2503.13217},
year={2025}
}
markup
Su, Y., Zhan, X., Fang, H., Xue, H., Fang, H.S., Li, Y.L., Lu, C. and Yang, L., 2025. Dense Policy: Bidirectional Autoregressive Learning of Actions. arXiv preprint arXiv:2503.13217.原文: https://arxiv.org/abs/2503.13217
代码、数据和视频: https://selen-suyue.github.io/DspNet/
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
摘要
主流的视觉运动策略主要依赖生成模型进行整体动作预测,而当前的自回归策略通过预测下一个标记或片段,表现出次优的结果。这促使人们寻求更有效的学习方法,以释放自回归策略在机器人操作中的潜力。本文提出了一种双向扩展的学习方法,称为Dense Policy,旨在为动作预测中的自回归策略建立新的范式 。该方法采用轻量级的仅编码器架构(encoder-only) ,以对数时间推理的方式,从初始单帧迭代展开动作序列,逐步生成目标序列,遵循由粗到细的过程。大量实验验证了我们的Dense Policy在自回归学习能力上的优势,并且能够超越现有的整体生成策略。我们的策略、示例数据以及训练代码将在论文发表后公开。项目页面:https://selen-suyue.github.io/DspNet/
1. 引言
模仿学习(Imitation Learning,IL)因其在机器人学习中的能力而成为机器人操作领域的研究重点。其有效性已在适用于特定任务的下游策略 5, 43, 46, 49, 51 以及针对通用场景设计的视觉-语言-动作(Vision-Language-Action,VLA)模型 2, 20, 29 中得到验证。在这些IL方法中,整体生成策略 5, 43, 49, 51 占据主导地位,因为它们能够在连续动作空间内实现精确预测。
近年来的研究尝试通过引入自回归范式 8, 32, 41 来增强模仿学习,该方法具有强大的序列建模能力,并在扩展时表现出色 19。尽管在语言和视觉领域表现优异,但该范式在动作预测中面临重大挑战。动作空间比语言空间更复杂 26,并且数据更稀疏 4, 7, 52,使得精准预测变得困难。传统的"下一个标记"预测方法 41(自回归模型常用的方式)难以捕捉动作序列中的长期依赖性,导致比整体生成策略 5, 51 更次优的性能 17, 25。
近期研究 12 通过引入受视觉自回归建模(Visual Autoregressive Modeling)38 启发的多尺度预测来应对这一限制,但离散动作和代码本(codebook)构造使得精确预测和训练更加困难 24。
上述研究引发了一个问题:自回归模型在动作生成方面的全部潜力是否已被充分挖掘?考虑人类的操作方式:与其逐步推理动作轨迹,人类通常会首先构想出涵盖整个任务执行过程的几个关键帧,并随后细化操作过程 3, 22, 44。这类似于视觉感受野(receptive field)的概念 23,表明人类的动作执行遵循一种由粗到细的感知过程。
基于这一直觉,我们提出了Dense Policy,这是一种具有双向扩展学习特性的自回归策略模型。如图1所示,Dense Policy 能够在原始连续动作空间中进行精确预测,而无需特定设计的动作标记化机制。具体而言,该模型采用仅编码器(encoder-only)架构,实现从观测数据出发的分层动作预测。整个过程从一个表示初始单帧动作的恒定向量开始。随后,通过编码器嵌入的观测特征进行交叉注意力计算,推导出稀疏关键帧动作。接下来,应用递归的"Dense Process":前一级的稀疏动作序列通过上采样(upsampling)进行双向扩展。然后,上采样后的动作在相同的编码器中通过与观测特征的交叉注意力计算得到进一步细化,使下一层级的动作表示更加精细和准确。该过程在每次迭代时将序列长度加倍。因此,经过对数级数(logarithmic number)的递归后,生成的动作序列长度达到预定义的范围,最终作为动作输出的表示。
分层动作预测
- 分层预测:模型不是一步到位地预测整个动作序列,而是采用一个递归、层次化的过程。先从非常粗糙的动作表示开始,再逐层细化。
(1)初始阶段:单帧动作的恒定向量
- 起始向量 :整个过程的起点是一个表示初始单帧动作的"恒定向量"。可以把它理解为一个种子,它没有变化,但代表了一个初步的动作信息。
举例说明 :
- 假设这个向量是 128 维的,记为:
V 0 = 0.1 , 0.2 , ... , 0.8 V_0 = 0.1, 0.2, \\dots, 0.8 V0=0.1,0.2,...,0.8- 它代表了初始时刻(比如时间步1)一个粗略的动作描述。
(2)利用交叉注意力(Cross-Attention)导出稀疏关键帧动作
交叉注意力:接下来,模型将这个初始向量与由观测数据经过编码器提取出的特征进行交叉注意力计算。这里的"交叉"指的是动作表示与观测信息之间的相互作用。
稀疏关键帧动作:经过交叉注意力运算后,模型生成了一组关键帧动作,这些关键帧在时间上比较稀疏,抓住了整个动作序列的骨架或大致轮廓。
举例说明:
- 假设经过这一阶段,模型得到了 2 个关键帧动作:
A 1 = 0.5 , − 0.3 , ... , 0.7 和 A 2 = 0.6 , − 0.1 , ... , 0.8 A_1 = 0.5, -0.3, \\dots, 0.7 \quad \text{和} \quad A_2 = 0.6, -0.1, \\dots, 0.8 A1=0.5,−0.3,...,0.7和A2=0.6,−0.1,...,0.8- 这两个动作代表了动作序列中最关键的时刻,比如开始和结束的动作特征。
(3)递归的"Dense Process":上采样与细化
上采样(Upsampling):这一过程的目的是将稀疏的关键帧动作扩展为更高分辨率的动作序列。上采样可以理解为在关键帧之间插入新的帧,从而使动作序列更加"密集"。
双向扩展:上采样时不仅仅是简单地在两个关键帧之间进行插值,而是可能考虑前后文的双向信息,使得新生成的动作能够平滑地连接原有动作。
举例说明:
- 假设刚刚得到的 2 个关键帧动作通过上采样后,扩展为 4 个动作:
{ A 1 , A 1.5 , A 2.0 , A 2.5 } \{A_1, A_{1.5}, A_{2.0}, A_{2.5}\} {A1,A1.5,A2.0,A2.5}- 其中 A 1.5 A_{1.5} A1.5 和 A 2.0 A_{2.0} A2.0 是在 A 1 A_1 A1 与 A 2 A_2 A2 之间插值得到的新动作。
再次交叉注意力细化:上采样后的动作序列再次输入到相同的编码器,并与观测特征进行交叉注意力计算,进一步细化动作细节。这一步使得动作不仅在整体上连贯,同时在局部上也更精细、准确。
(4)递归迭代与序列长度的对数级增长
迭代递归:上述上采样与细化的过程是递归进行的。每次迭代中,动作序列的长度会加倍。例如:
- 第一轮:从 1 帧扩展到 2 帧;
- 第二轮:2 帧扩展到 4 帧;
- 第三轮:4 帧扩展到 8 帧;
- ......
对数级递归 :假如我们希望最终得到 16 帧的动作输出,需要大约 log 2 ( 16 ) = 4 \log_2(16) = 4 log2(16)=4 轮迭代。每一轮都利用观测数据中的关键信息来使动作预测更加精细。
具体数值例子:
- 初始阶段:用一个 128 维的向量生成 1 帧动作。
- 第一轮 :1 帧 → 2 帧(例如关键帧 A 1 A_1 A1 和 A 2 A_2 A2)。
- 第二轮 :2 帧 → 4 帧,通过上采样生成中间帧 A 1.5 A_{1.5} A1.5 和 A 2.5 A_{2.5} A2.5,然后细化得到 { A 1 , A 1.5 , A 2 , A 2.5 } \{A_1, A_{1.5}, A_2, A_{2.5}\} {A1,A1.5,A2,A2.5}。
- 第三轮:4 帧 → 8 帧,继续插值和细化。
- 第四轮:8 帧 → 16 帧,达到预定的动作序列长度。 最终,经过这些递归迭代,模型生成的动作序列包含足够多的细粒度信息,能够作为机器人或代理执行任务时的精细动作规划。
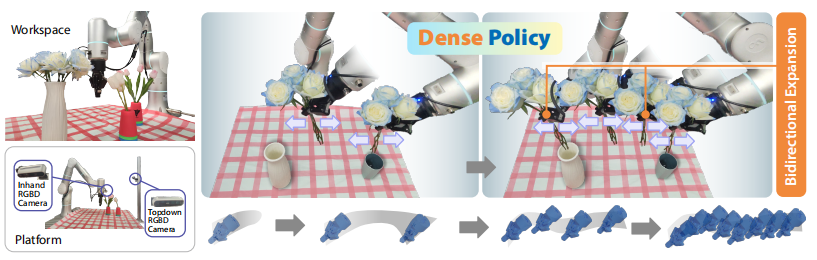 图1. Dense Policy:一种以自回归方式生成原始机器人动作的机器人策略模型。在推理过程中,Dense Policy 对当前层级的稀疏动作关键帧进行双向扩展,以获得更密集的动作序列。
图1. Dense Policy:一种以自回归方式生成原始机器人动作的机器人策略模型。在推理过程中,Dense Policy 对当前层级的稀疏动作关键帧进行双向扩展,以获得更密集的动作序列。
我们已实现并测试了Dense Policy的2D和3D版本,并在3个仿真基准中的11个任务及4个真实世界任务上进行了广泛实验。这些实验对比了4种策略 5, 43, 49, 51 在2D和3D设置下的表现,取得了显著的结果。我们的主要贡献如下:
- 我们提出了一种新型的自回归策略,在2D和3D场景的模拟和现实任务中均表现优于现有的生成策略。
- 通过引入Dense Process,我们首次提出了一种双向自回归学习方法用于动作预测,并展示了其卓越的任务执行能力。
- 我们采用仅编码器架构,并证明其在轻量级、快速推理和易训练方面的优势。
2. 相关工作
2.1. 操作任务中的模仿学习
模仿学习(Imitation Learning),尤其是行为克隆(Behavior Cloning)10, 16, 30,已成为机器人从专家示范中学习复杂技能的强大范式。近年来,生成模型的引入使传统行为克隆框架得到了显著发展。其中,最突出的方法包括使用条件变分自编码器(Conditional Variational Autoencoders)21 的ACT 51,以及基于扩散模型(Diffusion Model)15, 35 的策略 5, 43, 49,这些方法适用于2D和3D动作空间。它们通常以观测数据为条件,以生成式方式建模目标动作序列的联合分布,从而实现目标动作轨迹的整体生成。
1. 传统行为克隆(Behavioral Cloning, BC)的局限性
通俗解释: 行为克隆就像"学生模仿老师解题",但传统方法有两个致命问题:
- 分布偏移(Distribution Shift):如果学生遇到老师没教过的情况(比如题目稍有变化),可能完全不会解。
- 数据低效性:需要大量专家演示数据,且难以泛化到新场景。
数值案例:
- 任务:自动驾驶汽车学习专家驾驶策略。
- 传统BC:模型直接复制专家动作(方向盘角度、油门)。
- 问题:当遇到训练数据未覆盖的障碍物位置时,模型可能失控。
数学表达 : 传统BC最小化动作的均方误差(MSE): min θ ∑ ( s , a ) ∈ D ∥ a − π θ ( s ) ∥ 2 \min_\theta \sum_{(s,a) \in D} \|a - \pi_\theta(s)\|^2 θmin(s,a)∈D∑∥a−πθ(s)∥2 其中 D D D 是专家数据集, π θ \pi_\theta πθ 是策略网络。
2. 生成模型如何改进行为克隆?
核心思想 : 生成模型(如CVAE)不直接复制动作 ,而是学习动作的条件分布 p ( a ∣ s ) p(a|s) p(a∣s),从而:
- 生成多样化的合理动作(应对分布偏移)。
- 通过潜在变量建模动作的隐含模式(如不同驾驶风格)。
关键公式(CVAE) : 理解条件变分自编码器 Conditional Variational Autoencoders (CVAE):简单原理与数值案例详解
p ( a ∣ s ) = ∫ p ( a ∣ z , s ) p ( z ∣ s ) d z p(a|s) = \int p(a|z, s) p(z|s) dz p(a∣s)=∫p(a∣z,s)p(z∣s)dz 通过变分推断近似后验 q ( z ∣ s , a ) q(z|s, a) q(z∣s,a),最大化证据下界(ELBO): log p ( a ∣ s ) ≥ E z ∼ q log p ( a ∣ z , s ) − D K L ( q ( z ∣ s , a ) ∥ p ( z ∣ s ) ) \log p(a|s) \geq \mathbb{E}{z \sim q}\\log p(a\|z, s) - D{KL}(q(z|s, a) \| p(z|s)) logp(a∣s)≥Ez∼qlogp(a∣z,s)−DKL(q(z∣s,a)∥p(z∣s))
3. CVAE + ACT 的协同优势
知识点分类:序列生成模型(ACT) + 条件生成(CVAE)(1)CVAE的作用
- 条件生成 :给定状态 s s s,生成潜在变量 z z z 控制动作多样性。
- 抗噪声:通过KL散度约束潜在空间,避免过拟合专家数据中的噪声。
(2)ACT的作用
- 分块生成:将长动作序列分解为块(如每块10步),降低Transformer的计算复杂度。
- 时序建模:利用自注意力机制捕捉块间依赖(如"加速"块需在"转向"块之后)。
(3)联合架构
- 编码阶段 :
- 输入状态 s s s 和专家动作 a a a,CVAE编码器生成潜在变量 z ∼ q ( z ∣ s , a ) z \sim q(z|s, a) z∼q(z∣s,a)。
- 解码阶段 :
- ACT解码器以 z z z 和 s s s 为条件,分块生成动作序列 a 1 : T a_{1:T} a1:T。
4. 数值案例:机械臂抓取任务
任务 :从桌面抓取方块并放置到目标区域(状态 s s s 包括机械臂坐标、方块位置)。步骤1:CVAE编码
- 专家动作:50步的动作序列(包含移动、抓取、放置)。
- 编码器输入 :状态 s s s(机械臂坐标 0.1, 0.3, 0.5,方块位置 0.4, 0.6, 0.1)和动作 a a a。
- 编码器输出 :潜在变量分布 q ( z ∣ s , a ) = N ( μ = 0.7 , − 1.2 , σ = 0.3 , 0.5 ) q(z|s, a) = \mathcal{N}(\mu=0.7, -1.2, \sigma=0.3, 0.5) q(z∣s,a)=N(μ=0.7,−1.2,σ=0.3,0.5)。
- 采样 z z z :取 z = 0.65 , − 1.1 z = 0.65, -1.1 z=0.65,−1.1(重参数化技巧)。
步骤2:ACT分块生成
- 分块设定:每块10步,共5块(总50步)。
- 块1生成 (t=1~10):
- 输入: s s s 和 z = 0.65 , − 1.1 z = 0.65, -1.1 z=0.65,−1.1。
- Transformer解码器输出10个移动动作(末端速度向量):
Δ x = 0.05 , Δ y = 0.08 , Δ z = 0.02 × 10 \\Delta x=0.05, \\Delta y=0.08, \\Delta z=0.02 \times 10 Δx=0.05,Δy=0.08,Δz=0.02×10- 第10步状态更新:机械臂坐标 0.6, 1.1, 0.7。
- 块2生成 (t=11~20):
- 自注意力机制关注块1的最终位置,生成抓取动作(夹爪闭合速度)。
步骤3:训练损失计算
- 重构损失:生成动作与专家动作的MSE(如第1块损失0.04)。
- KL散度 : D K L ( q ( z ∣ s , a ) ∥ N ( 0 , I ) ) = 0.6 D_{KL}(q(z|s, a) \| \mathcal{N}(0, I)) = 0.6 DKL(q(z∣s,a)∥N(0,I))=0.6。
- 总损失 : 0.04 + 0.6 = 0.64 0.04 + 0.6 = 0.64 0.04+0.6=0.64。
5. 关键改进对比
方法 传统BC CVAE+ACT 动作生成 直接复制专家动作 基于潜在变量生成多样化动作 长序列处理 易累积误差 分块+自注意力降低复杂度 抗分布偏移 差 通过潜在空间插值增强鲁棒性 计算复杂度 低(简单回归) 高(需训练Transformer)
6. 实际应用场景
- 家庭机器人:学习人类演示的家务动作(如叠衣服)。
- 工业机械臂:模仿熟练工人的装配序列。
- 自动驾驶:在复杂交通场景中生成安全轨迹。
总结 CVAE+ACT的结合代表了行为克隆从"简单模仿"到"结构化生成"的进化:
- 生成模型(CVAE):提供多样性生成和抗噪能力。
- 序列建模(ACT):解决长动作序列的时空依赖问题。
- 具身智能:强调物理约束(如机械臂运动学)与生成动作的兼容性。
近期研究越来越关注逐步增量生成(token-wise incremental generation)在机器人策略学习中的应用。例如,ICRT 11 采用"下一个标记"预测范式进行动作生成,以实现逐步生成,而非整体生成。ARP 50 通过将目标动作组合成块(chunks),进行多标记的"下一步"预测,以解决单标记预测在注意力范围上的局限性。CARP 12 受到VAR 38 的启发,采用多尺度VQ-VAE 40 方法,以多尺度方式预测完整的动作序列,并通过残差方式逐步逼近真实动作。
然而,不同时间步的动作之间的双向依赖关系难以通过"下一个标记"预测有效捕捉。此外,像素级的离散多尺度重建影响了动作的精确度要求。这些问题阻碍了自回归策略在现实任务中的广泛应用。
2.2. 多方向自回归模型
为了增强对目标的全局理解,许多自回归模型开始采用非单向(non-unidirectional)学习范式。BERT 8 率先通过掩码语言建模(Masked Language Modeling)实现了双向上下文学习,从而推动了自然语言处理领域的重大进展 18, 28, 37。
最近,图像领域的自回归模型也开始突破传统的光栅扫描顺序(raster order generation),向非光栅顺序(non-raster order)生成方式转变。SAIM 31 通过随机顺序预测图像块(image patches),克服了传统光栅扫描顺序的限制。MAR 24 证明了固定顺序和离散表示并非必需,并采用扩散损失(diffusion loss)来训练一种基于掩码图像建模(Masked Image Modeling)的连续表示模型。SAR 27 构建了一个统一框架,使因果学习(causal learning)能够适应任意的序列顺序和输出间隔,从而为自回归图像建模提供了一种更灵活且强大的方法。
上述研究启发我们探索双向生成(bidirectional generation)方法,以获取更精确的动作表示。不同于这些方法,我们用双向扩展策略(bidirectional expanding strategy)取代了传统的掩码预测(masked prediction)。
3. 方法
3.1. 问题形式化
我们的目标是在自回归策略中引入双向学习,从而在动作模态中实现一种多尺度"感受野"的近似。这一过程包括:首先生成一组稀疏的关键帧动作,这些关键帧覆盖整个轨迹范围;随后通过逐步填充与细化的过程,构建出完整的密集动作序列。该由粗到细的生成范式被称为 Dense Policy。我们方法的整体流程如图3所示;此外,在图2中我们阐明了它与主流策略的差异。
 图2. Dense Policy与现有策略的区别。整体生成策略通过建模序列的联合分布,在整个时间范围内一次性生成所有动作。对于ACT,这只需要一步变分推理;而对于DP,则需要多步扩散过程。在自回归策略(Autoregressive Policies)中,Next-Token预测以递归方式为后续时间步生成动作;Next-Chunk则以片段为单位生成动作,这两者都具有线性复杂度。相比之下,Dense Policy采用双向扩展的方法,实现分层动作预测,并在对数复杂度内完成整个生成过程。
图2. Dense Policy与现有策略的区别。整体生成策略通过建模序列的联合分布,在整个时间范围内一次性生成所有动作。对于ACT,这只需要一步变分推理;而对于DP,则需要多步扩散过程。在自回归策略(Autoregressive Policies)中,Next-Token预测以递归方式为后续时间步生成动作;Next-Chunk则以片段为单位生成动作,这两者都具有线性复杂度。相比之下,Dense Policy采用双向扩展的方法,实现分层动作预测,并在对数复杂度内完成整个生成过程。
 图3. Dense Policy概览。Dense Policy 接收不同模态的视觉输入以及可选的机器人本体感知信息。它采用统一的编码器,在分层动作表示与观测特征之间执行交叉注意力计算,从而促进双向扩展的稠密过程。在每一层的稠密处理过程中,最初表示为稀疏关键帧的动作将被逐步填充与细化为完整的预测序列,形成一个由粗到细的生成过程。
图3. Dense Policy概览。Dense Policy 接收不同模态的视觉输入以及可选的机器人本体感知信息。它采用统一的编码器,在分层动作表示与观测特征之间执行交叉注意力计算,从而促进双向扩展的稠密过程。在每一层的稠密处理过程中,最初表示为稀疏关键帧的动作将被逐步填充与细化为完整的预测序列,形成一个由粗到细的生成过程。
形式上,设 O t O_t Ot表示时间 t t t时刻的观测,该观测可能包括视觉输入(例如RGB图像或点云)以及可选的本体感知信息。我们的目标是在未来 T T T个时间步内,预测一段动作序列 A t : t + T = { a t , a t + 1 , ... , a t + T − 1 } A_{t:t+T}=\{a_t,a_{t+1},\dots,a_{t+T-1}\} At:t+T={at,at+1,...,at+T−1}。在本工作中, a t a_t at表示机器人末端执行器的TCP位姿(Tool Center Point pose)。
Tool Center Point(TCP) pose指的是机器人末端执行器(如夹具、焊枪、喷涂器等)的工作参考点的位姿,即位置和朝向。简单来说,就是描述这个工具在三维空间中的具体位置和方向。
在标准的生成式行为克隆框架下 5, 51,这一目标通常通过最大化在给定观测条件下的动作序列的似然 P ( A ∣ O ) P(A|O) P(A∣O)来实现。而Dense Policy将整体目标 A A A分解为多个层级的表示: A 1 , A 2 , ... , A log 2 T A^1,A^2,\dots,A^{\log_2 T} A1,A2,...,Alog2T,其中
A n = { a t + i n ∣ i m o d T 2 n = 0 , i ∈ N < T } (1) A^n = \{a^n_{t+i} \mid i \bmod \frac{T}{2^n} = 0,\ i \in \mathbb{N}_{<T} \} \tag{1} An={at+in∣imod2nT=0, i∈N<T}(1)
表示动作序列 A A A在第 n n n层的稀疏表示形式。这里从时间 t t t开始,以 T 2 n \frac{T}{2^n} 2nT为间隔,采样得到关键帧动作 a t + i n a^n_{t+i} at+in,其中 i i i是小于 T T T的自然数索引。这种分层采样方式实现了从稀疏到密集的多尺度建模。
表示在第 n n n层以不同粒度级别生成的中间动作序列,强调该层已在这 n n n个时间步内生成了动作的粗略表示,这些表示将在后续过程中被逐步细化与优化。需要注意的是,根据公式(1), A 0 A^0 A0为 ∅ \emptyset ∅,即表示初始的恒定动作向量。具体而言,我们设置 A 0 = 0 A^0=0 A0=0,以为迭代细化过程提供一个无偏的起点。这样可以使模型完全基于观测学习动作序列,而不对初始动作作出任何先验假设。因此,我们的模型可以被表述为:
P ( A ∣ O ) = ∏ i = 1 n P ( A i ∣ A i − 1 , A i − 2 , ... , A 0 , O ) (2) P(A|O)=\prod_{i=1}^{n}P(A^i|A^{i-1},A^{i-2},\dots,A^0,O) \tag{2} P(A∣O)=i=1∏nP(Ai∣Ai−1,Ai−2,...,A0,O)(2)
其中,模型以观察 O O O为条件,逐层生成动作表示 A i A^i Ai,每一层都依赖于前面所有层的动作表示 A i − 1 , A i − 2 , ... , A 0 A^{i-1},A^{i-2},\dots,A^0 Ai−1,Ai−2,...,A0,从而实现逐步细化的分层建模。
3.2. 观测编码器(Observation Encoder)
尽管 Dense Policy 的主要创新在于其动作头(Action Head)的设计,而非特定的视觉骨干网络,但它可以轻松集成到多种视觉骨干结构中,并适应不同类型的视觉输入。受5, 43的启发,Dense Policy 默认使用带有GroupNorm 45的ResNet18 14作为2D视觉编码器,并使用稀疏卷积网络(Sparse Convolutional Network)6作为3D编码器,除非另有说明。我们在后续实验中展示了:Dense Policy能够无缝继承其他视觉编码方法 49,且不会削弱Dense Policy动作头的性能。
在需要本体感知(proprioceptive awareness)的场景中,Dense Policy在训练过程中会随机遮蔽机器人末端执行器位姿的一部分。这有助于降低模型对固定位置相关动作的记忆偏倚风险,从而提升泛化性能。本体感知信息始终通过MLP编码至特征空间中。
3.3. 自回归稠密策略(Autoregressive Dense Policy)
在特征编码之后,动作以分层方式递归地进行扩展。具体来说,层级之间的每一次过渡都经历一个稠密过程,如图3中间列所示。来自前一层的动作 A n A^n An首先通过线性上采样进行扩展。当前层中上采样后的动作记作 A u p n A^n_{up} Aupn,其表示为:
A u p n = { a ~ t + j n ∣ j m o d T 2 n + 1 = 0 , j ∈ N < T } (3) A^n_{up} = \{\tilde{a}^n_{t+j} \mid j\bmod\frac{T}{2^{n+1}}=0,\ j\in\mathbb{N}_{<T}\} \tag{3} Aupn={a~t+jn∣jmod2n+1T=0, j∈N<T}(3)
其中, a ~ t + j n \tilde{a}^n_{t+j} a~t+jn表示通过线性插值方式从上一层动作序列 A n A^n An生成的插值动作,索引间隔为 T 2 n + 1 \frac{T}{2^{n+1}} 2n+1T,表示当前层的分辨率是上一层的一倍。这一过程用于初始化更高分辨率的动作预测,为后续细化阶段提供基础。
图3. Dense Policy概览。Dense Policy 接收不同模态的视觉输入以及可选的机器人本体感知信息。它采用统一的编码器,在分层动作表示与观测特征之间执行交叉注意力计算,从而促进双向扩展的稠密过程。在每一层的稠密处理过程中,最初表示为稀疏关键帧的动作将被逐步填充与细化为完整的预测序列,形成一个由粗到细的生成过程。
- 背景:分层生成与"稠密过程"是什么?
在该模型中,动作序列是从粗到细分层生成的。最初只生成很稀疏的关键帧(比如只有几个关键时刻的动作),然后逐层将动作序列"补全"或"细化",最终得到长度更长、分辨率更高的完整动作序列。
- 上一层动作 A n A^n An:这一层的动作序列较为稀疏,比如只有 4 个关键帧。
- 当前层动作 A n + 1 A^{n+1} An+1:我们希望让动作序列变得更密集,比如扩展到 8 个关键帧,甚至更多。
在层与层之间的"稠密过程(Dense Process)"中,模型先做线性上采样 (即对前一层的动作做插值,补齐中间的帧),得到一个初步的、更高分辨率的动作序列 A u p n A^n_{up} Aupn。然后,再通过与观测特征的交叉注意力进一步"细化"这些插值动作,生成更准确的动作。
- 线性上采样公式含义
原文中给出的公式是:
A u p n = { a ~ t + j n ∣ j m o d T 2 n + 1 = 0 , j ∈ N < T } A^n_{up} = \{\tilde{a}^n_{t+j} \mid j \bmod \frac{T}{2^{n+1}}=0,\ j\in\mathbb{N}_{<T}\} Aupn={a~t+jn∣jmod2n+1T=0, j∈N<T}
其中要点包括:
a ~ t + j n \tilde{a}^n_{t+j} a~t+jn:表示"插值"得到的动作。
- 假设上一层的动作序列是 A n = { a 0 n , a 1 n , a 2 n , ... } A^n = \{a^n_0, a^n_1, a^n_2, \dots\} An={a0n,a1n,a2n,...},但它是稀疏的,比如只在关键时刻 0、2、4、6......有定义。
- 通过"线性插值"可以补出中间时刻 1、3、5、7......的动作,这些就是 a ~ t + j n \tilde{a}^n_{t+j} a~t+jn。
- "线性插值"本质上就是在两个已知关键帧之间做一个直线插值,得到中间帧的动作值。
T 2 n + 1 \frac{T}{2^{n+1}} 2n+1T:表示当前层动作之间的步长。
- 如果上一层的分辨率是 T / 2 n T / 2^n T/2n,那么当前层要加倍分辨率 ,即变成 T / 2 n + 1 T / 2^{n+1} T/2n+1,也就是时序上更密集。
- m o d \bmod mod这个符号表示:只有当时间索引 j j j 与这个步长对齐(取模为 0)时,才会被视为一个关键位置,用来初始化下一层的动作。
"初始化"下一层动作:
- 通过这一步,下一层动作序列并不从零开始,而是先有一个"线性插值"的初步猜测 A u p n A^n_{up} Aupn。
- 然后再让模型(通过交叉注意力等机制)对这些插值动作进行"细化",使它们更加准确。
简而言之,这是一个 "先插值、再细化" 的过程,用于在层与层之间逐步提高动作序列的时间分辨率,实现从粗到细的递归生成。这个知识点属于序列生成与多尺度(多分辨率)动作建模的范畴,经常出现在机器人策略学习和深度生成模型中。
上采样动作中的每一个元素 a ~ t + j n \tilde{a}^n_{t+j} a~t+jn都是通过以下过程获得的:
a ~ t + j n = { a t + j if j m o d T 2 n = 0 1 2 ( a t + j − T 2 n + 1 + a t + j + T 2 n + 1 ) if j m o d T 2 n ≠ 0 a t + T − T 2 n if j = T − T 2 n + 1 (4) \tilde{a}^n_{t+j} = \begin{cases} a_{t+j} & \text{if }\ j\bmod\frac{T}{2^n}=0 \\ \frac{1}{2}\left(a_{t+j-\frac{T}{2^{n+1}}} + a_{t+j+\frac{T}{2^{n+1}}}\right) & \text{if }\ j\bmod\frac{T}{2^n} \ne 0 \\ a_{t+T-\frac{T}{2^n}} & \text{if }\ j = T - \frac{T}{2^{n+1}} \end{cases} \tag{4} a~t+jn=⎩ ⎨ ⎧at+j21(at+j−2n+1T+at+j+2n+1T)at+T−2nTif jmod2nT=0if jmod2nT=0if j=T−2n+1T(4)
也就是说,如果位置 j j j正好是上一层关键帧的位置,就直接复制该动作;
如果 j j j在关键帧之间,则通过相邻两个关键帧的平均值得到插值动作;
而在序列尾部的特殊情况,则使用倒数第二个关键帧的位置。
随后,Dense Policy将由视觉骨干网络预处理后的观测特征嵌入到一个BERT编码器(BERT Encoder)8中。该嵌入特征随后与上一层上采样得到的动作序列进行交叉注意力计算,采用4层编码器层(Encoder Layers),最终输出下一层的动作表示 A n + 1 A^{n+1} An+1:
A n + 1 = Enc ( A u p n , O ) (5) A^{n+1} = \text{Enc}(A^n_{up}, O) \tag{5} An+1=Enc(Aupn,O)(5)
其中, Enc ( ⋅ ) \text{Enc}(\cdot) Enc(⋅)表示带有交叉注意力机制的编码器模块,它以上采样后的动作 A u p n A^n_{up} Aupn和观测特征 O O O为输入,生成当前层级的动作表示 A n + 1 A^{n+1} An+1。
在这一转换过程中,上一层中的关键动作作为先验知识,引导下一层中更精细动作的预测,这体现了"稠密过程"(dense process)的概念。该过程会反复进行,直到序列扩展到目标时间范围的长度。最终的动作表示将通过一个线性层投影到预测的动作空间中。使用L2损失对动作预测进行监督,使其接近真实动作。
4. 仿真实验
4.1. 设置
基准测试集(Benchmarks) 在三个仿真基准测试集上对Dense Policy及其对比方法进行了评估,总计涵盖11个不同任务:
- Adroit 33:该基准在MuJoCo 39环境中使用多指Shadow机器人执行高灵巧度的操作任务。这些任务包括与可动结构物体和刚体的交互。
- DexArt 1:该基准在SAPIEN 47环境中使用Allegro机器人进行高精度的灵巧操作,主要聚焦于可动结构物体的操控任务。
- MetaWorld 48:主要在MuJoCo环境中运行,使用夹爪执行涉及可动结构物体和刚体的操作任务。该基准覆盖多种技能任务,并按难度分为:简单、中等、困难和极难。我们在所有除"简单"以外的难度等级上进行了测试。
对比方法(Baselines)
在仿真环境评估中,选用Diffusion Policy 5 和3D Diffusion Policy 49分别作为2D与3D的基准方法。由于本工作主要贡献在于策略动作头的设计(即自回归稠密过程),因此所有方法在视觉骨干网络上保持一致(2D使用Diffusion Policy中的ResNet18,3D使用3D Diffusion Policy中的MLP)。具体而言,我们用本文提出的稠密过程替代基线方法中的基于扩散过程的动作头,从而能够隔离并公平评估稠密策略所带来的性能提升。
为了确保实验公平性,Dense Policy与基线方法均使用相同的专家演示数据,并进行相同次数的训练迭代。此外,在部署阶段,两种方法都使用相同次数的观测和推理步骤。
演示数据(Demonstrations)
专家演示数据分别通过以下方式生成:MetaWorld使用脚本策略、Adroit使用VRL3 42智能体、DexArt使用PPO 34智能体。这些演示的平均成功率分别为98.7%、72.8%和近乎100%。训练中,Adroit与MetaWorld各使用10条演示,DexArt使用100条演示。
评估协议(Protocols)
遵循49中制定的协议,每项实验在3次独立试验中执行,随机种子分别为0、1和2。对于每个种子,策略在每200个训练轮次后进行20轮测试,并取成功率最高的前5轮的平均值作为评估指标。最终报告的性能是这三组种子下成功率的平均值和标准差。
4.2. 实验结果
如表1所示的实验结果表明,Dense Policy在2D和3D环境中的大多数任务中均稳定优于基线方法。具体而言,Dense Policy相比DP3表现出19%的成功率提升,相比DP则提升了27%。Dense Policy在代表性仿真任务中的完成轨迹如图4所示。
 表1. Dense Policy与基线方法在仿真任务中的详细性能表现。我们报告的是来自三个不同随机种子中成功率最高的前5次的平均值。
表1. Dense Policy与基线方法在仿真任务中的详细性能表现。我们报告的是来自三个不同随机种子中成功率最高的前5次的平均值。
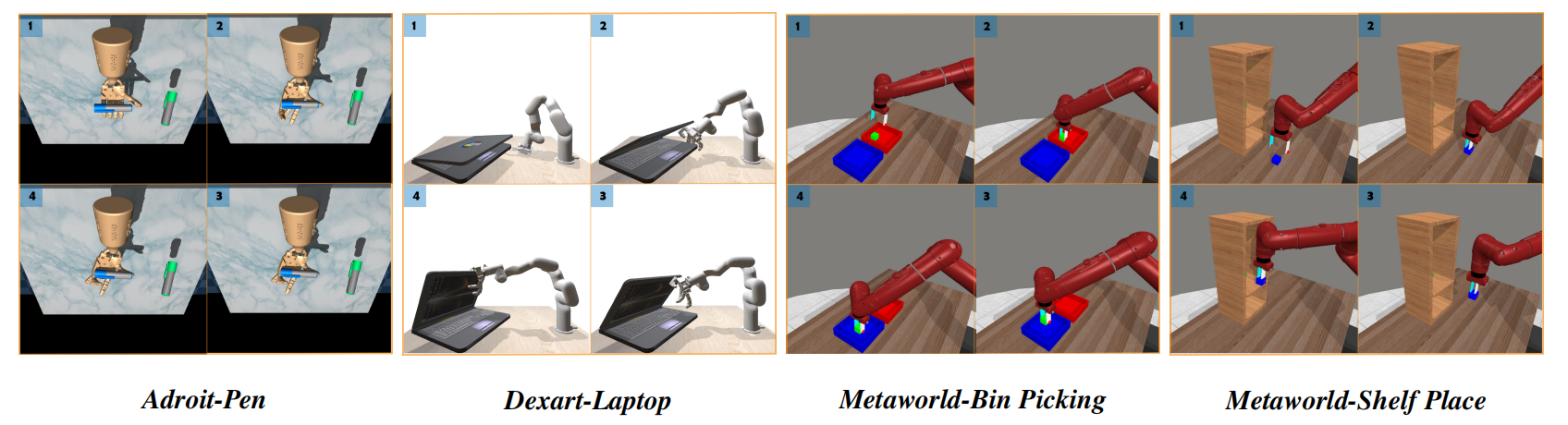
图4. 代表性仿真任务轨迹的可视化。
性能提升最显著的任务包括:shelf place 和bin picking (代表物体位姿估计任务);pen (代表高自由度的灵巧操作任务);以及Peg insert side(代表高接触约束的操作任务)。这些结果表明,在视觉骨干网络相同的前提下,Dense Policy展现出更强的下游能力,包括对被操控物体状态更精确的估计以及更稳健的运动规划。
例如像旋转笔(Rotating a pen)和Peg Insert Side这样的任务,对长时间范围内的误差极其敏感,而Dense Policy在动作序列上具备的双向建模能力使得动作执行更为平滑、连贯,从而显著提高了成功率。
4.3. 消融实验
我们在4个具有挑战性的操作任务上进行了消融实验------Door、Bin Picking、Shelf Place 和 Box Close------这些任务要求精确的物体定位以及对高自由度可动结构物体的操作能力。这些实验专门针对不同的自回归范式展开。我们将Dense Policy从双向架构修改为单向自回归学习框架,分别探索了"下一个标记"预测(next-token prediction)和"下一个片段"预测(next-chunk prediction)。考虑到仿真环境中的步骤数量有限,片段大小设为2。根据既定评估协议,我们记录了每种范式在每个测试点(直至收敛)时成功率最高的前5次的平均值。
如图5所示,双向预测在具有挑战性的任务上展现出更优的学习效率,能在更短时间内达到较好的性能,并表现出更高的成功率上限。这归因于在低容错任务中时间维度动作连贯性的重要性更高。双向、具标记感知(token-aware)的学习方式促进了更连贯、流畅的动作序列生成。
 图5. 不同自回归范式在四个不同任务中的学习效率表现。横轴表示测试时间点的编号;纵轴表示当前测试时间点中成功率最高的前5次的平均值。
图5. 不同自回归范式在四个不同任务中的学习效率表现。横轴表示测试时间点的编号;纵轴表示当前测试时间点中成功率最高的前5次的平均值。
5. 真实世界实验
5.1. 设置
平台:在真实世界实验中,我们使用配备Robotiq 2F-85夹爪的Flexiv Rizon机械臂进行物体操作。一个固定在上方的Intel RealSense D415 RGB-D相机从顶视角提供3D感知,采集全局工作空间的单视角点云。对于多视角2D感知,以上的顶视相机提供全局RGB图像,而一个安装在机械臂上的Intel RealSense D435 RGB-D相机提供局部RGB图像。机器人的工作空间被定义为位于机器人正前方的40 cm × 60 cm的矩形区域。所有硬件组件连接至一个配备Intel i9-10980XE CPU和NVIDIA 2080 Ti GPU的工作站,用于数据采集与评估。
任务:我们选择4个任务进行实验:将面包放入锅中(软体物体操作)、打开抽屉(可动结构物体操作)、倒球(6自由度任务)以及插花(长时间、多物体操作任务)。
演示数据:每个任务均通过使用触觉设备进行末端执行器远程操作的方式采集50条专家演示,所使用的设置和流程与9, 36, 43, 46中所述一致。
对比方法:我们选择DP 5与ACT 51这两种最广泛使用的方法作为我们的2D基线。同时,我们使用RISE 43作为3D基线方法,它是目前真实环境中表现最好的策略之一,亦为基于扩散的策略。与仿真实验保持一致,本实验的目标在于验证Dense Policy动作头在操作任务中的性能提升。因此,我们在2D视觉骨干网络中采用与DP相同的ResNet18,并在3D视觉骨干中采用RISE所引入的稀疏卷积网络 6,后者更适用于真实世界任务。
评估协议:除非另有说明,每种方法在每个任务上均执行20轮测试。所有方法均在场景初始配置随机但对齐的情况下进行评估。所有模型(包括Dense Policy)均训练1000轮,ACT除外。由于CVAE 13需要更大规模的训练以达到最佳性能,我们遵循ACT官方建议,将其训练轮数设为2000轮。
5.2. 性能表现
Put Bread into Pot 是一个涉及软体物体的抓取与放置任务,由于在接触过程中面包可能发生形变,因此对策略的鲁棒性提出了极高要求。
如表2所示,Dense Policy在该任务中优于现有基线方法,特别是在2D场景中表现出显著提升。我们观察到,当定位误差发生时,Dense Policy在抓取与放置过程中表现出更高的姿态调整概率。我们将此归因于其对序列依赖关系的更全面建模,从而生成了更不僵化、更具鲁棒性的动作。

Open Drawer 是一个包含两个阶段的操作任务,要求先精准抓取抽屉把手,然后执行水平拉动以打开抽屉。该任务的主要挑战在于:把手与抽屉表面之间间隙极小,哪怕是轻微的位姿估计误差也可能导致抓取失败或在拉动阶段发生夹爪滑动。因此,该任务对策略的预测精度极为敏感。
在此任务中,Dense Policy在2D场景下表现与基于扩散的方法相当,并优于ACT;而在3D场景中,Dense Policy优于扩散方法,如表2所示。我们验证了Dense Policy相较于扩散模型在动作预测上更为精确,从而提升了对可动结构物体的操作能力。
Pour Balls 是一个6自由度的操作任务,要求机械臂将装有10个球的杯子举起,并将球倒入碗中。该任务的困难主要体现在以下两方面:
i)杯子的直径沿高度变化,要求夹爪控制具有适应性。机器人在倒球过程中必须始终保持稳定的抓取,避免滑动,并确保正确的旋转。这需要策略具备泛化能力,能根据不同高度确定合适的夹爪开口度。
ii)任务的6自由度特性要求同时精准控制旋转和平移运动。这对策略在所有动作维度上的学习能力提出了全面挑战,有助于减弱其对特定自由度的偏倚。
如表2所示,该任务的性能评估基于以下指标:
Poured :至少成功将一个球倒入碗中的成功率;
Balls :每次实验平均成功倒入碗中的球数;
Complete:将10个球全部倒入碗中的成功率。
Dense Policy在关键的倒球指标上表现最佳,尤其是在平均倒球数量和完全倒球成功率方面。我们认为,这一优势来源于Dense Policy所学到的平滑、流畅的倒球动作,从而最小化了偏差误差。这一点优于扩散策略,后者更容易出现倒球偏差,从而影响球体的完全转移。
不过,在3D基准中,Dense Policy在"至少倒入一个球"的成功率上略低于RISE,主要原因在于夹爪偶尔过紧,造成持续性的抓取过度,这表明在自适应误差修正方面仍有进一步提升空间。

Flower Arrangement 是一个长时间跨度、多物体操作任务,要求依次将三个初始位置随机的花插入花瓶中。该任务的关键挑战在于其任务跨度较长,并且在某些物体配置中需要以特定顺序取花,以避免与其他花发生碰撞。这要求模型具备稳健的空间推理能力,以成功完成复杂的任务流程。
我们的实验表明,现有的2D策略(包括Dense Policy)普遍缺乏所需的复杂空间推理能力,这主要是由于2D表示在捕捉复杂空间关系方面的局限性。在3D场景中,如表2所示,Dense Policy明显优于RISE。
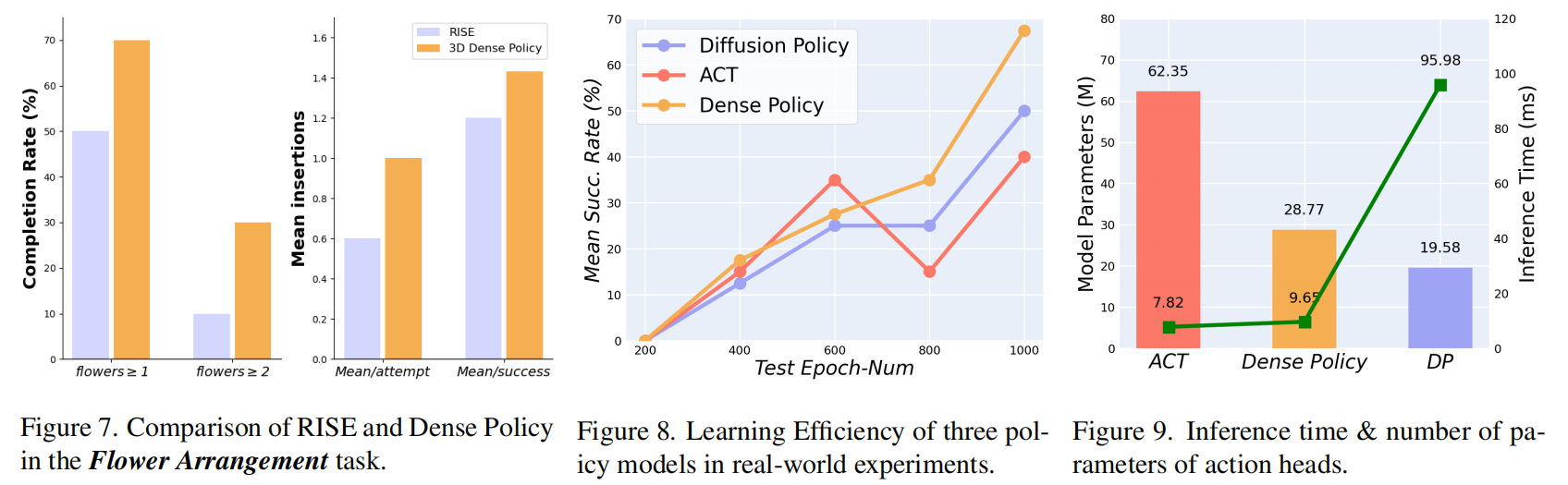
具体而言,Dense Policy在"至少插入一朵花"的成功率上提升了20%,并且每轮实验中平均插入的花数提升了0.4。此外,如图7所示,在"插入超过一朵花"的测试中,RISE的成功率为10%,而Dense Policy达到了显著的30%。在所有测试案例中(图7中标注为Mean/attempt),Dense Policy平均每轮插入1.0朵花,而RISE仅为0.6朵。在只统计插入成功的案例时(排除完全失败的情况,图7中标注为Mean/success),Dense Policy的平均插花数为1.43,RISE则为1.20,进一步表明Dense Policy在长时任务执行中具有更强的能力。
5.3. 高效的 Dense Policy
易于训练(Ease of Training)
我们认为,Dense Policy相比现有的生成策略具有更优的可训练性。扩散模型通常需要大量迭代步骤以准确建模样本分布。此外,基于VAE的策略尤其需要进行复杂的优化过程,因为其变分机制涉及编码与解码。其潜变量(或VQ-VAE中的codebook)引入了额外的优化目标,明显增加了训练负担。我们在2D场景下,以简单的初始部署条件,使用不同训练轮次(每200轮至1000轮)训练的模型,评估其在倒球任务中的成功率(即倒入球数与理论最大值的比值)。结果如图8所示,ACT的训练过程不稳定,最终性能也低于DP和Dense Policy。此外,DP的训练效率和最终性能均不及Dense Policy,这印证了我们的假设。
轻量化与快速推理(Lightweight and Rapid Inference)
我们对每个策略的动作头参数数量(不包含视觉骨干网络)以及其推理时间(在视觉骨干已编码信息基础上进行推理的时间)进行了量化,结果如图9所示。值得注意的是,Dense Policy在仅使用不到ACT一半参数数量的情况下,实现了与ACT相当的推理速度。尽管Dense Policy比DP多了9.19M的参数,但其推理速度却接近快了十倍。这是因为我们采用了对数级的递归预测机制,如图2所示,从而在保持高推理速度的同时,完成了分层生成。因此,我们强调,Dense Policy在轻量设计与快速推理之间实现了有效平衡,同时在性能上也超越了ACT与DP。
6. 结论
本文提出了Dense Policy,一种通过双向序列扩展实现高效模仿学习与高质量由粗到细动作生成的自回归策略。所提出的动作头在多种视觉输入模态下均展现出稳健的任务表现,并可兼容多种视觉骨干网络。此外,该策略在推理过程中表现出轻量化与计算高效性,同时在训练过程中展现出更高的效率与稳定性。
本研究的一个局限性在于,尚未探索将Dense Policy扩展为更通用的自回归视觉-语言-动作模型(VLA)的潜力,以及其在大规模基础模型中挑战基于扩散动作头的VLA时的稳定性。未来的研究将重点探索并发展Dense Policy在应对这些挑战中的潜力。