官网
简介
Elasticsearch 是一个分布式、开源的搜索引擎,专门用于处理大规模的数据搜索和分析。它基于 Apache Lucene 构建,具有实时搜索、分布式计算和高可扩展性,广泛用于 全文检索、日志分析、监控数据分析 等场景。
Elasticsearch 生态
- Elasticsearch:核心搜索引擎,负责存储、索引和搜索数据
- Kibana:可视化平台,用于查询、分析和展示Elasticsearch 中的数据。
- Logstash:数据处理管道,负责数据收集、过滤、增强和传输到 Elasticsearch。
- Beats:轻量级的数据传输工具,收集和发送数据到 Logstash 或 Elasticsearch。
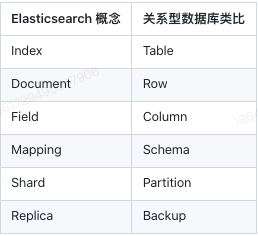
核心概念
-
索引(Index):类似于关系型数据库中的表,索引是数据存储和搜索的 基本单位。每个索引可以存储多条文档数据。
-
文档(Document):索引中的每条记录,类似于数据库中的行。文档以 JSON 格式存储。
-
字段(Field):文档中的每个键值对,类似于数据库中的列。
-
映射(Mapping):用于定义 Elasticsearch 索引中文档字段的数据类型及其处理方式,类似于关系型数据库中的 Schema 表结构,帮助控制字段的存储、索引和查询行为。
-
集群(Cluster):多个节点组成的群集,用于存储数据并提供搜索功能。集群中的每个节点都可以处理数据。
-
分片(Shard):为了实现横向扩展,ES 将索引拆分成多个分片,每个分片可以分布在不同节点上。
-
副本(Replica):分片的复制品,用于提高可用性和容错性。
全文索引
分词
Elasticsearch 的分词器会将输入文本拆解成独立的词条tokens,方便进行索引和搜索。分词的具体过程包括以下几步:
1.字符过滤:去除特殊字符、HTML 标签或进行其他文本清理。
2.分词:根据指定的分词器(analyzer),将文本按规则拆分成一个个词条。例如,英文可以按空格拆分,中文使用专门的分词器处理。
3.词汇过滤:对分词结果进行过滤,如去掉停用词(常见但无意义的词,如 "the"、"is" 等)或进行词形归并(如将动词变为原形)。
倒排索引
倒排索引与传统正排索引相反,通过词项到文档的映射实现快速检索。例如,正排索引类似书籍目录(文档→内容),而倒排索引类似索引页(关键词→页码)
- 分词与规范化:文档内容经分词器(如IK分词器)拆分为词项,去除停用词并进行规范化处理(如小写转换、词干提取) 例如,中文"生存还是死亡"分词为"生存""死亡",并记录其文档ID、位置等信息。
- 存储结构:倒排索引由**单词词典(Term Dictionary)和倒排列表(Posting List)**组成。词典存储词项及指向倒排列表的指针,倒排列表记录包含该词项的文档ID、词频(TF)、位置(POS)等信息
打分规则
打分规则(_Score)是用于衡量每个文档与查询条件的匹配度的评分机制。搜索结果的默认排序方式是按相关性得分(_score)从高到低。Elasticsearch 使用 BM25 算法 来计算每个文档的得分,它是基于词频、反向文档频率、文档长度等因素来评估文档和查询的相关性。
打分主要因素:
- 词频(TF, Term Frequency):查询词在文档中出现的次数,出现次数越多,得分越高。
- 反向文档频率(IDF, Inverse Document Frequency):查询词在所有文档中出现的频率。词在越少的文档中出现,IDF 值越高,得分越高。
- 文档长度:较短的文档往往被认为更相关,因为查询词在短文档中占的比例更大。
查询语法
DSL 查询(Domain Specific Language)
一种基于 JSON 的查询语言,它是 Elasticsearch 中最常用的查询方式。
json
{
"query": {
"match": {
"message": "Elasticsearch 是强大的"
}
}
}这个查询会对 message 进行分词,并查找包含 "Elasticsearch" 和 "强大" 词条的文档。
EQL( Event Query Language)
是一种用于检测和检索时间序列 事件 的查询语言,常用于日志和安全监控场景。
xml
process where process.name == "malware.exe"SQL 查询
Elasticsearch 提供了类似于传统数据库的 SQL 查询语法,允许用户以 SQL 的形式查询 Elasticsearch 中的数据。
sql
SELECT name, age FROM users WHERE age > 30 ORDER BY age DESC查询条件
match
用于全文检索,将查询字符串进行分词并匹配文档中对应的字段。适用于全文检索,分词后匹配文档内容。
json
{ "match": { "content": "你好" } }term
精确匹配查询,不进行分词。通常用于结构化数据的精确匹配,如数字、日期、关键词等。适用于字段的精确匹配,如状态、ID、布尔值等。
json
{ "term": { "status": "active" } }terms
匹配多个值中的任意一个,相当于多个 term 查询的组合。适用于多值匹配的场景。
json
{ "terms": { "status": ["active", "pending"] } }range
范围查询,常用于数字、日期字段,支持大于、小于、区间等查询。适用于数值或日期的范围查询。
json
{ "range": { "age": { "gte": 18, "lte": 30 } } }wildcard
通配符查询,支持 * 和 ?,前者匹配任意字符,后者匹配单个字符。适用于部分匹配的查询,如模糊搜索。
json
{ "wildcard": { "name": "鱼*" } }bool
组合查询,通过 must、should、must_not 等组合多个查询条件。适用于复杂的多条件查询,可以灵活组合。
json
{ "bool": { "must": [
{ "term": { "status": "active" } },
{ "range": { "age": { "gte": 18 } } } ] } }其他查询条件查看官网
数据同步
数据流向:mysql->ES
数据同步一般有 2 个过程:全量同步(首次)+ 增量同步(新数据)
1.定时任务
比如 1 分钟 1 次,找到 MySQL 中过去几分钟内(至少是定时周期的 2 倍)发生改变的数据,然后更新到 ES。
2.双写
写数据的时候,必须也去写 ES;更新删除数据库同理。
可以通过事务保证数据一致性,使用事务时,要先保证 MySQL 写成功,因为如果 ES 写入失败了,不会触发回滚,但是可以通过定时任务 + 日志 + 告警进行检测和修复。
3.Logstash 数据同步管道
一般要配合 消息队列 + beats 采集器
4.监听 MySQL Binlog
有任何数据变更时都能够实时监听到,并且同步到 Elasticsearch。一般不需要自己监听,可以使用现成的技术,比如 Canal 。
Canal 的核心原理:数据库每次修改时,会修改 binlog 文件,只要监听该文件的修改,就能第一时间得到消息并处理
环境搭建
1.安装Elasticsearch
查看是否兼容:文档
安装参考官方文档
Windows解压安装:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/zip-windows.html
其他系统安装:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/targz.html
进入es目录:.\bin\elasticsearch.bat
2.安装Kibana
只要是同一套技术,所有版本必须一致!
参考官方文档
安装Kibana
进入目录执行
xml
.\bin\kibana.bat实战(两种方法)
1.引入依赖
pom
<!-- elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>2.修改配置
yml
spring:
elasticsearch:
uris: http://xxx:9200
username: elastic
password: coder_swag3.测试
java
@SpringBootTest
public class ElasticsearchRestTemplateTest {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
private final String INDEX_NAME = "test_index";
// Index (Create) a document
@Test
public void indexDocument() {
Map<String, Object> doc = new HashMap<>();
doc.put("title", "Elasticsearch Introduction");
doc.put("content", "Learn Elasticsearch basics and advanced usage.");
doc.put("tags", "elasticsearch,search");
doc.put("answer", "Yes");
doc.put("userId", 1L);
doc.put("editTime", "2023-09-01 10:00:00");
doc.put("createTime", "2023-09-01 09:00:00");
doc.put("updateTime", "2023-09-01 09:10:00");
doc.put("isDelete", false);
IndexQuery indexQuery = new IndexQueryBuilder().withId("1").withObject(doc).build();
String documentId = elasticsearchRestTemplate.index(indexQuery, IndexCoordinates.of(INDEX_NAME));
assertThat(documentId).isNotNull();
}
// Get (Retrieve) a document by ID
@Test
public void getDocument() {
String documentId = "1"; // Replace with the actual ID of an indexed document
Map<String, Object> document = elasticsearchRestTemplate.get(documentId, Map.class, IndexCoordinates.of(INDEX_NAME));
assertThat(document).isNotNull();
assertThat(document.get("title")).isEqualTo("Elasticsearch Introduction");
}
// Update a document
@Test
public void updateDocument() {
String documentId = "1"; // Replace with the actual ID of an indexed document
Map<String, Object> updates = new HashMap<>();
updates.put("title", "Updated Elasticsearch Title");
updates.put("updateTime", "2023-09-01 10:30:00");
UpdateQuery updateQuery = UpdateQuery.builder(documentId)
.withDocument(Document.from(updates))
.build();
elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of(INDEX_NAME));
Map<String, Object> updatedDocument = elasticsearchRestTemplate.get(documentId, Map.class, IndexCoordinates.of(INDEX_NAME));
assertThat(updatedDocument.get("title")).isEqualTo("Updated Elasticsearch Title");
}
// Delete a document
@Test
public void deleteDocument() {
String documentId = "1"; // Replace with the actual ID of an indexed document
String result = elasticsearchRestTemplate.delete(documentId, IndexCoordinates.of(INDEX_NAME));
assertThat(result).isNotNull();
}
// Delete the entire index
@Test
public void deleteIndex() {
IndexOperations indexOps = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(INDEX_NAME));
boolean deleted = indexOps.delete();
assertThat(deleted).isTrue();
}
}4.通过kibana查看
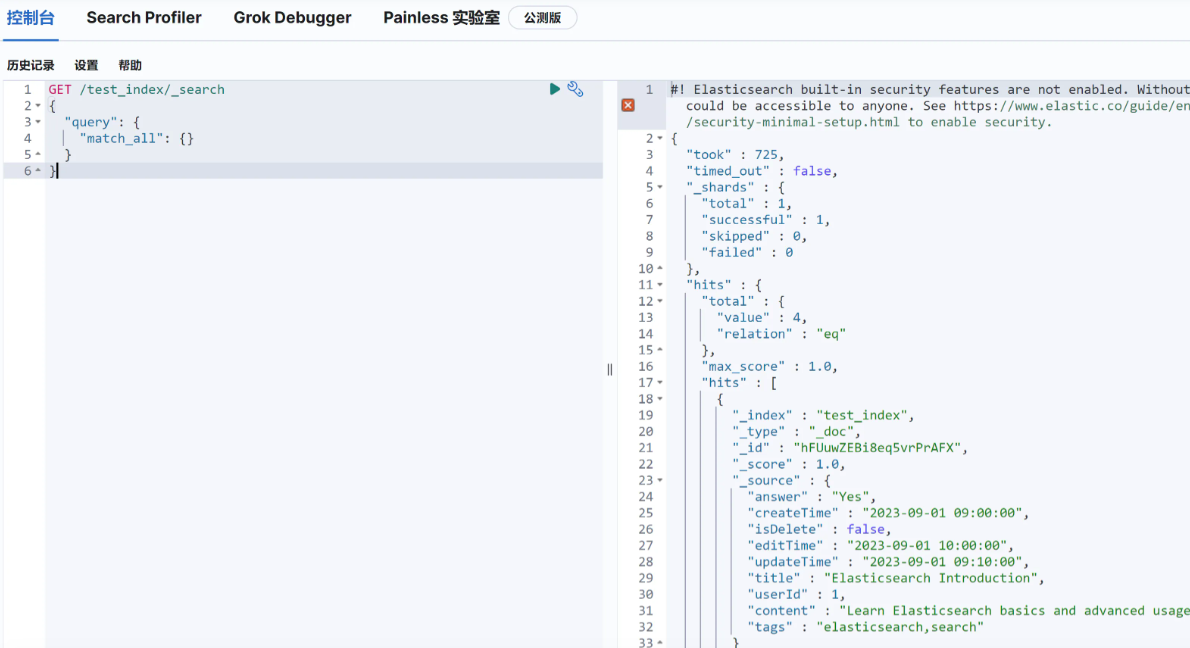
上述代码都是用 Map 来传递数据。记得之前使用 MyBatis 操作数据库的时候,都要定义一个数据库实体类,然后把参数传给这个实体类的对象就可以了,会更方便和规范。
没错,Spring Data Elasticsearch 也是支持这种标准 Dao 层开发方式的
5.编写 ES Dao 层
5.1 定义实体类
java
@Document(indexName = "question")
@Data
public class QuestionEsDTO implements Serializable {
private static final String DATE_TIME_PATTERN = "yyyy-MM-dd HH:mm:ss";
/**
* id
*/
@Id
private Long id;
/**
* 标题
*/
private String title;
/**
* 内容
*/
private String content;
/**
* 答案
*/
private String answer;
/**
* 标签列表
*/
private List<String> tags;
/**
* 创建用户 id
*/
private Long userId;
/**
* 创建时间
*/
@Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date createTime;
/**
* 更新时间
*/
@Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date updateTime;
/**
* 是否删除
*/
private Integer isDelete;
private static final long serialVersionUID = 1L;
/**
* 对象转包装类
*
* @param question
* @return
*/
public static QuestionEsDTO objToDto(Question question) {
if (question == null) {
return null;
}
QuestionEsDTO questionEsDTO = new QuestionEsDTO();
BeanUtils.copyProperties(question, questionEsDTO);
String tagsStr = question.getTags();
if (StringUtils.isNotBlank(tagsStr)) {
questionEsDTO.setTags(JSONUtil.toList(tagsStr, String.class));
}
return questionEsDTO;
}
/**
* 包装类转对象
*
* @param questionEsDTO
* @return
*/
public static Question dtoToObj(QuestionEsDTO questionEsDTO) {
if (questionEsDTO == null) {
return null;
}
Question question = new Question();
BeanUtils.copyProperties(questionEsDTO, question);
List<String> tagList = questionEsDTO.getTags();
if (CollUtil.isNotEmpty(tagList)) {
question.setTags(JSONUtil.toJsonStr(tagList));
}
return question;
}
}5.2定义 Dao 层
在 esdao 包中统一存放对 Elasticsearch 的操作,只需要继承 ElasticsearchRepository 类即可,该类集成大量的CRUD操作。
java
/**
* 题目 ES 操作
*/
public interface QuestionEsDao
extends ElasticsearchRepository<QuestionEsDTO, Long> {
/**
* 根据用户 id 查询
* @param userId
* @return
*/
//而且还支持根据方法名自动映射为查询操作,比如在 QuestionEsDao 中定义下列方法,就会自动根据 userId 查询数据。
List<QuestionEsDTO> findByUserId(Long userId);
}6.向ES全量写入数据
可以通过实现 CommandLineRunner 接口定义单次任务
java
// todo 取消注释开启任务
@Component
@Slf4j
public class FullSyncQuestionToEs implements CommandLineRunner {
@Resource
private QuestionService questionService;
@Resource
private QuestionEsDao questionEsDao;
@Override
public void run(String... args) {
// 全量获取题目(数据量不大的情况下使用)
List<Question> questionList = questionService.list();
if (CollUtil.isEmpty(questionList)) {
return;
}
// 转为 ES 实体类
List<QuestionEsDTO> questionEsDTOList = questionList.stream()
.map(QuestionEsDTO::objToDto)
.collect(Collectors.toList());
// 分页批量插入到 ES
final int pageSize = 500;
int total = questionEsDTOList.size();
log.info("FullSyncQuestionToEs start, total {}", total);
for (int i = 0; i < total; i += pageSize) {
// 注意同步的数据下标不能超过总数据量
int end = Math.min(i + pageSize, total);
log.info("sync from {} to {}", i, end);
questionEsDao.saveAll(questionEsDTOList.subList(i, end));
}
log.info("FullSyncQuestionToEs end, total {}", total);
}
}7.数据同步
根据之前的方案设计,通过定时任务进行增量同步,每分钟同步过去 5 分钟内数据库发生修改的题目数据。
7.1编写查询某个时间后更新的所有题目的方法
java
public interface QuestionMapper extends BaseMapper<Question> {
/**
* 查询题目列表(包括已被删除的数据)
*/
@Select("select * from question where updateTime >= #{minUpdateTime}")
List<Question> listQuestionWithDelete(Date minUpdateTime);
}7.2 编写增量同步到 ES 的定时任务
xml
// todo 取消注释开启任务
//@Component
@Slf4j
public class IncSyncQuestionToEs {
@Resource
private QuestionMapper questionMapper;
@Resource
private QuestionEsDao questionEsDao;
/**
* 每分钟执行一次
*/
@Scheduled(fixedRate = 60 * 1000)
public void run() {
// 查询近 5 分钟内的数据
long FIVE_MINUTES = 5 * 60 * 1000L;
Date fiveMinutesAgoDate = new Date(new Date().getTime() - FIVE_MINUTES);
List<Question> questionList = questionMapper.listQuestionWithDelete(fiveMinutesAgoDate);
if (CollUtil.isEmpty(questionList)) {
log.info("no inc question");
return;
}
List<QuestionEsDTO> questionEsDTOList = questionList.stream()
.map(QuestionEsDTO::objToDto)
.collect(Collectors.toList());
final int pageSize = 500;
int total = questionEsDTOList.size();
log.info("IncSyncQuestionToEs start, total {}", total);
for (int i = 0; i < total; i += pageSize) {
int end = Math.min(i + pageSize, total);
log.info("sync from {} to {}", i, end);
questionEsDao.saveAll(questionEsDTOList.subList(i, end));
}
log.info("IncSyncQuestionToEs end, total {}", total);
}
}