
🍑个人主页:Jupiter. 🚀 所属专栏:实战项目 欢迎大家点赞收藏评论😊


目录
-
- `🦅项目的背景`
- `🐍项目介绍`
- `🐏项目的宏观原理`
- `🐉搜索引擎技术栈和项⽬环境`
- `🐂项目编写`
-
- `📕认识正排索引与倒排索引`
- [`📚编写数据去标签与数据清洗的模块 Parser`](#
📚编写数据去标签与数据清洗的模块 Parser) -
- [🐆1. 去html标签](#🐆1. 去html标签)
- [🦀2. 编写parser模块](#🦀2. 编写parser模块)
- [`🐇3. 编写建⽴索引的模块 Index`](#
🐇3. 编写建⽴索引的模块 Index)
- [`🌸编写搜索引擎模块 Searcher`](#
🌸编写搜索引擎模块 Searcher) - [`🌻编写 http_server 模块`](#
🌻编写 http_server 模块) - [`🐻 编写前端模块`](#
🐻 编写前端模块) -
- `🚀加入CSS`
- [`🐟编写 js`](#
🐟编写 js)
- `🐕添加⽇志`
- [`🐱部署服务 `](#
🐱部署服务) - `🐅附件`
🦅项目的背景
在信息爆炸的时代,搜索引擎成为获取信息的核心工具。为了深入理解其技术原理并锻炼编程能力,我启动了BoostSiteSeeker项目。该项目旨在将理论知识与实际操作结合,夯实自己的编程基础并积累项目经验。
看看主流的搜索引擎的实现

可以发现:主流的搜索引擎都是根据用户输入的关键词,将索引到的内容,以一个一个的网页返回给用户(包括三个要素:网页标题+网页内容摘要+网页url)。
🐍项目介绍
BoostSiteSeeker 是一个基于 boost 文档的站内搜索引擎,当用户在页面上输入查询词后,就会快速的查询出相关的 boost 在线文档,根据权重构建网页返回给用户。
🐏项目的宏观原理
项自实现: 项目主要划分成下列模块
- 数据清洗模块 :针对 Boost 文档的 HTML 进行解析,去除 html 标签,提取出核心数据。
- 索引模块 :构建正排索引和倒排索引。
- 搜索模块 :基于索引,实现按查询词查找出匹配 HTML 文档的逻辑。
宏观原理图

🐉搜索引擎技术栈和项⽬环境
-
技术栈: C/C++ C++11, STL, 准标准库Boost,Jsoncpp,cppjieba,cpp-httplib
-
项⽬环境: Centos 7云服务器,vim/g++/Makefile , vs code
🐂项目编写
声明:只展示核心代码以及解析,如果全部列出很繁琐,不清晰。其他代码在文末有gitee链接,可以自行去查看。
📕认识正排索引与倒排索引
正排索引与倒排索引是数据库中常见的两种索引方式,下面使用例子讲解一下:
- 文档1:张三买了一个华为手机。
- 文档2:张三的手机品牌是华为。
正排索引:就是从⽂档ID找到⽂档内容(⽂档内的关键字)
| 文档id | 文档内容 |
|---|---|
| 1 | 张三买了一个华为手机 |
| 2 | 张三的手机品牌是华为 |
倒排索引:根据⽂档内容,分词,整理不重复的各个关键字,对应联系到⽂档ID的⽅案
对文档进行分词,方便建立倒排索引与查找:
- 文档1【张三买了一部华为手机】:张三 / 买 / 华为 / 手机
- 文档2【张三的手机品牌是华为】:张三 / 手机 / 品牌 / 华为
停⽌词:了,的,吗,a,the,⼀般我们在分词的时候可以不考虑;
| 关键字 | 文档id(权重) |
|---|---|
| 张三 | 文档1,文档2 |
| 买 | 文档1 |
| 华为 | 文档1,文档2 |
| 手机 | 文档1,文档2 |
| 品牌 | 文档2 |
简单模拟⼀次查找的过程:
- 用户输入:华为
- 查找过程:华为 ---> 在倒排索引中去查找 ---> 拿到文档ID(1,2) ---> 根据正排索引 ---> 找到文档内容 ---> 根据需求构建网页返回 。
📚编写数据去标签与数据清洗的模块 Parser
- boost官网 下载html文件(比如:boost_1_78_0/doc/html目录下的html文件),用它来建立索引。
🐆1. 去html标签
- <> : html的标签,这个标签对我们进⾏搜索是没有价值的,需要去掉这些标签,⼀般标签都是成对出现的!

预期⽬标:把每个⽂档都去标签,然后写⼊到同⼀个⽂件中,⽂档内部的三元素(标题,摘要,网址)用 \3 隔开,一个文档与文档之间用 \n 隔开
- 示例:title\3content\3url \n title\3content\3url \n title\3content\3url \n ...
利用\n分隔每一个html文件,可以方便后续我们使用getline()函数直接获取一个文档的全部内容(title\3des\3url)
🦀2. 编写parser模块
🌙parser模块代码的基本结构
cpp
// boost官网下载的原始html文件数据存放的文件的路径
const std::string src_data_path = "./data/input";
// 去标签等操作处理后的数据存放到的文件的路径
const std::string output_path = "./data/raw_html/raw.txt";
typedef struct Docinfo
{
std::string title; // 一个网页的标题
std::string content; // 一个网页的内容
std::string url; // 一个网页的url官网网址
} Docinfo_t;
bool Enumfilesname(const std::string &src_path,std::vector<std::string> *filesname_list);
bool ParserHtml(const std::vector<std::string> &filesname_list, std::vector<Docinfo_t> *results);
bool SaveHtml(const std::vector<Docinfo_t> &results, const std::string &output_path);
// 去标签,将input中放的原始的文档去掉标签后的html数据放到当前路径下的raw_html中
int main()
{
std::vector<std::string> filesname_list;
// 第一步:将原始文件中的文件名保存在vector中
if (!Enumfilesname(src_data_path,&filesname_list))
{
LOG(FATAL,"enum filesname error");
return 1;
}
// 第二步:通过filesname_list中的文件名,将每一个文件中的html标签去掉,将每一个文件关键信息放到Docinfo中,然后插入vector中
std::vector<Docinfo_t> results;
if (!ParserHtml(filesname_list, &results))
{
LOG(FATAL,"parser files error");
return 2;
}
// 第三步:将每一个文件的Docinfo_t信息格式化写入到output_path中
// 格式:: title\3content\3url\n title\3content\3url\n
if (!SaveHtml(results, output_path))
{
LOG(FATAL,"save files error");
return 3;
}
return 0;
}
bool Enumfilesname(const std::string &src_path, std::vector<std::string> *filesname_list)
{
return true;
}
bool ParserHtml(const std::vector<std::string> &filesname_list, std::vector<Docinfo_t> *results)
{
return true;
}
bool SaveHtml(const std::vector<Docinfo_t> &results, const std::string &output_path)
{
return true;
}🐀parser模块代码的具体实现与解析
- 这里使用boost开发库提供的方法
boost开发库的安装:
bash
sudo apt update #更新包列表
sudo apt install libboost-all-dev #安装Boost开发库提取title
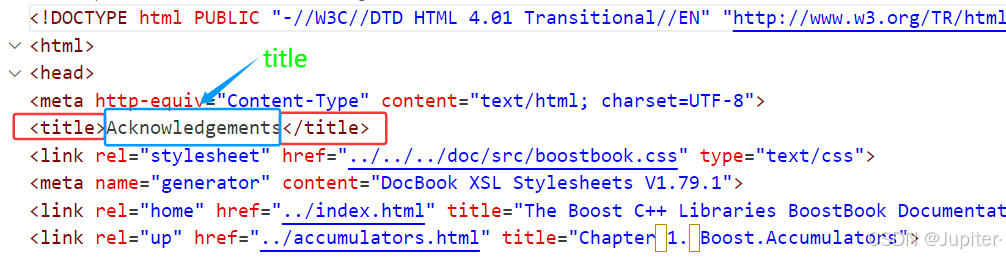
- 只需要找到的位置 与 的位置,中间就是title,使用string的类成员方法substr即可;
提取content
- 可以发现内容是在<>内容<>之间的,我们使用的是状态机方式实现的,在进⾏遍历的时候, 只要碰到了 > ,就意味着,当前的标签被处理完毕,紧接着就是内容, 只要碰到了 < 意味着内容结束了,紧接着就是新的标签开始了, 详情见代码。

构建URL
cpp
//构建URL boost库的官⽅⽂档,和我们下载下来的⽂档,是有路径的对应关系的
//URL 网址示例:https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html
//我们下载下来的url样例:boost_1_78_0/doc/html/accumulators.html
//我们拷⻉到我们项⽬中的样例:data/input/accumulators.html详情见代码;
实现代码以及代码解析见代码注释
cpp
bool Enumfilesname(const std::string &src_path, std::vector<std::string> *filesname_list){
namespace fs = boost::filesystem;
//利用src_path构建一个filesystem中的path对象
fs::path root_path(src_path);
//利用boost::filesystem里面的exists结构判断文件名是否存在
if (!fs::exists(root_path))
{
LOG(FATAL,"%s not exists",src_path.c_str());
return false;
}
// 定义一个空的迭代器,用于判断是否结束。
fs::recursive_directory_iterator end;
for (fs::recursive_directory_iterator iter(root_path); iter != end; iter++)
{
// 1. 利用boost::filesystem里面的is_regular_file接口判断是否是一个普通文件
if (!fs::is_regular_file(*iter)) continue;
// 2. 利用path类中extension()成员函数的 判断文件后缀是否是.html
if (iter->path().extension() != ".html") continue;
// 3. 文件符合要求,将文件名插入到vector中,方便后续进行Parser
filesname_list->push_back(iter->path().string());
}
return true;
}
cpp
bool ParserHtml(const std::vector<std::string> &filesname_list, std::vector<Docinfo_t> *results)
{
//依次读取文件名,将其打开,将内容读取并返回
for (const std::string& file : filesname_list)
{
// 第一步:读取文件,放到一个string中
std::string fileResult;
//这里的ReadFile函数就是打开一个文件,将内容读取出来,放到fileResult里面返回出来
if (!ns_util::FileUtil::ReadFile(file, &fileResult)){
LOG(FATAL,"Read file error");
continue;
}
Docinfo_t Doc; //存放一个html文件的三元素(title+desc+url)
// 第二步:提取文件的标题
if (!ParserTitle(fileResult, &Doc.title)){
continue;
}
// 第三步:提取文件内容
if (!ParserConent(fileResult, &Doc.content)){
continue;
}
// 第四步:提取文件url
if (!ParserUrl(file, &Doc.url)){
continue;
}
// 第五步:将Doc放入results中,方便后面SaveHtml
results->push_back(std::move(Doc)); // move进行优化
}
return true;
}
//提取标题 很简单,一看就懂 不赘述
static bool ParserTitle(const std::string &fileresult, std::string *title)
{
int begin = fileresult.find("<title>");
if (begin == std::string::npos){
return false;
}
int end = fileresult.find("</title>");
if (end == std::string::npos){
return false;
}
begin += std::string("<title>").size();
if (begin > end){
return false;
}
*title = fileresult.substr(begin, end - begin);
return true;
}
//提取内容
static bool ParserConent(const std::string &fileresult, std::string *content)
{
// 编写一个简易状态机来实现
enum Status{
LABEL, //标签
CONTENT //内容
};
enum Status s = LABEL; //html最开都是以标签开始的
for (char c : fileresult){
switch (s)
{
case LABEL:
if (c == '>') s = CONTENT; //> 标签结束标志 后面就是正文
break;
case CONTENT:
if (c == '<') s = LABEL; //< 正文结束标志 也代表标签开始
else //正文
{
if (c == '\n') c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}
//构建URL boost库的官⽅⽂档,和我们下载下来的⽂档,是有路径的对应关系的
//URL 网址示例:https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html
//我们下载下来的url样例:boost_1_78_0/doc/html/accumulators.html
//我们拷⻉到我们项⽬中的样例:data/input/accumulators.html
static bool ParserUrl(const std::string &file_path, std::string *url){
std::string url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
//file_path是该文件在服务器上的路径 例如:./data/input/####.html
//只需要保留####.html 然后与官网上的拼接即可
std::string url_tail = file_path.substr(src_data_path.size());
*url = url_head + url_tail;
return true;
}🐇3. 编写建⽴索引的模块 Index
cpp
namespace ns_index
{
struct Docinfo_t
{
std::string title;
std::string content;
std::string url;
uint64_t doc_id; //构建正排拉链后会返回一个Docinfo_t的对象,这里保存的文档id是为了填充invertedElem的id
};
struct invertedElem
{
std::string word; //关键词
uint64_t doc_id; //对应的文档id
int weight; //权重
invertedElem() : weight(0) {}
};
typedef std::vector<invertedElem> inverted_list; // 倒排拉链
class index
{
private:
// 正排索引的数据结构⽤数组,数组的下标天然是⽂档的ID,索引到文档
std::vector<Docinfo_t> forward_index;
// 倒排索引一定是一个关键字和一组(个)InvertedElem对应[关键字和倒排拉链的映射关系]
// 因为一个关键字可能会对应多个文档ID
std::unordered_map<std::string, inverted_list> inverted_index;
public:
index() {}
~index() {}
public:
//根据文档id,获取文档内容
Docinfo_t *GetForwardIndex(uint64_t doc_id)
{
if (doc_id >= forward_index.size())
return nullptr;
return &(forward_index[doc_id]);
}
//根据关键词,获取倒排拉链
inverted_list *GetInvertedList(const std::string &word)
{
auto iter = inverted_index.find(word);
if (iter == inverted_index.end())
return nullptr;
return &(iter->second);
}
// 用Parser处理完的数据来建立建正排和倒排索引 input:./data/raw_html
bool BulidIndex(const std::string &input)
{
std::ifstream in(input, std::ios::in | std::ios::binary);
if (!in.is_open())
return false;
std::string line;
while (std::getline(in, line))
{
Docinfo_t *Doc = BulidForwardIndex(line); // 建立正排索引
if (nullptr == Doc)
continue;
// 建立倒排索引
BulidInvertedIndex(*Doc);
}
in.close();
return true;
}
};
}建⽴正排的基本代码
cpp
//根据一个html文件的\3 \3 \n 的string,构建一个Docinfo_t对象,放入forward_index中
Docinfo_t *BulidForwardIndex(const std::string &line)
{
std::vector<std::string> result;
const std::string sep = "\3";
//将获取的一行字符串:也就是 title\3conttent\3url\n 以sep(\3)进行切割 放到result里面
//然后依次读取result里面内容 就拿到了title content url
ns_util::StringUtil::StringCut(line, &result, sep);
if (result.size() != 3) //说明不是一个完整的网页信息
return nullptr;
Docinfo_t Doc;
Doc.title = result[0];
Doc.content = result[1];
Doc.url = result[2];
Doc.doc_id = forward_index.size();
forward_index.push_back(std::move(Doc)); //放入正排索引中
return &forward_index.back();
}建⽴倒排的基本代码
下面的分词操作使用的cpppjieba里面的方法
jieba的安装与使用
- 对于分词,我们可以直接使用cppjieba分词工具即可。我们执行下面的命令将github上面的jieba库下载到本地。
bash
git clone git clone https://gitcode.net/qq_55172408/cppjieba.git- 如下是cppjieba的具体内容:
bash
$ tree cppjieba/
cppjieba/
├── appveyor.yml
├── ChangeLog.md
├── CMakeLists.txt
├── deps
│ ├── CMakeLists.txt
│ ├── gtest
│ │ ├── CMakeLists.txt
│ │ //.......
│ │
│ └── limonp
│ ├── ArgvContext.hpp
│ ├── BoundedQueue.hpp
│ //......
├── dict
│ ├── hmm_model.utf8
│ ├── pos_dict
│ │ ├── char_state_tab.utf8
│ //......
│
├── include
│ └── cppjieba
│ ├── DictTrie.hpp
│ ├── FullSegment.hpp
│ ├── HMMModel.hpp
│ ├── HMMSegment.hpp
│ ├── Jieba.hpp
│ ├── KeywordExtractor.hpp
│ ├── limonp
│ │ ├── ArgvContext.hpp
│ │ ├── BlockingQueue.hpp
│ │ ├── BoundedBlockingQueue.hpp
│ │ ├── BoundedQueue.hpp
│ │ ├── Closure.hpp
│ //......
└── test
├── CMakeLists.txt
├── demo.cpp
├── load_test.cpp
//.....
17 directories, 136 files
[xiaomaker@VM-28-13-centos jieba]$这里我们只需要关注的是两个文件:
- 头文件: cppjieba/include
- 字典: cppjiba/dict
下面我们了解jieba分词的使用,里面存在一个demo.cpp文件供我们测试。
bash
$ pwd
....../cppjieba/test
$ ll
total 20
-rw-rw-r-- 1 X X 148 Feb 14 14:02 CMakeLists.txt
-rw-rw-r-- 1 X X 2797 Feb 14 14:02 demo.cpp
-rw-rw-r-- 1 X X 1532 Feb 14 14:02 load_test.cpp
drwxrwxr-x 4 X X 4096 Feb 14 14:02 testdata
drwxrwxr-x 2 X X 4096 Feb 14 14:02 unittest注意:直接编译,它会报错。
bash
$ g++ demo.cpp
demo.cpp:1:30: fatal error: cppjieba/Jieba.hpp: No such file or directory
#include "cppjieba/Jieba.hpp"
^~~~~~~~~~~~~~~~~~~~ ^
compilation terminated.这是因为我们这里的库和头文件的路径是不对的,这里添加软链接即可。链接的路径是自己下载jieba的路径。
bash
$ ln -s .../jieba/cppjieba/include/include
$ ln -s .../jieba/cppjieba/dict/dict
$ ll
total 20
-rw-rw-r-- 1 X X 148 Feb 14 14:02 CMakeLists.txt
-rw-rw-r-- 1 X X 2853 Feb 24 12:16 demo.cpp
lrwxrwxrwx 1 X X 45 Feb 24 12:18 dict -> .../jieba/cppjieba/dict/
lrwxrwxrwx 1 X X 48 Feb 24 12:17 include -> .../jieba/cppjieba/include/
-rw-rw-r-- 1 X X 1532 Feb 14 14:02 load_test.cpp
drwxrwxr-x 4 X X 4096 Feb 14 14:02 testdata
drwxrwxr-x 2 X X 4096 Feb 14 14:02 unittest接下来就需要修改demo.cpp的头文件。
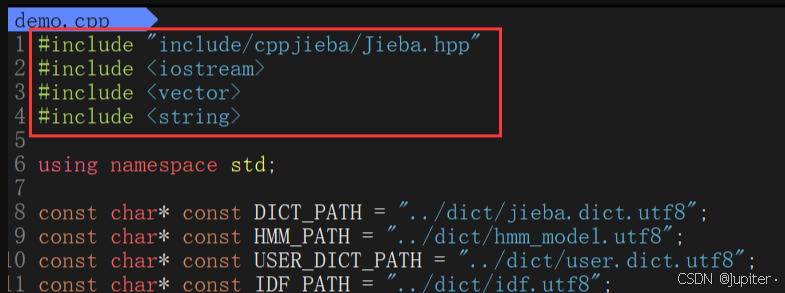
我们继续编译,我们发现还是出现错误。
这是因为找不到 limonp/Logging.hpp文件。这时候我们只需要将deps/limonp目录拷贝到include/cppjieba当中即可。
bash
$ cp deps/limonp/ include/cppjieba/ -rf这样我们就可以编译通过了:

项目中使用的jieba分词工具对指定的string进行分词,代码如下:
cpp
const char *const DICT_PATH = "./dict/jieba.dict.utf8";
const char *const HMM_PATH = "./dict/hmm_model.utf8";
const char *const USER_DICT_PATH = "./dict/user.dict.utf8";
const char *const IDF_PATH = "./dict/idf.utf8";
const char *const STOP_WORD_PATH = "./dict/stop_words.utf8";
class JiebaUtil
{
private:
static cppjieba::Jieba jieba;
public:
//对src字符串进行jieba分词,然后将分词后的结果放入out数组中
static void JiebaStringCut(const std::string &src, std::vector<std::string> *out)
{
jieba.CutForSearch(src, *out);
}
};
cppjieba::Jieba JiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
cpp
//根据建立正排索引返回的Docinfo_t对象建立倒排索引
void BulidInvertedIndex(const Docinfo_t &Doc)
{
//统计词频的结构体 根据词频计算权重,根据权重后面需要排序
struct word_cnt
{
int title_cnt; //标题中出现的次数
int content_cnt; //内容中出现的次数
word_cnt() : title_cnt(0), content_cnt(0) {}
};
//对应的是一个关键词在标题中出现的次数 与 在内容中出现的次数word_cnt
std::unordered_map<std::string, word_cnt> words_map;
//对标题进行分词,并且统计词频
std::vector<std::string> title_words;
ns_util::JiebaUtil::JiebaStringCut(Doc.title, &title_words);
for (std::string s : title_words)
{
boost::to_lower(s); //在统计与搜索的过程中,我们都是用小写
words_map[s].title_cnt++;
}
//对内容进行分词,并且统计词频
std::vector<std::string> content_words;
ns_util::JiebaUtil::JiebaStringCut(Doc.content, &content_words);
for (std::string s : content_words)
{
boost::to_lower(s);
words_map[s].content_cnt++;
}
#define X 10
#define Y 1
//std::unordered_map<std::string, word_cnt> words_map
//words_map里面存放的是该html标题与内容进行分词后,
//[每一个词对应的在标题与内容中出现的次数(词频结构体)的映射关系]
for (auto &words_pair : words_map)
{
invertedElem elem;
elem.doc_id = Doc.doc_id; //这里体现了为什么Docinfo里面需要保存doc_id
elem.word = words_pair.first;
//权重的计算
elem.weight = X * words_pair.second.title_cnt + Y * words_pair.second.content_cnt;
//根据关键词,利用map []的特性,如果map中存在该词,则返回对应的倒排拉链,
//如果不存在,则插入,再返回对应的倒排拉链
inverted_list &invertedlist = inverted_index[words_pair.first];
//讲填充好的invertedElem 插入到返回的倒排拉链中
invertedlist.push_back(std::move(elem));
}
}倒排索引

完上述所有工作后可以将index设置为单例模式。简单不赘述。可以查看文末gitee链接上源代码。
🌸编写搜索引擎模块 Searcher
- jsoncpp安装与使用在 计算机网络专栏:文章:自定义协议 提过,可以跳转过去查看,这里不再赘述。
Searcher模块的框架
搜索引擎模块提供的服务:
- 将清洗后的html文件用来建立索引(Searcher模块中包含inidex成员,直接调用相应的函数方法即可);
- 根据用户提供的quary,进行数据搜索(将quary进行分词,根据各词进行index查找,汇总查找的结果,根据结果进行权重排序,构建一个一个的json串返回)
cpp
class Searcher{
private:
ns_index::index *_index; //提供系统进行查找的索引
public:
Searcher() {}
~Searcher() {}
public:
//初始化Searcher 就是要先根据input文件建立索引
void InitSearcher(const std::string &input)
{
//1. 获取或者创建index对象
//2. 根据index对象建⽴索引
}
//提供搜索的函数 根据一个quary 进行搜索,返回一个json串
void Search(const std::string &quary, std::string *json_string)
{
//1.[分词]:对我们的query进⾏按照searcher的要求进⾏分词
//2.[触发]:就是根据分词的各个"词",进⾏index查找
//3.[合并排序]:汇总查找结果,按照相关性(weight)降序排序
//4.[构建]:根据查找出来的结果,构建json串 -- jsoncpp
}
};
cpp
//初始化Searcher 就是要先根据input文件建立索引
void InitSearcher(const std::string &input)
{
// 1. 根据input获取一个索引index index需要单例模式化
_index = ns_index::index::Getinstance();
// 2. 根据index 建立索引
_index->BulidIndex(input);
}
struct InvertedElemPrint{
uint64_t doc_id;
int weight;
std::vector<std::string> words;
InvertedElemPrint() : doc_id(0), weight(0) {}
};
//提供搜索的函数 根据一个quary 进行搜索,返回一个json串
void Search(const std::string &quary, std::string *json_string){
//[分词] 将quary进行分词
std::vector<std::string> quary_words;
ns_util::JiebaUtil::JiebaStringCut(quary, &quary_words);
//[触发] 根据quary的分词结果,进行index索引
// 存放一个关键词所对应的elem
std::vector<InvertedElemPrint> invertedlist_all;
std::unordered_map<uint64_t, InvertedElemPrint> tokens_map; //利用其进行去重
//根据搜索关键词获取 倒排拉链
for (std::string s : quary_words){
boost::to_lower(s);
ns_index::inverted_list *invertedlist = _index->GetInvertedList(s);
if (nullptr == invertedlist)
{
continue;
}
for (const auto &elem : *invertedlist){
auto &elemPrint = tokens_map[elem.doc_id];
elemPrint.doc_id = elem.doc_id;
elemPrint.weight += elem.weight;
elemPrint.words.push_back(elem.word);
}
}
for (const auto &elem : tokens_map){
invertedlist_all.push_back(std::move(elem.second));
}
//[合并排序] 根据index搜索结果进行合并并且排序(根据weight)
std::sort(invertedlist_all.begin(), invertedlist_all.end(),\
[](const InvertedElemPrint &e1, const InvertedElemPrint &e2)
{
return e1.weight > e2.weight;
});
//[构建]将合并的并排序的内容构建一个一个的json_string返回给浏览器,用户
Json::Value root;
for (auto &elem : invertedlist_all){
ns_index::Docinfo_t *doc = _index->GetForwardIndex(elem.doc_id);
if (nullptr == doc){
continue;
}
Json::Value e;
e["title"] = doc->title;
e["desc"] = GetDesc(doc->content, elem.words[0]); // 这里要的是文档的部分信息,并非全部信息,即摘要
e["url"] = doc->url;
//for debug
// e["id"] = (int)elem.doc_id;
// e["weight"] = elem.weight; //int->string
root.append(e);
}
//Json::StyledWriter writer;
Json::FastWriter writer;
*json_string = writer.write(root);
}
// 截取关键词附近,前50个字节,后100的字节的内容当摘要
std::string GetDesc(const std::string &html_content, const std::string &word)
{
const int prev_len = 50;
const int next_len = 100;
//html_content的数据是原始的,但是这里的word是小写的,就有可能再查找的时候查找不到
auto iter = std::search(html_content.begin(),html_content.end(),word.begin(),word.end(),\
[](int x,int y){ return std::tolower(x) == std::tolower(y); } );
if(iter==html_content.end()) return "None";
int pos = std::distance(html_content.begin(),iter);
int start = 0;
int end = html_content.size() - 1;
if (pos - prev_len > start) start = pos - prev_len;
if (pos + next_len < end) end = pos + next_len;
if (start >= end) return "None";
std::string desc = html_content.substr(start, end - start);
desc += "...";
return desc;
}🌻编写 http_server 模块
网络部分我们直接使用cpp-httplib库,
注意:cpp-httplib在使⽤的时候需要使⽤较新版本的gcc,centos 7下默认gcc 4.8.5
升级gcc
bash
# 安装scl
$ sudo yum install centos-release-scl scl-utils-build
# 安装新版本gcc
$ sudo yum install -y devtoolset-7-gcc devtoolset-7-gcc-c++
# 启动: 细节,命令⾏启动只能在本会话有效
$ scl enable devtoolset-7 bash安装 cpp-httplib
最新的cpp-httplib在使⽤的时候,如果gcc不是特别新的话有可能会有运⾏时错误的问题,建议:cpp-httplib 0.7.15,下载zip安装包,上传到服务器即可
基本的测试
http_server.cc
cpp
#include "cpp-httplib/httplib.h"
int main()
{
httplib::Server svr;
svr.Get("/hi", [](const httplib::Request &req, httplib::Response &rsp)
{ rsp.set_content("你好,世界!", "text/plain; charset=utf-8"); });
svr.listen("0.0.0.0", 8081);
return 0;
}编译运行结果:
bash
$ netstat -ntlp
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:44227 0.0.0.0:* LISTEN 1903/node
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:8081 0.0.0.0:* LISTEN 4191/./http_server
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN - - 一般而言我们需要有一个wwwroot目录,把前端网页内容信息或则一些资源就可以统一放到该根目录里面。
在当前目录下创建一个wwwroot目录
在服务器上面设置跟目录:
cpp
#include "cpp-httplib/httplib.h"
const std::string root_path = "./wwwroot";
int main()
{
httplib::Server svr;
// 设置跟目录
svr.set_base_dir(root_path.c_str());
svr.Get("hi", [](const httplib::Request& req, httplib::Response& rsp)
{
rsp.set_content("hello word!", "text/plain; charset=utf-8");
});
svr.listen("0.0.0.0", 8080);
return 0;
}由于我们创建的根目录里面什么都没有,所以启动后访问什么都没有,这时候我们写一个简单的网页放到根目录中
html代码如下:
html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>for test</title>
</head>
<body>
<h1>你好,世界</h1>
<p>这是⼀个httplib的测试⽹⻚</p>
</body>
</html>再次访问

开始编写search服务端
cpp
const std::string root_path = "./wwwroot"; // 网页内容信息
const std::string input = "./data/raw_html/raw.txt"; // 下载的html文件处理后的存放的路径
int main()
{
ns_searcher::Searcher Search; // 创建一个Searcher对象,供后面拿到用户的所搜关键字进行搜索
Search.InitSearcher(input); // 初始化Searcher对象,(包含建立索引)
// 引入httplib库,创建一个httplib::Server对象Svr,用于构建一个HTTP服务端
httplib::Server Svr;
// 设置服务器的基目录,这个目录通常用于静态文件服务,比如HTML、CSS、JS等文件的根目录
Svr.set_base_dir(root_path.c_str());
// 为服务端添加一个GET请求的处理函数,当客户端访问/s路径时,会触发这个函数
// 使用了lambda表达式来捕获Search对象,并处理请求和响应
Svr.Get("/s", [&Search](const httplib::Request &Req, httplib::Response &Res)
{
// 检查请求中是否包含名为"word"的参数,如果没有,则返回错误消息
if(!Req.has_param("word"))
{
Res.set_content("NO Search key word","text/plain:charset=utf-8");
return;
}
// 从请求中获取名为"word"的参数值
std::string word = Req.get_param_value("word");
// 调用Search对象的Search方法
std::string json_string;
Search.Search(word,&json_string);
if(json_string.empty())
{
Res.set_content("未找到相关内容,请检查输入是否正确 ","text/plain:charset=utf-8");
}
else // 如果找到了内容,则将json_string返回
{
Res.set_content(json_string,"application/json");
}
});
// 使服务器监听所有网络接口(0.0.0.0)上的8081端口,等待并处理客户端的请求
Svr.listen("0.0.0.0", 8081);
return 0;
}🐻 编写前端模块
直接使用vscode编写即可
关于 html,css,js
-
html: 是⽹⻚的⻣骼 -- 负责⽹⻚结构
-
css:⽹⻚的⽪⾁ -- 负责⽹⻚美观的
-
js(javascript):⽹⻚的灵魂---负责动态效果,和前后端交互
我们的预期效果

基于上面的预期,编写 html整体结构
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title></title>
</head>
<body>
<div class="container">
<div class="search">
<input type="text" value="输入搜索关键字...">
<button>搜索</button>
</div>
<div class="result">
<div class="item">
<a href="#">标题</a>
<p>xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx摘要</p>
<i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i>
</div>
<div class="item">
<a href="#">标题</a>
<p>xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx摘要</p>
<i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i>
</div>
</div>
</div>
</body>
</html>🚀加入CSS
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>boost 搜索引擎</title>
<style>
/* 去掉网页中的所有的默认内外边距,html的盒子模型 */
* {
/* 设置外边距 */
margin: 0;
/* 设置内边距 */
padding: 0;
}
/* 将我们的body内的内容100%和html的呈现吻合 */
html,
body {
height: 100%;
}
/* 类选择器.container */
.container {
/* 设置div的宽度 */
width: 800px;
/* 通过设置外边距达到居中对齐的目的 */
margin: 0px auto;
/* 设置外边距的上边距,保持元素和网页的上部距离 */
margin-top: 15px;
}
/* 复合选择器,选中container 下的 search */
.container .search {
/* 宽度与父标签保持一致 */
width: 100%;
/* 高度设置为52px */
height: 52px;
}
/* 先选中input标签, 直接设置标签的属性,先要选中, input:标签选择器*/
/* input在进行高度设置的时候,没有考虑边框的问题 */
.container .search input {
/* 设置left浮动 */
float: left;
width: 600px;
height: 50px;
/* 设置边框属性:边框的宽度,样式,颜色 */
border: 1px solid black;
/* 去掉input输入框的有边框 */
border-right: none;
/* 设置内边距,默认文字不要和左侧边框紧挨着 */
padding-left: 10px;
/* 设置input内部的字体的颜色和样式 */
color: #CCC;
font-size: 15px;
}
/* 先选中button标签, 直接设置标签的属性,先要选中, button:标签选择器*/
.container .search button {
/* 设置left浮动 */
float: left;
width: 150px;
height: 52px;
/* 设置button的背景颜色,#4e6ef2 */
background-color: #4e6ef2;
/* 设置button中的字体颜色 */
color: #FFF;
/* 设置字体的大小 */
font-size: 19px;
font-family: Georgia, 'Times New Roman', Times, serif;
}
.container .result {
width: 100%;
}
.container .result .item {
margin-top: 15px;
}
.container .result .item a {
/* 设置为块级元素,单独站一行 */
display: block;
/* a标签的下划线去掉 */
text-decoration: none;
/* 设置a标签中的文字的字体大小 */
font-size: 20px;
/* 设置字体的颜色 */
color: #4e6ef2;
}
.container .result .item a:hover {
/*设置鼠标放在a之上的动态效果*/
text-decoration: underline;
}
.container .result .item p {
margin-top: 5px;
font-size: 16px;
font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida SansUnicode', Geneva, Verdana, sans-serif;
}
.container .result .item i {
/* 设置为块级元素,单独站一行 */
display: block;
/* 取消斜体风格 */
font-style: normal;
color: green;
}
</style>
</head>
<body>
<div class="container">
<div class="search">
<input type="text" value="输入搜索关键字...">
<button>搜索一下</button>
</div>
<div class="result">
<div class="item">
<a href="#">标题</a>
<p>xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx摘要</p>
<i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i>
</div>
<div class="item">
<a href="#">标题</a>
<p>xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx摘要</p>
<i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i>
</div>
</div>
</div>
</body>
</html>🐟编写 js
如果直接使⽤原⽣的js成本会⽐较⾼(xmlhttprequest),我们使⽤JQuery.
JQuery CDN
html
<body>
<div class="container">
<div class="search">
<input type="text" value="请输入搜索关键字,例如:filesystem...">
<button onclick="Search()">搜索一下</button>
</div>
<div class="result">
<!-- 动态生成网页内容 -->
<!-- <div class="item">
<a href="#">这是标题</a>
<p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p>
<i>https://search.gitee.com/?skin=rec&type=repository&q=cpp-httplib</i>
</div>-->
</div>
</div>
<script>
function Search(){
// 是浏览器的一个弹出框
// alert("hello js!");
// 1. 提取数据, $可以理解成就是JQuery的别称
let query = $(".container .search input").val();
console.log("query = " + query); //console是浏览器的对话框,可以用来进行查看js数据
//2. 发起http请求,ajax: 属于JQuery中的一个和后端进行数据交互的函数
$.ajax({
type: "GET",
url: "/s?word=" + query,
success: function(data){
console.log(data);
BuildHtml(data);
}
});
}
function BuildHtml(data){
// 获取html中的result标签
let result_lable = $(".container .result");
// 清空历史搜索结果
result_lable.empty();
for( let elem of data){
// console.log(elem.title);
// console.log(elem.url);
let a_lable = $("<a>", {
text: elem.title,
href: elem.url,
// 跳转到新的页面
target: "_blank"
});
let p_lable = $("<p>", {
text: elem.desc
});
let i_lable = $("<i>", {
text: elem.url
});
let div_lable = $("<div>", {
class: "item"
});
a_lable.appendTo(div_lable);
p_lable.appendTo(div_lable);
i_lable.appendTo(div_lable);
div_lable.appendTo(result_lable);
}
}
</script>
</body>
</html>🐕添加⽇志
简单版本的日志:
cpp
#pragma once
#include <iostream>
#include <string>
#include <ctime>
#define NORMAL 1
#define WARNING 2
#define DEBUG 3
#define FATAL 4
#define LOG(LEVEL, MESSAGE) log(#LEVEL, MESSAGE, __FILE__, __LINE__)
void log(std::string level, std::string message, std::string file, int line)
{
std::cout << "[" << level << "]"
<< "[" << time(nullptr) << "]"
<< "[" << message << "]"
<< "[" << file << " : " << line << "]" << std::endl;
}这是之前实现过的日志:日志的实现
cpp
#pragma once
#include <iostream>
#include <string>
#include <ctime>
#include <cstdarg>
#include <unistd.h>
#include <fstream>
using namespace std;
#define FILENAME "LOG.txt" // 保存LOG的文件名
bool IsSave = false; // 标记是否需要保存到文件
// LOG(DEBUG, " Content is :%s %d %f ", "helloworld", 10, 3.14);
#define LOG(level, format, ...) \
do \
{ \
log(level, __FILE__, __LINE__, format, ##__VA_ARGS__); \
} while (0)
// 两各接口,修改IsSave的值,便于外部修改
#define EnIsSave() \
do \
{ \
IsSave = true; \
} while (0)
#define EnIsPrint() \
do \
{ \
IsSave = false; \
} while (0)
// 日志等级枚举
enum Level
{
DEBUG = 0,
INFO,
WARNING,
ERROR,
FATAL
};
// 将日志等级转为字符串
string LevelToString(int level)
{
switch (level)
{
case DEBUG:
return "DEBUG";
case INFO:
return "INFO";
case WARNING:
return "WARNING";
case ERROR:
return "ERROR";
case FATAL:
return "FATAL";
default:
return "UNKNOW";
}
}
// 将时间转为字符串
string timeToString(struct tm *stm)
{
char timebuffer[64];
snprintf(timebuffer, sizeof(timebuffer), "%d-%d-%d %d:%d:%d",
stm->tm_year + 1900, stm->tm_mon + 1, stm->tm_mday,
stm->tm_hour, stm->tm_min, stm->tm_sec);
return timebuffer;
}
// 如果是多线程打印日志,打印到显示器,显示器是公共资源(临界资源),需要保护
pthread_mutex_t Mutex = PTHREAD_ADAPTIVE_MUTEX_INITIALIZER_NP;
// 将日志存放到文件中,利用的C++的文件读写操作
void IsSaveFile(string &message)
{
ofstream out(FILENAME, ios::app);
if (!out)
{
return;
}
out << message << endl;
out.close();
}
// 日志的等级 时间 文件 行号 日志内容
void log(int level, string filename, int line, const char *format, ...)
{
// 等级
string levelstr = LevelToString(level);
// 时间
time_t curtime = time(nullptr);
struct tm stm;
localtime_r(&curtime, &stm);
string timestr = timeToString(&stm);
// 日志内容,多参数
va_list args;
va_start(args, format);
char ContentStr[1024];
vsnprintf(ContentStr, sizeof(ContentStr), format, args);
va_end(args);
// 将日志放到一个string里面
string message = "[ " + levelstr + " ] [ " + timestr + " ] [ " + filename + " ] [ " + to_string(line) + " ] [ " + ContentStr + " ]" + "\0";
// 保护临界资源
// 加锁
pthread_mutex_lock(&Mutex);
if (!IsSave)
{
cout << "[ "
<< levelstr << " ] [ "
<< timestr << " ] [ "
<< filename << " ] [ "
<< line << " ] [ "
<< ContentStr << " ]"
<< endl;
}
else
{
IsSaveFile(message);
}
// 释放锁
pthread_mutex_unlock(&Mutex);
}🐱部署服务
bash
$ nohup ./http_server > log/log.txt 2>&1 &
[1] 26890🐬后台部署服务
使用nohup
- nohup 命令是 Unix 和类 Unix 系统中非常有用的工具,它允许您在注销或关闭终端后继续运行进程。通过结合使用 & 和重定向操作符,您可以轻松地将进程放入后台运行,并将输出保存到指定的文件中。
(1) nohup指令
- nohup指令:将服务进程以守护进程的方式执行,使关闭XShell之后仍可以访问该服务
bash
nohup ./http_server
#这将在当前目录下启动 http_server 进程,并且即使您关闭了终端,它也会继续运行。
#但是,请注意,此命令会占用当前终端,输出将显示在终端上。- 让服务器后台运行:
bash
nohup ./http_server &
# 通过在命令末尾添加 &,您可以将进程放入后台运行,
#这样您就可以继续使用同一个终端进行其他操作。注意事项
- 当使用 nohup 和 & 时,进程将在后台运行,但仍然可以在终端中看到其输出。为了将输出重定向到文件而不是终端,可以使用重定向操作符 >。
(2)nohup 形成的文件
-
当使用 nohup 命令运行进程时,默认情况下,所有标准输出(stdout)和标准错误(stderr)都会被重定向到一个名为 nohup.out 的文件中(除非您指定了其他文件)。这个文件通常位于运行 nohup 命令的同一目录下。
-
查看日志文件
要查看 nohup.out 文件的内容,您可以使用 cat、less、more 或任何其他文本查看器。例如
bash
cat nohup.out- 重定向输出到指定文件
如果不希望使用默认的 nohup.out 文件,可以将输出重定向到指定的文件。例如:
bash
nohup ./http_server > my_log_file.log 2>&1 &
#> my_log_file.log 将标准输出重定向到 my_log_file.log 文件,2>&1 将标准错误也重定向到同一个文件。🐅附件
- 项目源码链接:BoostSiteSeeker