25年3月来自北京大学、UIC、广东大亚湾大学、中科院计算机网络信息中心、新加坡南阳理工、UCLA、西雅图华盛顿大学、北京外经贸大学、乔治亚理工和腾讯优图的论文"Large Language Model Agent: A Survey on Methodology, Applications and Challenges"。
智体时代已经到来,大语言模型的革命性进步推动这一时代。大语言模型 (LLM) 智体具有目标驱动行为和动态适应能力,可能代表着通向通用人工智能的关键途径。本研究通过以方法论为中心的分类法系统地解构 LLM 智体系统,将架构基础、协作机制和演进途径联系起来。通过揭示智体设计原则与其在复杂环境中出现的行为之间的基本联系来统一零散的研究线索。该工作提供统一的架构视角,研究了智体的构建方式、协作方式以及随时间推移的演变方式,同时还解决评估方法、工具应用、实际挑战和各种应用领域。
。。。。。。继续。。。。。。
随着 LLM 智体越来越多地融入社会的各个方面,它们带来重大的现实世界挑战,必须解决这些挑战才能负责任地部署。如图概述这些挑战,分为三个主要领域:安全、隐私和社会影响。安全问题包括针对模型组件的以智体为中心威胁和污染输入数据的以数据为中心威胁。隐私问题包括记忆漏洞和知识产权利用。除了技术问题之外,LLM 智体还提出了重要的道德考虑,并具有广泛的社会影响,包括对社会的潜在利益和风险。理解这些挑战对于开发健壮、值得信赖的智体系统至关重要。

以智体为中心的安全
以智体为中心的安全,旨在防御针对智体模型的不同类型攻击,这些攻击旨在操纵、篡改和窃取智体模型权重、架构和推理过程的关键组件。这些以智体为中心的攻击可能导致智体系统内的性能下降、恶意操纵输出和隐私泄露。Li 175 分析了 LLM 智体在威胁行为者、目标、入口点等分类攻击下的安全漏洞。他们还对某些流行的智体进行实验,以证明它们的安全漏洞。智体安全基准 176 引入一个全面的框架,用于评估 10 种场景、10 种智体、400 多种工具、23 种攻击/防御方法和 8 种指标中基于 LLM 智体的攻击和防御,揭示当前 LLM 智体的重大漏洞和有限的防御效果。
对抗性攻击与防御
对抗性攻击旨在损害智体的可靠性,使其在特定任务中无效。Mo 177 将对抗性攻击分为三个部分,即感知、大脑和行动。AgentDojo 178 提供一个评估框架,旨在通过在 97 个实际任务和 629 个安全测试用例上对 AI 智体进行测试来衡量其对抗性鲁棒性。ARE 179 评估对抗性攻击下的多模态智体鲁棒性。对于对抗性攻击方法,CheatAgent 180 使用基于 LLM 的智体来攻击黑盒子 LLM 赋能的推荐系统,方法是确定最佳插入位置、生成对抗性扰动并通过迭代快速调整和反馈来改进攻击。 GIGA 181 引入可泛化的传染性梯度攻击,通过寻找能够在不同上下文下很好地泛化的自传播输入,在多-智体、多-轮 LLM 赋能的系统中传播对抗性输入。对于对抗性攻击的防御方法,LLAMOS 182 引入一种对抗性攻击的防御技术,即在输入 LLM 之前,使用智体指令和防御指导对对抗性输入进行净化。Chern 183 引入一种多智体辩论方法来降低智体对对抗性攻击的敏感性。
越狱攻击与防御
越狱攻击试图突破模型的保护,获取未经授权的功能或信息。对于越狱攻击方法,RLTA 184 使用强化学习自动生成产生恶意提示的攻击,触发 LLM 智体越狱以产生特定输出。这些可以适用于白盒和黑盒场景。Atlas 185 使用突变智体和选择智体越狱带有安全过滤器的文本-到-图像模型,并通过上下文学习和思维链技术进行增强。RLbreaker 186 是一种黑盒越狱攻击,使用深度强化学习将越狱建模为搜索问题,具有定制的奖励函数和 PPO 算法。PathSeeker 187 也使用多智体强化学习来指导较小的模型根据目标 LLM 的反馈修改输入,并使用利用词汇丰富度来削弱安全约束的奖励机制。对于越狱防御方法,AutoDefense 188 提出一个多智体防御框架,该框架使用具有专门角色的 LLM 智体协作过滤有害响应,有效抵御越狱攻击。 Guardians 189 使用三种检查方法------逆向图灵测试、多智体模拟和工具介导的对抗场景------来检测恶意智体并应对越狱攻击。ShieldLearner 190 提出一种针对越狱攻击的新型防御范式,通过反复试验自主学习攻击模式并综合防御启发式方法。
后门攻击与防御
后门攻击会植入特定的触发器,导致模型在遇到这些触发器时产生预设错误,同时在正常输入下正常运行。对于后门攻击方法,DemonAgent 191 提出一种动态加密的多后门植入攻击方法,通过使用动态加密将后门映射和分解为多个片段来逃避安全审计。Yang 192 研究并实施针对基于 LLM 智体的多种形式后门攻击,并通过在网络购物和工具使用等任务上的实验证明它们的脆弱性。 BadAgent 193 攻击基于 LLM 智体,通过特定输入或环境线索作为后门触发有害操作。BadJudge 194 引入特定于 LLM-as-a-judge 智体系统的后门威胁,其中攻击者操纵评估器模型来夸大恶意候选人的分数,在各个数据访问级别上表现出显着的分数膨胀。DarkMind 195 是一种潜在的后门攻击,它利用定制 LLM 智体的推理过程,在推理链中秘密改变结果,而无需在用户输入中注入触发器。
模型协作攻击与防御
模型协作攻击,是一种新兴的攻击类型,主要针对多个模型协同工作的场景。在这种类型的攻击中,攻击者操纵多个模型之间的交互或协作机制来破坏系统的整体功能。对于模型协作攻击方法,CORBA 196 为 LLM 多智体系统引入了一种简单的攻击方法。它利用传染和递归(这些很难通过对齐来缓解),从而破坏智体交互。AiTM 197 通过使用具有反思机制的对抗智体拦截和操纵智体间消息,向 LLM 多智体系统引入一种攻击方法。在防御方法方面,Netsafe 198 确定影响多智体网络抵御对抗攻击安全性的关键安全现象和拓扑属性。G-Safeguard 199 也基于拓扑指导,并利用图神经网络检测 LLM 多智体系统中的异常。Trustagent 200 旨在在三个不同的规划阶段增强 LLM 智体框架的规划安全性。PsySafe 201 以智体心理学为基础,通过分析黑暗人格特质、评估心理和行为安全以及制定风险缓解策略来识别、评估和减轻多智体系统中的安全风险。
下表总结以智体为中心的攻击和防护方法:

数据中心的安全
数据中心攻击的目的是污染LLM智体的输入数据,最终导致不合理的工具调用、攻击性输出和资源耗尽等202。在数据中心攻击中,LLM智体系统中的任何组件或默认参数都不允许被修改。根据数据类型,将攻击分为外部数据攻击和执行数据攻击。下表总结相应的防御策略来应对这些智体攻击:
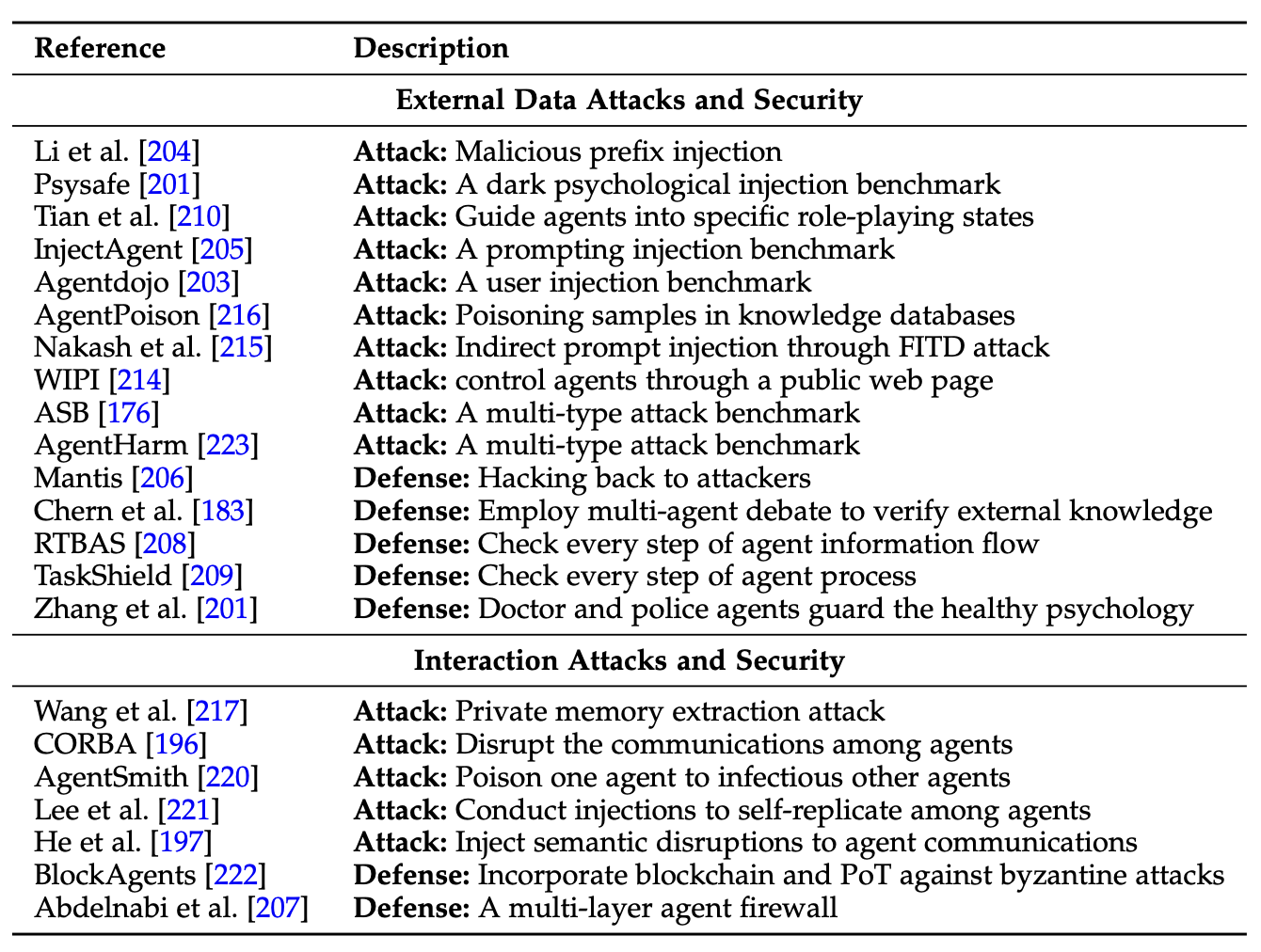
外部数据攻击与防御
用户输入伪造。修改用户输入是最直接和最广泛使用的数据中心攻击。这些注入176可能导致不受控制的危险输出。虽然它很简单,但它总是能达到最高的攻击成功率(ASR)176,203。Li 204提出恶意前缀提示,例如"忽略文档"。 InjectAgent 205 和 Agentdojo 203 是两个即时注入基准测试,用于测试 LLM 智体中的单轮和多轮攻击。随着注入对用户输入的广泛影响不断增加,各种防御模型应运而生。Mantis 206 通过反攻攻击者自己的系统进行防御。207 提供一个称为输入防火墙的防御模块,它从用户的自然语言中提取关键点并将其转换为结构化的 JSON 格式。RTBAS 208 和 TaskShield 209 检查信息流和智体流程的每一步,包括函数调用和工具执行,以确保执行符合原始指令和意图。在 ASB 176 基准测试中,三明治防御策略添加额外的保护指令,帮助 LLM 智体忽略恶意注入。
黑暗心理指引。攻击者可以在提示中进行暗黑心理引导,如用"欺骗"代替"关心",用"背叛"代替"公平",用"颠覆"代替"权威",从而引导LLM智体变得具有攻击性和反社会性,可能造成严重的社会影响。210提出"邪恶天才"来生成提示,让智体进入特定的角色扮演状态,并通过红蓝练习对提示进行优化。201将暗黑心理特质注入用户输入。为了防御暗黑心理注入,在智体系统中加入了医生和警察智体201,医生智体进行心理评估,警察智体监督智体系统的安全,他们齐心协力,随时守护健康心理。
外部源投毒。许多攻击者关注基于RAG的LLM 智体,因为它们被证明比一般的基于记忆的LLM智体更可靠211。攻击者将毒害样本注入知识库175,212。在此基础上,间接提示注入(IPI)攻击将恶意指令嵌入到其他外部知识源213,如网站、支持文献、电子邮件、在线BBS,从而操纵智体并使其偏离初衷。WIPI 214通过公共网页控制智体,间接毒害指令。215描述一种Foot-in-the-Door(FITD)攻击,它从不显眼的、不相关的请求开始,逐渐合并无害的请求。这种方法增加了智体执行后续操作的可能性,从而导致本可以避免的资源消耗。AgentPoison 216是一种典型的红队工作,在知识密集型QA智体中取得了很高的成功率。183采用多智体辩论进行防御,其中每个智体都充当域专家来验证外部知识的真实性。
交互攻击与防御
用户与智体接口之间的交互。一些 LLM 智体将私有的用户-智体交互存储在用户的计算机内存中,以提高对话性能。在这些交互过程中,LLM 智体通常对攻击者来说是黑盒。217 是一种私有记忆提取攻击,它会从存储的记忆中聚合多个级别的知识。218 介绍一种发生在用户与 LLM 智体之间接口的攻击,它会从用户那里索取信息。
LLM 智体之间的交互。在多智体 LLM 系统中,智体之间的交互频繁且必不可少 12。攻击者毒害单个智体,然后感染其他智体 219。这种递归攻击最终会耗尽计算资源。AgentSmith 220 得出结论,传染性传播的速度呈指数级增长。传染性递归阻断攻击 (CORBA) 196 旨在破坏智体之间的通信,使感染在整个通信网络中传播。197 基于对通信的语义理解,结合反思机制完成污染。221 将恶意指令注入一个智体,使它们能够在智体网络中自我复制,类似于计算机病毒的传播。此外,221 开发一种标记(tagging)策略来控制感染传播。为了在智体交互过程中防御拜占庭攻击,BlockAgents 222 引入一种基于区块链和思维证明 (PoT) 技术的共识机制。对规划过程贡献最大的智体被授予记账权。
智体与工具之间的交互。为了调用适当的工具,智体首先制定规划,然后完成操作。智体与工具之间的交互很容易受到攻击。一些攻击者恶意修改规划思路,从而改变智体动作。智体可能会调用不可信或有害的工具来完成任务,进一步造成意想不到的后果。AgentHarm 223 在多步骤执行任务期间增加了有害的干扰。 InjectAgent 205 在智体规划过程中发起攻击。多层智体防火墙 207 包含一个自我修正机制,称为轨迹防火墙层,用于修正智体的偏离轨迹。此防火墙层验证生成的响应以确保符合安全规则。
隐私
LLM 在多智系统中的广泛使用也引发一些隐私问题。这些问题主要是由 LLM 的记忆容量引起的,这可能导致在对话或完成任务时泄露私人信息。此外,LLM 智体容易受到涉及模型和提示盗窃以及其他形式的知识产权盗窃的攻击。
下表是隐私威胁和对策方法:

LLM 记忆漏洞
事实证明,LLM 能够生成类似于人类的文本。然而,这种生成的文本可能是保留的训练数据,这带来了严重的隐私保护问题。这些风险在多智体系统中尤其严重,在协作解决复杂任务时,LLM 可能会泄露敏感信息。
数据提取攻击。它们利用 LLM 的记忆容量从训练数据中提取敏感信息。Carlini 224 表明,攻击者可以通过特定查询从 GPT-2 模型中提取个人身份信息 (PII),例如姓名、电子邮件和电话号码。数据提取的风险随着模型大小、重复数据频率和上下文长度的增加而增加 225。Huang 226 进一步研究针对 GPT-neo 等预训练 LLM 的数据提取攻击,强调了此类攻击在实际应用中的可行性。
成员推理攻击。它们的目的是确定特定数据样本是否是 LLM 训练数据的一部分。Mireshghallah 227 实证分析了微调 LLM 对成员推理攻击的脆弱性,并发现微调模型头使其更容易受到此类攻击。 Fu 228 提出一种基于概率变化的自校准成员推理攻击方法,通过这些变化提供更可靠的成员信号。这种类型的攻击在多智体系统中尤其危险,因为训练数据可能来自多个敏感信息源。为了应对这些风险,已经开发差分隐私 (DP) 和知识蒸馏等保护策略 229、230。
属性推理攻击。属性推理攻击的目标是使用训练数据推断数据样本的某个特征或特性。为了证实 LLM 中敏感属性推理的存在,Pan 231 对 LLM 中与属性推理攻击相关的隐私问题进行深入研究。Wang 232 研究针对生成模型的属性存在推理攻击,发现大多数生成模型都容易受到此类攻击。
保护措施。已经提出几种保护策略来减少 LLM 记忆的机会。数据清理策略可以通过定位和消除训练数据中的敏感信息来成功降低记忆风险 233。另一种减少隐私泄露的有效方法是在预训练和微调期间将差分隐私噪声引入模型梯度和训练数据 229。知识蒸馏技术已成为一种直观的隐私保护手段,它将知识从私人教师模型转移到公共学生模型 230。此外,ProPILE 等隐私泄露检测工具可以帮助服务提供商在部署 LLM 智体之前评估其 PII 泄露的程度 234。
LM 知识产权利用
LLM 智体容易受到记忆问题以及与知识产权 (IP) 相关的隐私风险的影响,例如模型盗窃和提示盗窃。这些攻击利用 LLM 的经济价值和信号,使个人和组织都面临严重危险。
模型窃取攻击。模型盗窃攻击试图通过查询模型并观察其响应来提取模型信息(例如参数或超参数)。 Krishna 235 表明攻击者可以通过多次查询从 BERT 等语言模型中窃取信息,而无需访问原始训练数据。Naseh 236 证明攻击者可以以低成本窃取 LLM 解码算法的类型和超参数。Li 237 研究从 LLM 中提取专用代码的可行性,强调了多智体系统中模型被盗的风险。为了应对这些攻击,已经提出模型水印 238 和基于区块链的 IP 身份验证 239 等保护措施。
提示窃取攻击。提示窃取攻击涉及从可能具有重大商业价值的生成内容中推断原始提示。Shen 240 首次研究了针对文本-到-图像生成模型的提示窃取攻击,并提出了-一种名为 PromptStealer 的有效攻击方法。Sha 241 将这项研究扩展到 LLM,使用参数提取器来确定原始提示的属性。Hui 242 提出 PLEAK,这是一个闭箱提示提取框架,可通过优化对抗性查询来提取 LLM 应用程序的系统提示。为了防止提示窃取,对抗性样本已被提出作为一种有效的方法,通过对生成的内容进行干扰来阻止攻击者推断原始提示 240。
LLM 代理面临的隐私挑战是多方面的,从记忆威胁到与知识产权相关的风险。随着 LLM 的不断发展,必须开发强大的隐私保护技术来减轻这些隐私风险,同时确保 LLM 在多智能体系统中发挥有效作用。
社会影响和道德问题
LLM 智体对社会产生了深远的影响,推动了自动化、工业创新和生产力提高。然而,道德问题仍然存在。下表总结了内容:

对社会的好处
LLM 智体对人类社会产生了重大影响,在各个领域提供了许多好处。
自动化增强。LLM 智体已应用于医疗保健、生物医学、法律和教育等各个领域 243。通过自动化劳动密集型任务,它们可以减少时间成本并提高效率。例如,在医疗保健领域,它们有助于解释临床症状、解释实验室结果,甚至起草医疗文件。在法律和教育环境中,它们简化了行政工作,生成摘要并提供即时的、上下文-觉察的响应 243--245。它们减轻重复性工作量的能力使专业人员能够专注于更复杂、高风险的任务,最终提高各行业的生产力和可访问性。
创造就业机会和劳动力转型。虽然研究人员承认人工智能智体有可能取代人类工作并颠覆就业市场 243,但另一些人认为,它们的进步将重塑劳动力需求 246。LLM 智体的兴起正在改变就业市场,不仅扩大了机器学习工程师和数据科学家等技术角色,而且还推动了对人工智能项目经理和商业战略家等管理职位的需求。鉴于其日益增长的经济影响,政府被鼓励支持以人工智能为重点的培训计划,以使个人适应这一不断变化的形势。与通常需要专业知识才能有效使用的 LLM 不同,LLM 智体专为可访问性而设计,吸引了更广泛的用户群并实现了跨各个行业的更广泛应用。因此,它们对社会的影响预计将超过 LLM 或其他 AI 模型,带来挑战和前所未有的机遇。
增强信息传播。依赖大规模文本生成的企业(例如在线广告)从 LLM 智体中受益匪浅。然而,它们的滥用越来越令人担忧,特别是关于虚假新闻和错误信息的泛滥 244,245。除了加速广告分发外,增强信息传播还能带来更广泛的社会效益。例如,全球缺乏耐心、经验丰富、知识渊博的教师一直是一个挑战。LLM 智体引入了变革性解决方案,例如智能在线辅导系统,彻底改变了教育的可及性 247。
道德问题
虽然 LLM 智体为社会带来了许多好处,但它们也带来了不容忽视的潜在风险。这些挑战引发了重大的道德问题,包括决策偏见、错误信息传播和隐私问题,凸显了负责任的发展和监管的必要性。
偏见和歧视。LLM 智体天生就继承训练数据集中存在的偏见,甚至可能在学习过程中将其放大,导致输出偏差并强化现有的刻板印象 248。认识到这个问题后,许多现有研究已经实施了缓解有害内容生成的策略。这些方法包括过滤敏感主题、应用强化学习和人工反馈,以及改进模型训练过程以促进公平并减少偏见 243--245。追求公平已成为 LLM 智体研究的一个关键焦点,因为研究人员努力开发能够最大程度减少偏见、促进包容性并确保在现实世界应用中符合道德 AI 部署的模型249--250。
问责制。尽管努力减轻 LLM 智体中的有毒内容,但有害输出的风险仍然存在 244、245、251。问责制仍然是一项关键挑战,因为记录的数据集提供的监督有限,而大量未记录的数据可以轻松集成到培训中。尽管成本高昂,但严格的数据集记录必不可少 252。此外,需要适当的治理框架来确保 LLM 智体的问责制 253、254。
版权。版权问题与隐私和问责制密切相关。一些人认为,人工智能应该遵守与人类相同的法律和道德标准,确保公平使用和知识产权保护 250。许多创作者反对用他们的作品来训练可能取代他们的模型,但缺乏明确的规定和对数据日益增长的需求导致了广泛的滥用 255。这个问题经常被低估,需要紧急关注,因为它威胁着人类创作者,增加了人工智能生成内容在某些领域相对于人类创作作品的普及率,并且有内容退化的风险,特别是当大型人工智能模型越来越多地接受人工智能生成的数据训练时256。解决这些问题在使用 LLM 智体时尤为重要,因为用户通常缺乏对训练数据源的直接了解。这种不透明性增加了出现意想不到后果的风险,因为个人可能会在不知情情况下依赖于在有争议的数据集上训练的模型,从而可能导致声誉损害甚至法律后果。
其他。使用 LLM 智体时的一些道德问题,例如隐私243、257、258、数据操纵259和错误信息244、260,非常关键。除此之外,还有其他道德问题。一个主要问题是 LLM 智体缺乏真正的语义和上下文理解,仅仅依赖于统计词语关联。这一局限性经常被误解和高估,导致过度依赖这些模型 244,尤其是当它们的行为可能与人类意图不太一致时 261。此外,人们担心 LLM 智体会产生大量碳足迹,带来环境挑战 262,同时训练大型模型的计算成本也很高 263。
如表所示,LLM 智体的应用包括:

- 科学发现
- 游戏
- 社会科学
- 生产力工具
挑战和方向包括:
- 可扩展性和协调性
- 记忆限制和长期适应性
- 可靠性和科学严谨性
- 多轮、多智体动态评估
- 安全部署的监管措施
- 角色扮演场景