PyTorch量化进阶教程:第二章 Transformer 理论详解
本教程通过深入讲解 Transformer 架构、自注意力机制及时间序列预测,结合 Tushare 数据源和 TA-Lib 技术指标,实现从数据处理到模型训练、回测与策略部署的完整量化交易系统。教程每个环节都通过专业示例和代码实现进行阐释,确保读者能够扎实掌握并灵活运用所学知识。
文中内容仅限技术学习与代码实践参考,市场存在不确定性,技术分析需谨慎验证,不构成任何投资建议。适合量化新手建立系统认知,为策略开发打下基础。

学习对象
- 中高级水平的开发者
- 具备 Python 编程基础和一定的机器学习知识
- 对 A 股市场有一定了解,熟悉 Tushare 数据源和 TA-Lib 技术指标
教程目标
- 系统学习 PyTorch 和 Transformer 技术
- 掌握 Transformer 在时间序列预测和量化交易中的应用
- 使用 Tushare 数据源和 TA-Lib 技术指标构建量化交易模型
- 实现从数据获取到模型训练、评估和部署的完整流程
教程目录
1.1 PyTorch 环境搭建与基本操作
1.2 张量(Tensor)与自动求导机制
1.3 神经网络模块(nn.Module)与优化器
1.4 数据加载与预处理(DataLoader 和 Dataset)
2.1 Transformer 架构概述
2.2 自注意力机制(Self-Attention)
2.3 编码器与解码器结构
2.4 Transformer 在时间序列预测中的应用
3.1 使用 Tushare 获取 A 股数据
3.2 数据存储与管理(Parquet 文件)
3.3 使用 TA-Lib 计算技术指标
3.4 特征工程与数据预处理
4.1 Transformer 模型的 PyTorch 实现
4.2 时间序列预测任务的模型设计
4.3 模型训练与超参数优化
4.4 模型评估与性能分析
5.1 量化交易策略设计与实现
5.2 回测与风险评估
5.3 策略优化与改进
5.4 模型保存与加载
5.5 ONNX 优化模型
6.1 部署整体架构设计
6.2 核心部署流程
6.3 关键技术实现
6.4 性能调优路线
6.5 监控指标设计
6.6 总结建议
第二章 Transformer 理论详解
2.1 Transformer 架构概述
2.1.1 Transformer 的基本结构
Transformer 是一种基于自注意力机制的深度学习模型,最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出。其核心思想是通过自注意力机制捕捉序列中元素之间的全局依赖关系,而不需要像 RNN 那样逐元素处理。
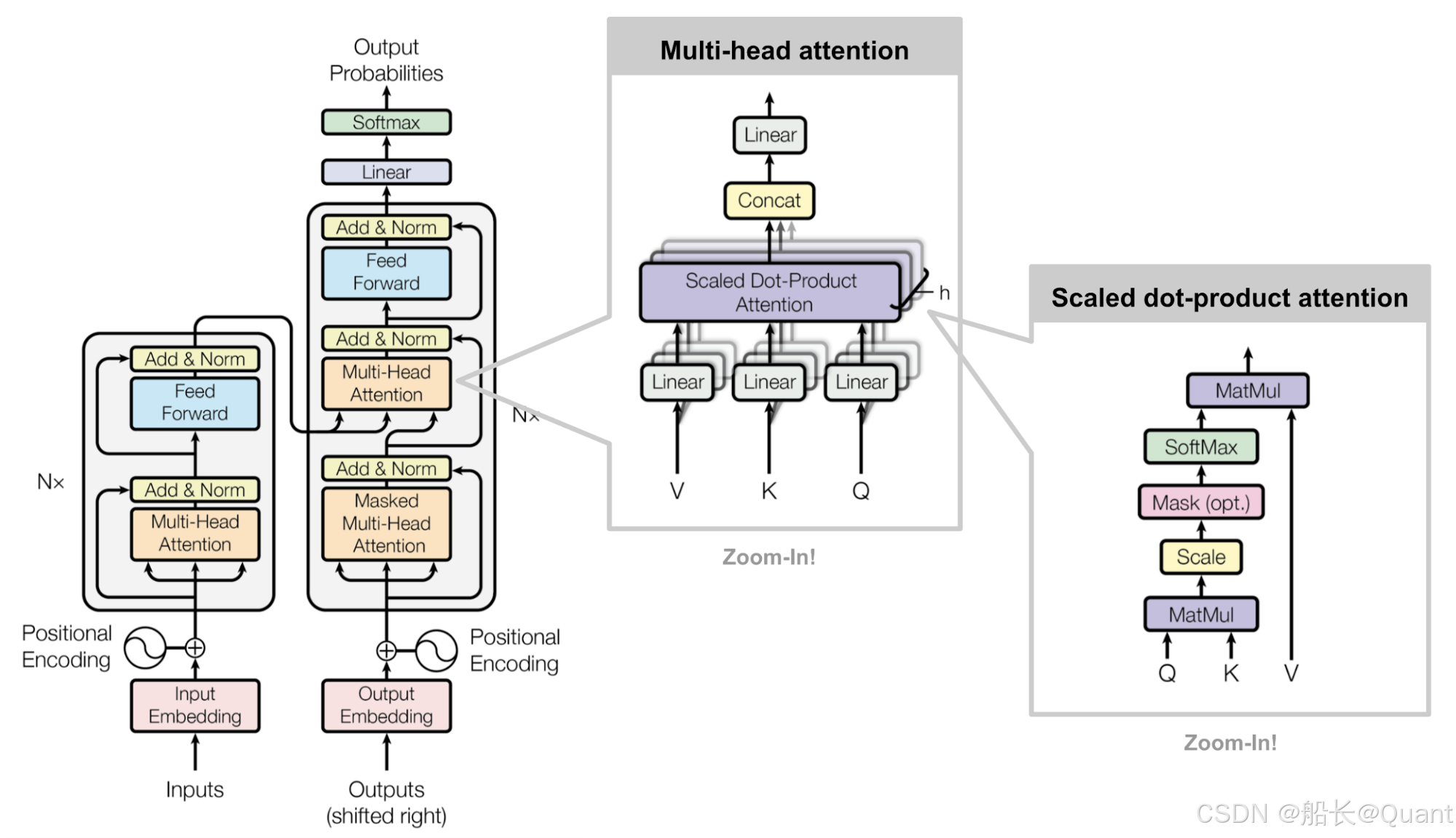
Transformer 的主要组成部分:
- 编码器(Encoder):处理输入序列,生成上下文表示。
- 解码器(Decoder):基于编码器的输出生成输出序列。
- 自注意力机制(Self-Attention):捕捉序列中元素之间的关系。
- 位置编码(Positional Encoding):引入位置信息。
2.1.2 编码器与解码器的作用
- 编码器:将输入序列转换为高维表示,捕捉上下文信息。
- 解码器:根据编码器的输出生成目标序列,通常用于序列生成任务(如机器翻译)。
2.2 自注意力机制
2.2.1 注意力机制的数学原理
自注意力机制通过计算查询(Query)、键(Key)和值(Value)之间的关系来捕捉元素间的依赖。
公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
- Q Q Q 是查询矩阵, K K K 是键矩阵, V V V 是值矩阵。
- d k d_k dk 是键的维度,用于缩放点积以避免梯度消失。
2.2.2 多头注意力(Multi-Head Attention)
多头注意力通过将输入投影到多个不同的子空间,分别计算注意力,然后将结果拼接起来。
公式:
MultiHead ( Q , K , V ) = Concat ( head 1 , ... , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
- head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i) headi=Attention(QWiQ,KWiK,VWiV)
- h h h 是头的数量, W i Q , W i K , W i V , W O W^Q_i, W^K_i, W^V_i, W^O WiQ,WiK,WiV,WO 是可学习的权重矩阵。
2.2.3 代码实现:自注意力机制
python
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
"""多头注意力机制。
:param d_model: 输入和输出的维度
:param num_heads: 注意力头的数量
"""
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads # 注意力头的数量
self.d_model = d_model # 输入和输出的维度
self.depth = d_model // num_heads # 每个头的维度
self.wq = nn.Linear(d_model, d_model) # 查询线性变换
self.wk = nn.Linear(d_model, d_model) # 键线性变换
self.wv = nn.Linear(d_model, d_model) # 值线性变换
self.dense = nn.Linear(d_model, d_model) # 输出线性变换
def split_heads(self, x, batch_size):
"""将输入张量分割成多个头。
:param x: 输入张量 (batch_size, seq_len, d_model)
:param batch_size: 批次大小
:return: 分割后的张量 (batch_size, num_heads, seq_len, depth)
"""
x = x.view(batch_size, -1, self.num_heads, self.depth) # 将d_model维度拆分成num_heads和depth
return x.permute(0, 2, 1, 3) # 调整维度顺序为 (batch_size, num_heads, seq_len, depth)
def forward(self, q, k, v):
"""前向传播函数。
:param q: 查询张量 (batch_size, seq_len, d_model)
:param k: 键张量 (batch_size, seq_len, d_model)
:param v: 值张量 (batch_size, seq_len, d_model)
:return: 输出张量 (batch_size, seq_len, d_model) 和注意力权重 (batch_size, num_heads, seq_len, seq_len)
"""
batch_size = q.size(0) # 获取批次大小
q = self.wq(q) # 对查询进行线性变换
k = self.wk(k) # 对键进行线性变换
v = self.wv(v) # 对值进行线性变换
q = self.split_heads(q, batch_size) # 将查询张量分割成多个头
k = self.split_heads(k, batch_size) # 将键张量分割成多个头
v = self.split_heads(v, batch_size) # 将值张量分割成多个头
# 计算注意力
scaled_attention, attention_weights = self.scaled_dot_product_attention(q, k, v)
scaled_attention = scaled_attention.permute(0, 2, 1, 3) # 调整维度顺序为 (batch_size, seq_len, num_heads, depth)
concat_attention = scaled_attention.reshape(batch_size, -1, self.d_model) # 合并头,恢复原始维度
output = self.dense(concat_attention) # 进行最终的线性变换
return output, attention_weights
def scaled_dot_product_attention(self, q, k, v):
"""计算缩放点积注意力。
:param q: 查询张量 (batch_size, num_heads, seq_len, depth)
:param k: 键张量 (batch_size, num_heads, seq_len, depth)
:param v: 值张量 (batch_size, num_heads, seq_len, depth)
:return: 注意力输出 (batch_size, num_heads, seq_len, depth) 和注意力权重 (batch_size, num_heads, seq_len, seq_len)
"""
matmul_qk = torch.matmul(q, k.transpose(-1, -2)) # 计算Q和K的点积
dk = torch.tensor(k.size(-1), dtype=torch.float32) # 获取深度dk
scaled_attention_logits = matmul_qk / torch.sqrt(dk) # 缩放点积
attention_weights = torch.softmax(scaled_attention_logits, dim=-1) # 计算注意力权重
output = torch.matmul(attention_weights, v) # 应用注意力权重到值上
return output, attention_weights2.3 编码器与解码器结构
2.3.1 编码器的实现
编码器由多头注意力层和前馈神经网络组成,每个子层都包含残差连接和层归一化。
代码实现:编码器
python
class EncoderLayer(nn.Module):
"""编码器层。
:param d_model: 输入和输出的维度
:param num_heads: 注意力头的数量
:param dff: 前馈神经网络的中间维度
:param dropout: dropout 概率,默认为 0.1
"""
def __init__(self, d_model, num_heads, dff, dropout=0.1):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads) # 多头注意力机制
self.ffn = nn.Sequential(
nn.Linear(d_model, dff), # 线性变换到dff维度
nn.GELU(), # GELU激活函数
nn.Linear(dff, d_model), # 线性变换回d_model维度
)
self.layer_norm1 = nn.LayerNorm(d_model) # 第一个层归一化
self.layer_norm2 = nn.LayerNorm(d_model) # 第二个层归一化
self.dropout = nn.Dropout(dropout) # Dropout层
def forward(self, x):
"""前向传播函数。
:param x: 输入张量 (batch_size, seq_len, d_model)
:return: 输出张量 (batch_size, seq_len, d_model)
"""
# 多头注意力
attn_output, _ = self.mha(x, x, x) # 计算多头注意力
attn_output = self.dropout(attn_output) # 应用dropout
out1 = self.layer_norm1(x + attn_output) # 残差连接和层归一化
# 前馈神经网络
ffn_output = self.ffn(out1) # 前馈神经网络
ffn_output = self.dropout(ffn_output) # 应用dropout
out2 = self.layer_norm2(out1 + ffn_output) # 残差连接和层归一化
return out22.3.2 解码器的实现
解码器包含两个多头注意力层:第一个用于掩码自注意力,第二个用于编码器-解码器注意力。
代码实现:解码器
python
class DecoderLayer(nn.Module):
"""解码器层。
:param d_model: 输入和输出的维度
:param num_heads: 注意力头的数量
:param dff: 前馈神经网络的中间维度
:param dropout: dropout 概率,默认为 0.1
"""
def __init__(self, d_model, num_heads, dff, dropout=0.1):
super().__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads) # 掩码多头注意力
self.mha2 = MultiHeadAttention(d_model, num_heads) # 编码器-解码器注意力
self.ffn = nn.Sequential(
nn.Linear(d_model, dff), # 线性变换到dff维度
nn.GELU(), # GELU激活函数
nn.Linear(dff, d_model), # 线性变换回d_model维度
)
self.layer_norm1 = nn.LayerNorm(d_model) # 第一个层归一化
self.layer_norm2 = nn.LayerNorm(d_model) # 第二个层归一化
self.layer_norm3 = nn.LayerNorm(d_model) # 第三个层归一化
self.dropout = nn.Dropout(dropout) # Dropout层
def forward(self, x, enc_output):
"""前向传播函数。
:param x: 输入张量 (batch_size, seq_len, d_model)
:param enc_output: 编码器输出 (batch_size, src_seq_len, d_model)
:return: 输出张量 (batch_size, seq_len, d_model) 和两个注意力权重
"""
# 掩码多头注意力
attn1, attn_weights1 = self.mha1(x, x, x) # 计算掩码多头注意力
attn1 = self.dropout(attn1) # 应用dropout
out1 = self.layer_norm1(x + attn1) # 残差连接和层归一化
# 编码器-解码器注意力
attn2, attn_weights2 = self.mha2(
out1, enc_output, enc_output
) # 计算编码器-解码器注意力
attn2 = self.dropout(attn2) # 应用dropout
out2 = self.layer_norm2(out1 + attn2) # 残差连接和层归一化
# 前馈神经网络
ffn_output = self.ffn(out2) # 前馈神经网络
ffn_output = self.dropout(ffn_output) # 应用dropout
out3 = self.layer_norm3(out2 + ffn_output) # 残差连接和层归一化
return out3, attn_weights1, attn_weights22.4 Transformer 在时间序列预测中的应用
2.4.1 时间序列数据的处理
时间序列数据需要转换为适合 Transformer 输入的格式,通常将每个时间步的特征作为输入。
2.4.2 位置编码
位置编码用于引入序列中元素的位置信息。
代码实现:位置编码
python
class PositionalEncoding(nn.Module):
"""位置编码。
:param d_model: 输入和输出的维度
:param max_len: 最大序列长度,默认为5000
:param dropout: dropout 概率,默认为 0.1
"""
def __init__(self, d_model, max_len=5000, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout) # Dropout层
pe = torch.zeros(max_len, d_model) # 初始化位置编码
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 位置索引
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
) # 用于计算正弦和余弦的位置项
pe[:, 0::2] = torch.sin(position * div_term) # 正弦位置编码
pe[:, 1::2] = torch.cos(position * div_term) # 余弦位置编码
pe = pe.unsqueeze(0) # 增加批次维度
self.register_buffer("pe", pe) # 注册位置编码为缓冲区
def forward(self, x):
"""前向传播函数。
:param x: 输入张量 (batch_size, seq_len, d_model)
:return: 添加了位置编码的张量 (batch_size, seq_len, d_model)
"""
x = x + self.pe[:, : x.size(1)] # 添加位置编码
return self.dropout(x) # 应用dropoutclass TransformerModel(nn.Module):
"""Transformer模型。
:param input_size: 输入特征的维度
:param d_model: 输入和输出的维度
:param num_heads: 注意力头的数量
:param num_layers: 编码器层数
:param dff: 前馈神经网络的中间维度
:param dropout: dropout 概率,默认为 0.1
"""
def __init__(self, input_size, d_model, num_heads, num_layers, dff, dropout=0.1):
super().__init__()
self.embedding = nn.Linear(input_size, d_model) # 输入嵌入
self.pos_encoding = PositionalEncoding(d_model, dropout=dropout) # 位置编码
self.encoder_layers = nn.ModuleList(
[
EncoderLayer(d_model, num_heads, dff, dropout)
for _ in range(num_layers)
] # 编码器层
)
self.fc = nn.Linear(d_model, 1) # 全连接层
def forward(self, x):
"""前向传播函数。
:param x: 输入张量 (batch_size, seq_len, input_size)
:return: 输出张量 (batch_size, 1)
"""
x = self.embedding(x) # 输入嵌入
x = self.pos_encoding(x) # 位置编码
for enc_layer in self.encoder_layers:
x = enc_layer(x) # 通过每个编码器层
x = self.fc(x.mean(dim=1)) # 使用全局平均池化并进行最终线性变换
return x2.4.3 Transformer 模型的完整实现
python
class TransformerModel(nn.Module):
"""Transformer模型。
:param input_size: 输入特征的维度
:param d_model: 输入和输出的维度
:param num_heads: 注意力头的数量
:param num_layers: 编码器层数
:param dff: 前馈神经网络的中间维度
:param dropout: dropout 概率,默认为 0.1
"""
def __init__(self, input_size, d_model, num_heads, num_layers, dff, dropout=0.1):
super().__init__()
self.embedding = nn.Linear(input_size, d_model) # 输入嵌入
self.pos_encoding = PositionalEncoding(d_model, dropout=dropout) # 位置编码
self.encoder_layers = nn.ModuleList(
[
EncoderLayer(d_model, num_heads, dff, dropout)
for _ in range(num_layers)
] # 编码器层
)
self.fc = nn.Linear(d_model, 1) # 全连接层
def forward(self, x):
"""前向传播函数。
:param x: 输入张量 (batch_size, seq_len, input_size)
:return: 输出张量 (batch_size, 1)
"""
x = self.embedding(x) # 输入嵌入
x = self.pos_encoding(x) # 位置编码
for enc_layer in self.encoder_layers:
x = enc_layer(x) # 通过每个编码器层
x = self.fc(x.mean(dim=1)) # 使用全局平均池化并进行最终线性变换
return x总结
本章详细讲解了 Transformer 的理论基础和实现细节,包括自注意力机制、编码器与解码器的结构,以及在时间序列预测中的应用。通过代码示例,用户可以理解 Transformer 的核心机制,并为后续章节的实战应用打下基础。
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。