transformer架构与其它架构对比
一、Transformer架构详解
Transformer是一种完全基于注意力机制的深度学习架构,由编码器(Encoder)和解码器(Decoder)堆叠组成,适用于序列建模任务(如机器翻译、文本生成)。以下为核心组件和机制:
编码器结构
多头自注意力层:通过并行计算序列中所有位置的关联,捕捉全局依赖关系。每个"头"关注不同语义空间的特征。
前馈神经网络:对每个位置独立进行非线性变换(如ReLU激活)。
残差连接与层归一化:缓解梯度消失问题,加速训练。
解码器结构
掩码自注意力:在生成时屏蔽未来信息,确保自回归特性。
交叉注意力:连接编码器输出与解码器输入,实现上下文对齐。
关键技术
位置编码:使用正弦/余弦函数显式注入位置信息,公式为:
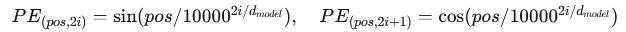
注意力计算:通过缩放点积注意力(Scaled Dot-Product Attention)计算权重:

二、与其他架构对比
1. RNN/LSTM
并行性:RNN需按序列顺序计算,无法并行;Transformer全序列矩阵运算高度并行。
长距离依赖:RNN因梯度消失难以捕捉长程关系,而Transformer通过自注意力直接建模任意位置关联。
位置感知:RNN隐式学习位置,Transformer显式编码位置信息。
2. CNN
特征提取:CNN擅长局部特征(如图像边缘),而Transformer通过全局注意力捕捉整体结构。
计算效率:CNN复杂度为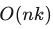
(k为卷积核大小),Transformer为
但可通过稀疏注意力优化。
3. GNN
图结构处理:GNN专门处理图数据(如社交网络),Transformer需调整结构(如Graph Transformer)才能适配。
三、技术拓展与应用
1. 模型变体
BERT:仅用编码器进行双向预训练,适合文本分类、问答。
ViT(Vision Transformer):将图像分割为块序列处理,在ImageNet分类任务中超越CNN。
GPT系列:基于解码器的自回归模型,擅长生成连贯文本。
2. 优化技术
稀疏注意力:限制每个位置关注的邻域范围,降低计算复杂度(如Longformer)。
混合架构:结合CNN局部特征提取与Transformer全局建模(如Swin Transformer)。
3. 多模态应用
CLIP:联合训练图像与文本编码器,实现跨模态检索。
AlphaFold 2:利用Transformer预测蛋白质3D结构。
四、未来研究方向
高效计算:开发线性注意力、内存压缩技术,解决长序列处理瓶颈。
动态结构:自适应调整注意力头数量或网络深度,提升资源利用率。
多任务统一:构建单一Transformer模型处理跨模态、跨领域任务。
总结
Transformer通过全局注意力机制突破了传统模型的序列处理限制,成为NLP、CV等领域的通用架构。其核心优势在于并行性、长程建模能力和灵活性,但计算资源消耗较大。未来发展方向将聚焦于效率提升、多模态融合和硬件适配。