Apache Flink 是一个开源的流处理框架,用于实时数据流的处理和分析。
本文将详细的介绍如何利用 Docker 在本地部署 Apache Flink 并结合路由侠实现外网访问本地部署的 Apache Flink 。
第一步,本地部署安装 Flink
1,打开 Linux 终端,确保 Docker 已经安装好了。拉取 Flink 镜像。
docker pull flink2,创建 Flink 项目文件夹并进入。
mkdir -p docker/flink && cd docker/flink3,用 vim docker-compose.yml 打开文件,把下面代码复制进去并保存,端口和其他信息可根据自己需要自行更改。
version: "2.1"
services:
jobmanager:
image: flink
expose:
- "6123"
ports:
- "8081:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: flink
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager4,启动执行。
docker-compose up -d
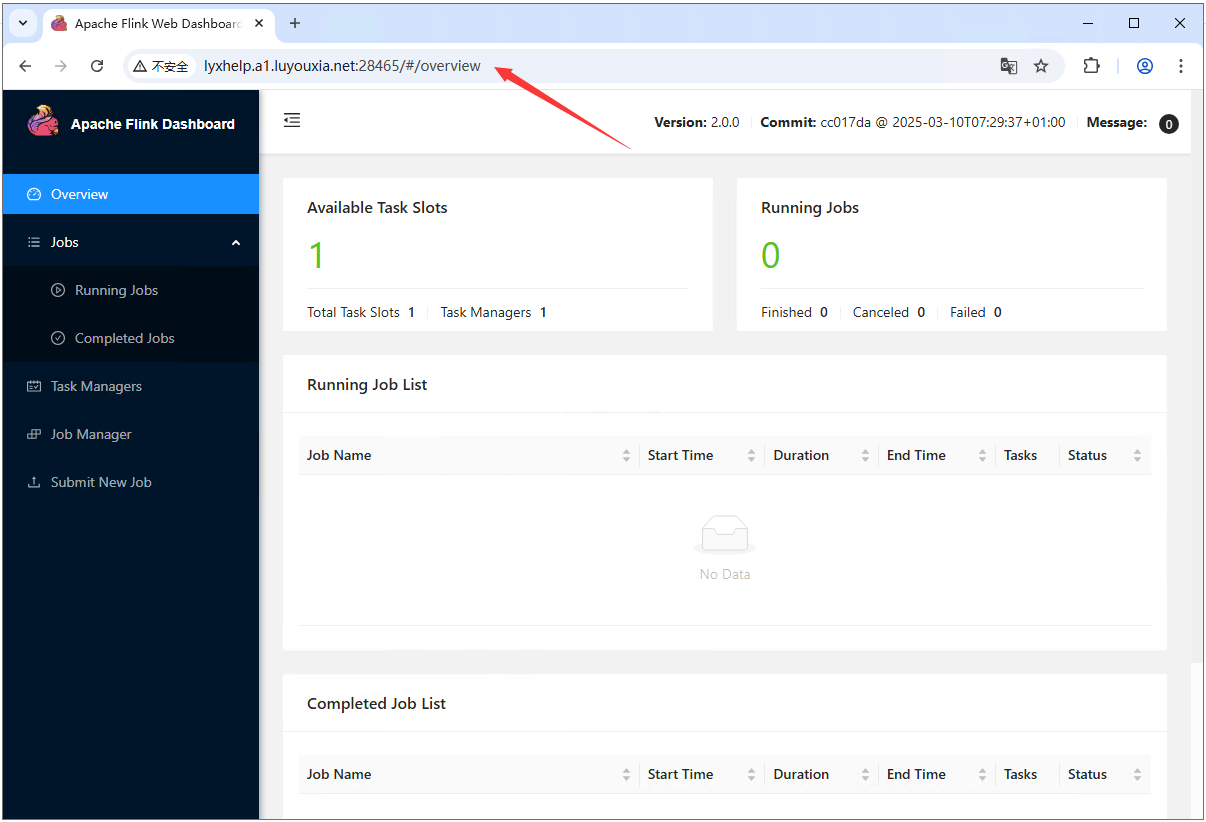
5,在浏览器输入 http://本地IP:8081 ,就可以看到 Flink 主界面了。
第二步,外网访问本地的 Flink
安装路由侠内网穿透。
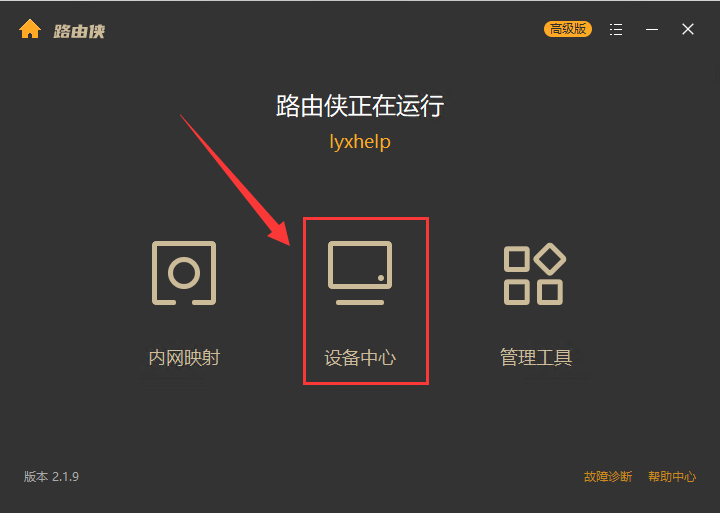
1,当前未提供网页管理,需要先在任意一台 Windows 机器安装路由侠 Windows 版本,用作跨机器管理。
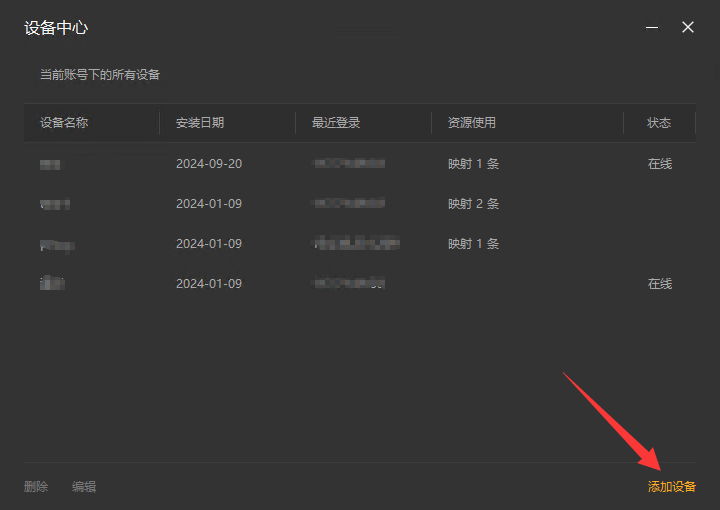
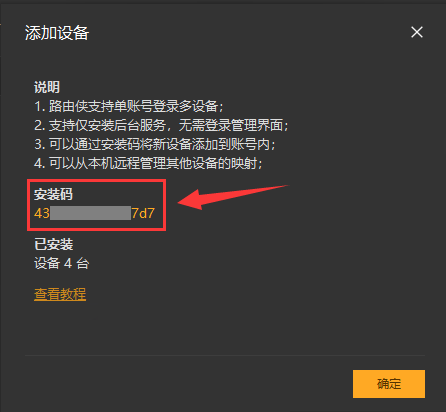
2,在路由侠客户端主界面,进入"设备管理",点击右下角的"添加设备",此时可查看到对应的安装码,此安装码用于将设备添加到对应账号下,可选中后复制。
3,直接下载后导入:
wget https://dl.luyouxia.com:8443/v2/lyx-docker-x86_64.tar
docker load -i lyx-docker-x86_64.tar4,然后使用该镜像启动容器
docker run --name lyx -it --restart=always --net=host -e code=这里填写安装码 luyouxia/lyx5,此时,需要等待下载和安装的过程,如果一切正常,最终可以看到一些输出,并且可以看到如下提示:
[Device] Logged in. Token: ....这就表示安装成功了。
当前 Linux 终端这边,如果是使用的上面的命令,Docker 是运行在前台,此时可以按住 Ctrl+C ,退出路由侠,容器也将退出。现在可以使用以下命令将其放入后台持续运行:
docker start lyx注意如果容器删除,重新 docker run, 将创建为新的设备。
需要注意的是,因为容器参数已经添加了 --restart=always,这样开机就会自动启动,不需要再手动启动路由侠了。
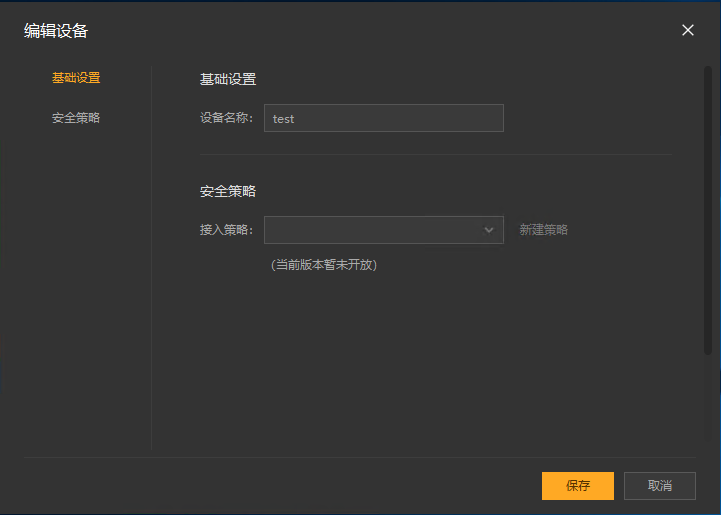
6,现在回到 Windows 这边设备列表,点击右上角的×返回主界面,再次进入,就可以找到这个设备,可以修改名称。
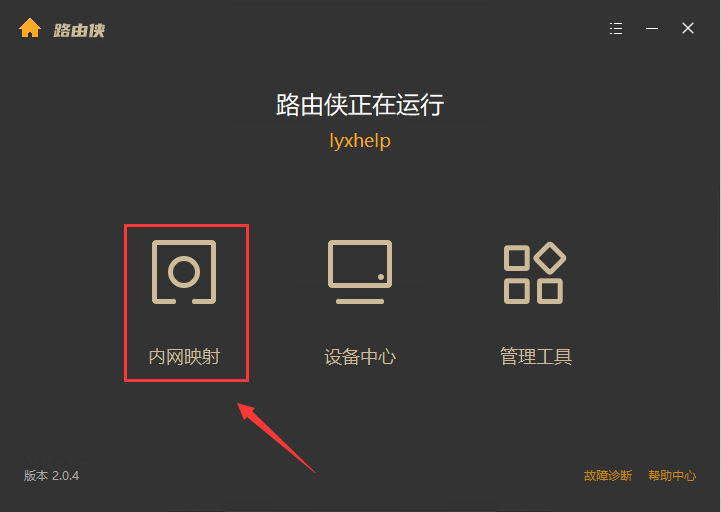
7,回到主界面,点击【内网映射】。
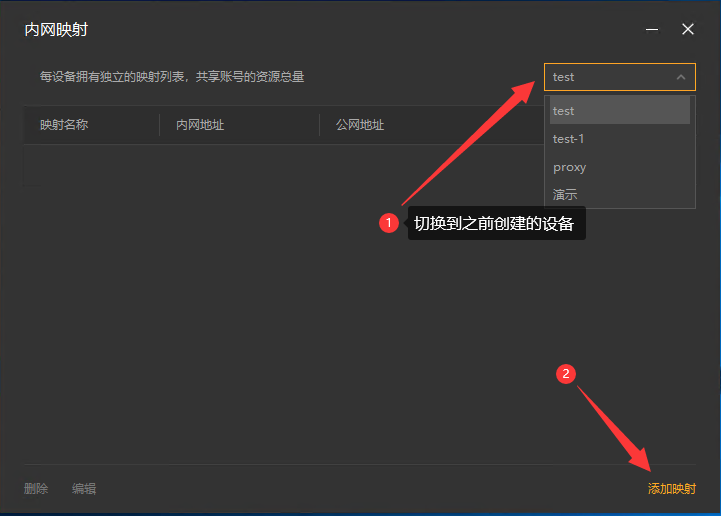
8,注意右上角的设备名称下拉框,这里选中刚刚添加的设备名称,此时在这个界面上添加的映射,就属于刚刚这个设备。添加或修改一般需要等待30秒,容器中的路由侠进程就会更新并加载。切换好设备后,点击【添加映射】。
9,选择【原生端口】。
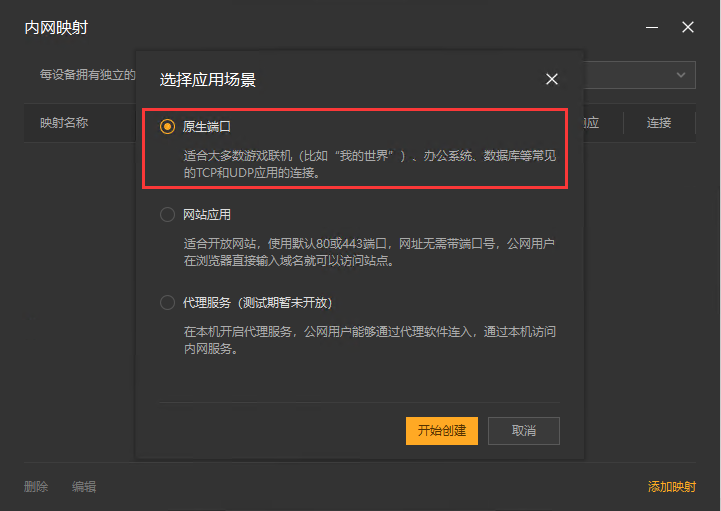
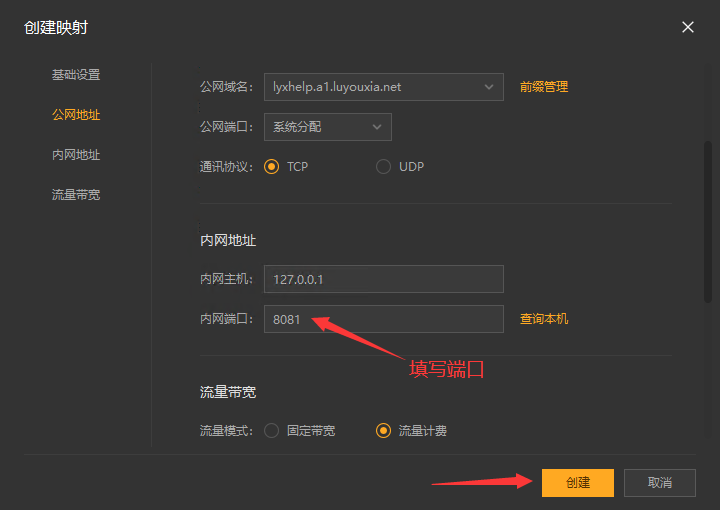
10,在内网端口里填写端口 8081 后点击【创建】按钮,如下图。
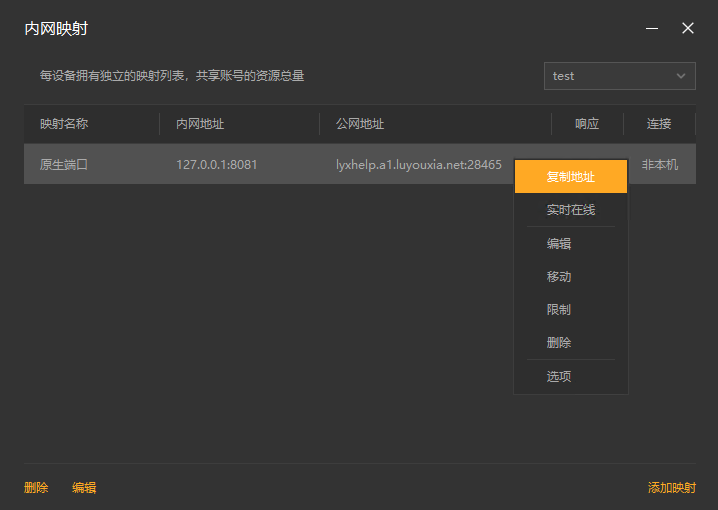
11,创建好后,就可以看到一条映射的公网地址,鼠标右键点击【复制地址】。
12,在外网电脑上,打开浏览器,在地址栏输入从路由侠生成的外网地址,就可以看到内网部署的 Flink 界面了。