安装压测软件
为了有效测试,应在局域网设备测试,我这里用的服务器是局域网内的Ubuntu,下载的压测软件是WRK
apt install wrk测试脚本
为了省事我直接在/root目录下新建lua脚本
vim test.lua脚本内容如下,app-xxxx更换为你工作流的API密钥
wrk.method = "POST"
wrk.body = '{"inputs":{"query":"1"},"response_mode":"streaming","user":"dcf压测"}'
wrk.headers["Content-Type"] = "application/json"
wrk.headers["Authorization"] = "Bearer app-08mesPqsdYfybwN6iIjyVcji"新建测试工作流
这里只新建了个空的工作流直接返回user_id,不加大模型,加上模型有其他延迟
API密钥在检测里面创建
开始压测
测试命令
wrk -t50 -c200 -d20s -s test.lua --timeout 10s --latency http://192.168.11.119/v1/workflows/run【测试20线程,200个链接,持续20秒,持续请求工作流10秒】
平均延迟:251.70毫秒,最大延迟:1.79秒,QPS:每秒851次
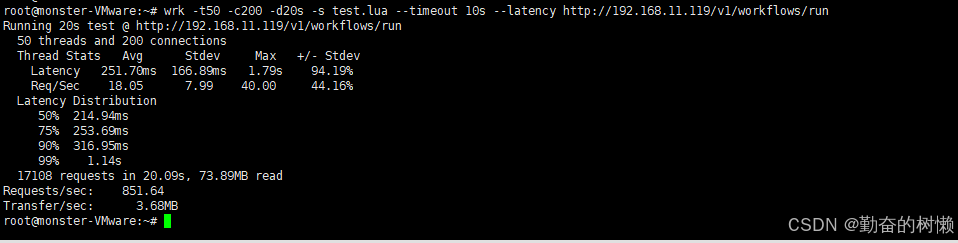
性能调优
修改工作进程数量参数SERVER_WORKER_AMOUNT,默认为1,官方参考公式:cpu核数*2+1。
我这里是CPU64核,256G内存,试了一下调成129,Dify有点动不了,然后我改成了65(每次修改.env文件参数需重启Dify)
#将默认的1参数改大,参考cpu核数*2+1
SERVER_WORKER_AMOUNT=65
再压测一下,明显快了很多

性能上来了,但是返现Dify里面的所有应用会提示报错:Internal Server Error
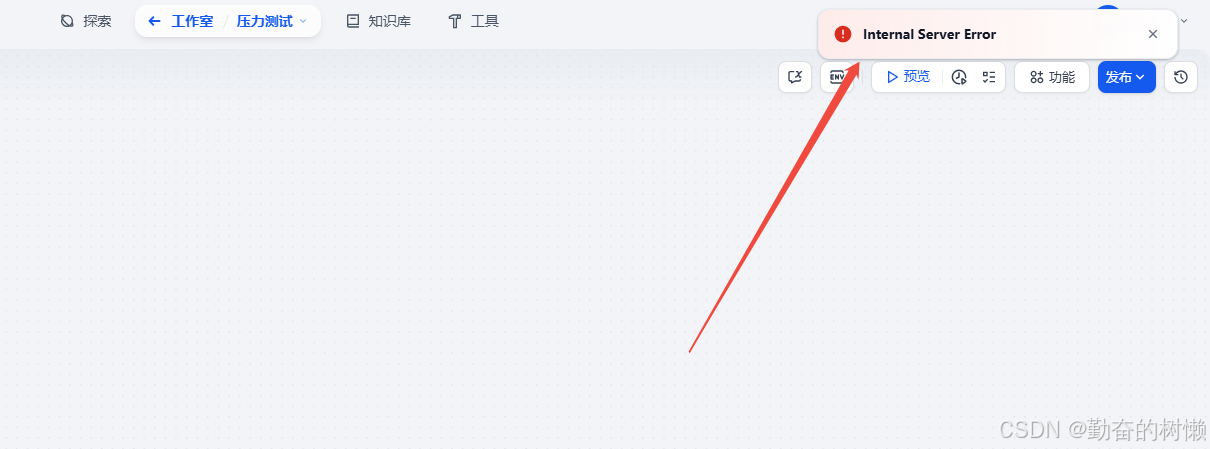
同时返回了很多非2XX和3XX响应,还需要修改连接池数量参数,避免超过连接数
我这里将SQLALCHEMY_POOL_SIZE、POSTGRES_MAX_CONNECTIONS、SQLALCHEMY_MAX_OVERFLOW三个参数全部调到了3000,默认30、100能不超过吗。
SQLALCHEMY_POOL_SIZE=3000
POSTGRES_MAX_CONNECTIONS=3000
#注意默认.env配置文件里没有SQLALCHEMY_MAX_OVERFLOW这个参数,需手动添加
SQLALCHEMY_MAX_OVERFLOW=3000重启Dify再测试,测一次1700+个对话
