目录
SpringCache详解
SpringCache概述
早期的Java开发中,缓存技术需要借助第三方库(Ehcache、Guava等),导致了代码与具体缓存实现强耦合。此时缺乏统一缓存规范,并且在企业中更换缓存组件成本较高。
Spring框架在3.1版本首次引入缓存抽象层,定义了Cache和CacheManager接口,通过注解(如@Cacheable)实现声明式缓存。随后在Spring4.1开始全面支持JCache规范(2012年提出的JSR-107规范草案),通过JCacheManager集成第三方缓存实现,自此开发者可以通过标准接口切换缓存方案,实现了通过标准接口隔离业务代码与具体缓存的抽象解耦,符合"开方-封闭原则"。
Spring Cache 是 Spring 框架提供的抽象化缓存解决方案,通过注解和 AOP 技术简化了缓存逻辑的集成。它并不直接管理缓存存储,而是作为统一接口 ,支持多种缓存实现(如 Ehcache、Redis、Caffeine 等),使开发者能够通过声明式注解快速为方法添加缓存功能,从而减少重复计算,提升系统性能。
核心原理
接口抽象与多态
SpringCache定义了两大核心接口实现缓存标准化:
- Cache接口
定义缓存基本操作(get、put、evict),不同缓存技术(如Redis、Ehcache)通过实现该接口完成适配,例如:
RedisCache通过RedisTemplate操作Redis数据
ConcurrentMapCache使用本地内存Map存储数据
- CacheManager接口
管理多个Cache实例的生命周期,支持多级缓存混合使用。
(EhCacheCacheManager解析ehcahe.xml配置,RedisCacheManager配置TTL和序列化策略)
AOP动态代理
SpringCache通过CacheInterceptor拦截器实现方法级缓存空值:
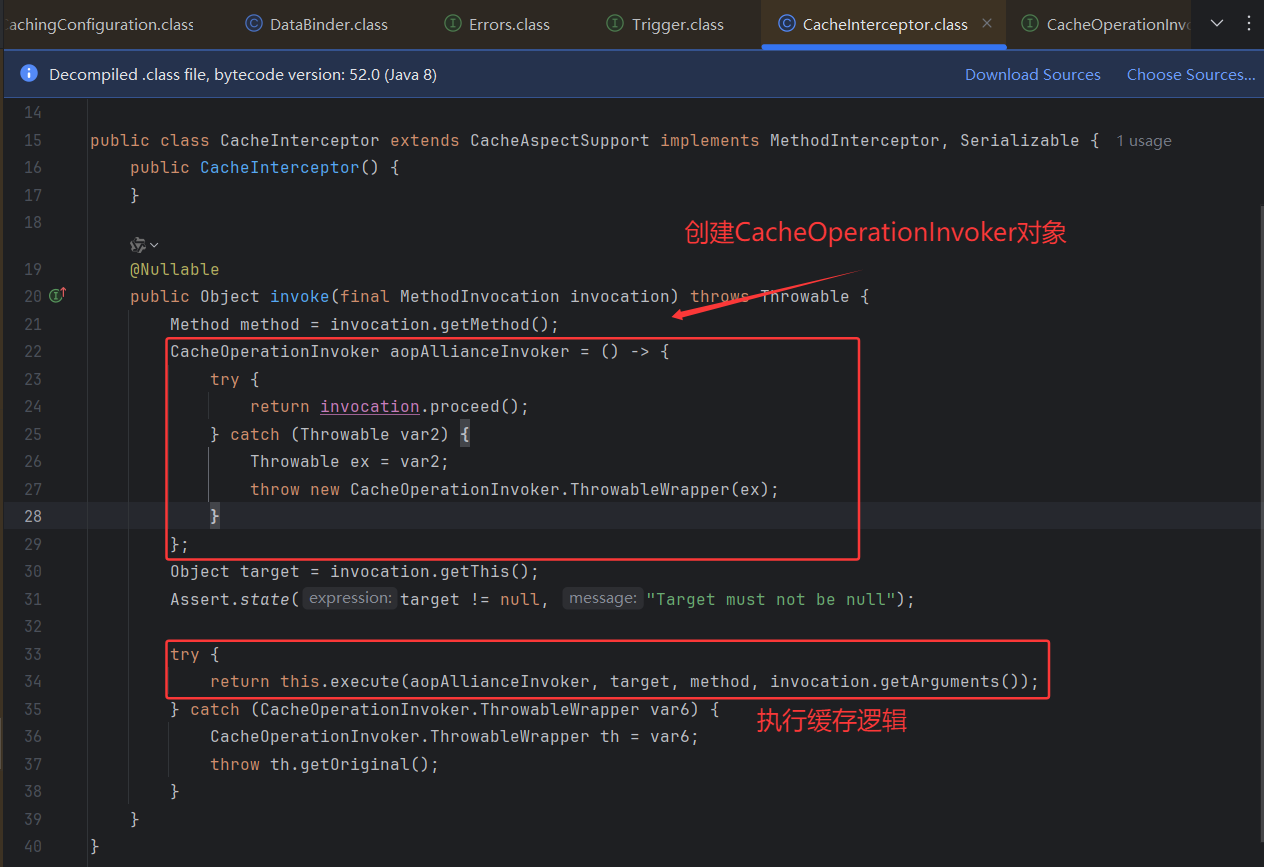
说明:
- 将
invocation.proceed()封装为CacheOperationInvoker实例,延迟执行原始方法。 - 捕获所有
Throwable并封装为ThrowableWrapper,避免缓存逻辑干扰异常类型。 - 调用
execute:传递方法调用器、目标对象、方法对象和参数,进入缓存处理核心逻辑。
然后一直跟进execute方法,最终找到处理缓存的主逻辑:
java
@Nullable
private Object execute(final CacheOperationInvoker invoker, Method method, CacheOperationContexts contexts) {
if (contexts.isSynchronized()) {
CacheOperationContext context = (CacheOperationContext)contexts.get(CacheableOperation.class).iterator().next();
if (!this.isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) {
return this.invokeOperation(invoker);
}
Object key = this.generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT);
Cache cache = (Cache)context.getCaches().iterator().next();
try {
return this.wrapCacheValue(method, this.handleSynchronizedGet(invoker, key, cache));
} catch (Cache.ValueRetrievalException var10) {
Cache.ValueRetrievalException ex = var10;
ReflectionUtils.rethrowRuntimeException(ex.getCause());
}
}
this.processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT);
Cache.ValueWrapper cacheHit = this.findCachedItem(contexts.get(CacheableOperation.class));
List<CachePutRequest> cachePutRequests = new ArrayList();
if (cacheHit == null) {
this.collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests);
}
Object cacheValue;
Object returnValue;
if (cacheHit != null && !this.hasCachePut(contexts)) {
cacheValue = cacheHit.get();
returnValue = this.wrapCacheValue(method, cacheValue);
} else {
returnValue = this.invokeOperation(invoker);
cacheValue = this.unwrapReturnValue(returnValue);
}
this.collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);
Iterator var8 = cachePutRequests.iterator();
while(var8.hasNext()) {
CachePutRequest cachePutRequest = (CachePutRequest)var8.next();
cachePutRequest.apply(cacheValue);
}
this.processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);
return returnValue;
}流程图:

核心注解以及使用
这里可以看这篇博客:SpringCache详解_spring cache-CSDN博客
公共属性
cacheNames
每个注解中都有自己的缓存名字。该名字的缓存与方法相关联,每次调用时,都会检查缓存以查看是否有对应cacheNames名字的数据,避免重复调用方法。名字可以可以有多个,在这种情况下,在执行方法之前,如果至少命中一个缓存,则返回相关联的值。( Springcache提供两个参数来指定缓存名:value、cacheNames,二者选其一即可,每一个需要缓存的数据都需要指定要放到哪个名字的缓存,缓存的分区,按照业务类型分 )

KeyGenerator:key生成器
缓存的本质是key-value存储模式,每一次方法的调用都需要生成相应的Key, 才能操作缓存。
通常情况下,@Cacheable有一个属性key可以直接定义缓存key,开发者可以使用SpEL语言定义key值。若没有指定属性key,缓存抽象提供了 KeyGenerator来生成key ,具体源码如下,
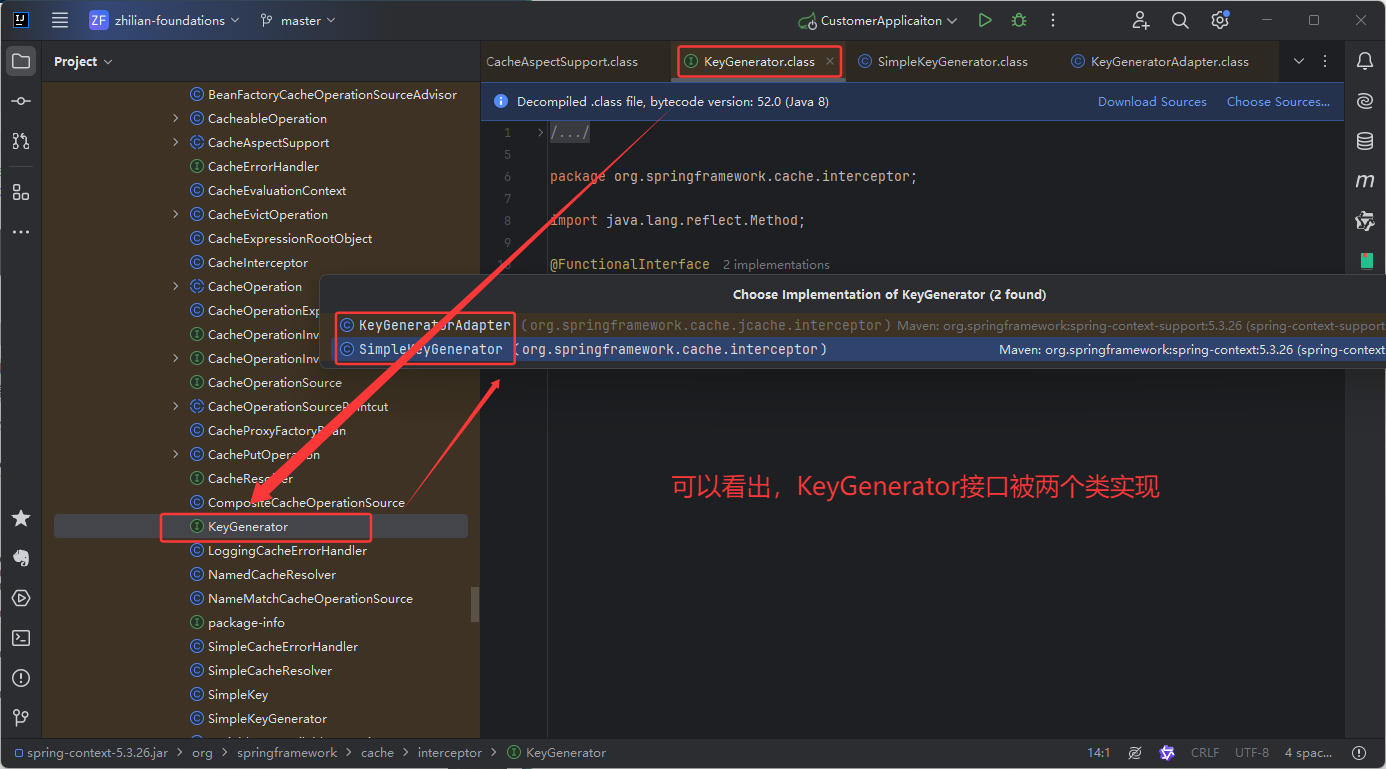
import java.lang.reflect.Method;
public class SimpleKeyGenerator implements KeyGenerator {
public SimpleKeyGenerator() {
}
public Object generate(Object target, Method method, Object... params) {
return generateKey(params);
}
public static Object generateKey(Object... params) {
if (params.length == 0) {
return SimpleKey.EMPTY;
} else {
if (params.length == 1) {
Object param = params[0];
if (param != null && !param.getClass().isArray()) {
return param;
}
}
return new SimpleKey(params);
}
}
}- 如果没有参数,则直接返回SimpleKey.EMPTY;
- 如果只有一个参数,则直接返回该参数;
- 若有多个参数,则返回包含多个参数的SimpleKey对象。
当然Spring Cache也考虑到需要自定义Key ,我们可以通过实现KeyGenerator 接口来重新定义key生成方式
默认的 key 生成器要求参数具有有效的 hashCode() 和 equals() 方法实现。
key
key,缓存的key,如果是redis,则相当于redis的key
可以为空,如果需要可以使用spel表达式进行表写。如果为空,则缺省默认使用key表达式生成器进行生成。默认的 key 生成器要求参数具有有效的 hashCode() 和 equals() 方法实现。key的生成器。key/keyGenerator二选一使用
condition:缓存的条件,对入参进行判断
可以为空,如果需要指定,需要使用SPEL表达式,返回true/false,只有返回true的时候才会对数据源进行缓存/清除缓存。在方法调用之前或之后都能进行判断。
condition=false 时,不读取缓存,直接执行方法体,并返回结果,同时返回结果也不放入缓存。
condition=true 时,读取缓存,有缓存则直接返回。无则执行方法体,同时返回结果放入缓存(如果配置了result,且要求不为空,则不会缓存结果)。
注意:
condition 属性使用的SpEL语言只有#root和获取参数类的SpEL表达式,不能使用返回结果的#result 。 所以 condition = "#result != null" 会导致所有对象都不进入缓存,每次操作都要经过数据库。
使用实例:
@Override
@Caching(evict = {
@CacheEvict(value = RedisConstants.CacheName.ZL_CACHE, key = "'ACTIVE_REGIONS'"),
@CacheEvict(value = RedisConstants.CacheName.SERVE_ICON, key = "#id"),
@CacheEvict(value = RedisConstants.CacheName.SERVE_TYPE, key = "#id"),
@CacheEvict(value = RedisConstants.CacheName.HOT_SERVE, key = "#id")
})注解
@Cacheable: 在方法执行前查看 是否有缓存对应的数据,如果有直接返回 数据,如果没有调用方法获取 数据返回,并缓存起来,也就是查询数据时缓存,将方法的返回值进行缓存
1、unless:条件符合则不缓存,对出参进行判断
unless属性可以使用#result表达式。效果: 缓存如果有符合要求的缓存数据则直接返回,没有则去数据库查数据,查到了就返回并且存在缓存一份,没查到就不存缓存。
condition 不指定相当于 true,unless 不指定相当于 false
当 condition = false,一定不会缓存;
当 condition = true,且 unless = true,不缓存;
当 condition = true,且 unless = false,缓存;
2、sync:是否使用异步,默认是false.
在一个多线程的环境中,某些操作可能被相同的参数并发地调用,同一个 value 值可能被多次计算(或多次访问 db),这样就达不到缓存的目的。针对这些可能高并发的操作,我们可以使用 sync 参数来告诉底层的缓存提供者将缓存的入口锁住,这样就只能有一个线程计算操作的结果值,而其它线程需要等待。当值为true,相当于同步可以有效的避免缓存击穿的问题。
@CachePut: 方法在执行前不会去检查 缓存中是否存在之前执行过的结果,而是每次都会执行该方法 ,并将执行结果以键值对的形式存入指定的缓存 中,简单来说就是更新缓存,将方法的返回值放到缓存中
**@CacheEvict:**用于清空缓存,方法在调用时会从缓存中移除已存储的数据
1、allEntries:是否清空左右缓存。默认为false
当指定了allEntries为true时,Spring Cache将忽略指定的key
2、beforeInvocation:是否在方法执行前就清空,默认为 false(可以看上面的流程图
清除操作默认是在对应方法成功执行之后触发的,即方法如果因为抛出异常而未能成功返回时也不会触发清除操作。使用beforeInvocation可以改变触发清除操作的时间,当我们指定该属性值为true时,Spring会在调用该方法之前清除缓存中的指定元素。
**@Caching:**组合多个缓存注解
xxl-job详解
在分布式环境下进行任务调度需要使用分布式任务调度平台,XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
官网:https://www.xuxueli.com/xxl-job/
文档:https://www.xuxueli.com/xxl-job/#《分布式任务调度平台XXL-JOB》
XXL-JOB主要有调度中心、执行器、任务:
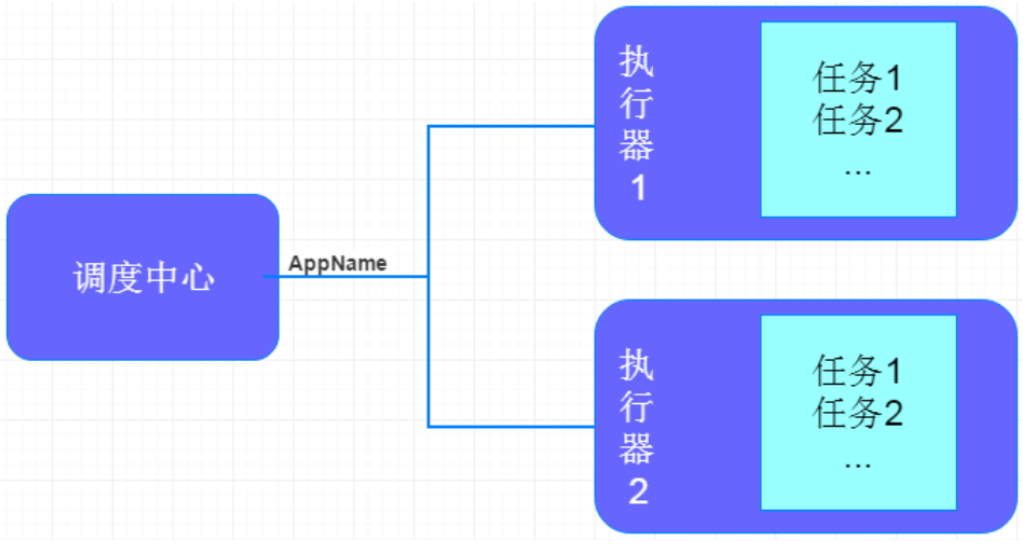
调度中心:
负责管理调度信息,按照调度配置发出调度亲你跪求,自身不承担业务代码;
主要职责为执行器管理、任务管理、监控运维、日志管理等;
任务执行器:
负责接收调度请求并执行任务逻辑;
主要职责是执行任务、执行结果上报、日志服务等;
使用xxl-job解决多个jvm进程冲入执行任务问题:
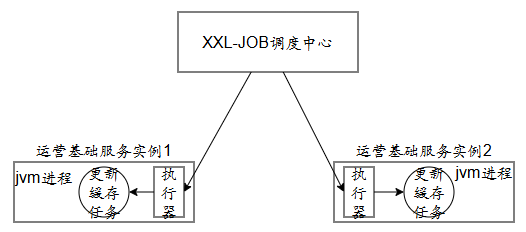
XXL-JOB调度中心可以配置路由策略:第一个、轮询策略、分片等
第一个:每次执行任务都由第一个执行器去执行
轮询:执行器轮番执行
分片:每次执行任务广播给每个执行器让他们同时执行任务
如果根据需求每次执行任务仅由一个执行器去执行任务可以设置路由策略:第一个、轮询
如果根据需求每次执行任务由多个执行器同时执行可以设置路由策略:分片
Springcache+Redis实现缓存
这里借用我最近做的一个项目的代码举例:(功能是将访问频率较高的查询开通区域列表接口进行缓存,并且在每天的凌晨1点实现缓存刷新,更新信息
启用区域后删除已开通区域列表缓存,当之后去查询开通区域列表时重新缓存最新的开通区域列表。
/**
* 已开通服务区域列表
*
* @return 区域简略列表
*/
@Override
@Cacheable(value = RedisConstants.CacheName.ZL_CACHE, key = "'ACTIVE_REGIONS'", cacheManager = RedisConstants.CacheManager.FOREVER)
public List<RegionSimpleResDTO> queryActiveRegionListCache() {
return queryActiveRegionList();
}xxl-job定时刷新缓存
foundations包下面的处理器handler类:定义了xxl-job实现缓存同步任务的定时任务
删除缓存->查询开通区域列表进行缓存->遍历区域列表下的服务类型进行缓存
package com.zhilian.foundations.handler;
import com.zhilian.api.foundations.dto.response.RegionSimpleResDTO;
import com.zhilian.foundations.constants.RedisConstants;
import com.zhilian.foundations.service.HomeService;
import com.zhilian.foundations.service.IRegionService;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
/**
* springCache缓存同步任务
*
**/
@Slf4j
@Component
public class SpringCacheSyncHandler {
@Resource
private IRegionService regionService;
@Resource
private RedisTemplate redisTemplate;
@Resource
private HomeService homeService;
/**
* 已启用区域缓存更新
* 每日凌晨1点执行
*/
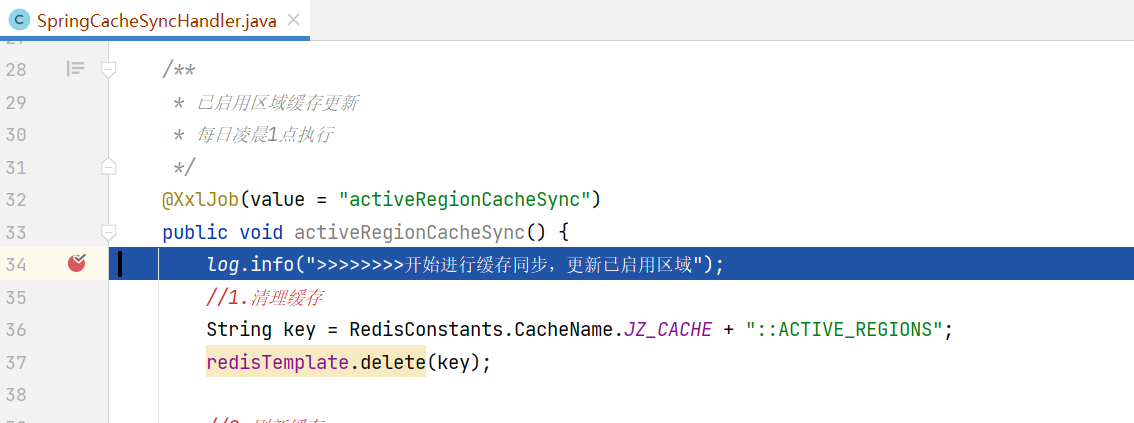
@XxlJob(value = "activeRegionCacheSync")
public void activeRegionCacheSync() {
log.info(">>>>>>>>开始进行缓存同步,更新已启用区域");
//删除缓存
Boolean delete = redisTemplate.delete(RedisConstants.CacheName.ZL_CACHE + "::ACTIVE_REGIONS");
//通过查询开通区域列表进行缓存
List<RegionSimpleResDTO> regionSimpleResDTOS = regionService.queryActiveRegionList();
//遍历区域对该区域下的服务类型进行缓存
regionSimpleResDTOS.forEach(item -> {
//区域id
Long regionId = item.getId();
//删除该区域下的首页服务列表
String serve_list_key = RedisConstants.CacheName.SERVE_ICON + "::" + regionId;
redisTemplate.delete(serve_list_key);
homeService.queryServeIconCategoryByRegionIdCache(regionId);
// 删除该区域下的服务类型列表缓存
String serve_type_key = RedisConstants.CacheName.SERVE_TYPE + "::" + regionId;
redisTemplate.delete(serve_type_key);
homeService.queryServeTypeList(regionId);
// 删除该区域下的服务类型列表缓存
String serve_hot_list_key = RedisConstants.CacheName.HOT_SERVE + "::" + regionId;
redisTemplate.delete(serve_hot_list_key);
homeService.queryHotServeListByRegionIdCache(regionId);
});
}
}代码写好了,需要去xxl-job调度中心对该定时任务进行管理:

填写任务信息:
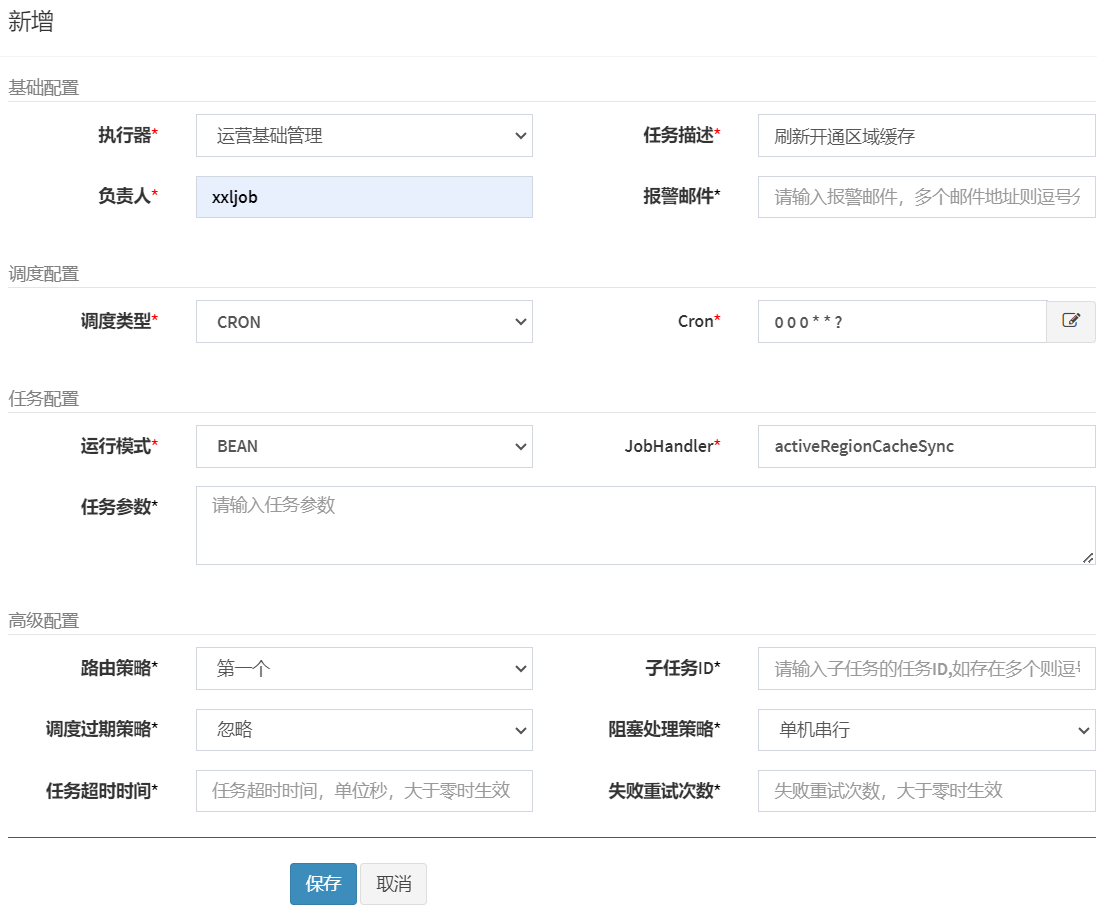
说明:
调度类型:CRON
固定速度指按固定的间隔定时调度
Cron,通过Cron表达式实现更丰富的定时调度策略
Cron表达式是一个字符串,通过它可以定义调度策略,格式:
{秒数}{分钟}{小时}{日期}{月份}{星期}{年份(可为空)}
xxl-job提供图形界面配置:

运行模式 :BEAN和GLUE,bean模式较常用就是在项目工程中编写执行器的任务代码,GLUE是将任务代码编写在调度中心(Bean模式通常有两种形式的实现:类形式和方法形式 ,此处使用的是方法形式,即在方法上加上@XxlJob注解
JobHandler即任务方法名,填写任务方法上边@XxlJob注解中的名称
任务配置完成,下边启动任务
启动成功:
我们在任务方法上打断点跟踪,任务方法被执行,如下图:
关于springcache的具体使用,可以看看这个文档:SpringCache详解_spring cache-CSDN博客
关于xxl-job的原理、架构分析以及使用,见这篇文档: