文章目录
- 前言
- [人类思考 VS 机器学习 VS 深度学习](#人类思考 VS 机器学习 VS 深度学习)
- 基础术语
- 损失函数
-
- 常用的损失函数
-
- [均方误差MSE(Mean Square Error)](#均方误差MSE(Mean Square Error))
- [交叉熵误差(Cross Entropy Error)](#交叉熵误差(Cross Entropy Error))
- mini-batch学习
- 为何要设定损失函数
- 数值微分
- 神经网络学习算法的实现
- 参考资料
前言
机器学习的过程通常分为学习 (从训练数据中自动获取权重参数的过程)和推理(利用学习到的权重参数对新的数据进行预测)两个环节。本文将主要介绍学习的过程。
人类思考 VS 机器学习 VS 深度学习
- 人类解决问题的思维方式:以经验和直觉为线索,通过反复试验来推进;
- 机器学习:避免人为介入,尝试从数据中得到答案(模式);
- 深度学习:比机器学习更加避免人为介入,又称为"端到端学习",也就是从原始数据(输入)获取到目标结果(输出)的意思。
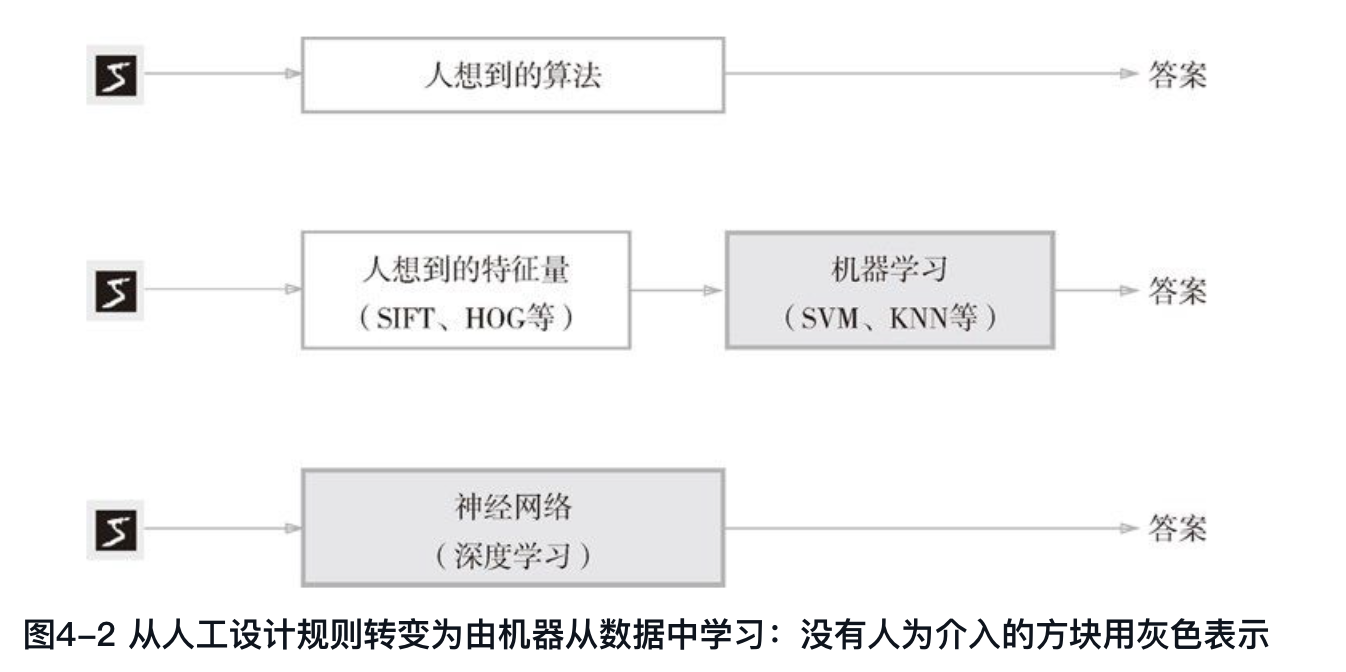
基础术语
- 训练数据/监督数据:用来学习权重参数的数据;
- 测试数据:评估模型性能的数据,检查模型的泛化能力();
- 泛化能力 :模型对未见过的数据的预测能力;泛化能力是机器学习的终极目标;
- 过拟合:模型在训练数据上表现的很好,在测试数据上表现的很差。
损失函数
损失函数是用于衡量神经网络性能"恶劣程度"的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
常用的损失函数
均方误差MSE(Mean Square Error)
E = 1 2 ∑ k ( t k − y k ) 2 E = \frac{1}{2}\sum_k{(t_k-y_k)^2} E=21k∑(tk−yk)2
python
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)其中, t k t_k tk是神经网络的输出, y k y_k yk是监督数据, k k k表示数据的维数。
举个例子:
y = 0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0
t = 0, 0, 1, 0, 0, 0, 0, 0, 0, 0
神经网络的输出 y y y是经过softmax函数后的输出,可以理解为概率。 t t t是监督数据,正确的标签为2。将正确标签表示为1,其他标签表示为0的表示方法称为one-hot表示。
交叉熵误差(Cross Entropy Error)
E = − ∑ k t k l o g y k E = -\sum_k t_klog{y_k} E=−k∑tklogyk
python
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))其中 l o g y k logy_k logyk是以 e e e为底的自然对数,图像如下:
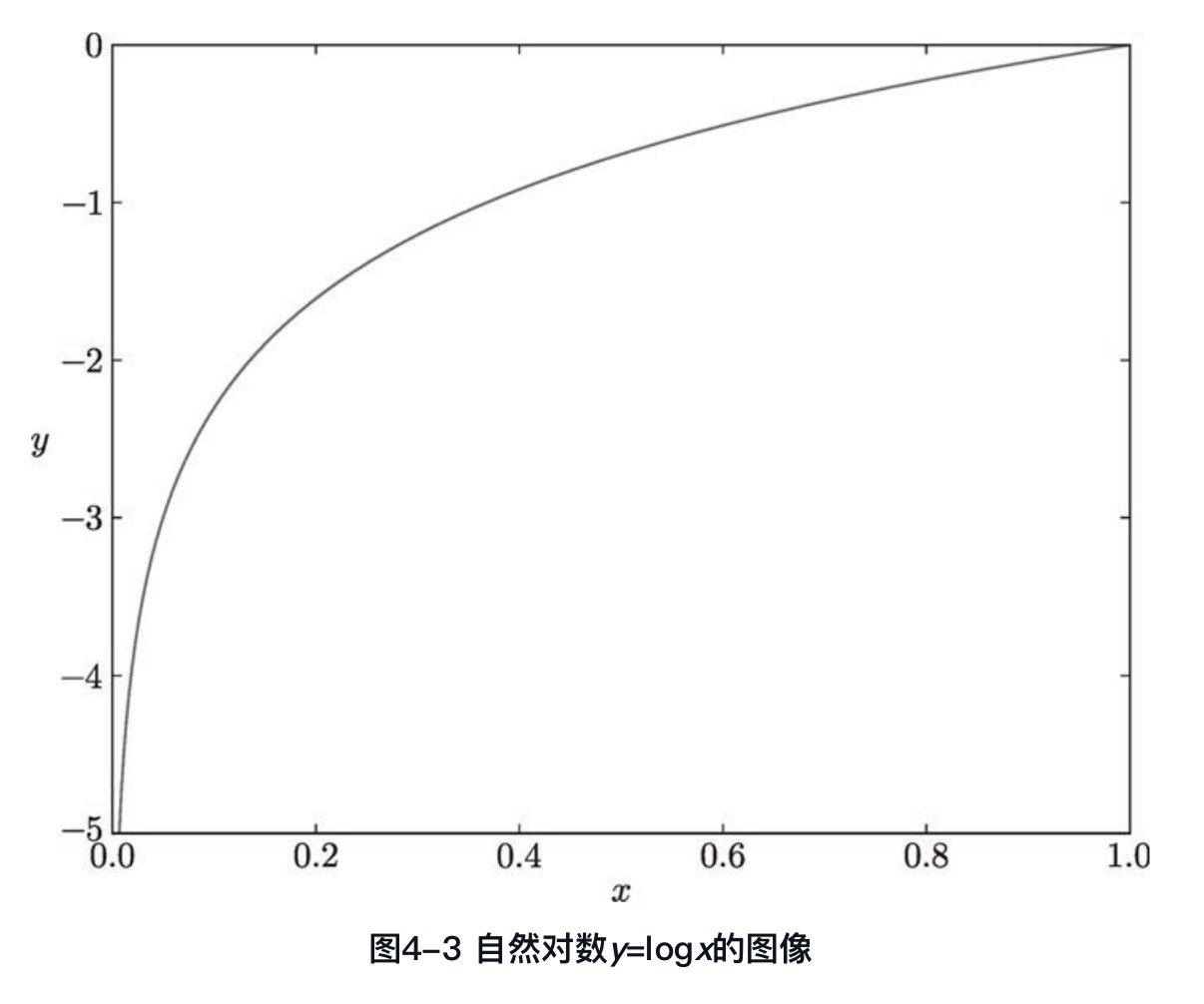
可以看到,交叉熵误差的值是由正确解标签所对应的输出结果而决定的。 当正确解标签的输出值(理解为概率)越接近于1,则 l o g y k logy_k logyk越接近于0,交叉熵误差越接近于0;反之,若正确解标签的输出值越接近于0,则 l o g y k logy_k logyk越接近于-5,即越来越大,交叉熵误差的值取-后,也越来越大。
mini-batch学习
上面介绍的损失函数的计算公式都是用来计算单条数据的,实际的运用中,我们都是用批量的数据进行学习,因此,计算损失函数也是批量计算,以交叉熵误差为例,批量计算的公式可以写作:
E = − 1 N ∑ k t n k l o g y n k E = -\frac{1}{N}\sum_kt_{nk}log{y_{nk}} E=−N1k∑tnklogynk
通过这样的平均化,可以获得与训练数据量无关的平均损失。
由于真实的训练数据量可能非常大,我们对所有的训练数据都求一次交叉熵误差值不太现实,通常我们会随机选择一批数据(称为mini-batch,小批量),然后对这个min-batch进行学习 。比如我们有60000条训练数据,每次选择100条进行学习。其核心思想是,用随机选择的小批量数据代表整体训练数据。
python
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]为何要设定损失函数
假设我们学习的最终目标是实现高准确率,为什么不直接以准确率作为指标,而是找一个损失函数呢?
原因是:如果以准确率为学习目标,则参数的导数在大多数地方都会变为0。假设我们正确识别了100个数据里32个正样本,如果我们是以准确率为目标,那当我们稍微修改参数,即使实现了一点点的优化,准确率仍然是32%,不会识别到准确率的改善。它的变化只有32%, 33%,34%...这类离散的值,阶跃函数也是一样的道理(除了在x=0的地方以外,其他地方的导数都为0)。然而如果以损失函数来刻画的话,就会是一个连续的值,即使是微小的改进也能刻画出来,因此神经网络的学习得以正常进行。
当损失函数的导数为负 时,我们让权重向正方向 改变,可以减小损失函数的值;当损失函数的导数为正 时,我们让权重向负方向 改变,可以减小损失函数的值;当损失函数的导数为0 时,权重不论朝哪个方向改变,损失函数的值都不会改变,此时,权重函数的更新会停在此处。
数值微分
这里直接参考我之前的文章即可:导数、偏导数、梯度
这里单独再回顾一下学习率 的概念。它决定了在一次学习中,应该学习多少,以及多大程度的更新参数。像学习率这类需要人工设置的参数,称为超参数 。它和神经网络里的参数(权重和偏置)不同,权重和偏置是通过训练数据和学习算法自动获得的,而超参数是需要人工设定的。
神经网络学习算法的实现
一共分为四个步骤:
- 抽取mini-batch:从训练数据中随机抽取一部分数据用于学习;
- 计算梯度:计算各个权重参数的梯度,梯度的方向代表了使得损失函数减少最多的方向;
- 更新参数:沿着梯度的方向更新权重
- 重复1-3步,直到达到终止条件。
两层神经网络的类
python
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
e_x = np.exp(x - np.max(x)) # 减最大值防止溢出
return e_x / e_x.sum(axis=0)
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_ini_std=0.01):
# 初始化权重
self.params = {}
# 生成一个形状为[input_size, hidden_size]的标准正态分布随机矩阵,然后用weight_ini_std进行缩放;
self.params['W1'] = weight_ini_std*np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_ini_std*np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a1 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
acc = np.sum(y==t) / float(x.shape[0])
return acc
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 超参数
iter_nums = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hiden_size=50, output_size=10)
# mini batch的实现
for i in range(iter_nums):
# 1. 获取mini-batch
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
# 2. 计算梯度
grad = network.numerical_gradient(x_train, t_train)
# 3. 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 记录学习过成
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 记录每个epoch的识别精度
if i % 100 == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
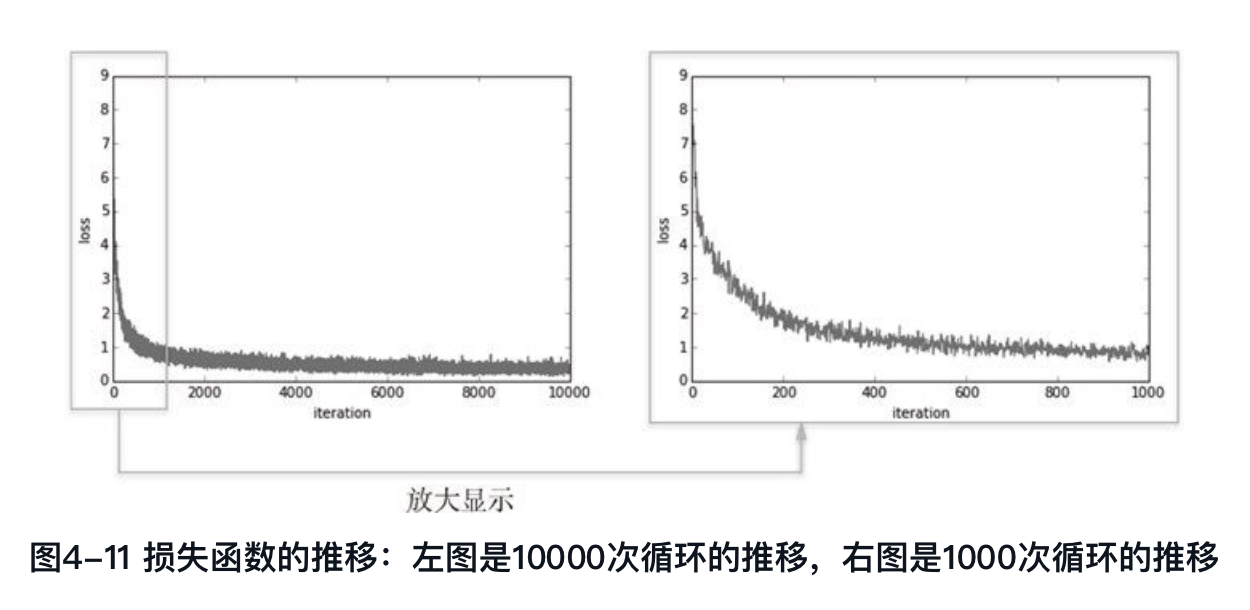
test_acc_list.append(test_acc)可视化损失函数的值:
代码里提到了epoch这个词语,我们理解一下。
前面提到,神经网络学习的最终目的是泛化能力,因此,我们要评估它在测试数据(没有见过的数据)上的表现。在学习的过程中,没经过一个epoch,都会记录模型在训练数据和测试数据上的表现。
epoch : 一个单位,表示训练数据中所有的数据都被使用过一次所需的更新的次数。比如我们一共有10000条训练数据,mini_batch_size=100,即每次随机抽取100条数据进行学习,那么可以认为重复随机梯度下降法100辞后,所有的训练数据都被看过了,此时,100就是一个epoch。
可视化acc的图:
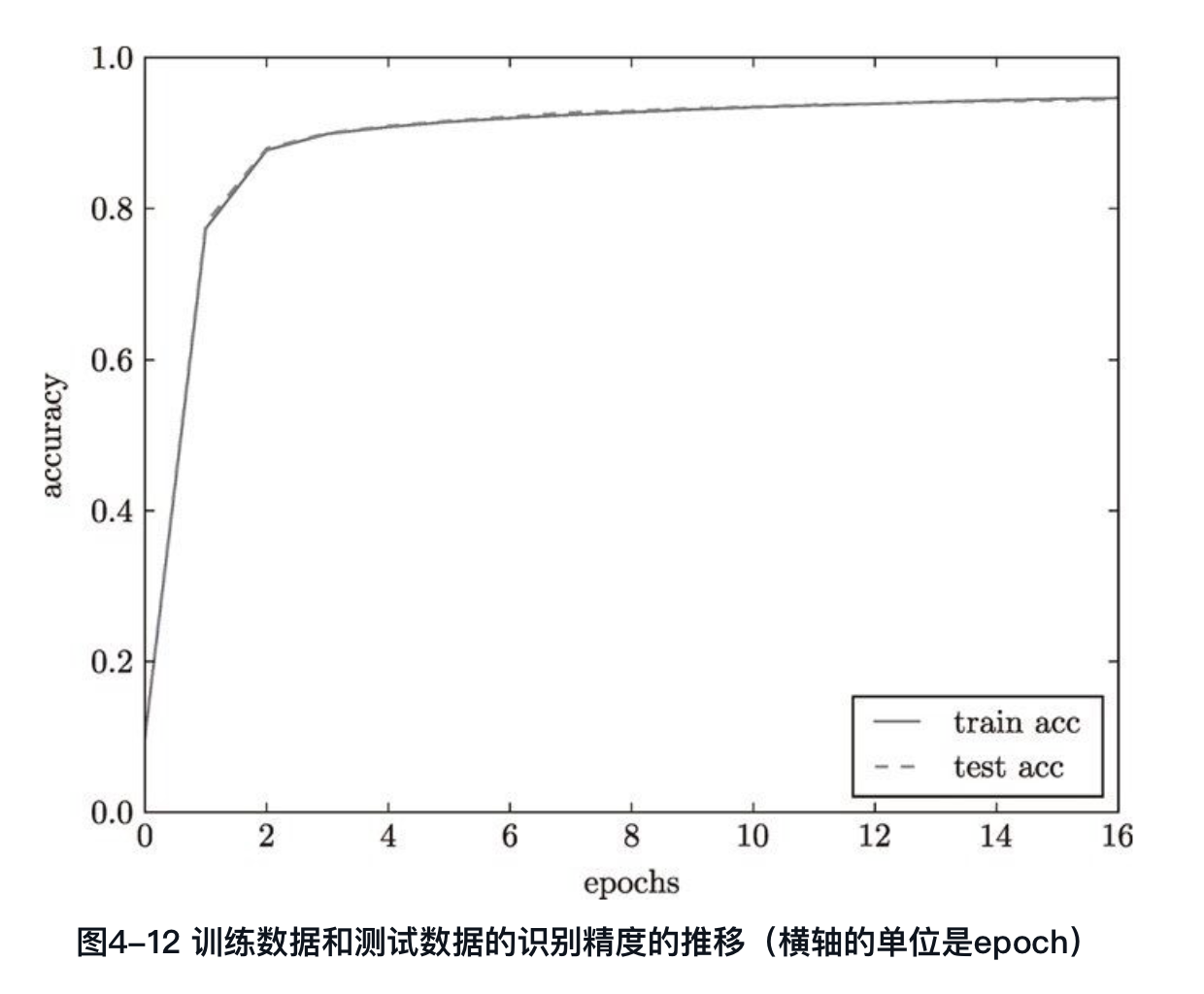
随着epoch(学习)的推进,两条曲线的京都都上升了,非常贴合,可以认为学习过程中没有发生过拟合的现象。
参考资料
1 斋藤康毅. (2018). 深度学习入门:基于Python的理论与实践. 人民邮电出版社.