RPM-Net
论文链接:RPM-Net: Robust Point Matching using Learned Features
官方链接:RPMNet
老规矩,先看看效果。

看看论文里给的对比图

总体流程
在学之前得储备PointNet++的知识,因为RPM-Net是通过PointNet++提取输入特征的。因为之前讲过Pointnet++,所以这里不会重复讲PointNet++的内容。
RPMNet是一个用于点云配准 的模型,基于传统算法RPM做的,而RPM是非常吃经验值 α α α和 β β β的,RPMNet通过神经网络来预测这两个值。
算法的总体框架如下图。
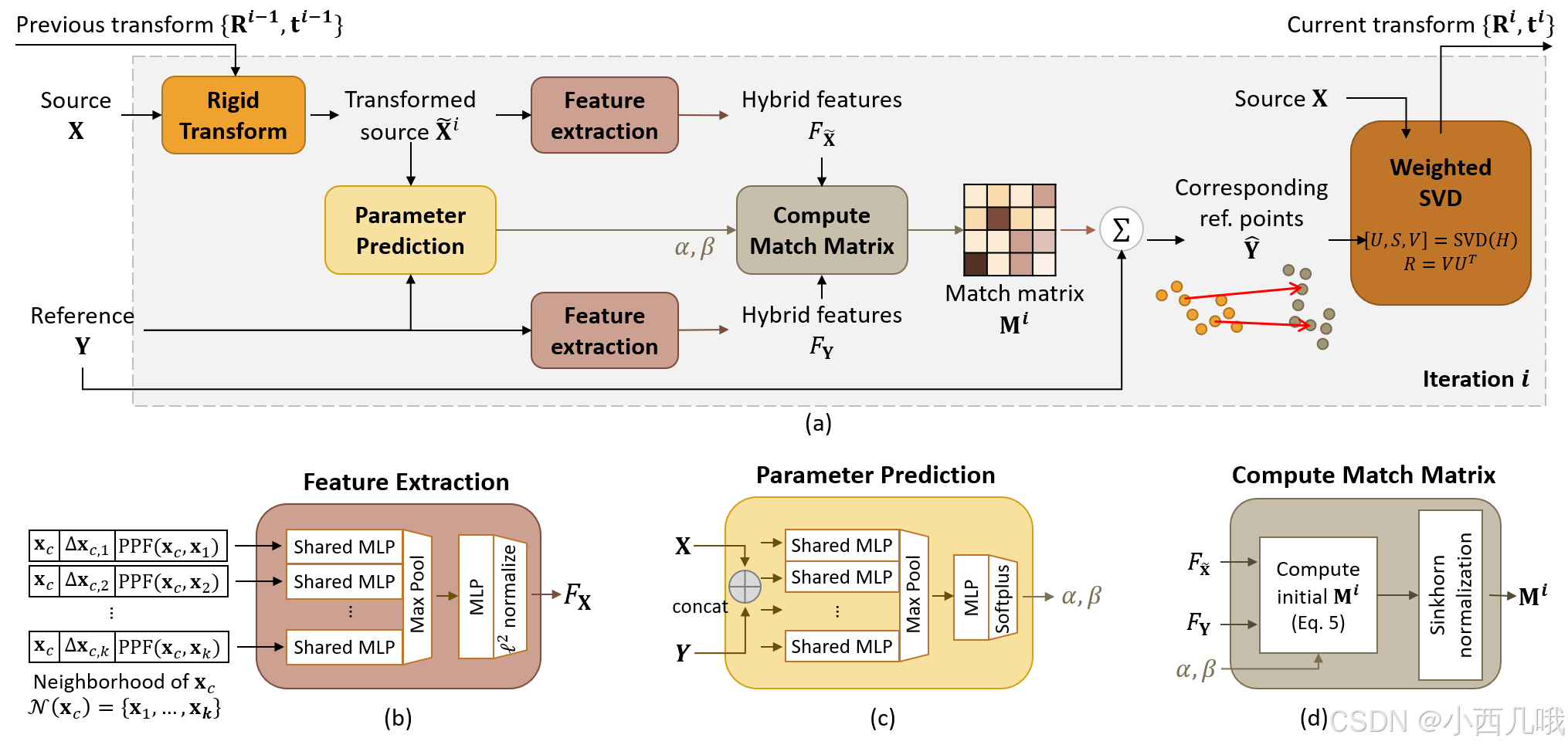
(b)这个特征提取模块和PointNet++是一样,不过这里有些不同的是,这里会提取10个特征。首先xyz、dxyz肯定是有的,然后还有4个就是这个PPF。PointNet++ 里不是有多簇嘛,每个簇里有很多个点,这些点与簇的关系是怎么样的呢?这就是PPF要干的事情,最后会得到4个关系特征。
(c)X,Y分别是原点云数据和参考点云数据(原点云数据仅是在原数据上采样了,或者裁剪了,位置什么的都没有变化。参考点云数据在采样裁剪的基础上还会有一些扰动,比如旋转平移之类的)。然后经过一系列的Conv1D卷积,maxpool,连几个MLP全连接层,最后激活输出 α α α和 β β β。
(d)这里输入的 F x F_x Fx和 F y F_y Fy是(b)的输出, α α α和 β β β是©的输出。最后我们得到啥?变换的矩阵啊。这个变换矩阵的的求解论文到没详细说,只是引用了两篇参考文献,表示照着这个人家这个做的,有兴趣的可以去看看这两篇文献[DeepICP](https://arxiv.org/abs/1905.04153),[Deep Closest Point](https://arxiv.org/abs/1905.03304)。
代码
数据预处理
数据预处理这块很简单,在路径src/data_loader/datasets.py的方法get_train_datasets。
python
def get_train_datasets(args: argparse.Namespace):
train_categories, val_categories = None, None
if args.train_categoryfile: # 训练类别
train_categories = [line.rstrip('\n') for line in open(args.train_categoryfile)]
train_categories.sort()
if args.val_categoryfile: # 验证类别
val_categories = [line.rstrip('\n') for line in open(args.val_categoryfile)]
val_categories.sort()
# 根据指定的参数对数据进行变换
train_transforms, val_transforms = get_transforms(args.noise_type, args.rot_mag, args.trans_mag,
args.num_points, args.partial)
_logger.info('Train transforms: {}'.format(', '.join([type(t).__name__ for t in train_transforms])))
_logger.info('Val transforms: {}'.format(', '.join([type(t).__name__ for t in val_transforms])))
train_transforms = torchvision.transforms.Compose(train_transforms)
val_transforms = torchvision.transforms.Compose(val_transforms)
if args.dataset_type == 'modelnet_hdf': # 从数据集中选择了部分数据
train_data = ModelNetHdf(args.dataset_path, subset='train', categories=train_categories,
transform=train_transforms)
val_data = ModelNetHdf(args.dataset_path, subset='test', categories=val_categories,
transform=val_transforms)
else:
raise NotImplementedError
return train_data, val_data步骤很简单吧,首先拿到数据的类别信息,然后根据参数对数据进行变换。数据集里并不是所有的数据都适合做这个任务的,所以作者选了一部分的数据来做。主要看看get_transforms吧,别的也没啥好说的。
python
def get_transforms(noise_type: str,
rot_mag: float = 45.0, trans_mag: float = 0.5,
num_points: int = 1024, partial_p_keep: List = None):
partial_p_keep = partial_p_keep if partial_p_keep is not None else [0.7, 0.7] # 裁剪比例
if noise_type == "clean":
...
elif noise_type == "jitter":
...
elif noise_type == "crop":
# Both source and reference point clouds cropped, plus same noise in "jitter"
train_transforms = [Transforms.SplitSourceRef(), # 复制一份 源点云和参考点云
Transforms.RandomCrop(partial_p_keep), # 裁剪
Transforms.RandomTransformSE3_euler(rot_mag=rot_mag, trans_mag=trans_mag), # 旋转 平移
Transforms.Resampler(num_points), # 采样num_points个点
Transforms.RandomJitter(), # 高斯噪声
Transforms.ShufflePoints()] # 打乱点的顺序
test_transforms = [Transforms.SetDeterministic(),
Transforms.SplitSourceRef(),
Transforms.RandomCrop(partial_p_keep),
Transforms.RandomTransformSE3_euler(rot_mag=rot_mag, trans_mag=trans_mag),
Transforms.Resampler(num_points),
Transforms.RandomJitter(),
Transforms.ShufflePoints()]
else:
raise NotImplementedError
return train_transforms, test_transforms因为clean和jitter的内容都包含在crop,我就直接说crop了。作者没有直接用transforms.Compose的方法哈,所有的变换都是自己写的,在路径src/data_loader/transforms.py下。我就不去transforms.py里细讲了,这个看名字也知道干啥了。SplitSourceRef()拷贝一份点云数据(源点云和参考点云)、RandomCrop()随机裁剪、RandomTransformSE3_euler()随机旋转和平移、Resampler()随机采样、RandomJitter()添加高斯噪声、ShufflePoints()随机打乱。
模型
主要来看看模型的前向传播是怎么搞的,在路径src/models/rpmnet.py里RPMNet的方法forward。
python
def forward(self, data, num_iter: int = 1):
endpoints = {}
xyz_ref, norm_ref = data['points_ref'][:, :, :3], data['points_ref'][:, :, 3:6]
xyz_src, norm_src = data['points_src'][:, :, :3], data['points_src'][:, :, 3:6]
xyz_src_t, norm_src_t = xyz_src, norm_src # (b,717,3) 717=1024*0.7
transforms = []
all_gamma, all_perm_matrices, all_weighted_ref = [], [], []
all_beta, all_alpha = [], []
for i in range(num_iter):
beta, alpha = self.weights_net([xyz_src_t, xyz_ref])
feat_src = self.feat_extractor(xyz_src_t, norm_src_t) # (b,717,96)
feat_ref = self.feat_extractor(xyz_ref, norm_ref) # (b,717,96)
feat_distance = match_features(feat_src, feat_ref) # 计算距离 (b,717,717)
affinity = self.compute_affinity(beta, feat_distance, alpha=alpha) # (b,717,717)
# Compute weighted coordinates
log_perm_matrix = sinkhorn(affinity, n_iters=self.num_sk_iter, slack=self.add_slack)
perm_matrix = torch.exp(log_perm_matrix)
weighted_ref = perm_matrix @ xyz_ref / (torch.sum(perm_matrix, dim=2, keepdim=True) + _EPS) # (b,717,3)
# Compute transform and transform points
transform = compute_rigid_transform(xyz_src, weighted_ref, weights=torch.sum(perm_matrix, dim=2)) # (b,3,4)
xyz_src_t, norm_src_t = se3.transform(transform.detach(), xyz_src, norm_src)
transforms.append(transform)
all_gamma.append(torch.exp(affinity))
all_perm_matrices.append(perm_matrix)
all_weighted_ref.append(weighted_ref)
all_beta.append(to_numpy(beta))
all_alpha.append(to_numpy(alpha))
endpoints['perm_matrices_init'] = all_gamma
endpoints['perm_matrices'] = all_perm_matrices
endpoints['weighted_ref'] = all_weighted_ref
endpoints['beta'] = np.stack(all_beta, axis=0)
endpoints['alpha'] = np.stack(all_alpha, axis=0)
return transforms, endpoints先将源点和参考点的xyz坐标与法向量坐标拿出来吗,方便后面做计算。好,直接看for循环。之前有说过传统算法RPM是非常吃经验值的, α α α和 β β β需要人为估计一个值。作者一想,好麻烦,直接使用神经网络来预测一个吧。来看看self.weights_net怎么做的。
计算 α α α和 β β β
在路径src/models/feature_nets.py里ParameterPredictionNet的方法forward。
python
def forward(self, x):
src_padded = F.pad(x[0], (0, 1), mode='constant', value=0) # 多了一个标识符 src的为0
ref_padded = F.pad(x[1], (0, 1), mode='constant', value=1) # ref的为1 (b,717,4) 4->xyz+标识符
concatenated = torch.cat([src_padded, ref_padded], dim=1) # (b,1434,4)
prepool_feat = self.prepool(concatenated.permute(0, 2, 1)) # (b,4,1434) -> (b,1024,1434)
pooled = torch.flatten(self.pooling(prepool_feat), start_dim=-2) # (b,1024)
raw_weights = self.postpool(pooled) # (b,2)
beta = F.softplus(raw_weights[:, 0])
alpha = F.softplus(raw_weights[:, 1])
return beta, alpha首先将源点云数据和参考点云数据拼接在一起,在此之前呢会给它们添个标识符,源的为0,参考的为1。
这里解释一下为什么经常使用permute来转变维度,因为pytorch里channel first,特征维度要放在第一位(也就是batch后的第一位)。正常特征图的维度是(c,h,w),但这里只有两个维度啊,2D卷积用不了,所以用的是一维卷积Conv1d。看一下self.prepool的结构。
python
self.prepool = nn.Sequential(
nn.Conv1d(4, 64, 1),
nn.GroupNorm(8, 64),
nn.ReLU(),
nn.Conv1d(64, 64, 1),
nn.GroupNorm(8, 64),
nn.ReLU(),
nn.Conv1d(64, 64, 1),
nn.GroupNorm(8, 64),
nn.ReLU(),
nn.Conv1d(64, 128, 1),
nn.GroupNorm(8, 128),
nn.ReLU(),
nn.Conv1d(128, 1024, 1),
nn.GroupNorm(16, 1024),
nn.ReLU(),
)self.prepool里有好几层Conv1d,可以看到channel的的变化,4->64->64->64->128->1024。这里的nn.GroupNorm也是一种归一化的方式,第一个参数是num_groups,表示将channel划分为num_groups组,比如第一层输出是(8, 64, 1434),会将64个channel划分为8组,每组8个channel。然后每个样本独立计算(不依赖 batch 统计信息),每个组共享均值和方差,然后归一化。(像常见的BN,会依赖batch size,因为它是计算整个 batch 维度的均值和方差)。
然后做一个maxpooling,将数据浓缩成精华。比如pooling之前,1434个点有1024个特征;pooling完之后,不是每个点有啥特征了,而是全局的一个特征是一个1024维向量。现在做完这些我们得有一个输出了,还记得我们初衷吗?预测 α α α和 β β β啊。看一下self.postpool的结构。
python
self.postpool = nn.Sequential(
nn.Linear(1024, 512),
nn.GroupNorm(16, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.GroupNorm(16, 256),
nn.ReLU(),
nn.Linear(256, 2 + np.prod(weights_dim)),
)连了几个全连接,可以看到维度的转变, 1024->512->256->2。输出的结果可以看到有正有负,不过 α α α和 β β β的值需要是正数,所以连个F.softplus,可以看做激活函数,最后输出。
=======================================================================
回到RPMNet的forward,现在需要对原点云数据和参考点云数据进行特征提取,来看看self.feat_extractor是怎么做的。
特征提取
在路径src/models/feature_nets.py里FeatExtractionEarlyFusion的方法forward。先展示部分。
python
def forward(self, xyz, normals):
features = sample_and_group_multi(-1, self.radius, self.n_sample, xyz, normals)
features['xyz'] = features['xyz'][:, :, None, :]之前PointNet++里也有sample_and_group_multi,代码一模一样的,不过这里面添了个PPF,来看看怎么回事。
python
def sample_and_group_multi(npoint: int, radius: float, nsample: int, xyz: torch.Tensor, normals: torch.Tensor,
returnfps: bool = False):
B, N, C = xyz.shape
if npoint > 0:
S = npoint
fps_idx = farthest_point_sample(xyz, npoint) # [B, npoint, C]
new_xyz = index_points(xyz, fps_idx)
nr = index_points(normals, fps_idx)[:, :, None, :]
else:
S = xyz.shape[1]
fps_idx = torch.arange(0, xyz.shape[1])[None, ...].repeat(xyz.shape[0], 1).to(xyz.device)
new_xyz = xyz
nr = normals[:, :, None, :] # (b,717,1,3)
idx = query_ball_point(radius, nsample, xyz, new_xyz, fps_idx) # (B, npoint, nsample)
grouped_xyz = index_points(xyz, idx) # (B, npoint, nsample, C) npoint个簇 每个簇nsample个点 每个点C个特征
d = grouped_xyz - new_xyz.view(B, S, 1, C) # d = p_r - p_i (B, npoint, nsample, 3) 去均值(邻域点相对中心点的位置偏移量)
ni = index_points(normals, idx)
nr_d = angle(nr, d) # 中心点法向量与邻域点坐标偏移量的夹角 (b,717,64)
ni_d = angle(ni, d) # 邻域点法向量与邻域点坐标偏移量的夹角 (b,717,64)
nr_ni = angle(nr, ni) # 中心点法向量与邻域点法向量的夹角 (b,717,64)
d_norm = torch.norm(d, dim=-1) # 邻域点相对中心点的距离 (b,717,64)
xyz_feat = d # (B, npoint, n_sample, 3)
ppf_feat = torch.stack([nr_d, ni_d, nr_ni, d_norm], dim=-1) # (B, npoint, n_sample, 4)
if returnfps:
return {'xyz': new_xyz, 'dxyz': xyz_feat, 'ppf': ppf_feat}, grouped_xyz, fps_idx
else:
return {'xyz': new_xyz, 'dxyz': xyz_feat, 'ppf': ppf_feat}这里输入的npoint为-1,表示每个点都作为中心点画圈采样。query_ball_point之前在PointNet++里面讲的很详细了,这里就不说了。得到的grouped_xyz的size为(B, 717, 64, 3),可以理解为:以所有点为中心画圈,圈成717个簇,每个簇64个点,每个点3个特征。
nr_d的size为(B,717,64),这个计算的是中心点法向量与邻域点坐标偏移量的夹角,可以理解为:每簇里有64个点,这64个点与对应簇的关系。同理,ni_d、nr_ni和d_norm你都可以这样理解,就是计算簇里的点与簇的关系,论文里也没解释为啥这样做。
=======================================================================
回到FeatExtractionEarlyFusion的forward中,继续往下看。
python
# Gate and concat
concat = []
for i in range(len(self.features)): # 为了将10个特征拼在一起
f = self.features[i]
expanded = (features[f]).expand(-1, -1, self.n_sample, -1)
concat.append(expanded)
fused_input_feat = torch.cat(concat, -1) # (B,717,64,10)
# Prepool_FC, pool, postpool-FC
new_feat = fused_input_feat.permute(0, 3, 2, 1) # [B, 10, n_sample, N]
new_feat = self.prepool(new_feat)
pooled_feat = torch.max(new_feat, 2)[0] # Max pooling (B, C, N)
post_feat = self.postpool(pooled_feat) # Post pooling dense layers
cluster_feat = post_feat.permute(0, 2, 1)
cluster_feat = cluster_feat / torch.norm(cluster_feat, dim=-1, keepdim=True)
return cluster_feat # (B, N, C)for循环是为了将xyz、dxyz和ppf的特征拼接在一起,得到fused_input_feat的size为(b,717,64,10)。ok。现在我们有3个维度了,可以做2D卷积了,来看看self.prepool的结构。
python
Sequential(
nn.Conv2d(10, 96, 1),
nn.GroupNorm(8, 96),
nn.ReLU(),
nn.Conv2d(96, 96, 1),
nn.GroupNorm(8, 96),
nn.ReLU(),
nn.Conv2d(96, 192, 1),
nn.GroupNorm(8, 192),
nn.ReLU(),
)可以看到维度的变化,10->96->96->192。然后接着Max pooling得到size为(b,192,717)。这下又只有两个维度了,只能用1D卷积了,来看一下self.postpool的结构。
python
Sequential(
nn.Conv1d(192, 192, 1),
nn.GroupNorm(8, 192),
nn.ReLU(),
nn.Conv1d(192, 96, 1),
nn.GroupNorm(8, 96),
nn.ReLU(),
nn.Conv1d(96, 96, 1),
)可以看到维度的变化,192->96。最后进行L2归一化,得到最终输出,size为(B,717,96)
。
=======================================================================
回到RPMNet的forward,继续往下看。现在要计算变换矩阵了。
变换矩阵
1、计算加权坐标
现在源点云数据和参考点云数据的特征都提取出来了,match_features来计算它俩之间的距离。每个源点与所有的参考点计算距离(相似度),构成一个J × K 的匹配矩阵(这里J、K是一样的),size为(b,717,717)。compute_affinity的解释是计算匹配矩阵值的对数, 看一下是怎么计算的。
python
def compute_affinity(self, beta, feat_distance, alpha=0.5):
if isinstance(alpha, float):
hybrid_affinity = -beta[:, None, None] * (feat_distance - alpha)
else:
hybrid_affinity = -beta[:, None, None] * (feat_distance - alpha[:, None, None])
return hybrid_affinity很简单啊,公式就是 β × ( 匹配矩阵 − α ) β×(匹配矩阵-α) β×(匹配矩阵−α),这个公式可以理解为,衡量每对点之间是否是对应点(源点-参考点 对应关系)。你要问我为什么这样就可以衡量?那我包支支吾吾的,应该涉及传统RPM算法的数学公式吧...。不过,很显然这里面也没计算对数啊,我看了一下在下面的sinkhorn计算了。
sinkhorn的解释是将输入矩阵归一化为近似的双重随机矩阵(每行、每列的和小于等于1)。就不跳进去看了,代码很简单。结果出来又进行了torch.exp,刚log完又exp回来,就理解为将刚刚的矩阵归一化了就行,得到源点和参考点的匹配关系。最后计算加权的参考点坐标,用刚刚的概率矩阵作为权重(因为归一化了嘛,就当概率矩阵看吧),与参考点进行加权求和,最终得到每个源点对应的加权参考点坐标,然后归一化。
(注:这里应该是涉及了一些数学公式的推导,但是论文里并没有详细说,就这么理解吧)
2、计算刚体变换矩阵和变换点
compute_rigid_transform是计算刚体变换的,即找到一个 旋转矩阵和平移向量 ,使得源点变换后最接近参考点。看一下compute_rigid_transform干了啥吧。
python
def compute_rigid_transform(a: torch.Tensor, b: torch.Tensor, weights: torch.Tensor):
weights_normalized = weights[..., None] / (torch.sum(weights[..., None], dim=1, keepdim=True) + _EPS) # (b,717,1)
centroid_a = torch.sum(a * weights_normalized, dim=1) # (b,3)
centroid_b = torch.sum(b * weights_normalized, dim=1) # (b,3)
a_centered = a - centroid_a[:, None, :] # 去中心化 (b,717,3)
b_centered = b - centroid_b[:, None, :] # (b,717,3)
cov = a_centered.transpose(-2, -1) @ (b_centered * weights_normalized) # (b,3,3)
# Compute rotation using Kabsch algorithm. Will compute two copies with +/-V[:,:3]
# and choose based on determinant to avoid flips
u, s, v = torch.svd(cov, some=False, compute_uv=True)
rot_mat_pos = v @ u.transpose(-1, -2)
v_neg = v.clone()
v_neg[:, :, 2] *= -1
rot_mat_neg = v_neg @ u.transpose(-1, -2)
rot_mat = torch.where(torch.det(rot_mat_pos)[:, None, None] > 0, rot_mat_pos, rot_mat_neg)
assert torch.all(torch.det(rot_mat) > 0)
# Compute translation (uncenter centroid)
translation = -rot_mat @ centroid_a[:, :, None] + centroid_b[:, :, None]
transform = torch.cat((rot_mat, translation), dim=2)
return transform先将权重归一化,这个权重weights就是我刚刚说的概率矩阵的和。对源点坐标和参考点坐标进行去中心化,使其绕 (0,0,0) 旋转。然后计算它俩之间的协方差矩阵,...,woc下面全是数学公式,看得我头疼。
下面代码看不懂,看注释上写的是计算旋转矩阵、处理镜像翻转、计算平移向量,最终找到源点到参考点的最优刚体变换(旋转+平移)。返回的是刚体变换矩阵size为(b,3,4),3表示xyz,4:前三列是旋转矩阵,最后一列是平移向量。
======================================================================
回到RPMNet的forward,继续往下看。
这时候我们已经有变换矩阵了,那得看看这个矩阵效果怎么样啊。se3.transform将源点通过变换矩阵得到变换后的点,用于下一次迭代的特征提取和匹配。将每次循环的结果都存储起来,为后续损失计算做准备。
计算损失
来到路径src/train.py下看看compute_losses损失是什么计算的。
python
def compute_losses(data: Dict, pred_transforms: List, endpoints: Dict,
loss_type: str = 'mae', reduction: str = 'mean') -> Dict:
losses = {}
num_iter = len(pred_transforms)
# Compute losses
gt_src_transformed = se3.transform(data['transform_gt'], data['points_src'][..., :3]) # (b,717,3)
if loss_type == 'mse':
# MSE loss to the groundtruth (does not take into account possible symmetries)
criterion = nn.MSELoss(reduction=reduction)
for i in range(num_iter):
pred_src_transformed = se3.transform(pred_transforms[i], data['points_src'][..., :3])
if reduction.lower() == 'mean':
losses['mse_{}'.format(i)] = criterion(pred_src_transformed, gt_src_transformed)
elif reduction.lower() == 'none':
losses['mse_{}'.format(i)] = torch.mean(criterion(pred_src_transformed, gt_src_transformed),
dim=[-1, -2])
elif loss_type == 'mae':
# MSE loss to the groundtruth (does not take into account possible symmetries)
criterion = nn.L1Loss(reduction=reduction)
for i in range(num_iter):
pred_src_transformed = se3.transform(pred_transforms[i], data['points_src'][..., :3])
if reduction.lower() == 'mean':
losses['mae_{}'.format(i)] = criterion(pred_src_transformed, gt_src_transformed)
elif reduction.lower() == 'none':
losses['mae_{}'.format(i)] = torch.mean(criterion(pred_src_transformed, gt_src_transformed),
dim=[-1, -2])
else:
raise NotImplementedError
# Penalize outliers
for i in range(num_iter):
ref_outliers_strength = (1.0 - torch.sum(endpoints['perm_matrices'][i], dim=1)) * _args.wt_inliers
src_outliers_strength = (1.0 - torch.sum(endpoints['perm_matrices'][i], dim=2)) * _args.wt_inliers
if reduction.lower() == 'mean':
losses['outlier_{}'.format(i)] = torch.mean(ref_outliers_strength) + torch.mean(src_outliers_strength)
elif reduction.lower() == 'none':
losses['outlier_{}'.format(i)] = torch.mean(ref_outliers_strength, dim=1) + \
torch.mean(src_outliers_strength, dim=1)
discount_factor = 0.5 # Early iterations will be discounted
total_losses = []
for k in losses:
discount = discount_factor ** (num_iter - int(k[k.rfind('_')+1:]) - 1)
total_losses.append(losses[k] * discount)
losses['total'] = torch.sum(torch.stack(total_losses), dim=0)
return losses又看到se3.transform老朋友了,先将源点通过变换矩阵变换过来,这里用的都是真实值,是真货。判断一下用哪种损失函数,然后又看到se3.transform兄弟,这次还是源点通过变换矩阵变换过来,but,这次用的是我们预测出来的变换矩阵,是假货。ok,让我们来看看真货与假货之间的差异。
单单计算配准损失,不够不够,得再来点离群惩罚。上面说过,perm_matrices里存放的是源点与参考点的匹配概率,对行或列求和再取1-sum,就是匹配失败的程度。
之前在rpmnet里计算时,不是迭代的计算了几次,每次迭代的数据都被存储下来了。很显然,前面迭代的时候只是粗糙的计算了一下,后面再此基础上再微调,让其越来越准确。因此,需要加个权重discount ,前面迭代的结果损失轻点,但是到后面了,就不能一直这么碌碌无为了,得加重点。最终加权叠加所有损失返回结果。